 夜雨聆风
夜雨聆风一个开源工具,任意 .txt / .md 小说丢进去,AI 把人物、地点、事件、关系全提取出来,做成可交互可视化系统。本地跑,不联网,桌面端即装即用。
近期,小编陆续整理过几篇 AI 拆解经典的项目文章:
294 卷《资治通鉴》被 720 个圆点和 1812 条线拆开、整本《史记》被时间线重排、26 万首唐诗宋词被词频统计成两个朝代的脾气;评论阅读反响都很好。但留言区问得最多的是要是能解析出“XXX“,就好了;这次还真被小编找到了。
GitHub 上有个开源项目,叫 AI Reader V2;它干的事一句话讲清楚。
直接上在线 Demo(不下载也能玩)
https://ai-reader.cc/demo/honglou/graph?v=3
你丢一本 .txt 或 .md 进去,AI 把整本小说的人物、地点、事件、关系全部提取出来,画成图给你看。
任意小说。
不是"AI 帮你写读后感",不是"AI 帮你做总结"——它不替你读;它替你记账。
再也不用没耐心地翻开一本厚书,对着 800 个名字干瞪眼。下面挨个拆它的功能。
1. 人物关系图谱:70+ 种关系,自动识别
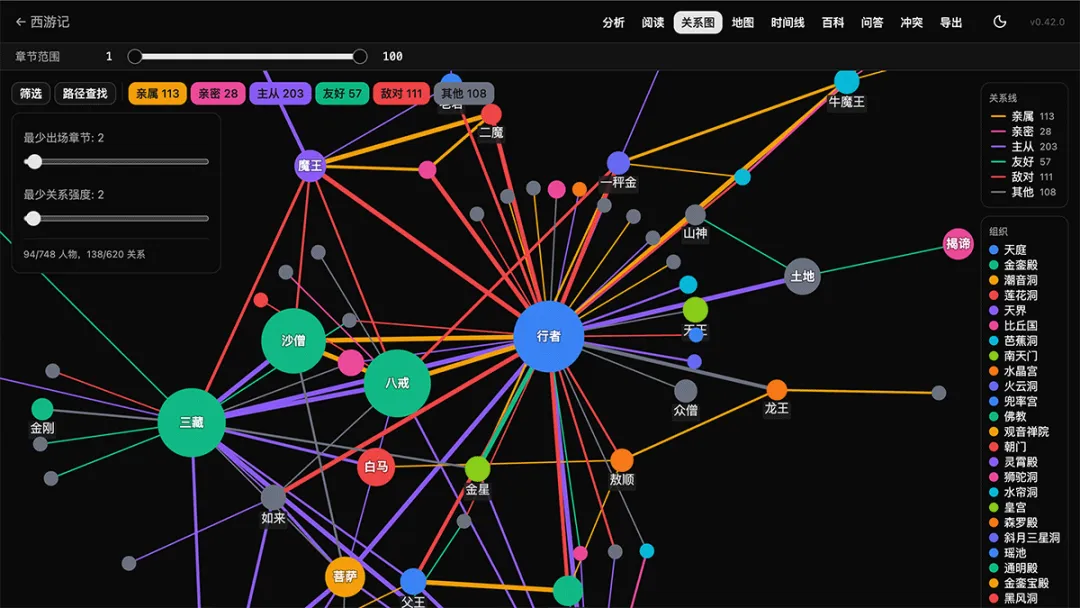
分析完,第一个视图就是这张图。
每个点是一个角色,每条线是一种关系。血亲、师徒、同盟、敌对、同门、结拜、师兄弟——70+ 种关系类型自动识别,六大分类着色。
这里有个细节最难做。
孙悟空 = 美猴王 = 行者 = 齐天大圣 = 弼马温 = 孙行者
