 夜雨聆风
夜雨聆风商业地产 × AI数据分析
AI 不会替代商业地产的运营人。
但它能让运营人从琐碎的案头工作中抬起头来,去思考更重要的事情。
做商业地产运营的朋友,大概都有过这种时刻:
“ERP 系统导出的月报,单位乱得像菜市场——"元""万元""万元/月"混在一起;千分符把数字搅成浆糊;空值和 N/A 随处潜伏。
竞品调研的 Excel 更离谱,星巴克一个牌子能冒出七八种写法,日期格式从 "2025.3" 到 "5月中" 无奇不有。
小红书爬下来的热搜呢?"始祖乌""星巴充""間鱼"……OCR 识别错误加上繁简混用,看得人脑壳疼。”
三个数据源,47 处脏数据标记。这不是夸张,这是真实发生的事。而且这还只是冰山一角——每次出报告之前,光是洗数据就要耗掉大半天。

▲ 本次演示的数据规模:3 个异构数据源、22 家有效商户、60 条热搜词条
01 / 三大异构数据源,各有各的"脏"
我们面对的从来不是一张干净的数据表,而是三股完全不同来源、不同格式、不同质量的数据流。
A 表 · 商户扣率月报 ——来自你自己的 ERP 系统。看起来最靠谱,实际上坑最多:

