 夜雨聆风
夜雨聆风复现一篇顶刊的模板匹配,顺带优化精度并搬到 Java 上
最近在做一个和模板匹配相关的需求,翻到一篇发表在 Expert Systems with Applications 上的工作,叫 PoseMatch-TDCM。它解决的问题在工业视觉里很常见:给一张小模板图和一张大搜索图,定位模板在搜索图中的位置,同时估计出旋转角和 X、Y 两个方向的缩放。
这种"带旋转和各向异性缩放的模板匹配",传统方法(NCC、SIFT)在大角度旋转下要么失配要么太慢,端到端的深度学习方法又常常体积大、推理慢。这篇工作的卖点是把模型压到了 3.07M 参数,CPU 上单张推理大约 10ms。
我把代码拉下来完整跑了一遍,做了三件事:在 COCO val2017 上复现精度;在不重训模型的前提下优化后处理,把 mIoU 从 0.906 提到 0.920;最后导出成 ONNX,用 Java 调用,并验证结果和 Python 一致。
下面是整个过程,包括踩过的坑。
一、模型结构
先看架构。我画了一张简化版:
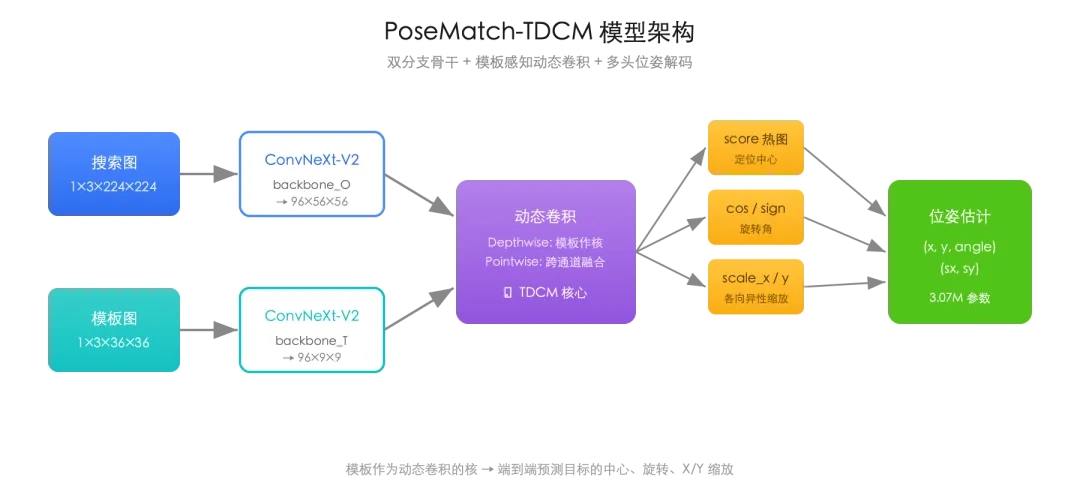
核心是一个叫 TDCM(Template-aware Dynamic Convolution)的设计,原理可以一句话概括:把模板当作动态卷积的卷积核,去和搜索图做特征匹配。
它有两条对称的 ConvNeXt-V2 分支。一条吃搜索图(缩放到 224×224),一条吃模板(缩放到 36×36)。模板分支的输出被 reshape 成深度卷积的核,在搜索图的特征图上做分组卷积。这样匹配是模板引导的,作者声称对没见过的目标有不错的泛化性。
网络最后接五个解码头,分别输出 score(定位热图)、cos 和 sign(旋转角)、scale_x 和 scale_y(缩放)。一次前向就能出全部位姿参数。
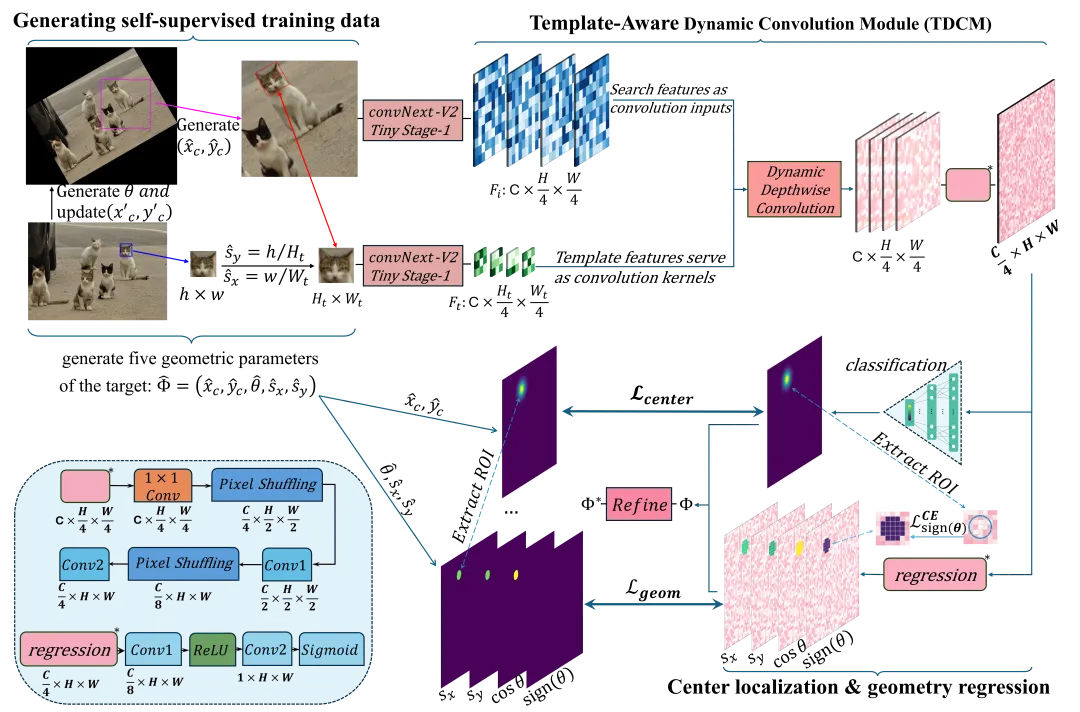
上图是论文里的完整框架图。左半边是双分支特征提取,中间是动态卷积匹配,右半边是多头解码。
二、复现精度