同一个人,六个名字。
普通文本处理会当六个人,关系网瞬间崩成一锅粥。
AI Reader 在这件事上花的力气,光看版本号就懂:
v0.66:Canonical 选名优先 3 字全名、绰号降权 v0.71:相似名阻断防桥接、跨人物冲突检测 v0.71.4:「沙僧别名误入八戒」专门发了一个 hotfix
图谱本身还能:
路径查找——选两个角色,看他们最短的关系链是什么 分类过滤——只看血亲、只看敌对 边权重调节——只保留强关系,过滤一面之缘
我用《红楼梦》Demo 数据玩了 20 分钟,第一次看清楚薛家是怎么从外戚变成贾家"自己人"的。
那张图就是一本厚厚的家谱,被你拿在手里转着看。
2. 世界地图:从文本里"长"出来
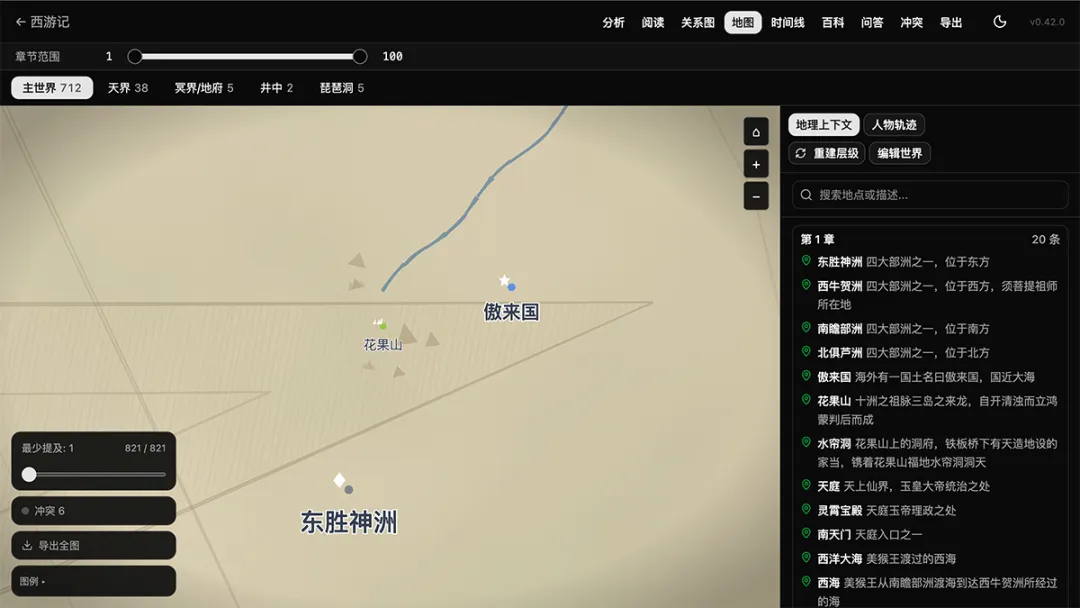
这是我看的时候喊出声的一个功能。
AI 从小说原文里,自动构建一张多层级交互式地图。不是预制模板填名字,是真的画出来。
具体做了什么:
| 角色路径动画——孙悟空从花果山 → 东海 → 天宫 → 五行山 → 西天,整条路在地图上动起来 |
底层算法不简单。
地点层级用的是 Edmonds 全局最优生成树算法(McDonald 2005),把"地点 A 属于地点 B"建模成"最大权有向生成树"组合优化问题,130ms 求解。
这种顶会论文里的算法用在小说地图上——我没见过第二个。
效果是:西游的世界、红楼的大观园、冰与火的维斯特洛——每本书都有自己一张地图,不是套模板套出来的。