▲ A 表(商户月报)共发现 23处脏数据 — 单位混用、千分符干扰、品牌名同名词异写
金额单位混用:"元""万元""万元/月" 三种单位混在一个列里 千分符干扰:"1,250,000" 这种带逗号的数字直接导致计算报错 空值陷阱:N/A、零值、空格——每个都代表不同含义 品牌名称同名词异写:"喜茶·国金店" 和 "喜茶" 是不是同一个商户?
B 表 · 竞品新进品牌 ——竞品市调手动录入,问题更复杂:

▲ B 表(竞品品牌)14处脏数据 — OCR 遗留错误、日期格式混乱
注意看最后一条——tomford → Tom Ford。这是典型的 OCR 全小写遗留错误,人工排查几乎不可能一个个发现。
C 文本 · 小红书热搜 TOP60 ——社交平台爬虫数据,最不可控的一层:

▲ C 文本(小红书热搜)10处脏数据 — "始祖乌→始祖鸟"、"METAL→MELAND?" 待确认
这里有个细节值得玩味:METAL 到底是 MELAND CLUB 还是别的什么? AI 给出了疑似判断但标注了问号——它知道自己的边界在哪里。
02 / 四步标准化管线:让数据说人话
面对上面那堆烂摊子,传统做法是什么?Excel 手动查找替换、VLOOKUP 匹配、肉眼逐行校对……一套下来,半天就没了。
AI 的做法是搭一条标准化管线,分四个步骤依次处理:

▲ 字段标准化引擎:四步管线,每一步都有明确的输入输出
Step 1 · 金额统一
听起来简单,但实际操作中坑非常多:
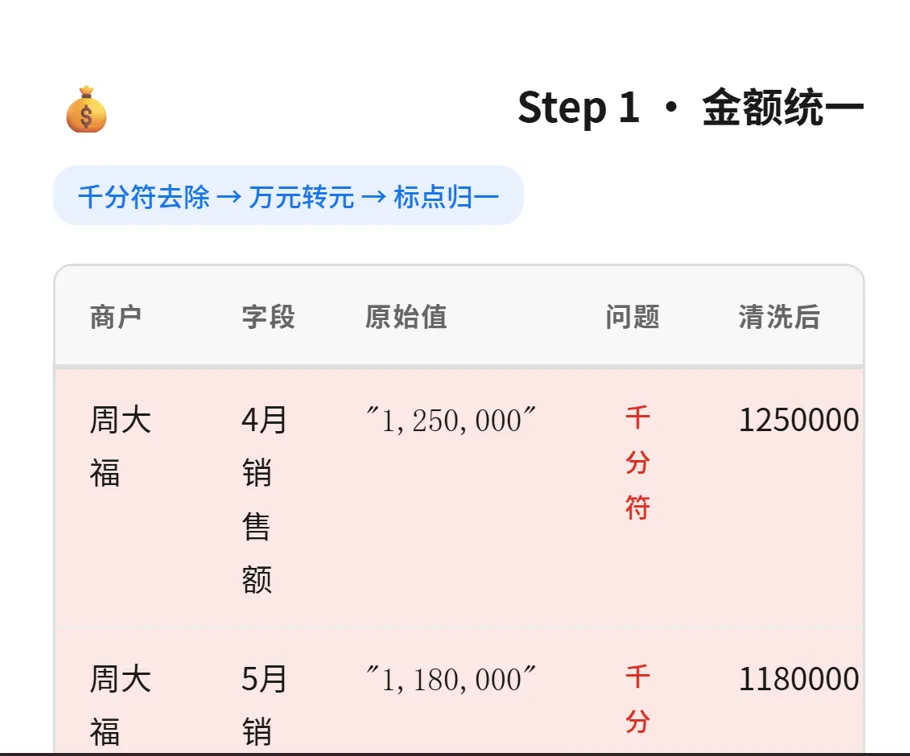
▲ 金额统一示例:周大福的销售额经过"千分符去除→万元转元→标点归一"三步处理
周大福 4 月销售额原始值是 "1,250,000"——带千分符的万元单位。AI 自动识别并转换为纯数字 1250000 元。整个过程不需要写任何公式。
Step 2 · 日期归一
光日期格式就有四种混用:
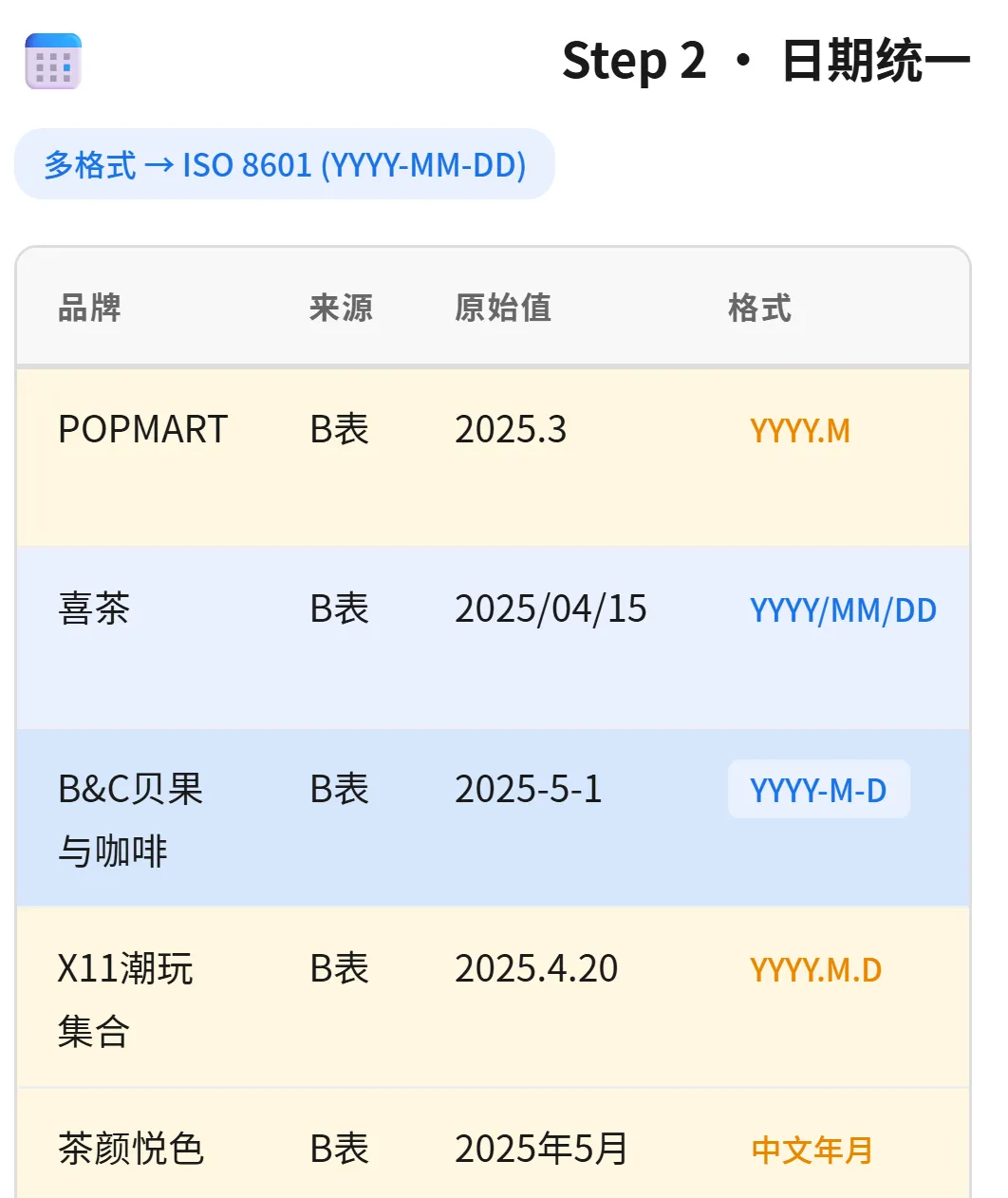
▲ 四种日期格式全部归一到 ISO 8601 标准(YYYY-MM-DD),AI 能自动识别语义
"2025年5月" 这种中文月份也能被正确解析。关键是——AI 不是在做正则匹配,它在理解语义。
Step 3 · 异常值识别 ——这一步是真正的杀手锏。
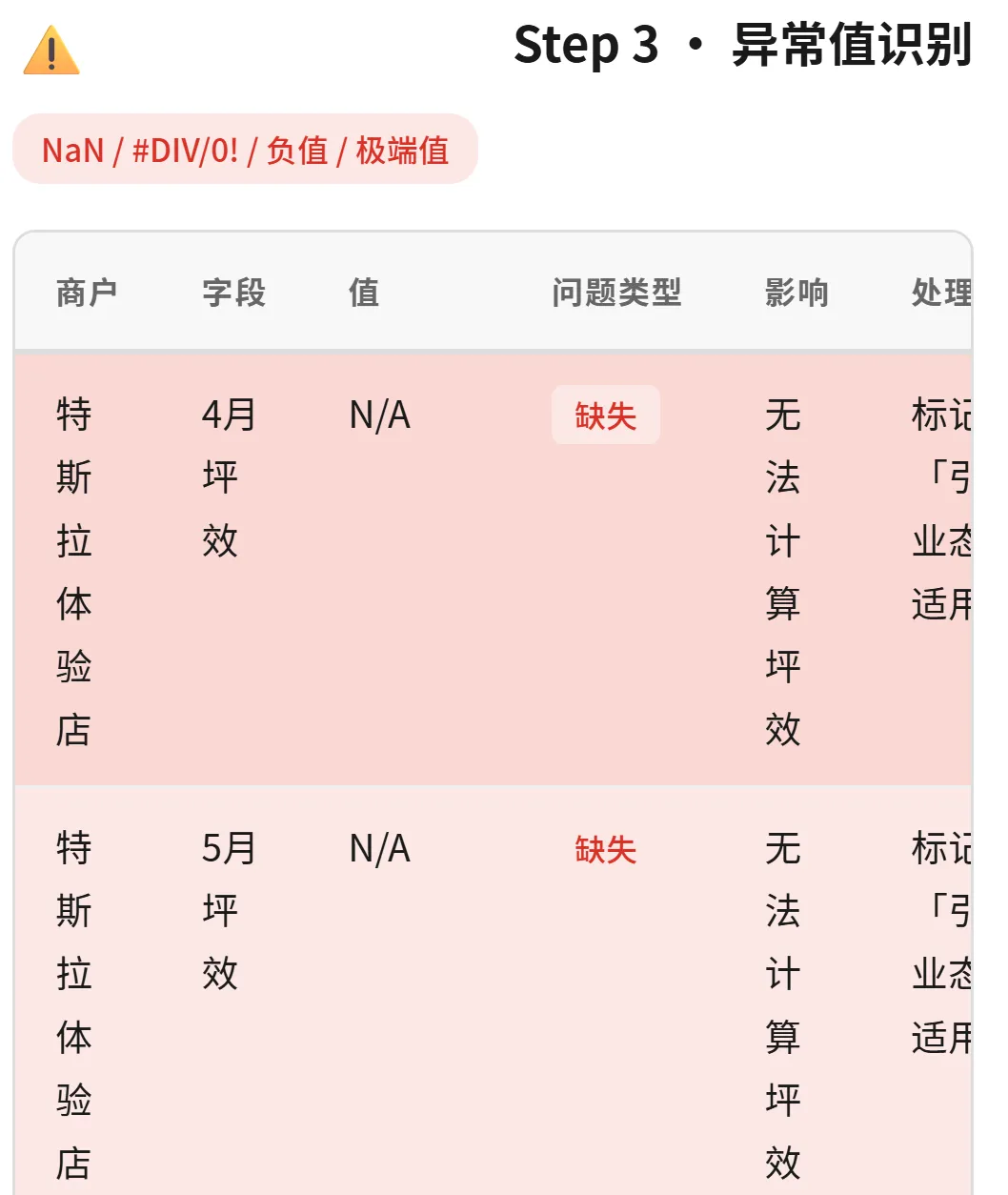
