 夜雨聆风
夜雨聆风
领导让我做一个RAG知识库内容分享。
我这两天一直在整理。
写着写着,我突然意识到一个挺离谱的事。
很多人嘴里说的「我要搭一个 RAG 知识库」,其实翻译成人话就是,把一堆 PDF 扔进向量库,然后接一个聊天框。
完事。
甚至很多 Demo 真的能跑。
你上传一份员工手册,问它年假怎么算,它能回答。
你上传一份产品文档,问它某个接口怎么调,它也能回答。
你再把界面稍微做得漂亮一点,左边是文件列表,右边是聊天窗口,答案下面带一个「根据知识库生成」。
一瞬间,感觉自己已经把公司知识管理这座大山给攻下来了。
我当时第一次看到这类 Demo 的时候,也挺兴奋。
说真的,太爽了。
以前一个新人入职,要到处问人,要翻飞书,要找旧文档,要在群里问一句「这个流程现在到底按哪个版本来」。
现在你把问题丢给聊天框,它啪一下给你一段答案。
这玩意谁看了不迷糊。
但问题是,Demo 阶段越爽,上线之后越容易出事。
因为真实的公司知识,从来不是一堆安安静静躺在文件夹里的 PDF。
它更像一个很吵的菜市场。
有人在卖旧版制度,有人在喊新版口径,有人拿着半年前的会议纪要说这个才算数,有人把临时方案写在聊天记录里,还有人把最关键的例外条件塞在表格备注里。
然后你让一个大模型进去逛一圈,让它回来给你一个准确答案。
你觉得它真的不会迷路吗?
我现在越来越觉得,RAG 知识库这件事,最危险的误解不是技术门槛太高。
而是大家把它想得太简单。
不是说向量库不重要。
Milvus、Qdrant、Weaviate、Pinecone、PostgreSQL 加 pgvector,这些都很重要。
也不是说框架不重要。
LangChain、LlamaIndex、Haystack、Dify、FastGPT,这些当然能帮你少写很多胶水代码。
但如果你一上来就纠结选哪个向量库,选哪个 embedding,选哪个框架,我觉得大概率方向已经有点偏了。
真正的问题应该是。
你的知识到底干不干净。
谁能看。
哪份材料有效。
哪份材料已经过期。
用户会问什么。
什么答案算对。
答错了谁负责。
这些问题听起来一点都不酷。
甚至有点烦。
但就是这些不酷的问题,决定了你的 RAG 到底是知识库,还是一个会聊天的文件夹。
会聊天的文件夹。
这个词我越想越觉得准确。
文件夹本来就能存东西,现在它会说话了,好像很厉害。
