 夜雨聆风
夜雨聆风
上周,Claude Code发了一次更新。
版本号2.1.179。changelog里没有新模型,没有benchmark分数,没有“代码能力提升XX%”。就几条不起眼的bug修复:连接断了以后保留部分响应、工具执行时的spinner不再卡在“running tool”、远程session里的后台任务不再在多个turn之间一直显示“still running”。
如果你不是天天用Claude Code的人,你甚至不会点开这个changelog。
但如果你仔细看这几条修复——它们指向了同一件事。一件比“哪个模型更强”更重要的事。
不是模型的问题。是系统的问题。
过去两年,我们评价一个AI编程产品,问的都是同一个问题:模型聪不聪明? 谁能写更好的代码,谁能理解更长的上下文,谁在SWE-bench上拿更高分。这些答案回答的是“它会不会写代码”。
Claude Code这次修的几个问题,回答的是另一个问题:当它真的开始替你干活了,它能稳定地把这件事做完吗?
区别在哪?
你让一个聊天机器人修bug。它给了你一段代码。中间网络断了——你刷新一下,重新问一遍,通常就完事了。
你让一个coding agent修bug。在你看到那段代码之前,Agent已经读了几十个文件,调了几次工具,改了一部分代码,可能还跑过测试。中间网络断了——系统必须知道:哪些内容已经返回给你了?哪些工具已经真正执行了?哪些文件已经被修改了?哪些动作只是模型准备做但还没发生?
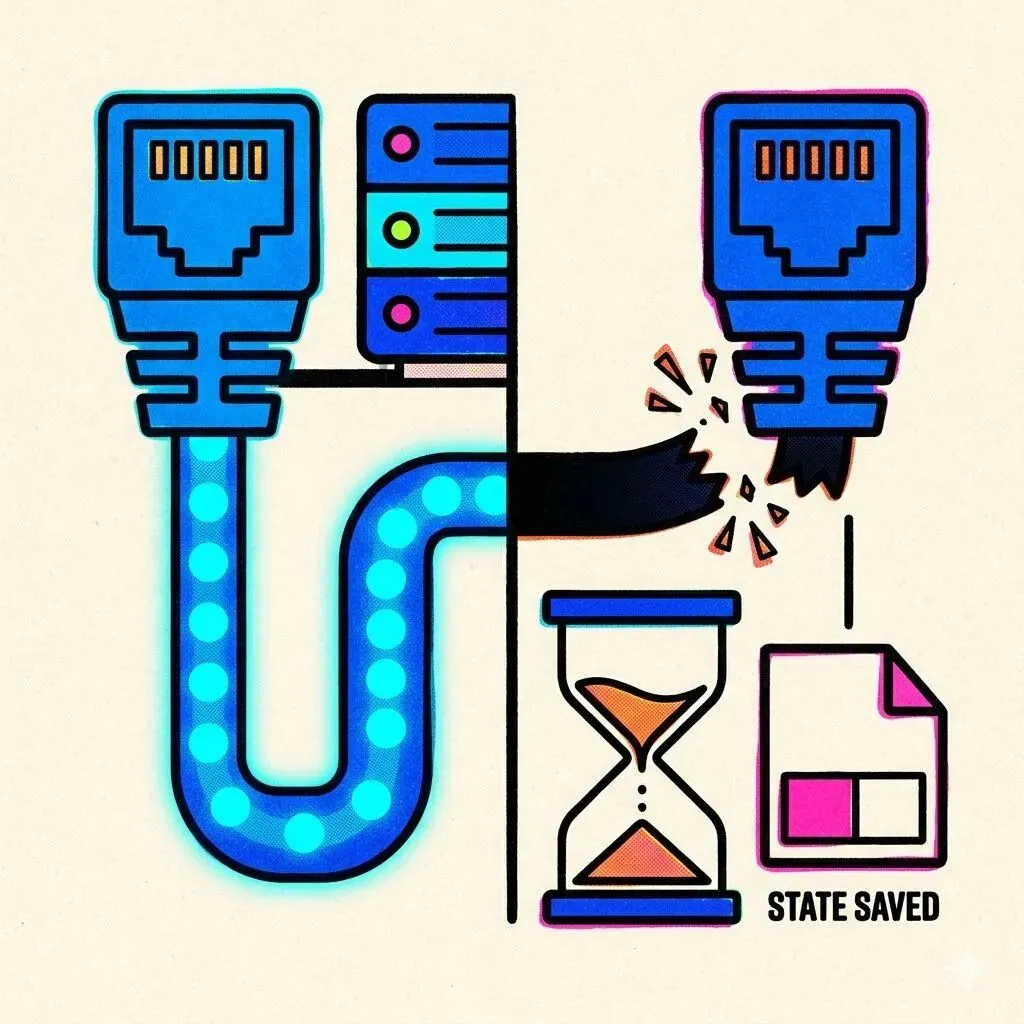
如果这些状态没被保存下来,恢复就会很尴尬。Agent可能不知道该从哪里继续。可能重复执行已经做过的操作。对于一个真正会改代码、跑命令的产品来说——这不是简单的网络问题。这是任务现场有没有被保住的问题。
所以Claude Code修了“连接中断后保留partial response”。这不是一个网络bug的修复。这是在补Agent产品从demo走向生产环境时,遇到的第一道裂缝。
“running tool”——一个spinner背后的信任危机
还有一个更细的修复。工具执行时,界面上的spinner——那个转圈圈的图标——不再卡在“running tool”了。

表面上看,这是一个前端显示bug。但在Agent产品里,这个spinner其实是在回答一个很关键的问题:它到底还在不在做事?