▲ 异常值识别:N/A 缺失、NaN 无法计算、极端值告警——每类问题自动分类处理
实战案例:星巴克甄选的 600 万之谜
系统检测到某门店单月销售额高达 687 万,远超同类店铺正常水平。AI 触发异常告警,提示人工确认。
经核查:该数据不仅包含门店零售额,还叠加了外卖+快递+区域内 2-3 家联营店的总额。如果没有这个告警,这条数据会严重扭曲整栋楼的平效评估。
还有一类更隐蔽的问题——引流业态误判:
特斯拉体验店这类新能源车展厅,坪效极低但战略价值极高。如果按普通零售业态考核,会把整个项目的健康度算偏。AI 会自动标记"引流业态"并将其从坪效统计中剔除,单独评估其引流价值。
Step 4 · 商户名清洗 ——一线运营同事最头疼的环节:
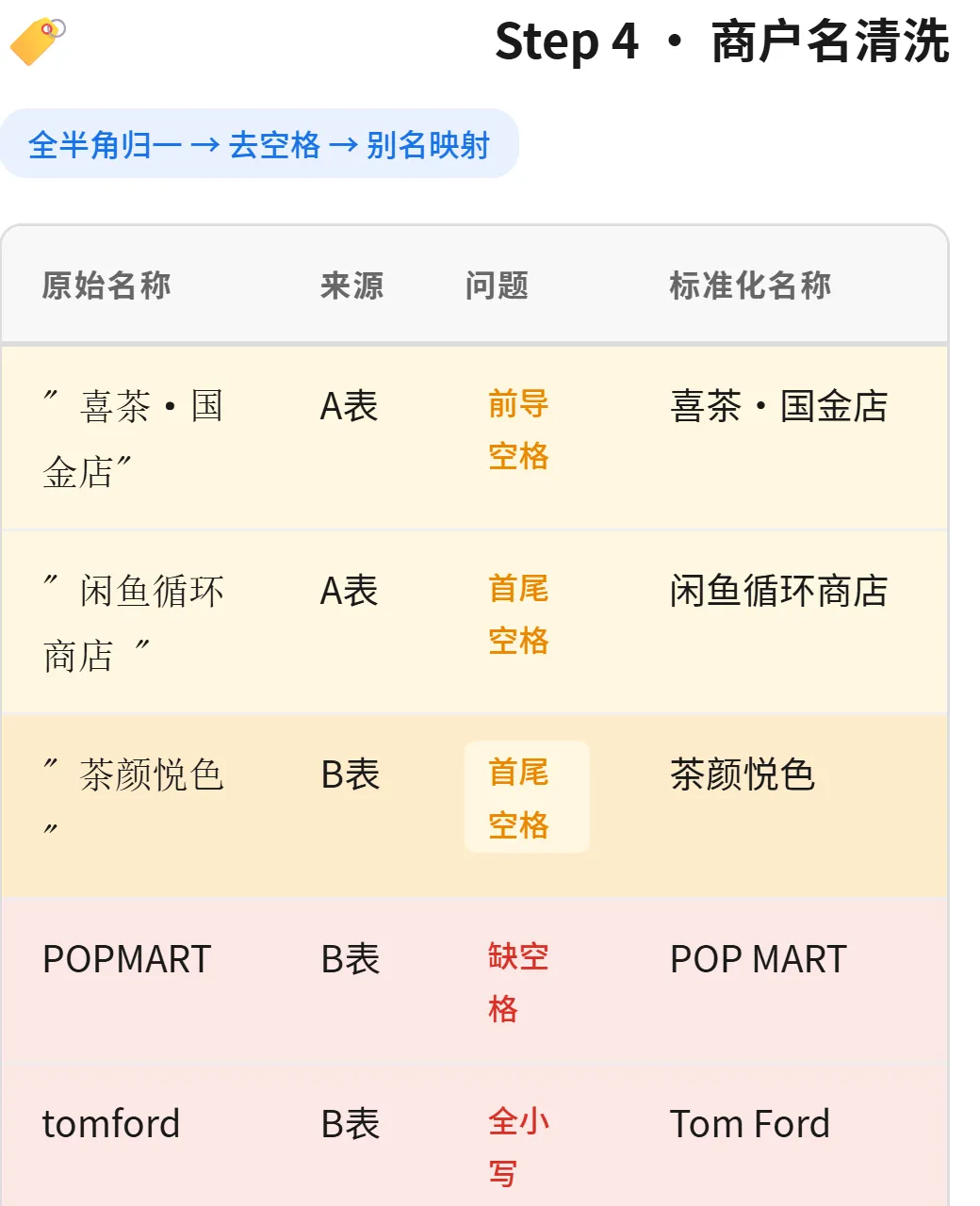
▲ 商户名清洗:全半角归一、去空格、别名映射——"tomford"→"Tom Ford" 一键修复
03 / 模糊匹配:AI 比 VLOOKUP 聪明在哪?
数据洗干净了,接下来要解决的核心问题是——怎么把 A 表、B 表、C 文本这三股数据关联起来?