但如果里面装的是过期材料、重复材料、权限不明的材料、互相冲突的材料,那它越会说话,越危险。
因为它会把混乱讲得很顺。
这才是最吓人的地方。
很多朋友可能不知道,RAG 这个词真正进入主流视野,大概要追到 2020 年 Patrick Lewis 那篇论文,名字叫 Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks。
当时这篇论文想解决的问题很朴素。
大模型确实能记住很多东西,但它记住的东西,更新不了,查不准,也不好给出处。
世界会变。
制度会变。
产品价格会变。
法律条文会变。
客户状态会变。
但模型参数不会因为你公司今天下午三点改了一个报销制度,就突然自己长出新记忆。
所以 RAG 最早的精神,其实不是炫技。
它是在承认一件事。
模型不应该把所有知识都背下来。
它应该在需要的时候,去外部世界里找证据。
这个思路太对了。
它也特别适合企业。
因为企业知识有权限,有版本,有来源,有生效日期,有责任人。
这些东西你不可能全塞进模型参数里。
你要把它们放在外部系统里,按权限检索,按来源引用,按版本更新。
这才像一个企业系统。
但后来很多人做着做着,就把这件事简化成了三步。
切块。
向量化。
top-k 检索。
然后,就开始快乐了。
这套流程不是错。
它是入门。
就像你学做饭,第一步当然是把菜洗了切了扔锅里。
但如果你真要开餐厅,你还得管进货、冷链、后厨卫生、菜单、出餐速度、客诉、食安检查。
RAG 也是一样。
PDF 切块加向量库,只是把菜扔进锅里。
真正麻烦的,是后面那一整套。
我举几个特别真实的坑。
一个制度文档里,年假规则写在第三章,适用范围写在第二章,例外审批写在第七章。
你如果按固定 500 token 切块,很可能模型只拿到了第三章那一小段。
它看起来答对了。
但它漏了例外条件。
这类错误最难发现,因为答案不是完全错,而是只错一点点。
但业务上,很多事故就是这一点点造成的。
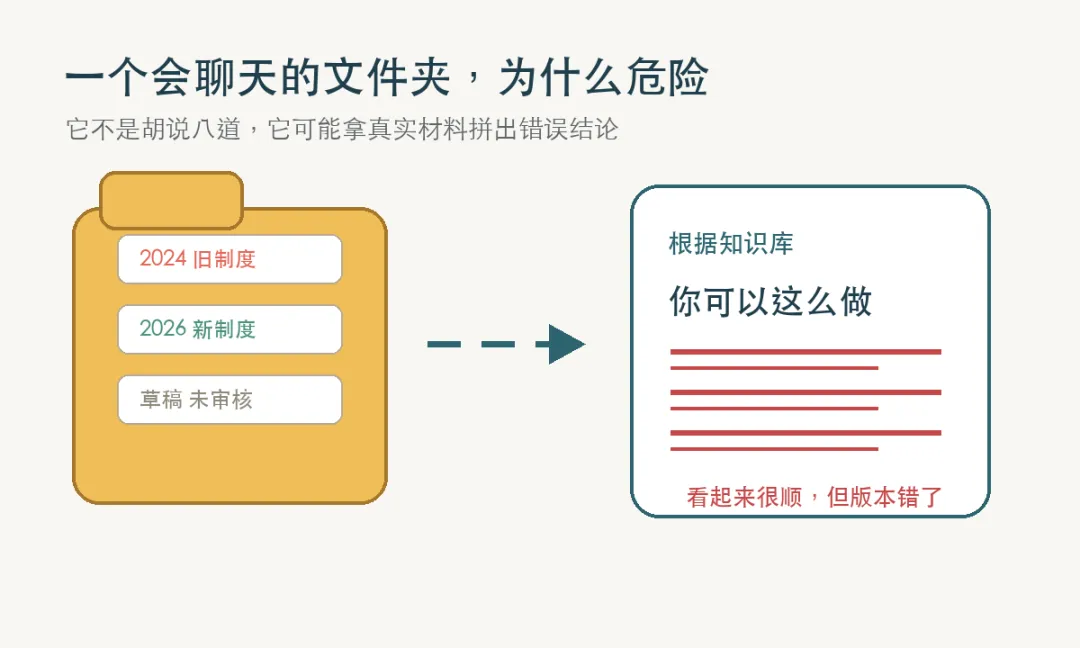
再比如,一个公司有三份销售政策。
2024 版、2025 版、2026 版。
文件名都差不多,里面很多句子也差不多。
向量检索一看,哎呀,都挺相关。
于是模型把 2024 版的折扣政策和 2026 版的审批流程拼到一起,生成了一个特别自然、特别像人的答案。
你敢信???