3. 时间线 / 故事线:多泳道并行
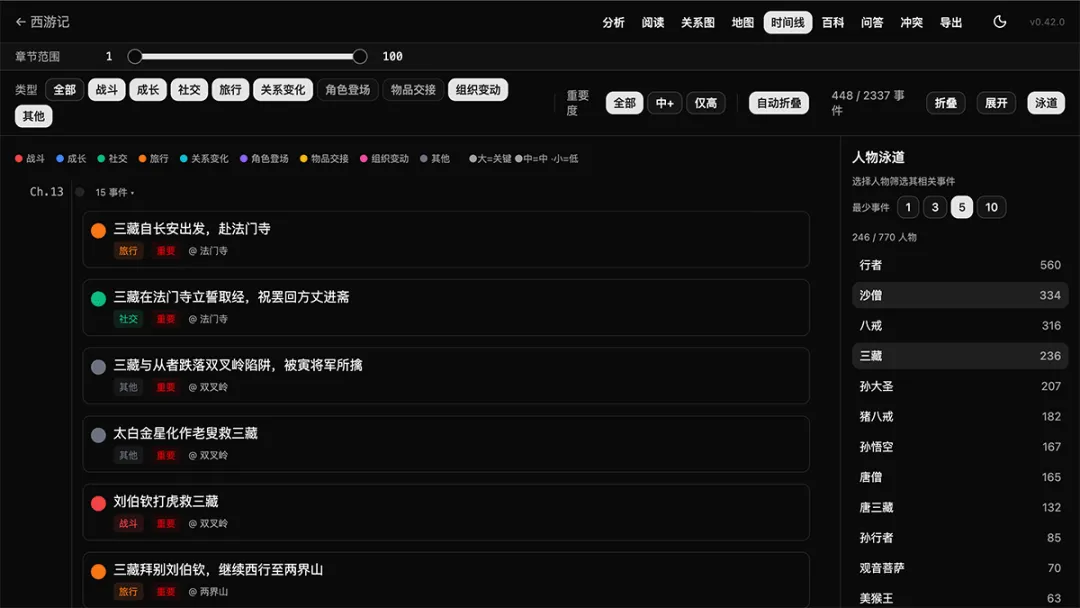
长篇最难梳理的就是多线叙事。
冰与火之歌一个章节换一个 POV,凡人记不住。
AI Reader 的解法是多泳道时间线:
每个角色一条独立泳道 角色登场 + 物品流转 + 关系变迁 + 组织变动,四种事件聚合 每个事件标情绪基调(紧张 / 平和 / 转折) 智能降噪过滤掉无关紧要的小事 章节折叠,长书也能装进一屏
你能看清楚同一章里,史塔克在北境干嘛,兰尼斯特在君临干嘛,丹妮莉丝在东方干嘛——三条线并排。
这是一个 POV 写作时代最迫切需要的视图。
4 小说百科:所有实体都有自己的卡片
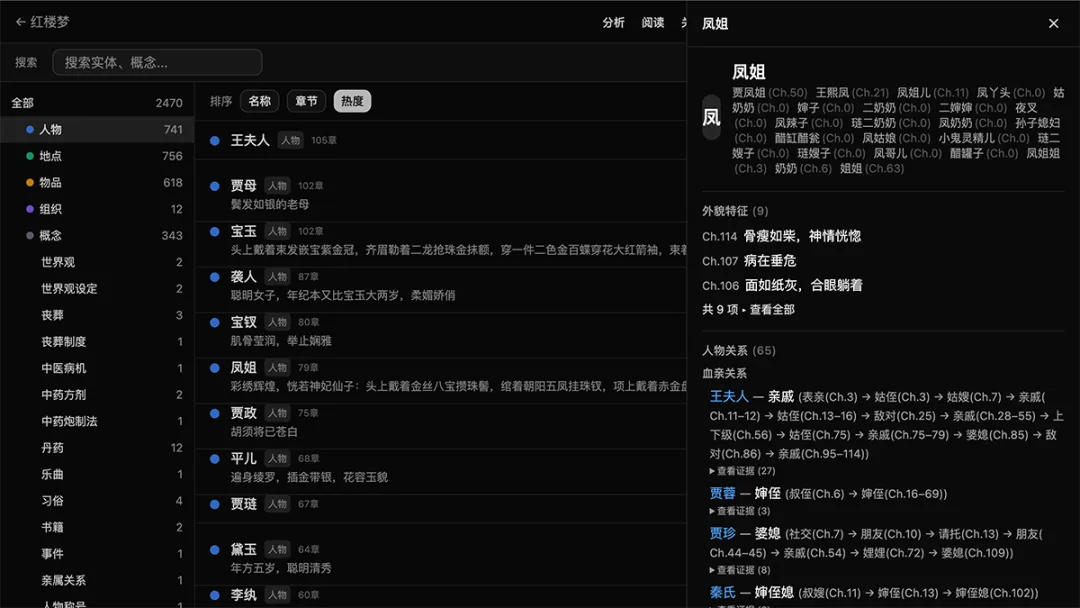
五类实体分类浏览:人物 / 地点 / 物品 / 组织 / 概念。
每个实体一张卡片。点开一个地点,你能看到:
它的层级树(属于哪个国、哪个洲、哪个层) 空间关系面板(相邻地点、包含地点) 场景索引——它在原文哪一章哪一段被提到过
读到一半忘了「金陵十二钗」里某个人是谁?搜一下,卡片告诉你她是谁、出过几次场、和谁有关系。
这是把整本书变成一个可搜索的数据库。
5. 还有一堆藏在 README 深处的能力
往下读 README,会发现一些没显眼讲、但很值得的功能。我挑四个最有意思的。
RAG 智能问答——
基于原文的检索增强问答。你问:"黛玉葬花那天,宝玉在干嘛?"