在 Excel 里,你只能做精确匹配。"喜茶·国金店" 和 "喜茶"?匹配不上,因为字符串不相等。
但 AI 可以做模糊匹配:
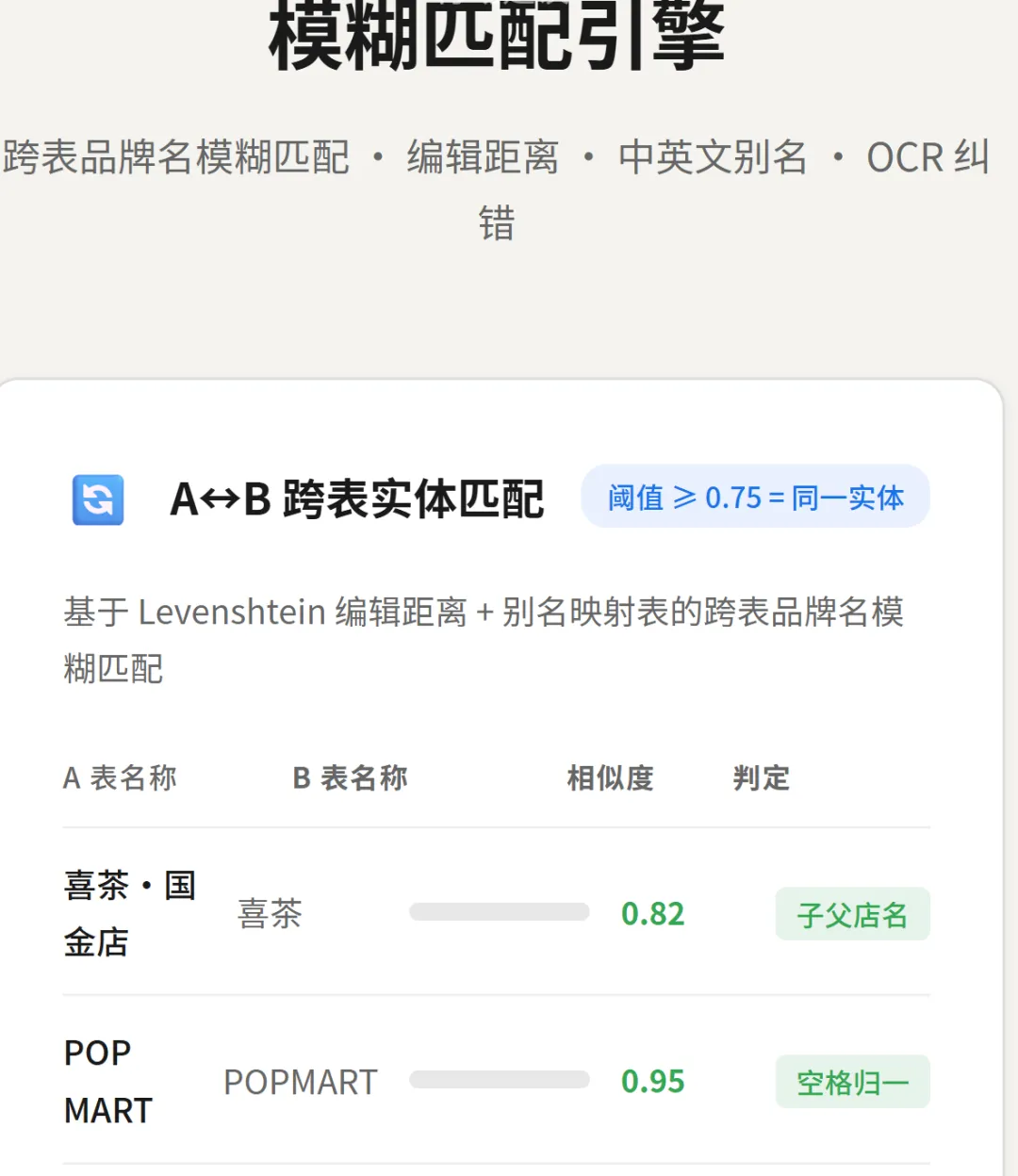
▲ 基于 Levenshtein 编辑距离的跨表模糊匹配:相似度 ≥ 0.75 即判定为同一实体
看看这些匹配结果:
- "喜茶·国金店" ↔ "喜茶"
→ 相似度 0.82 → 判定:子父店名 ✓ - "POP MART" ↔ "POPMART"
→ 相似度 0.95 → 判定:空格归一 ✓ - "泡泡玛特" ↔ "POPMART"
