 夜雨聆风
夜雨聆风如果你最近长时间开着 Codex CLI、Codex App,或者在 VS Code、Cursor、tmux 里挂着 Codex,这件事最好花两分钟看一下。
最近 Codex 社区里冒出一个很扎眼的问题:有人发现自己的硬盘被持续写入,源头不是 node_modules,不是 Docker 镜像,也不是编译缓存,而是 Codex 本地目录里的几个 SQLite 日志文件。
更具体一点,是这些文件:
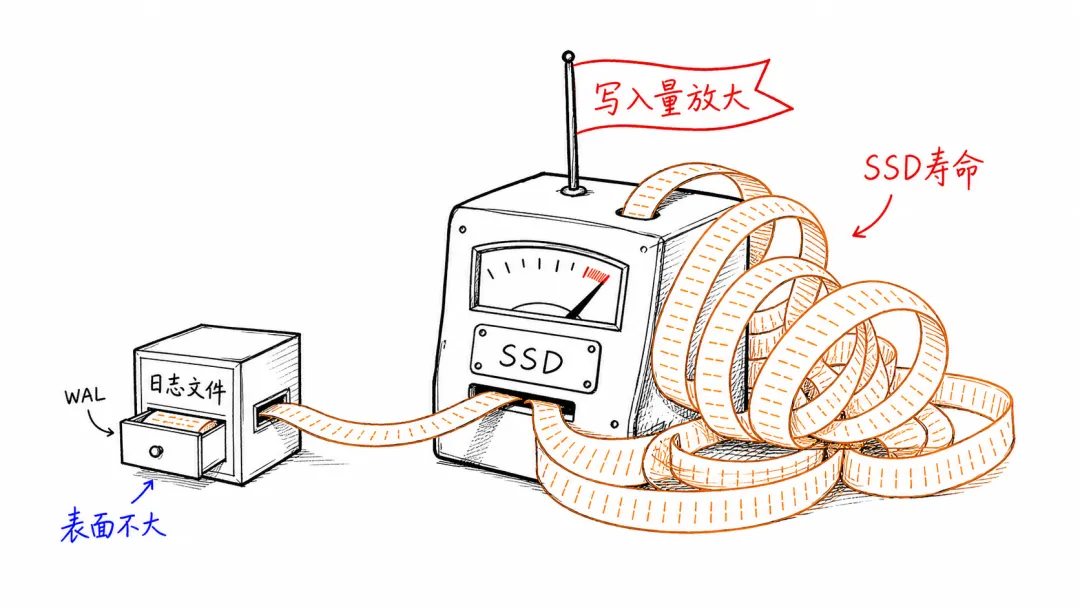
~/.codex/logs_2.sqlite~/.codex/logs_2.sqlite-wal~/.codex/logs_2.sqlite-shm它吓人的地方不只是“日志文件变大了”。真正的问题是:日志系统一边高频写入,一边裁剪旧记录,一边继续写。你最后看到的文件可能只有几百 MB 或 1GB,但 SSD 背后已经承受了远远超过这个数字的写入量。
公开 issue 里有用户估算,自己的机器在大约 21 天内,因为 Codex 相关日志让主 SSD 写入了约 37TB。按这个速率线性外推,一年可能接近 640TB。这个数字已经接近不少消费级 SSD 的保修写入寿命。
这也是为什么很多人第一反应是:这不是小 bug,这是在悄悄消耗硬盘寿命。
问题不在 SQLite,而在日志太“话痨”
先把锅分清楚:SQLite 本身不是问题,WAL 机制也不是问题。
WAL,也就是 Write-Ahead Log,本来就是数据库常见机制,用来提升可靠性和性能。正常情况下,它不应该成为用户肉眼可见的磁盘压力源。
这次真正出问题的是 Codex 的持久化日志链路一度太吵。