最离谱的是,用户看了还会觉得很可信。
因为它不是瞎编的。
它每句话都能在某个文档里找到影子。
只是它把不该放在一起的东西放在一起了。
这尼玛就是 RAG 幻觉最阴险的地方。
它不是凭空造假。
它是拿真实材料,拼出一个错误结论。
还有权限问题。
HR 的绩效制度能不能被销售看到。
客户 A 的材料能不能被客户 B 的项目组搜到。
离职员工相关的材料是不是还在索引里。
某个文档从共享改成私密之后,向量库里的 chunk 有没有同步删除。
这些问题,平时大家不爱聊。
因为聊起来很麻烦。
但这恰恰是企业 RAG 和个人知识库最大的区别。
个人知识库错了,你顶多骂一句自己笨。
企业知识库错了,它可能会误导客服,误导销售,误导法务,误导风控。
有时候还会泄密。
安全,安全,还是安全。
说到这里,很多人可能会有点烦。
不是哥们,我就想搭个知识库,怎么你一上来就给我讲这么多治理、权限、评估、审计。
我非常理解这种感觉。
你不是专门做搜索系统的。
你不是专门做数据治理的。
你可能只是一个业务负责人,或者一个产品经理,或者一个被老板问「我们能不能也搞个内部知识助手」的技术同学。
你想要的是一个能跑起来的东西。
最好下周就能给老板看。
我懂。
真的懂。
所以我不是说你不能用 Dify,也不是说你不能先用 FastGPT 搭一个原型。
正相反,我觉得第一版就应该快。
先把 50 份最干净、最常用、最没有争议的文档丢进去,做一个内部问答试点。
让真实用户去问。
看他们到底问什么。
看他们会不会接受答案。
看它能不能减少重复咨询。
这一步很重要。
但你心里要知道,这叫业务验证,不叫企业知识基础设施。
别把试吃摊当中央厨房。
这个比喻有点土,但我觉得挺准。
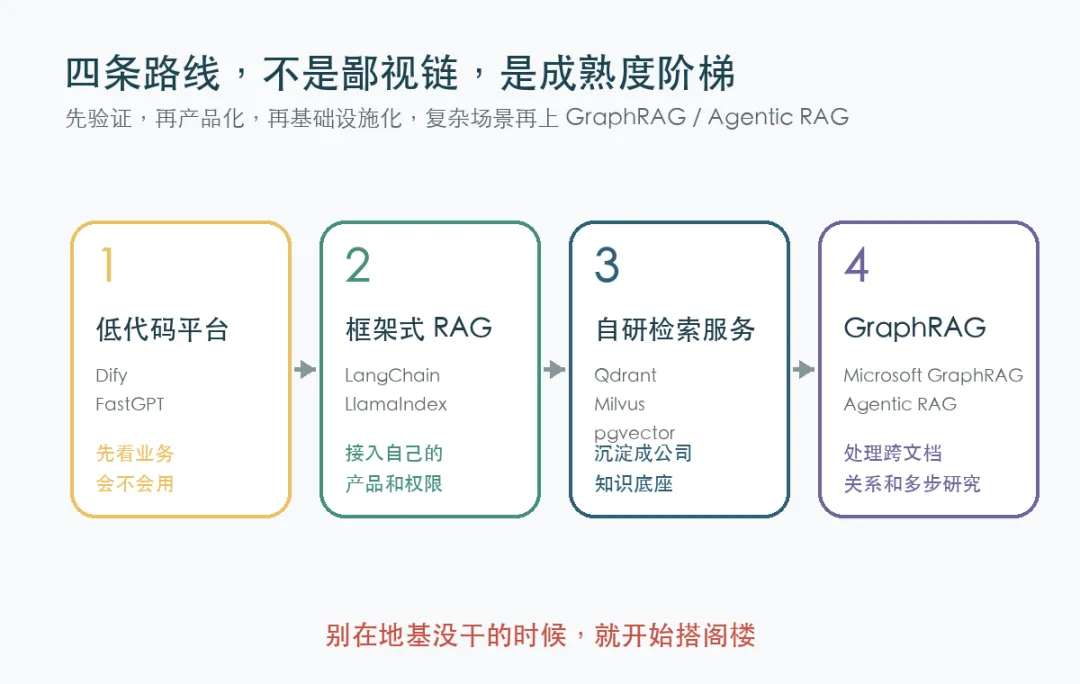
低代码平台像试吃摊。
优点是快,东西能端出来,大家一吃就知道有没有味道。
LangChain、LlamaIndex、Haystack 这类框架,像你开始租了一个后厨,有炉灶,有工具,有食材处理台,可以按自己的菜单做菜。
自研检索服务,像你真的在建中央厨房。
进货、仓储、冷链、分拣、出餐、追溯、质检,全都得有。
GraphRAG 和 Agentic RAG 呢,像你开始做复杂宴席。
不只是炒一个菜,而是要设计菜单、协调节奏、理解客人的口味,还要知道每道菜之间怎么呼应。
这四条路没有谁绝对高级。
只有适合不适合。
如果你只是想验证一个客服 FAQ,直接上低代码平台,挺好。
如果你要把 RAG 嵌进自己产品,接账号体系、权限系统、业务数据库,那就别只停在平台配置,框架式开发会更稳。
如果你要给整个公司做统一知识底座,客服、销售、法务、研发都要用,那检索服务就应该变成基础设施。
如果你的问题经常是「这些材料共同说明了什么」,「这个项目失败背后有哪些组织关系」,「一批论文之间形成了哪些主题社区」,那 GraphRAG 才开始有价值。
顺序很重要。
不是所有项目都要一步到 GraphRAG。