→ 相似度 0.76 → 判定:中英别名 ✓ - "赫莲娜" ↔ "tomford美妆"
→ 相似度 0.15 → 不匹配 ✗
这就是 AI 和 Excel 最本质的区别——AI 理解语义,Excel 只能比较字符。
对于 C 文本的小红书热搜,还有一层 OCR 纠错 + 热搜关联 的能力:
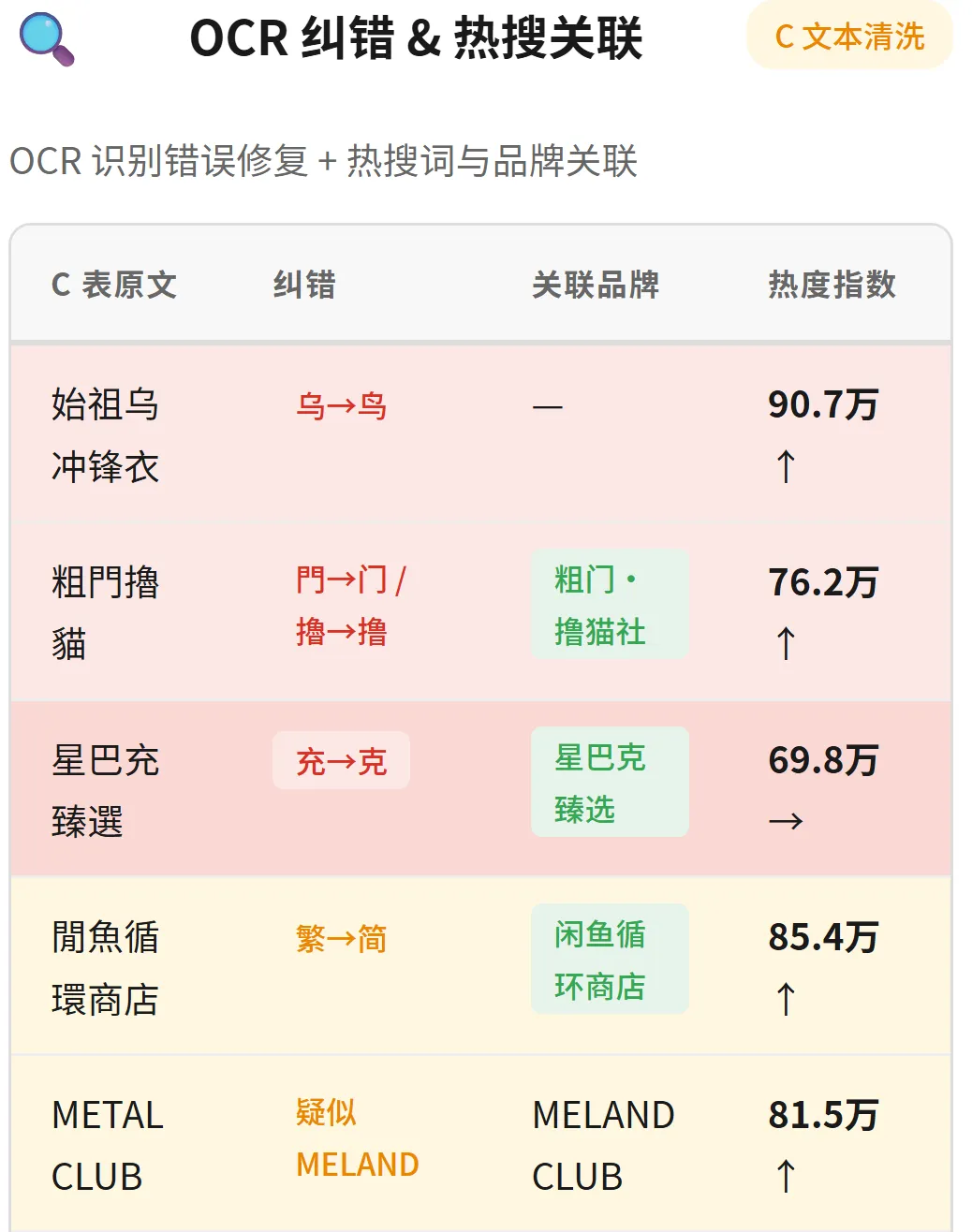
▲ C 文本 OCR 纠错 & 热搜词关联:始祖鸟(90.7万↑)、粗门撸猫社(76.2万↑)、闲鱼循环商店(85.4万↑)