大量 TRACE 级别日志、Responses WebSocket 流式事件、底层依赖库事件,以及重复的 OpenTelemetry 镜像事件,都被写进了本地 SQLite 日志。尤其在长线程、高频 streaming、多终端、多进程同时使用时,这些“小记录”会变成持续写盘的风暴。
你可以把它理解成:
Codex 每次和模型通信、每次收到流式响应、每次内部状态变化,都可能留下一笔记录。单条记录不大,但数量非常多。更麻烦的是,日志数据库还会不断插入、索引、写入 WAL,再裁剪旧记录。
所以文件表面看起来没有无限膨胀,实际写入量却已经被放大。
这就像一个人不停记笔记,又不停撕掉旧笔记。你看到桌面上没几张纸,但整本本子已经被消耗掉了。
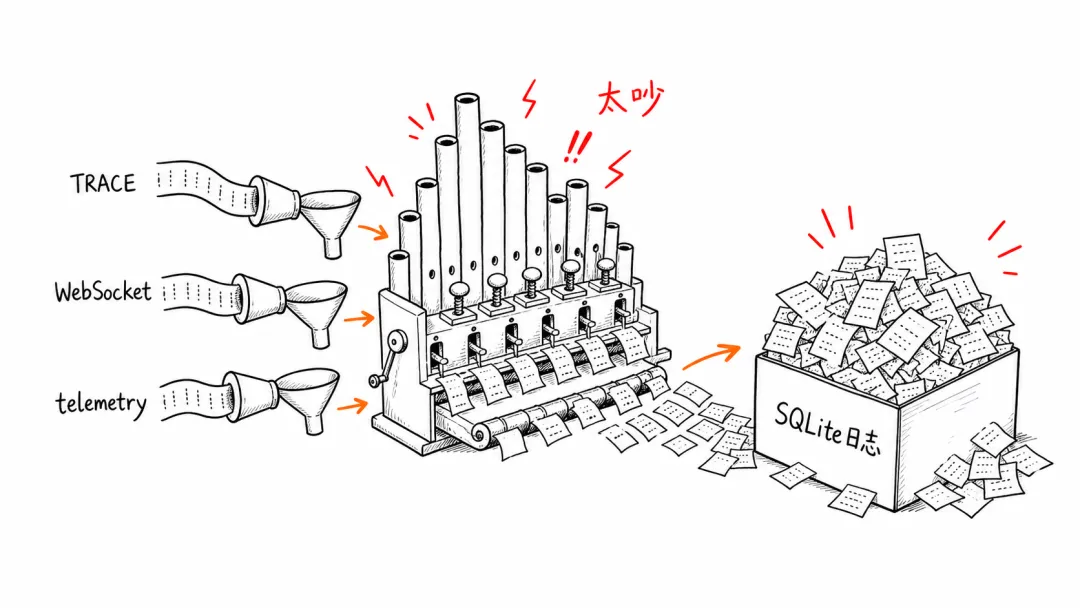
为什么删了文件,空间还是没回来?
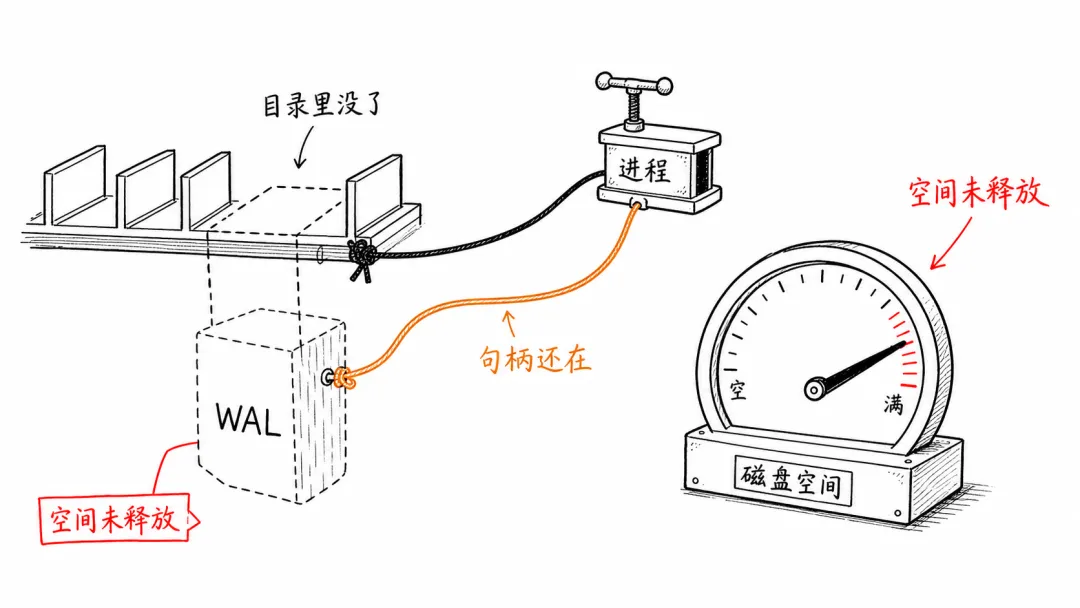
这次事件里还有一个很容易误判的点:有些人看到 logs_2.sqlite-wal 长到几十 GB,直接删除,结果 du ~/.codex 看起来小了,df -h 却还是显示空间没有回来。
原因很简单:文件虽然从目录里消失了,但 Codex 进程可能还握着这个“已删除文件”的句柄。只要进程没退出,系统就不会真正释放那块空间。
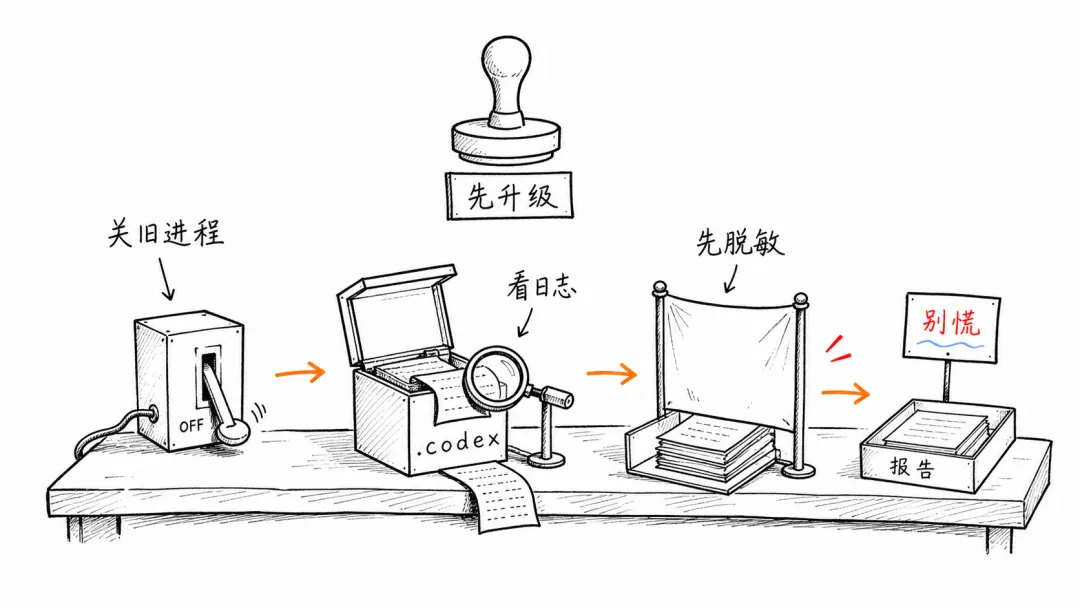
所以不要在 Codex 正在运行时硬删、硬截断 WAL 文件。更稳妥的处理顺序是:
先退出所有 Codex 相关进程,包括 CLI、TUI、桌面 App、IDE 插件后端和 tmux 里的旧 session。 再检查 .codex目录下的日志文件大小。如果确认有异常大文件,再清理或移动。 清理后重新启动 Codex,并观察 WAL 是否继续快速增长。
Linux/macOS 用户可以先看这几条:
ls -lh ~/.codex/logs_2.sqlite*du -sh ~/.codexlsof -nP +L1 | grep codex如果你看到 Codex 进程仍然持有 (deleted) 的大文件,说明空间还没有真正释放。
Windows 用户可以先关闭 Codex 桌面端、终端里的 Codex、IDE 插件后端,再检查:
Get-ChildItem "$env:USERPROFILE\.codex\logs_2.sqlite*" | Select-Object Name,Length,LastWriteTime如果空间迟迟不回来,最简单的办法往往是完全退出相关进程,必要时重启一次系统。
现在修了吗?
截至 2026 年 6 月 23 日,我核对到的公开进展是:主因已经被明显缓解,但不建议把它理解成“所有本地日志问题都彻底结束了”。
OpenAI/codex 在 6 月 22 日合并了两个关键修复:
停止记录每一个成功的 Responses WebSocket 事件。 过滤持久化日志里的高噪声 target,尤其是重复 telemetry 记录。
随后 0.142.0 版本说明里也明确提到,已经减少 persistent-log churn,也就是减少持久化日志的反复写入和裁剪。
这句话要分两层看。
好消息是,高频写盘风暴的主要来源被砍掉了一大块。相关 issue 里也有人反馈,这两个 PR 能显著减少日志量。
但谨慎一点说,修复进入 release,不代表你本机的旧版本自动安全。你仍然需要升级 CLI、桌面 App 或 IDE 插件。社区里也还有关于 WAL 文件增长、旧进程持有句柄、日志上限、checkpoint 和轮转策略的讨论。
所以我的建议不是恐慌,而是做一次本地体检。
普通用户该怎么处理?