就像你刚学走路,没必要先买一双职业马拉松鞋。
回到具体怎么做这块。
如果今天屏幕前的你,真的要从零搭一个 RAG 知识库,我会建议你别从工具开始。
从三句话开始。
谁用它。
问什么。
不能答什么。
这三句话写不清楚,后面全是糊的。
比如你说,我要做公司知识库。
这句话没用。
公司知识太大了。
HR 制度、销售话术、产品文档、研发规范、合同模板、客户工单,全都叫公司知识。
但客服、销售、研发、法务、HR,他们的问题完全不一样。
客服要的是处理步骤和推荐话术。
研发要的是代码路径和架构决策。
法务要的是条款依据和风险提示。
销售要的是客户场景和产品卖点。
你不能让他们都问同一个聊天框,然后指望一个 prompt 包治百病。
AI 不是祖传膏药。
所以第一版要窄。
窄到有点不好意思。
比如只做「新人入职制度问答」。
只做「产品 A 的售后政策问答」。
只做「客服常见故障排查」。
越窄,越容易做对。
越容易做对,越容易建立信任。
信任起来了,再扩。
然后是知识盘点。
这一步特别无聊,但特别关键。
你要把材料分成三类。
能用的。
待修的。
禁用的。
能用的材料,版本明确,来源可信,权限清楚,还在生效。
待修的材料,内容有价值,但格式乱、版本不明、重复冲突、扫描质量差。
禁用的材料,过期制度、草稿、个人笔记、未审核结论、敏感数据没脱敏。
这一步做完,你会突然发现一个很残酷的事实。
很多公司不是没有知识。
是知识没有身份。
没有 owner,没有版本,没有生效日期,没有过期时间,没有权限边界。
像一堆没有身份证的人挤在火车站。
你当然可以让 RAG 去问他们。
但它问出来的东西,你敢直接拿来决策吗?
我不敢。
然后才轮到切分。
很多人喜欢问 chunk size 设多少。
300 token 还是 500 token。
要不要 overlap。
这问题当然有价值,但它不是起点。
真正的原则是,把文档切成还能被理解的知识单元。
这句话很重要。
RAG 不是把文档切碎。
RAG 是把文档切成离开原文以后,仍然能被理解、定位、验证的小块。
如果一个 chunk 里只有「该政策适用于上述客户」,那它就是一张失忆的纸条。
上述客户是谁。
哪份政策。
哪个版本。
什么时候生效。
全没了。
这种 chunk 丢进向量库,就像把一页纸从书里撕下来,扔进风里,然后指望模型在风里把它拼回去。
想想就很玄学。
Anthropic 之前提过 Contextual Retrieval,我很喜欢这个方向。
简单讲,就是给每个 chunk 补一点上下文,让它知道自己来自哪份文档、哪一章、讲什么主题。
这不是什么玄妙的新概念。
更像给每张纸条背后写一行备注。
「本段来自 2026 年销售费用报销制度第 3 章,适用于中国区销售团队,讨论住宿费上限和审批例外」
你看。
一下就不失忆了。
这就是好 RAG 很多时候真正的工作。
不是让模型更聪明。
是让知识别失忆。
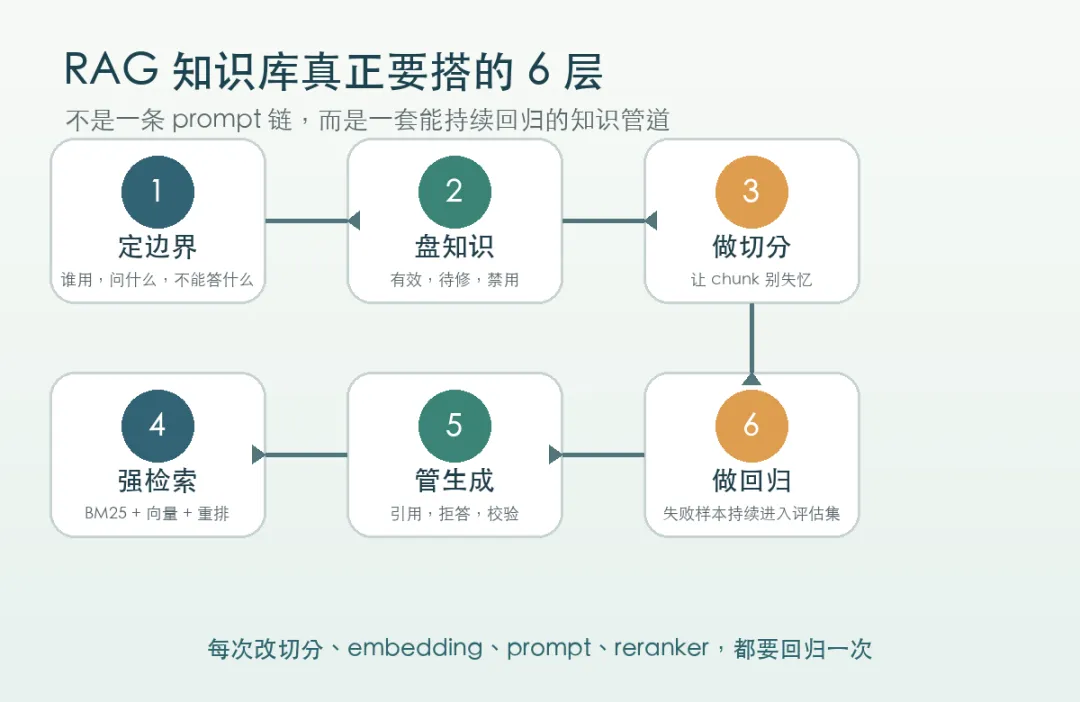
