 夜雨聆风
夜雨聆风百度悄悄开源Unlimited OCR,模型总参数量3B,实际激活仅500M,轻量化架构跑出远超主流大模型的识别效果。

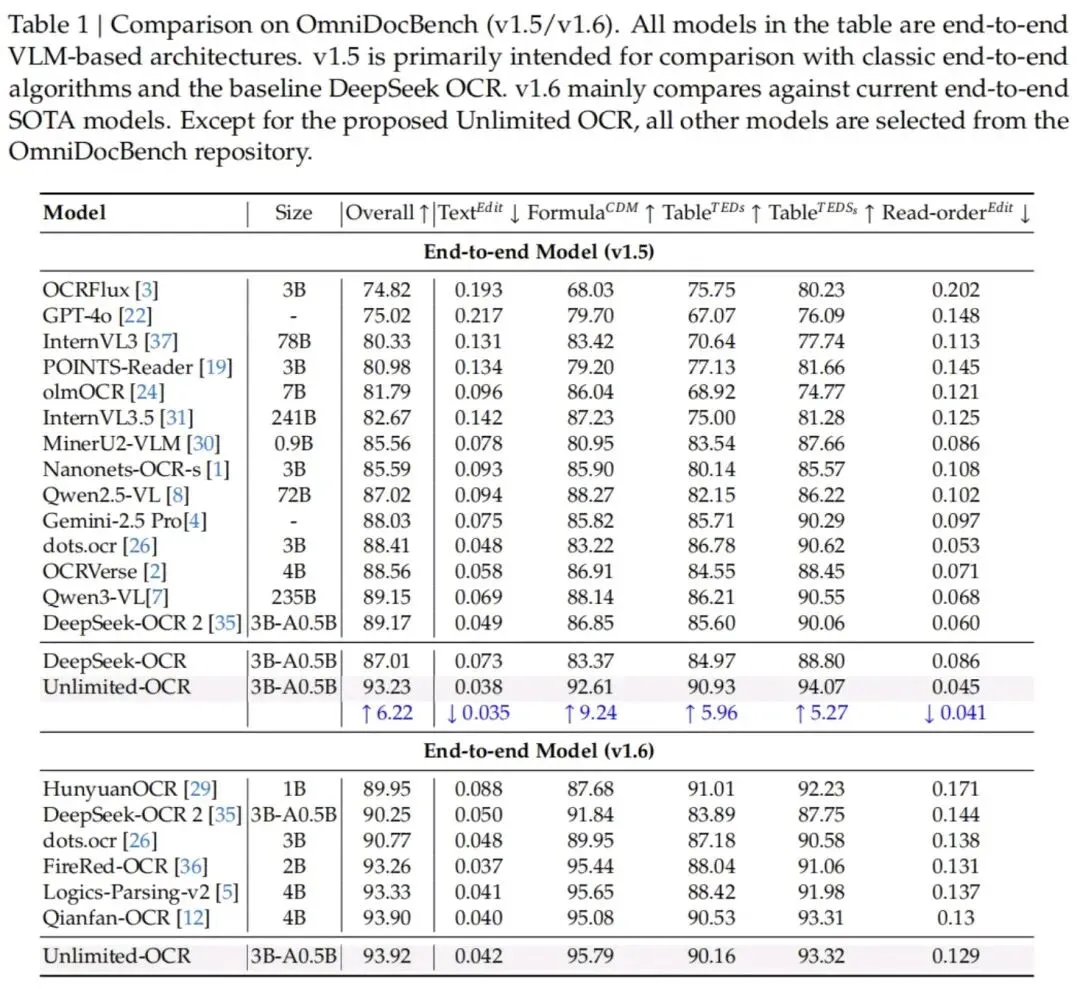
在OmniDocBench评测中,该模型v1.5综合得分93.23%,v1.6提升至93.92%,拿下端到端文档识别新纪录;235B的Qwen3-VL、72B的Qwen2.5-VL、Gemini-2.5 Pro等竞品得分均不足89%,差距明显。
过往OCR处理多页长文档普遍存在缓存膨胀、跨页丢失上下文的缺陷,只能分段识别拼接,越往后推理速度越慢。百度自研R-SWA滑动窗口注意力机制,模仿人类阅读记忆逻辑,模型全程读取完整文档图像信息,输出仅保留最近128组字符,旧内容自动释放,缓存占用恒定不变。
依托这套架构,模型单次推理可一次性解析四十页以上文档,全程不丢上下文、速度稳定。
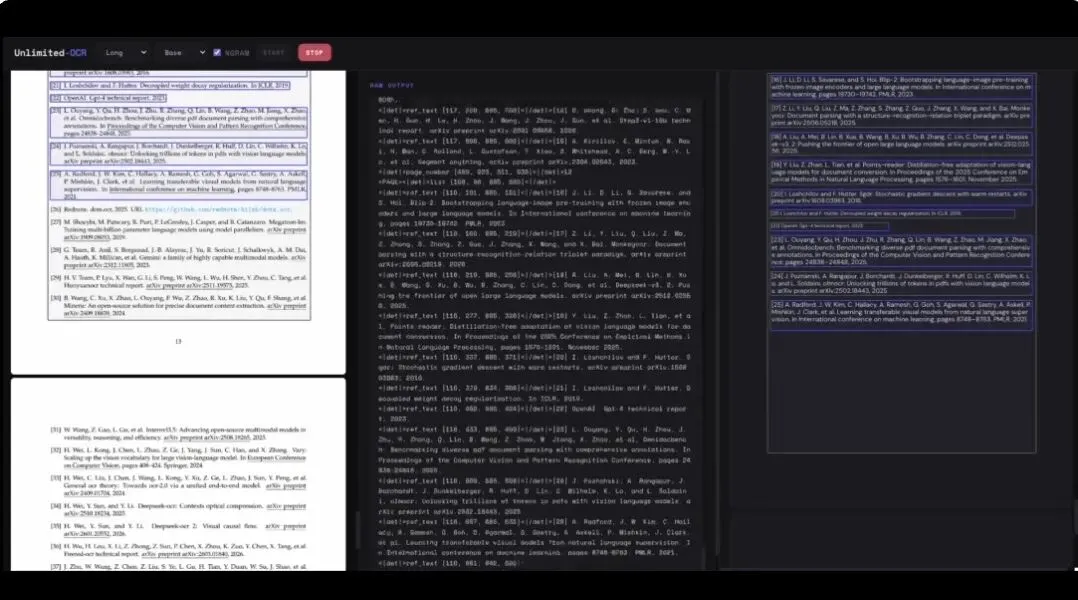
搭配DeepEncoder视觉编码器,单页PDF图像最高压缩16倍,连续处理数十页文件也不会出现画面细节退化。实测四十页文档识别误差极低,重复输出、文字错乱问题很少出现,论文、报刊、PPT等九类文档均可适配,表格、公式识别精度较同类产品大幅提高。
模型权重与完整代码现已同步上架GitHub、HuggingFace,开发者可直接部署。业内结合论文文风、技术脉络与开源仓库致谢信息推测,项目核心负责人为魏浩然。他曾在DeepSeek搭建完整OCR技术线,主导两代DeepSeek OCR研发,如今入驻百度,将长文档解析前沿技术与百度成熟产业底座结合,这套R-SWA机制未来还有望复用在语音转写、翻译等长文本任务中。