如果你最近用过 Codex,尤其是长期挂着 CLI、桌面 App、VS Code/Cursor 插件,建议做三件事。
第一,升级到包含修复的新版本。
CLI 用户可以检查 GitHub Release、Homebrew、npm 或官方安装脚本对应版本。桌面 App 用户也建议重启应用并检查更新。重度用户不要长期停留在旧版本。
第二,看一眼本地 .codex 目录。
如果 logs_2.sqlite-wal 或 logs_2.sqlite 已经到了 GB 级别,不要一边运行 Codex 一边强行处理。先退出相关进程,再清理或移动日志文件。对不熟悉 SQLite/WAL 的用户来说,先关进程比先删文件重要。
第三,注意隐私。
这些本地日志不一定只是“无意义日志”。从公开讨论看,日志里可能包含 prompt、路径、命令、项目元信息,甚至经过处理的通信事件。遇到问题向社区或 issue 上传诊断材料时,不要把整个 ~/.codex 目录随手打包发出去。
真正值得警惕的,不只是这一个 bug
这件事表面上是一个日志 bug,但它提醒我们:AI 编程工具的身份已经变了。
过去的编辑器插件,多数时候只是补全工具。你敲代码,它给建议。
现在的 Codex、Claude Code、Cursor Agent、Gemini CLI,越来越像本地自动化系统。它会读项目、跑命令、开线程、写状态、维护上下文、连接远程服务,甚至长时间在后台执行任务。
也就是说,它不再只是一个输入框,而是一组常驻进程。
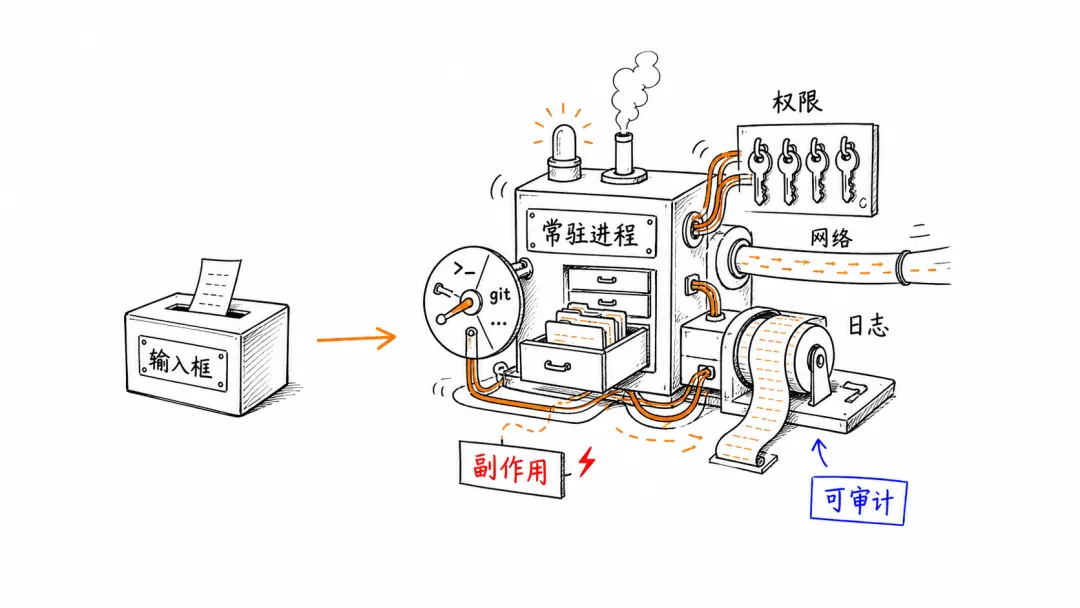
一旦工具变成常驻进程,工程质量的要求就完全不一样了。日志要有上限,缓存要能回收,WAL 要能 checkpoint,异常进程要能退出,后台任务要能被用户看见,诊断数据要可控、可清理、可审计。
否则,一个“为了方便排查问题,多记一点日志”的设计,在重度用户那里就可能变成每天几十 GB 的硬盘写入。
这不是 Codex 独有的问题,而是所有 AI Agent 工具都会遇到的问题。
Agent 越强,权限越大;权限越大,副作用越多;副作用越多,工程边界就越重要。
我的判断
这次 Codex 写盘事件,不太适合简单写成“OpenAI 又翻车了”。
更准确的判断是:AI 编程工具正在从“聪明插件”变成“本地自动化系统”,而本地自动化系统需要很多传统软件里朴素但关键的工程纪律。
日志不能无限写。
缓存不能无限长。
后台进程不能无感常驻。
本地状态不能只增长不治理。
诊断能力不能以牺牲用户硬盘寿命为代价。
好消息是,这次主因已经被快速修复了一大块。坏消息是,类似问题以后还会出现。
对开发者来说,AI 编程工具确实越来越有用。但如果你准备把它们长期挂在本地机器上,就应该像对待 Docker、数据库、CI runner 一样对待它们:定期升级,定期检查磁盘、进程、网络和权限。
AI Agent 的未来不只是“能不能写代码”。
更重要的问题是:它能不能可靠、可控、可审计地在真实机器上工作。
这次 Codex 疯狂写盘,正好给所有 AI 编程工具提了一个醒。