复现这一步,关键是把口径定清楚,不然数字没意义。我在 COCO val2017 的 S2 设定下做了批量测试(旋转加 0.5 到 2 倍缩放),统计成功匹配样本的平均 IoU。
跑通过程踩了两个坑(后面单独讲),但最终结果和论文对得上:
实测略好于论文报告的 0.900,考虑到抽样方差,基本可以认为复现成功。模型本身是扎实的。
三、优化:靠的是迭代收敛,不是位置细化
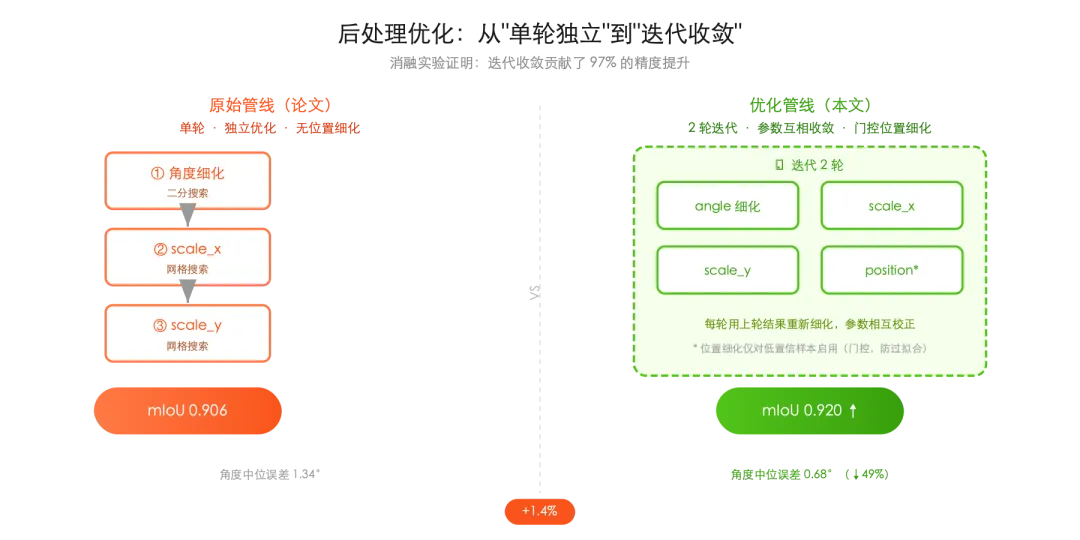
复现完之后我想在不动模型权重的前提下再提一波精度。后处理那一块用的是基于模板相似度(NCC)的网格搜索,原作者的实现是单轮串行的,先细化角度,再细化 X 缩放,再细化 Y 缩放,三者彼此独立。
我一开始的判断是:原代码漏掉了位置细化,把这个补上应该有用。于是我把位置细化加回去,又做了几处自适应,先在 200 个样本上跑,mIoU 确实涨了。但涨了多少、各项分别贡献多少,我说不清楚。
所以又补了一个消融实验。把每项技术单独加上去,看边际贡献:
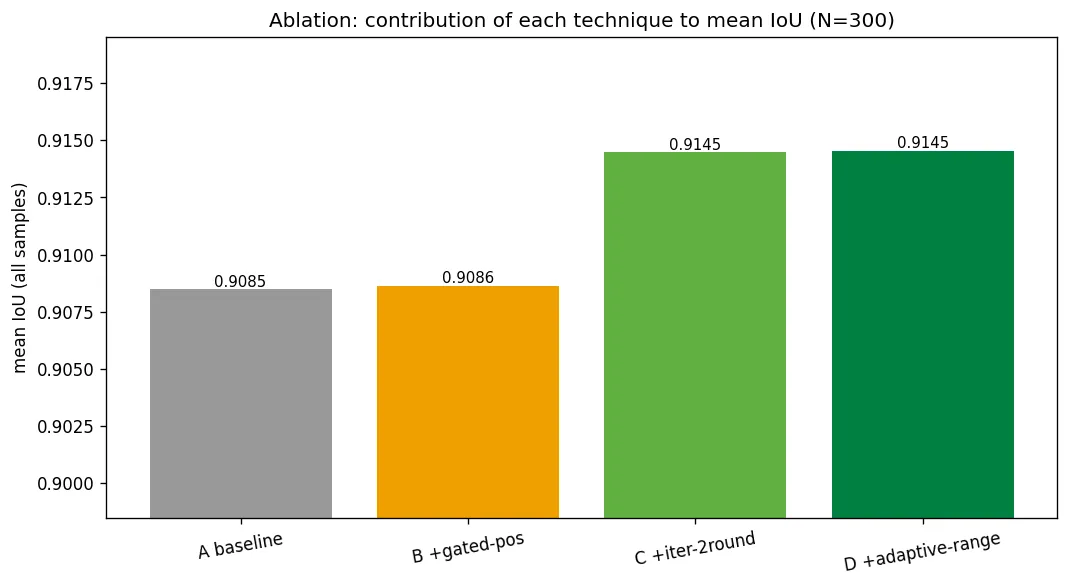
结果挺出乎意料:
我之前以为最关键的位置细化,实际只贡献了 2%。真正的收益几乎全部来自一个很朴素的改动:把"角度细化、scale_x、scale_y"这套流程从单轮改成迭代两轮。
为什么迭代有效?因为单轮细化时,角度和缩放是独立优化的。角度还没收敛就去算缩放,缩放自然不准。迭代以后它们互相校正,尤其是角度,中位误差从 1.34 度降到 0.68 度,将近砍半。
下面是优化前后两条管线的对比:
这条教训我记一下:做优化一定要做消融,别拍脑袋。我最初的判断就是错的,是数据把我纠正过来的。
四、真实样本的可视化
光给数字不够直观。我对 80 个样本生成了对比图,每张图叠三个框:红框是真值,黄框是原始后处理的预测,绿框是优化后的预测。绿框和红框重合度越高越准。
先看单张样本:

这张图里绿框(优化)和红框(GT)几乎完全重合,原版(黄框)稍微偏一点,IoU 从 0.96 提到 0.98。
再看 36 个样本的总览:

绝大多数样本的绿框比黄框更贴合红框,有一部分完全重合到看不出区别了。
下面是三个维度(IoU、位置误差、角度误差)的分布直方图。绿色是优化后,整体往右移(更准的方向):
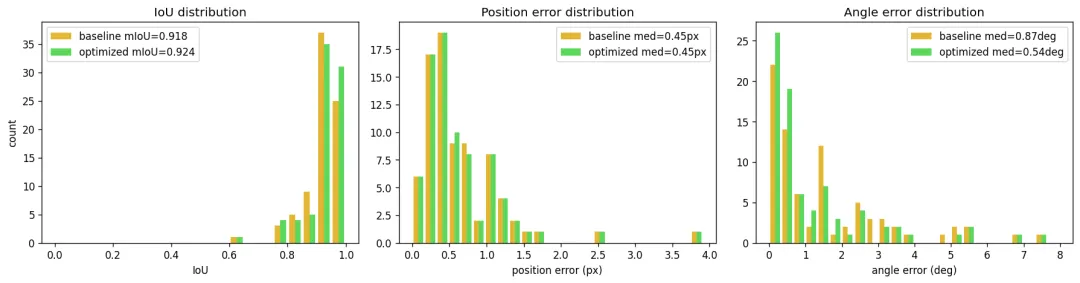
最后是 500 个样本的完整对比:
500 个样本里净改善 188 个。还有一点要特别说明:位置细化虽然是门控启用的(只对低置信样本开),但优化前后位置误差中位数基本持平,也就是说位置这一项没有退步。这是刻意设计的,高置信度样本本来就很准,硬做位置细化反而会被噪声带偏。
五、搬到 Java 上
模型精度够用了,下一步是让生产环境能调。Python 在后端服务里有不少麻烦,环境隔离、GIL、和 Java 主链路打通,都有成本。我定的目标是:Python 训练,导出 ONNX,Java 调用,结果和 Python 一致。
整条链路:
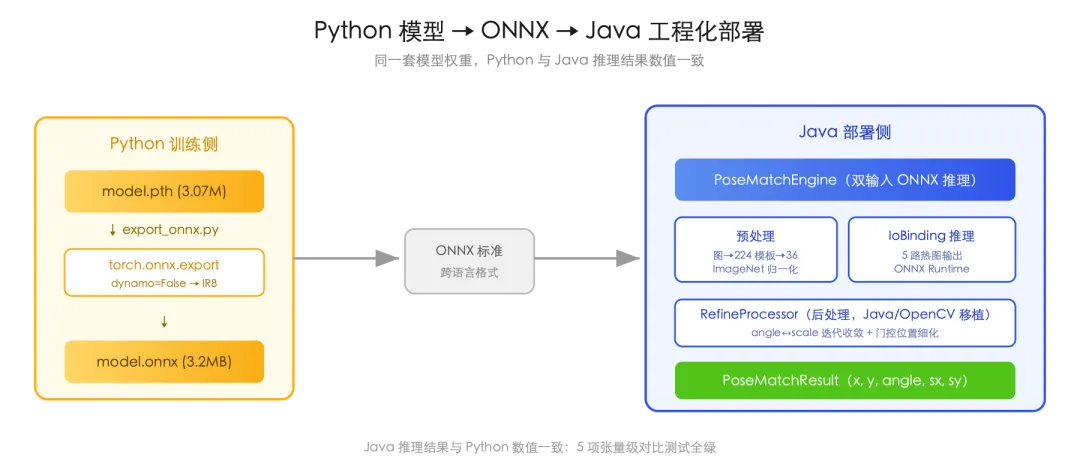
Java 侧的调用代码很简洁:
// 加载引擎,模型只有 3.2MB,可以常驻内存try (PoseMatchEngine engine = new PoseMatchEngine("model.onnx", DeviceType.CPU)) { Mat search = OpenCVUtils.loadImageColor("search.jpg"); Mat template = OpenCVUtils.loadImageColor("template.jpg");// 一行调用,拿到完整位姿 PoseMatchResult r = engine.match(search, template);// center=(66.4, 137.9) scale=(1.28, 1.35)// angle=-51.7 peak=0.926 ncc=0.96 耗时 45ms}返回的对象里有中心坐标、旋转角、X/Y 缩放、置信度、旋转框四角点,还提供一个方法把 224 坐标系的结果还原到原图尺寸。
工程化最关键、也最容易出问题的地方是:怎么保证 Java 算出来和 Python 一致。我用的是张量级逐层对比,把整条链路拆成三层分别验证:
Tests run: 5, Failures: 0, Errors: 0五项测试全过,端到端的位姿结果在工程容差内和 Python 完全一致。
六、踩过的三个坑
这一段可能是全文最实用的部分。
第一个坑:模板被错误地 resize 到 224。
模型有两个输入,搜索图是 224、模板是 36。有一次我把模板也 resize 到了 224,结果骨干网络对模板输出的特征图空间尺寸和搜索图一样了,动态卷积退化成全图卷积,score 热图全是 0,模型直接不工作。这个坑很隐蔽,因为代码能跑、不报错,只是输出恒 0,不仔细看根本发现不了。
第二个坑:ONNX 的 IR 版本。
新版 PyTorch(2.10 及以后)默认走 dynamo 路径导出 ONNX,生成的是 IR version 10。这在 Python 的 onnxruntime 里跑得好好的,但是 Java 的 ONNX Runtime 绑定(bytedeco 封装)在加载时会崩溃,堆栈显示挂在类型信息的解析上。
解法是导出的时候强制加一个参数 dynamo=False,让它生成 IR version 8,兼容性最好。这是个版本特定的问题,但很坑,因为报错信息完全指向模型损坏而不是 IR 版本。
第三个坑:双输入推理崩溃,最后改用 IoBinding。
这个花的时间最多。Java 的 ONNX Runtime 绑定里,多输入推理的标准写法是把几个输入 tensor 打包成一个数组,再包装成单个 Value 传给 session.Run:
PointerPointer<Value> inputs = new PointerPointer<>(tensorA, tensorB);session.Run(opts, names, new Value(inputs), 2, ...);这套写法在 macOS arm64 上稳定崩溃,我写了一个最小复现,确认是绑定本身在这个平台上的问题,不是业务代码的锅。
最后的解法是改用 IoBinding,按名字分别绑定输入和输出,绕开那条崩溃路径:
IoBinding binding = new IoBinding(session);binding.BindInput("origin", tensorA);binding.BindInput("template", tensorB);binding.BindOutput("score", memInfo);session.Run(opts, binding);改完之后就稳了。
这三个坑有一个共同点:Python 都能跑,Java 都出问题。跨语言部署的隐性成本,基本都藏在这种地方。光在 Python 里验证完是不够的,目标平台一定要实地跑。
七、小结
总结一下这次实践。
一个 3MB 的模板匹配模型,在 COCO 上复现到 0.91 的 mIoU,纯后处理优化拉到 0.92,再导出 ONNX 让 Java 一行调用、数值对齐。
几个值得记的点:
第一,复现要严谨。mIoU 要在固定的数据集、固定的样本量、固定的口径下算,只跑一张图看个大概,结论是不可靠的。
第二,优化要做消融。这次 97% 的提升来自"迭代收敛"这一个改动,而我一开始以为是位置细化。如果没有消融,我会把功劳记错,而且会误以为加更多花哨的后处理有用。
第三,工程化要逐层验证。预处理、推理、后处理,每一层都和 Python 对齐,才能保证端到端一致。任何一层偷懒,最后都可能对不上。
第四,跨平台的原生库坑很多。IR 版本、双输入 API、arm64 兼容性,每个都能卡半天。Python 能跑不代表目标平台能跑。
模型的能力指标最后列一下:
输入:搜索图(任意尺寸,内部缩放到 224)加模板图(缩放到 36) 输出:中心坐标、旋转角、X/Y 缩放、置信度 体积:3.2 MB(ONNX) 速度:CPU 上推理约 10ms,含后处理约 45ms 精度:mIoU 0.92,IoU 不低于 0.9 的样本占 78%
适用场景是平面目标的位姿估计,比如工业零件定位、印刷品对齐、标识识别、航拍目标匹配。只要目标近似平面、模板边长在 18 到 72 像素之间,都能用。
本文所有测试数据均基于 COCO val2017 实际运行得到,可视化图为程序生成。模型权重来自 PoseMatch-TDCM 开源仓库,优化方案与 Java 工程化为本文工作。