为了实现这些匹配,背后有一套别名映射词典作为支撑:
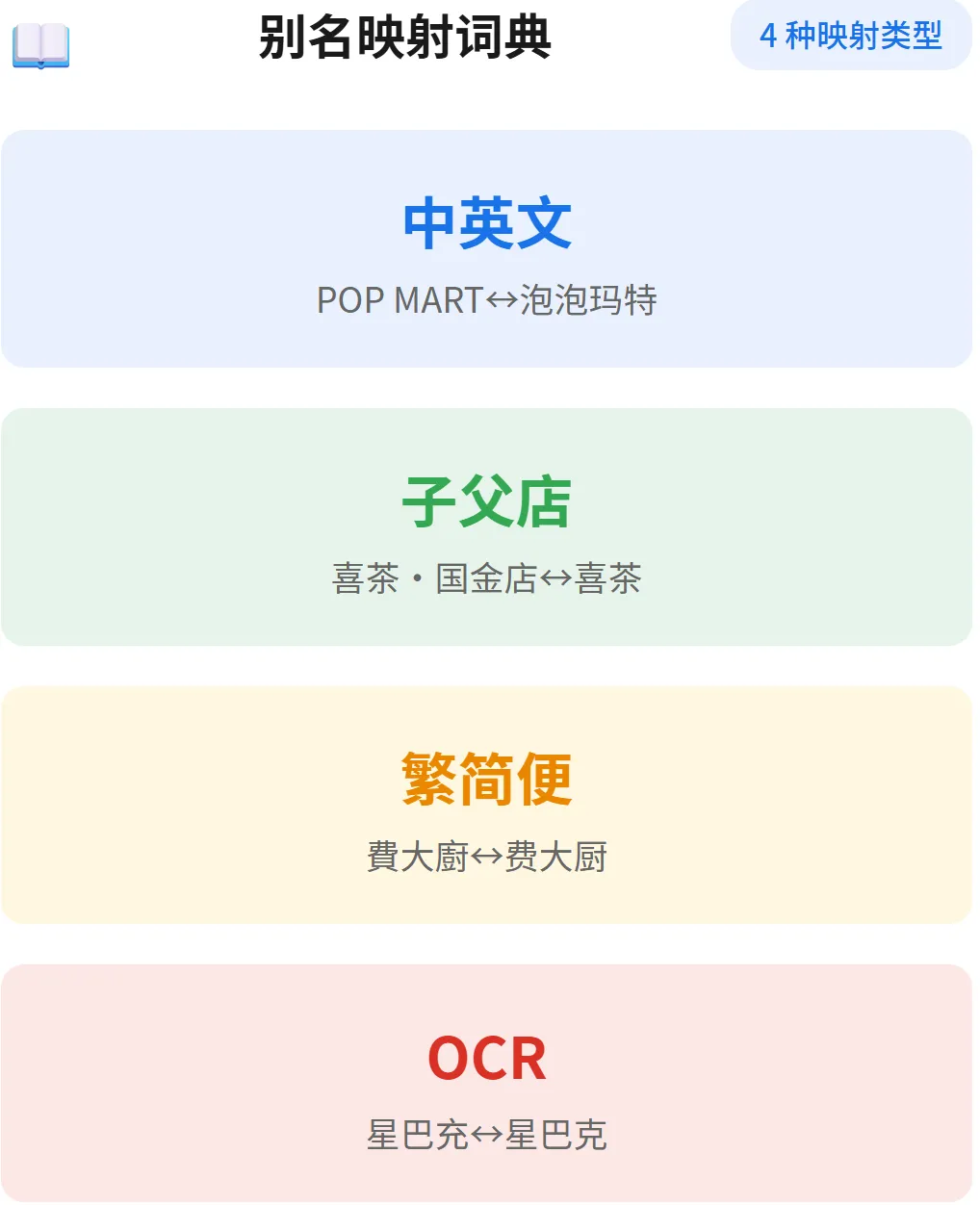
▲ 四种映射类型:中英文、子父店、繁简便、OCR纠错
这套词典可以持续积累——每次人工确认一条新规则,下次就能自动复用。越用越聪明,这才是 AI 工具的正确打开方式。
04 / 四象限决策矩阵:从"看数字"到"做决策"
所有数据都清洗完毕、关联到位之后,我们终于来到了最有价值的部分——交叉归因分析。
核心思路非常直观:两个维度画十字,四个象限定策略。
横轴 = 坪效(内部经营效率)你场内品牌的每平米产出,4 月 vs 5 月环比变化