AI 去原文里找证据,给你答案,标章节出处。
读完一本书想跟人讨论但身边没人聊——这本书给你配了个 24 小时在线的助教。
势力图——
组织架构 + 势力关系网络。专门为「四大家族」「七大宗派」「五大世家」这类多组织对抗的小说设计。
智能阅读页——
不是分析完就完事,而是把分析结果反向喂回阅读体验:
读到「行者」两个字,鼠标悬停告诉你是孙悟空。读到一个新地点,色块标记,点开看背景。读到一场战役,剧本面板告诉你当前章节出现了谁、在哪、做了什么。
这是 AI 重新设计的"读法",不只是"读完之后给你看图"。
设定集导出(Markdown / Word / Excel / PDF 四格式)——
这个功能对网文作者太友好了。
新章写完,导出一份最新版世界设定。发给责编、发给读者、发给自己几个月后续写时不至于忘。
v0.72 体验版又加了「可读分析报告导出」——按章节排版的实体清单,替代裸 JSON。
6. 技术栈:值得开发者看一眼
| 桌面 | Tauri 2 (Rust) + Python sidecar (PyInstaller 打包) |
技术选型里最值得注意的是桌面这一行:
Tauri 把 Rust 壳子 + 完整 Python 后端打包成单个 dmg / exe,用户双击就能用,不装 Python、不装 Node。
这个方案大多数 Electron 应用做不到。
7. 一句必须说的诚实话
我不能只夸不提缺点——那是营销号的活。
作者自己在 README 顶部写了一句:
「本项目正处于数据分析质量提升的密集迭代期,当前版本仅供尝鲜体验,分析结果可能包含较多错误。」
实测下来——确实有错。
别名合并偶尔出问题 地点层级偶尔有歧义 用本地小模型(7B 以下)分析,准确率明显下降
它现在更像一个辅助梳理工具,不是最终结论生成器:AI 给你一份初稿,你再去修。
但 README 那份从 v0.43 走到 v0.72 的更新日志——三个月 30 个版本,单元测试从 151 涨到 529——能看出来作者真的在认真打磨。
不是融完资跑路那种开源。
8. 一个绕不开的彩蛋:作者全程没写代码
作者在 README 里挂了一篇知乎文章:
《全程不写一行代码,我如何用 AI 做出一个复杂的小说分析系统》
我点进去看完了。
这个项目,是完全用 AI Coding 工具做出来的开源产品。
React 19 + TypeScript + Tauri 2 + Rust + Python FastAPI + Edmonds 算法+ ChromaDB——这个技术栈拉出来,至少是一个 3 年经验的全栈工程师水平。
而它来自一个声称"不写代码"的人。
我对"AI 是否能让普通人做出真产品"这件事,过去一直有保留。
看到这个项目,态度软化了一格。
不是 AI 能替代程序员。是会用 AI 的非程序员,能做出来的东西,确实超出了我的预期。
9. 怎么用上
桌面端(推荐这条路)
零配置,下载即用。
下载后只需要再装一个 Ollama 拉一个 qwen3:8b 模型,就能完全离线运行。
内置《红楼梦》《西游记》完整分析数据,所有视图可点可玩。
自己跑开发版(程序员用)
ollama pull qwen3:8b && ollama servecd backend && uv sync && uv run uvicorn src.api.main:app --reloadcd frontend && npm install && npm run dev打开 http://localhost:5173。
项目地址
GitHub:https://github.com/mouseart2025/AI-Reader-V2 官网:https://ai-reader.cc 协议:AGPL v3(个人 / 教育 / 研究免费,商业闭源另谈)
最后说一句。
长篇小说这种媒介,过去几十年阅读方式没什么进化。一本书摆在眼前,全靠脑子记账。
AI Reader 至少提供了另一种可能——
用 AI 把书的结构画出来,让大脑只负责欣赏,不负责记账。
把你硬盘里那本看了一半的书拖进去,让 AI 替你算一笔账。
如果对你有用,点个推荐,让更多喜欢读书和技术的人看到这个项目。
同类AI与知识工程文章,值得阅读:
