 夜雨聆风
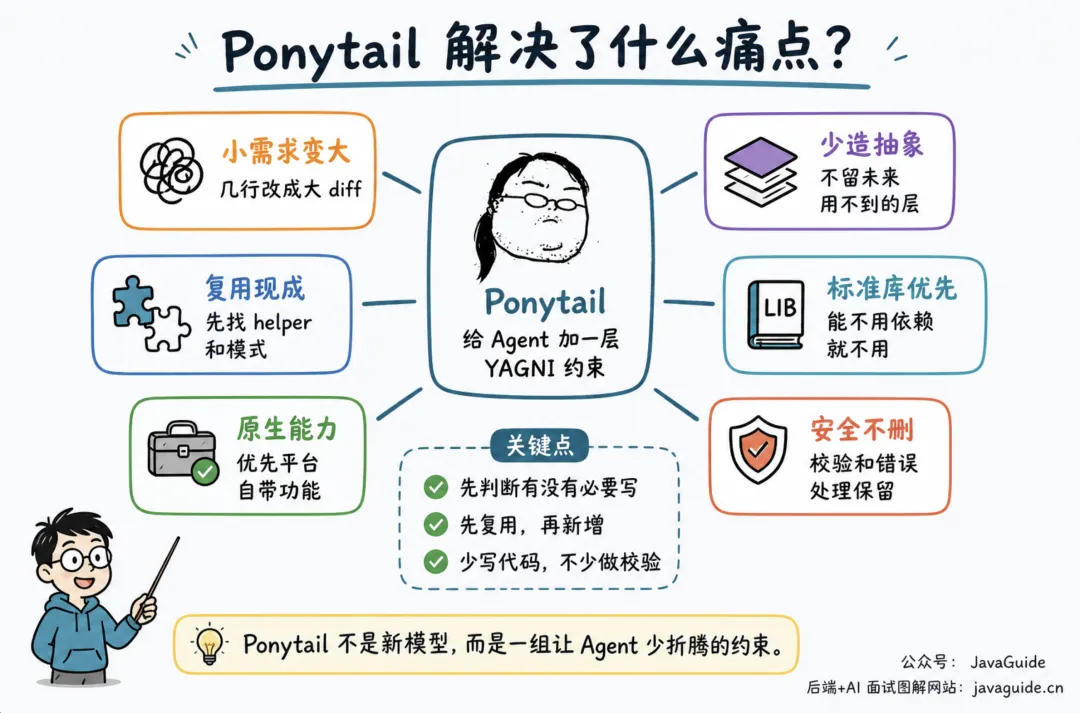
夜雨聆风AI Coding Agent 的常见问题是把小需求做大。
本来只该动几行的任务,它会先补结构,再补解释,最后顺手加几个“以后可能用得上”的文件。单看每一步都说得过去,合起来就是大 diff。
最近爆火的 Ponytail 项目解决的就是这类问题。它给 Claude Code、Codex 这类工具加一层 YAGNI 约束:先找现成代码、标准库和平台能力,再决定要不要写新东西。它由规则、Skills 和 lifecycle hooks 组成。
我第一次注意到 Ponytail,是因为它 Star 涨得特别快。刚开始只是觉得这个项目挺火;后面又看到球友在群里分享说用着还不错,才去认真看了一下。
目前这个项目在 Github 上已经有 56.2k+ Star了。
它的 Logo 是一个不爱废话、懒得解释、只想写最少代码把事情做完的老工程师形象。

先让 Agent 少折腾
这组检查会固定进入 Agent 的工作过程,不用每次手动补一句“少写点”。

写代码前先过一遍 lazy ladder:
这个东西真要写吗?不需要就跳过。 代码库里已经有类似 helper、类型、模式吗?先复用。 标准库能做吗?用标准库。 平台原生能力能做吗?用原生能力。 已安装依赖能做吗?用现成依赖。 一行能解决吗?就一行。 到这一步才写最小可用实现。
这套东西听起来像少写代码版 checklist,实际用起来更像在改 Agent 的第一反应。
普通 Agent 接到需求后,经常会先把问题摊开:新文件、新 helper、新 wrapper、新配置,再加一段看起来很负责的说明。Ponytail 会把顺序往前拨一下:先查项目里有没有现成写法,再看标准库和原生能力,最后才动手写最小实现。
我自己开着用了一阵子,整体体感还不错。它不能保证每次都少写,也不会替你判断业务取舍,但小修小补时,Agent 确实没那么爱把 diff 铺开。