传统聊天机器人不用回答这个问题。它要么在“思考”——模型在生成回复。要么在“回答”——回复已经显示出来了。不需要中间状态。
但Agent不一样。它在读文件、在跑Bash、在执行测试、在远程session里等结果。用户看到“running tool”的时候,真正想知道的是:工具有没有启动?运行到哪一步了?是不是已经失败了?能不能取消?如果已经结束了,为什么界面还显示正在运行?
任何一个状态说不清楚,用户就会失去控制感。你看着那个spinner在转——你不知道它是在干活,还是在卡死,还是已经出错了只是没告诉你。一个工具调用状态的显示bug,在demo里没人注意。但在真实的开发任务里——当Agent花了二十分钟还没告诉你结果的时候——用户对它的信任就从这个spinner开始裂开了。
所以这个修复不是改了一个UI。是补了Agent产品最脆弱的那根神经——用户对“它到底在干什么”的知情权。
权限规则太细,也会拖垮上下文
changelog里最有工程含义的一条,是关于Linux sandbox的。
原文很技术:denyRead/allowRead的glob扫过大目录树后,会把Bash tool description撑得巨大,最后让session不可用。
翻译一下:为了限制Agent能读哪些文件、不能读哪些文件,系统会给它一套权限规则——“这个目录不能看”“那个文件可以读”。但当这些规则太细、太多,并且被塞进工具描述里的时候——安全规则本身,成了拖垮系统的负担。
这对Agent产品来说是一个根本性的矛盾。Agent需要权限系统——它面对的是真实的代码仓库,里面可能有密钥、配置、内部逻辑。系统必须限制它能看什么、能改什么。但权限规则不是免费的。为了让模型知道自己能做什么、不能做什么,这些规则往往会进入上下文或者工具描述。规则越细,说明越长。说明越长,token成本越高,模型处理任务时也越容易被干扰。严重时——整个session不可用。
这说明了一件事:Agent安全不能只是“加限制”。还要考虑这些限制怎么表达、哪些信息需要给模型看、哪些应该留在系统底层静默执行。Agent越能干,权限边界就越重要。权限越细,规则管理就越复杂。规则越复杂,就越容易反噬上下文和执行效率。
这不是一个安全团队能单独解决的问题。这是Agent工程的核心难题。
从“模型强不强”到“系统稳不稳”
这四个修复放在一起看——连接恢复、工具状态、权限膨胀、后台任务——它们没有一个是关于“模型能不能写出更好的代码”的。
它们全部是关于“系统能不能稳定地把任务执行完”。
这才是Agent产品从“惊艳的demo”到“真正能用的工具”之间,最难跨过去的那段路。demo阶段的Agent看起来像魔法——你提一个需求,它自动读文件、调工具、改代码、跑测试。这一切只需要模型够聪明。但真实的开发工作不是这样。真实任务会更长,代码仓库会更大,权限会更多,测试会失败,工具会超时,网络会断,用户会中途切走。

Agent如果要进入日常工作流,就必须处理所有这些不稳定因素。模型仍然重要。没有强模型,Agent不可能完成复杂任务。但只有模型已经不够了。真正进入开发者日常工作流的产品,必须有一套可靠的runtime来支撑模型。这套runtime包括上下文管理、工具调用、权限控制、沙箱、远程session、后台任务、错误恢复和可观测性。它们看起来不像模型发布那样容易传播,也很少有一个漂亮的分数——但它们决定了用户敢不敢把任务交给Agent。
说穿了就一句话:模型要能想。系统要能做。模型生成计划,runtime负责把计划稳定地执行下去。
AI编程产品的下半场,比的不是谁更聪明——是谁更可靠。
评论区聊聊:你用过最靠谱的AI编程工具是哪个?它有没有在关键时刻掉过链子?
