 夜雨聆风
夜雨聆风AI学习目录汇总
1、前言
YOLOv1~3作者是约瑟夫·雷德蒙(Joseph Chet Redmon),他的网站:https://pjreddie.com/ YOLOv1网站:https://pjreddie.com/darknet/yolov1/ YOLOv2网站:https://pjreddie.com/darknet/yolov2/ YOLOv3网站:https://pjreddie.com/darknet/yolo/ YOLOv4作者是Alexeyab(俄),网站:https://github.com/AlexeyAB/darknet YOLOv5作者是Glenn Jocher,网站:https://github.com/ultralytics/yolov5 YOLOX作者是刘松涛,网站:https://gitee.com/alexbd/YOLOX
2、简介
YOLO v3在之前Darknet-19的基础上引入了残差模块,并进一步加深了网络,改进后的网络有53个卷积层,取名为Darknet-53,网络结构图如下所示: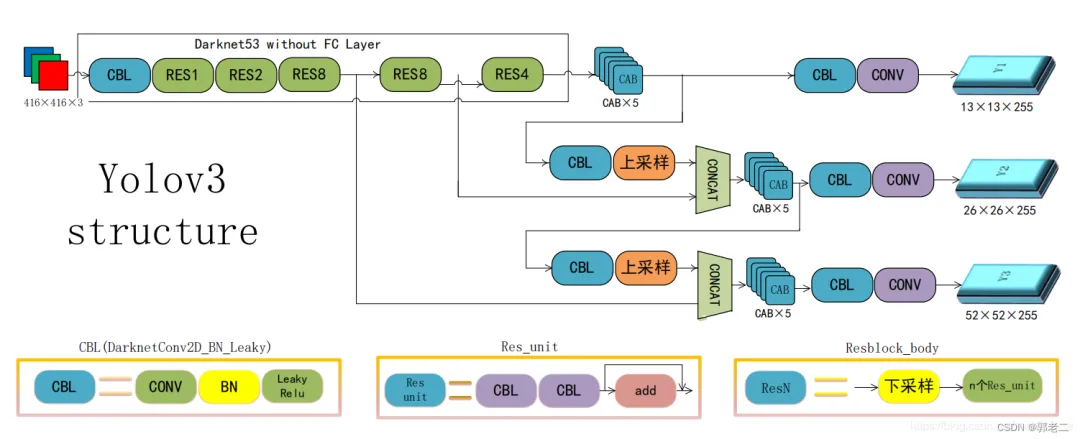
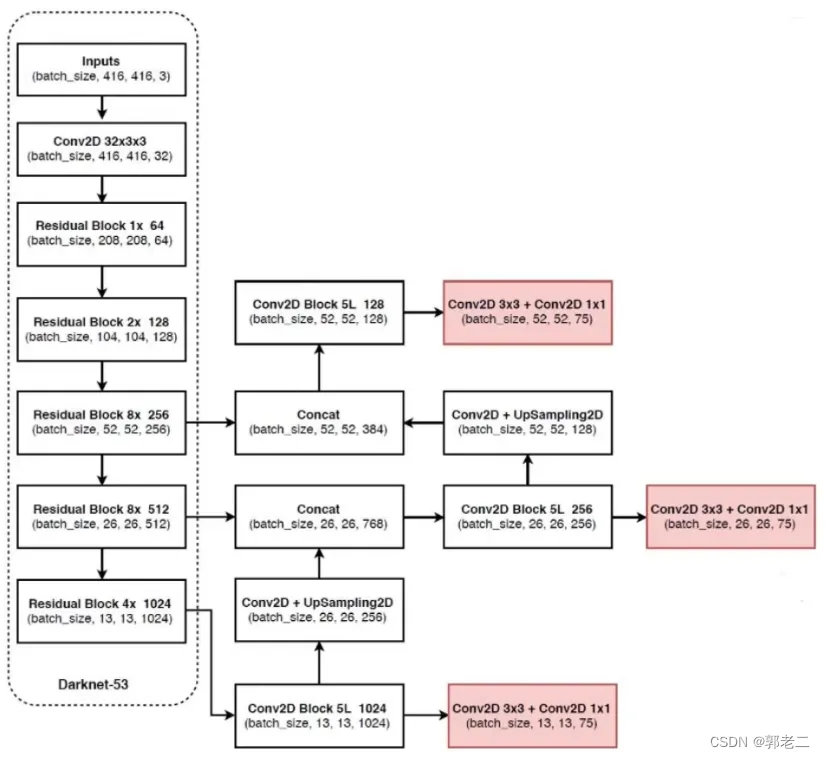
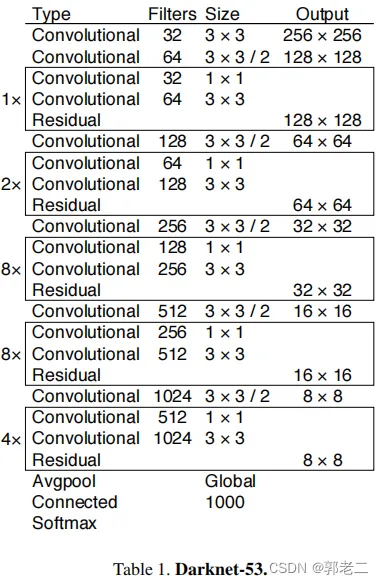
3、YOLOv3的改进
3.1 Yolov3的三个基本组件
3.1.1 CBL
Yolov3网络结构中的最小组件,由卷积层Conv+批归一化Bn+激活函数Leaky ReLU三者组成。 这是为了防止过拟合,在每个卷积层之后加入了一个BN层和一个Leaky ReLU。
3.1.2 Res unit
借鉴Resnet网络中的残差结构,让网络可以构建的更深,同时避免出现梯度消失或爆炸。
3.1.3 ResX
由一个CBL和X个残差组件构成,是Yolov3中的大组件。每个Res模块前面的CBL都起到下采样的作用,因此经过5次Res模块后,得到的特征图是608->304->152->76->38->19大小。
3.2 Concat
张量拼接,会扩充两个张量的维度,例如26×26×256和26×26×512两个张量拼接,结果是26×26×768。 将网络的中间层和后面某一层的上采样进行张量拼接,达到多尺度特征融合的目的。
3.3 Add
张量相加,张量直接相加,不会扩充维度,例如104×104×128和104×104×128相加,结果还是104×104×128。