安装方式
Codex CLI 的安装是两步:
codex plugin marketplace add DietrichGebert/ponytailcodex如果团队想固定版本,也可以指定 Git ref:
codex plugin marketplace add DietrichGebert/ponytail --ref v4.8.3然后在 Codex 里打开 /plugins 安装 Ponytail;再到 /hooks 检查并信任 lifecycle hooks,最后新开一个 thread。
这里别一路点信任。Ponytail 是第三方插件,包含会在本机执行的 Node.js hooks;安装或更新后,至少看一下 .codex-plugin/plugin.json、hooks/claude-codex-hooks.json 和对应脚本。Codex 会按 hook 哈希记录信任状态,内容变了会重新要求审查。
Claude Code 里也可以直接输入:
/plugin marketplace add DietrichGebert/ponytail/plugin install ponytail@ponytail懒一点的话,可以直接让 Claude Code 或 Codex 帮你跑这些安装命令,或者让它带你打开 /plugins。但 /hooks 里的信任确认最好自己看,别让 Agent 替你一路确认;hook 脚本会在本机执行,至少扫一眼它到底跑了什么。

项目支持很多 Agent,但能力不完全相同。Codex、Claude Code 可以用插件、Skills 和 hooks;Cursor、Windsurf、Cline、Aider、Kiro、Zed 等更多是加载规则文件,未必有 always-on hook 和审查命令。
Codex 中常用 @ 调用:
@ponytail lite|full|ultra|off:切换强度,默认是full。@ponytail-review:在 Codex 里按 diff 找过度设计。@ponytail-audit:扫整个仓库,列出能删、能复用标准库、能换原生能力的地方。@ponytail-gain:查看项目 benchmark 里的收益说明。

Claude Code、OpenCode 这类宿主则用 Slash Command,比如 /ponytail、/ponytail-review、/ponytail-audit。
它靠什么生效
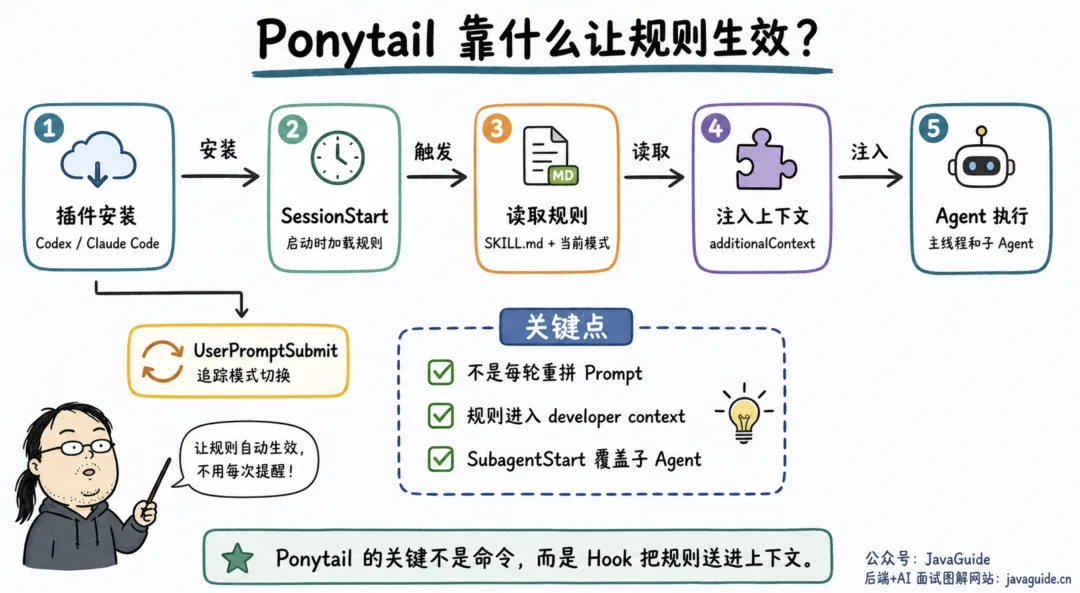
安装后,Ponytail 主要靠 Codex lifecycle hooks 生效。SessionStart 会在启动、恢复、清空、压缩上下文时加载规则;UserPromptSubmit 负责追踪 @ponytail、/ponytail、$ponytail 这类模式切换;SubagentStart 则把同一套规则交给子 Agent。
真正影响模型的内容来自 hookSpecificOutput.additionalContext。systemMessage: PONYTAIL:<MODE> 更像界面或事件流里的模式提示,规则本身会作为额外 developer context 注入。
这也是 v4.8.3 值得注意的地方。之前主线程能吃到 Ponytail 规则,Task 派生出来的子 Agent 不一定能吃到;现在 SubagentStart 会把同一套规则也塞给子 Agent。
为什么它会影响输出质量
模型写代码时,最终产物很受上下文里的评价标准影响。
如果上下文一直暗示“完整、可扩展、专业”,它很容易补出接口、配置、封装和长解释。Ponytail 反过来强化另一套评价标准:先读代码,查调用方,复用已有东西,优先标准库和平台能力,安全、校验、可访问性不能删,复杂逻辑留一个最小可运行检查。
这会改变 Agent 的搜索顺序。