再往后,检索也不能只靠一路 top-k。
向量检索很擅长语义相似,但它不是什么都擅长。
用户问「ESP-2026-17 这条规则」,关键词可能比语义更重要。
用户问「Q3 续费率低于 80% 的客户有哪些」,这已经不是普通文档问答了,它要结构化数据,要时间范围,要指标定义,还要权限过滤。
所以生产里的 RAG,大概率会走向混合检索。
BM25 管关键词。
向量检索管语义。
metadata filter 管权限、版本、部门、时间。
reranker 管谁排前面。
生成模型管把证据组织成人话。
听起来复杂对吧。
但你想想看,人类真的查资料,也是这么干的。
你不会只在脑子里凭感觉搜。
你会先确定范围,再查关键词,再翻相关材料,再判断哪份更可信,攒够证据才写答案。
RAG 只是在把这个过程工程化。
这也是为什么我一直觉得,RAG 走到深处,会越来越像搜索系统、知识管理系统和审计系统的混合体。
它表面是聊天框。
底下是管道。
而管道比聊天框重要得多。
还有评估。
这块我必须多说几句。
没有评估集,就没有 RAG 知识库。
只有感觉。
很多团队的评估方式特别朴素。
老板问了三个问题。
都答得不错。
上线。
这太刺激了。
真的太刺激了。
你至少要有一批真实问题。
50 个也行,100 个更好。
每个问题都要知道标准答案是什么,应该召回哪份文档,什么情况下应该拒答,什么用户角色能看。
然后每次你改 chunk 策略,改 embedding,改 prompt,改 reranker,都跑一遍。
如果召回变差了,就别上线。
如果引用错了,就别上线。
如果没证据还硬答,就别上线。
这听起来像软件测试。
没错。
RAG 不是一次性写完的 prompt。
它是一个持续回归的系统。
用户点踩也不是情绪反馈。
那是训练样本。
线上失败也不是丢人的事。
那是知识库长大的材料。
一个成熟的 RAG 知识库,不是永远不犯错。
而是它犯过的错,不会反复犯。
这话听着有点刺耳,但我觉得非常重要。
如果你的系统今天答错,明天还答错,下周用户又用另一种问法问,它继续答错。
那它不是知识库。
它只是一个很有礼貌的复读机。
说到这里,我突然想起一个很老的东西。
图书馆。
你想想看,图书馆厉害的地方,不是它有书。
谁家还没几本书呢。
图书馆厉害的地方,是书被分类,被编号,被借阅,被归还,被维护,被淘汰。
一本书什么时候出版,作者是谁,属于哪个主题,放在哪个架子,谁借走了,什么时候归还,是否需要下架。
这些看起来不性感的秩序,才让图书馆成为图书馆。
RAG 知识库也是一样。
它厉害的地方,不是它有文档。
而是每份知识都有身份,有位置,有边界,有来源,有更新机制,有责任人。
没有这些,它只是仓库。
仓库再会说话,也还是仓库。
甚至更麻烦。
因为仓库不会自信地给你错误建议。
会聊天的仓库会。
我自己的判断是,未来几年,RAG 会变成几乎所有企业 AI 应用的默认底座。
客服助手会用。
销售助手会用。
研发助手会用。
法务助手会用。
风控助手会用。