3.4 去掉池化层
Darknet-53没有采用最大池化层,而是采用步长为2的卷积层进行下采样。
3.5 多尺度预测(先验框)
YOLOv3借鉴了FPN的思想,从不同尺度提取特征。相比YOLOv2,YOLOv3提取最后3层特征图,不仅在每个特征图上分别独立做预测,同时通过将小特征图上采样到与大的特征图相同大小,然后与大的特征图拼接做进一步预测。用维度聚类的思想聚类出9种尺度的anchor box,将9种尺度的anchor box均匀的分配给3种尺度的特征图。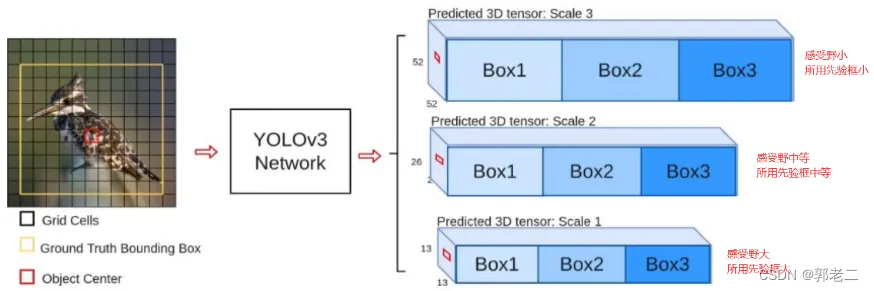
3.6 多标签分类
在YOLOv2中,使用softmax进行分类,softmax会假设这个目标只从属于一个类别,根据网络输出类别的得分最大值,将其归为某一类。然而在一些复杂的场景中,单一目标可能从属于多个类别。比如在一个交通场景中,某目标的种类既属于汽车也属于卡车。
为实现多标签分类,YOLOv3使用了sigmoid函数,如果某一特征图的输出经过该函数处理后的值大于设定阈值(比如0.5),那么就认定该目标框所对应的目标属于该类。
4、相关代码
4.1 python代码
代码地址:https://github.com/ultralytics/Yolov3
4.2 C++代码
这里推荐Yolov4作者的darknetAB代码,代码和原始作者代码相比,进行了很多的优化,如需要运行Yolov3网络,加载cfg时,使用Yolov3.cfg即可 代码地址:https://github.com/AlexeyAB/darknet
4.3 python版本的Tensorrt代码
4.3.1 Tensort中的加速案例
tensort自带的Yolov3加速案例:TensortX/samples/python/Yolov3_onnx 代码讲解文章:https://www.cnblogs.com/shouhuxianjian/p/10550262.html
4.3.2 Github上的tensorrt加速
代码地址:https://github.com/lewes6369/TensorRT-Yolov3
4.4 C++版本的Tensorrt代码
YOLOv4作者Alexey的github:https://github.com/AlexeyAB/darknet 其它的:https://github.com/wang-xinyu/tensorrtx/tree/master/Yolov3