日期输入优先想到 <input type="date">,颜色选择优先想到 <input type="color">,文件上传优先想到平台原生能力。后端小改动也会先查现有 service、router、helper,而不是另起一个“更漂亮”的抽象。
少生成文件、少制造无关 diff,通常会降低后续读取和审查的上下文负担。但它不保证总 token 一定下降:模型为了判断“能不能不写”,也可能花掉更多推理 token。Ponytail README 也提醒过,成本和延迟下降只是部分模型上的副作用。
我自己的体感判断也是偏正面的:开着之后,Agent 的回答没那么爱铺开,返工少一些,尤其是“你先别给我整套架构”的任务。这个判断只算使用体感,不是同仓库、同 prompt、同模型跑出来的严肃对照实验。
效果如何
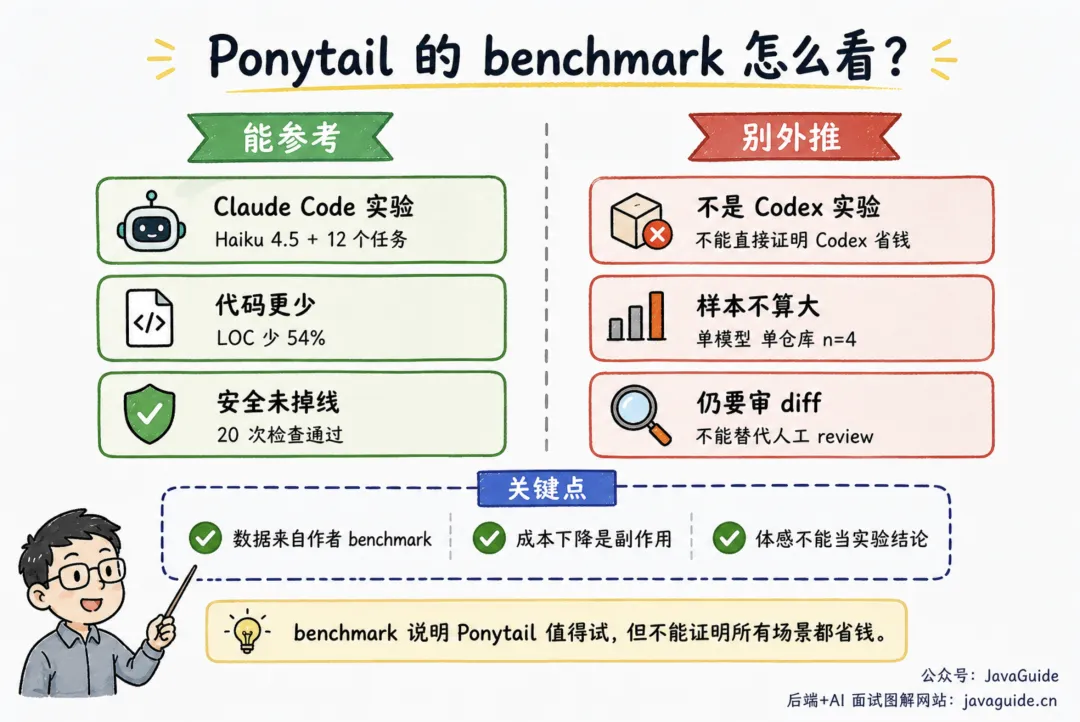
Ponytail 的 README 里有 benchmark,可以作为参考。不过,不要拿它证明用了就一定省 token、一定更便宜。
当前较可信的一组实验,跑在 Claude Code 2.1.177 和 Haiku 4.5 上,测试仓库是固定版本的 tiangolo/full-stack-fastapi-template。实验包含 12 个功能任务,每组运行 n=4。
按 README 的汇总结果,Ponytail 相比无 skill baseline:新增代码行数少 54%,tokens 少 22%,cost 少 20%,time 少 27%。
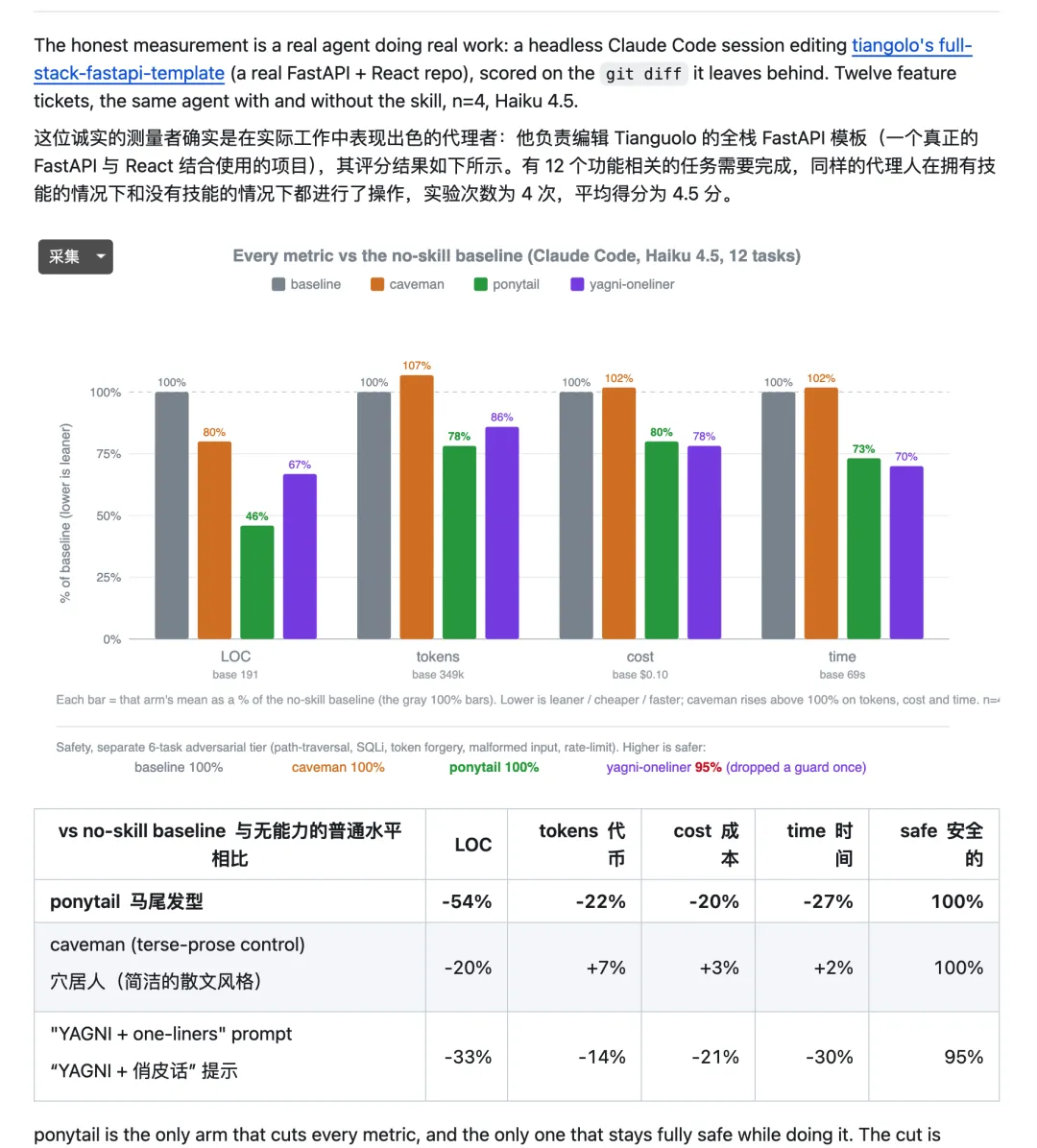
早期单次生成 benchmark 写过 80-94% less code,后来 README 自己把这个说法收回了一截:旧 baseline 偏聊天型,解释、选项和样板把数字抬高了。
现在这版说法更接近我愿意相信的范围:原生能力能接住的任务收益很大,已经很小的 CRUD 基本没多少空间。