但大多数成功的产品,可能不会天天把 RAG 挂在嘴边。
就像数据库很重要,但普通用户不会说,我今天用了一个 PostgreSQL 应用。
他只会说,这个系统挺好用。
RAG 也会慢慢隐身。
真正留下来的,不是哪个框架的名字,而是一套组织知识的能力。
所以如果你现在想搭一个 RAG 知识库,我给一个不成熟的路线。
说实话我也还在摸索,不敢说这是唯一答案。
但如果让我重新从零做,我会这么干。
第 0 周,不选工具。
只定边界。
谁用,问什么,不能答什么,错了谁负责。
第 1 周,做知识盘点。
只选最干净的 50 到 200 份材料。
脏的先别进。
别舍不得。
脏知识进系统,就会变成脏答案。
第 2 周,做最小可用链路。
解析、切分、embedding、向量库、基础检索、引用回答。
这一步别追求完美,先跑起来。
第 3 周,做评估集。
把真实问题沉下来。
哪些应该答,哪些应该拒答,哪些必须引用哪份材料。
第 4 周,增强检索。
加 BM25,加 metadata filter,加 reranker,加必要的查询改写。
第 5 周,接权限和日志。
谁问了什么,系统检索了什么,输出了什么,都要能追。
第 6 周以后,灰度上线。
收集失败样本,持续回归。
然后再考虑 GraphRAG、Agentic RAG、多库路由、结构化数据。
这个过程一开始可能会很笨。
甚至会让你怀疑,我直接把 PDF 扔进 Dify 不是挺好吗,为什么要搞这么多。
但只要你经历过一次线上误答,一次权限串数据,一次旧制度被当成新制度引用,你就会明白。
这些麻烦不是额外成本。
这些麻烦就是 RAG 本身。
说到底,搭 RAG 知识库,真正要搭的不是一个聊天框。
而是一套组织记忆的秩序。
这件事听起来没有「三分钟搭建企业知识库」那么爽。
但它更真实。
也更有长期价值。
我有时候觉得,AI 这一波最有意思的地方,不是它让电脑更会说话。
而是它逼我们重新审视,自己到底知道什么。
哪些知识是真的。
哪些知识过期了。
哪些知识只是某个人脑子里的经验。
哪些知识被锁在聊天记录和旧文档里,从来没有被好好整理过。
RAG 像一面镜子。
你把组织知识照进去。
它不会自动把混乱变成秩序。
它只会把混乱放大。
但如果你愿意认真整理,它也会把秩序放大。
这就是我被 RAG 打动的地方。
它不是让模型知道更多。
它是让我们重新学会,怎么认真对待自己已经知道的东西。
所以,别急着问向量库哪个好。
先回去看看你的文件夹。
看看那些旧制度、旧表格、旧会议纪要、旧流程图。
看看它们有没有版本,有没有 owner,有没有生效日期,有没有权限。
看看它们是不是真的值得被一个会说话的系统引用。
如果答案是否定的,也别灰心。
这恰好是起点。
毕竟,能做的,还是那句话。
磨平一点点信息差。
哪怕,只是先把一个会聊天的文件夹,慢慢变成一个真正的知识库。
那也挺好。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标。
谢谢你看我的文章,我们,下次再见。