另外,Ponytail 和 RTK 可以一起搭配使用,额度消耗确实变慢,效果很好。而且,@ponytail-audit 对整理 vibe-coded 代码库有帮助。
它适合谁
如果你经常让 Codex、Claude Code 或 OpenCode 改现有项目,Ponytail 很值得试。它尤其适合小需求变大 diff、Agent 总想加依赖、项目里有重复 helper 和空抽象这类场景。
我不建议把它无脑开到 ultra 后丢给所有任务。
团队项目里,可读性、统一风格和后续维护有时比少几行更重要。Ponytail 明确说不能删输入校验、安全措施、可访问性和防数据丢失的错误处理,但它也不能保证每次都更正确或更安全。你还是要像审普通 Agent 产物一样审 diff。
安装时还有个细节:Claude Code 和 Codex 插件依赖 Node.js lifecycle hooks。README 提醒过,node 要在非交互 shell 的 PATH 里。用 nvm、Nix 或特殊 shell 环境时,这个点最好先查,不然 rules 还在,always-on 激活可能没跑起来。
写在最后
Ponytail 是一个给 Claude Code、Codex 这类 AI coding agent 用的约束插件,核心作用是把 YAGNI、标准库优先、原生能力优先这些工程习惯固定塞进 Agent 的工作过程里。
它主要解决 Agent 过度实现的问题:小需求变大 diff、顺手加依赖、抽无用层、写未来用不到的配置。
如果你经常用 Agent 改现有项目,Ponytail 值得放进常用插件列表;只是最后能不能合并,仍然要看 diff。
项目地址:https://github.com/DietrichGebert/ponytail

⭐️推荐阅读:
AIGuide:AI 应用开发、AI 编程实战与面试指南(对标 JavaGuide,完全开源免费) 《SpringAI 智能面试平台》(2.0 版本已开源)(Star 数量 2.1k+)