纵轴 = 热度(外部消费趋势)该品牌在小红书的搜索指数及趋势走向
先看坪效异动检测:
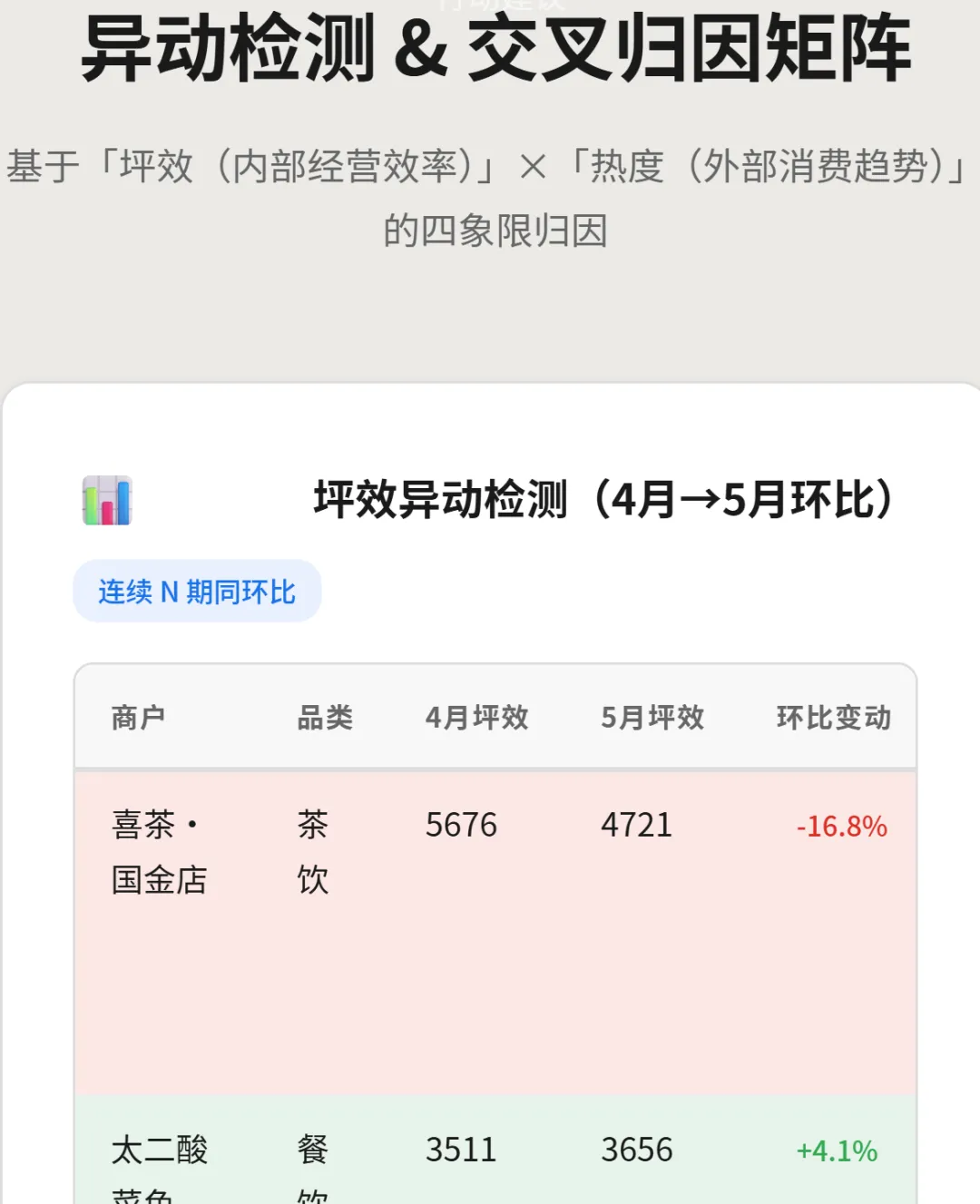
▲ 平效异动检测(4月→5月):喜茶国金店下滑 16.8%,太二酸莱鱼微升 4.1%
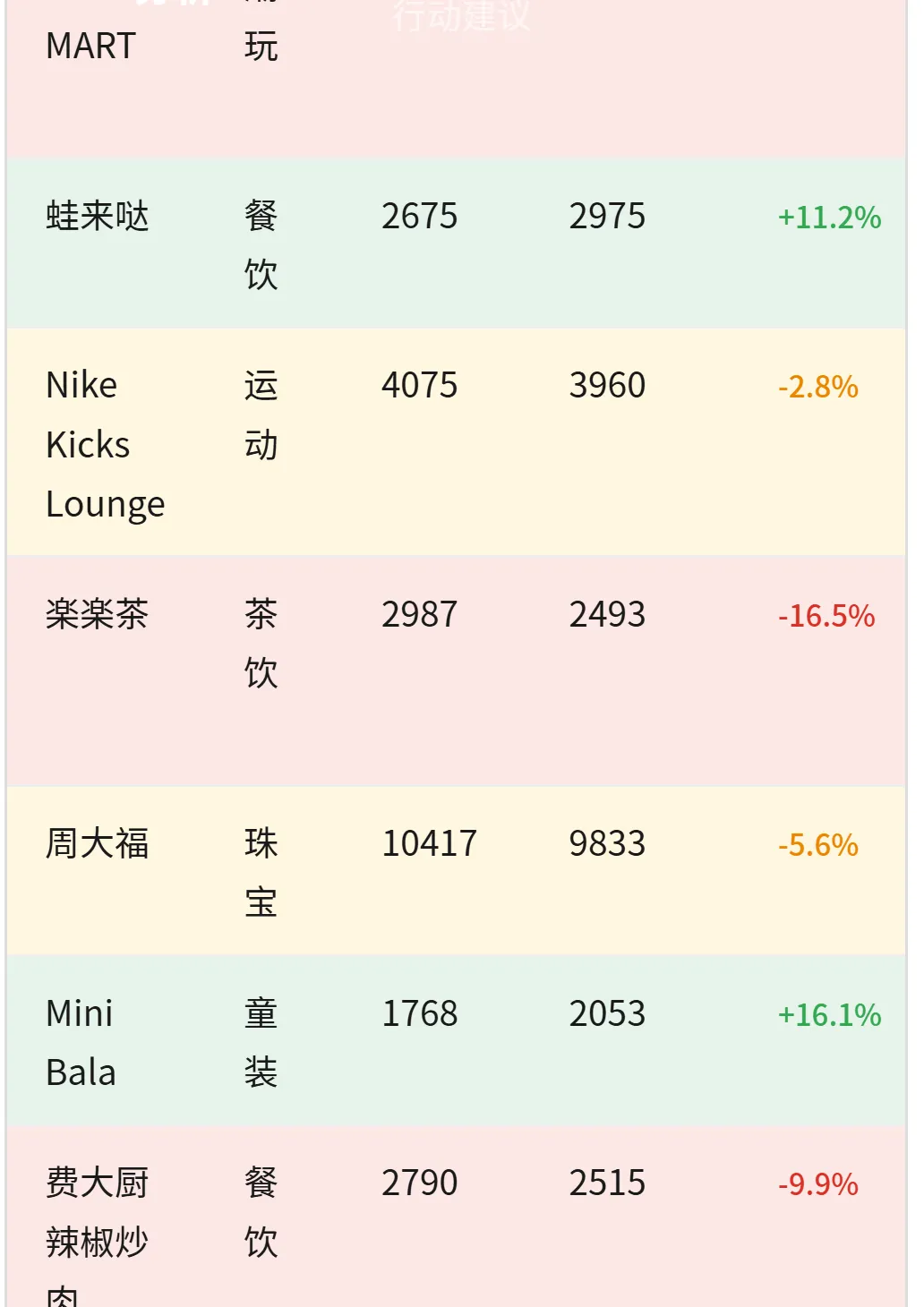
▲ POP MART 连续下滑 ↓↓、蛙来哒上升 ↑、周大福微降 -5.6%——每条都带着状态标注
然后把平效数据和热度数据叠在一起,得到这张四象限矩阵:
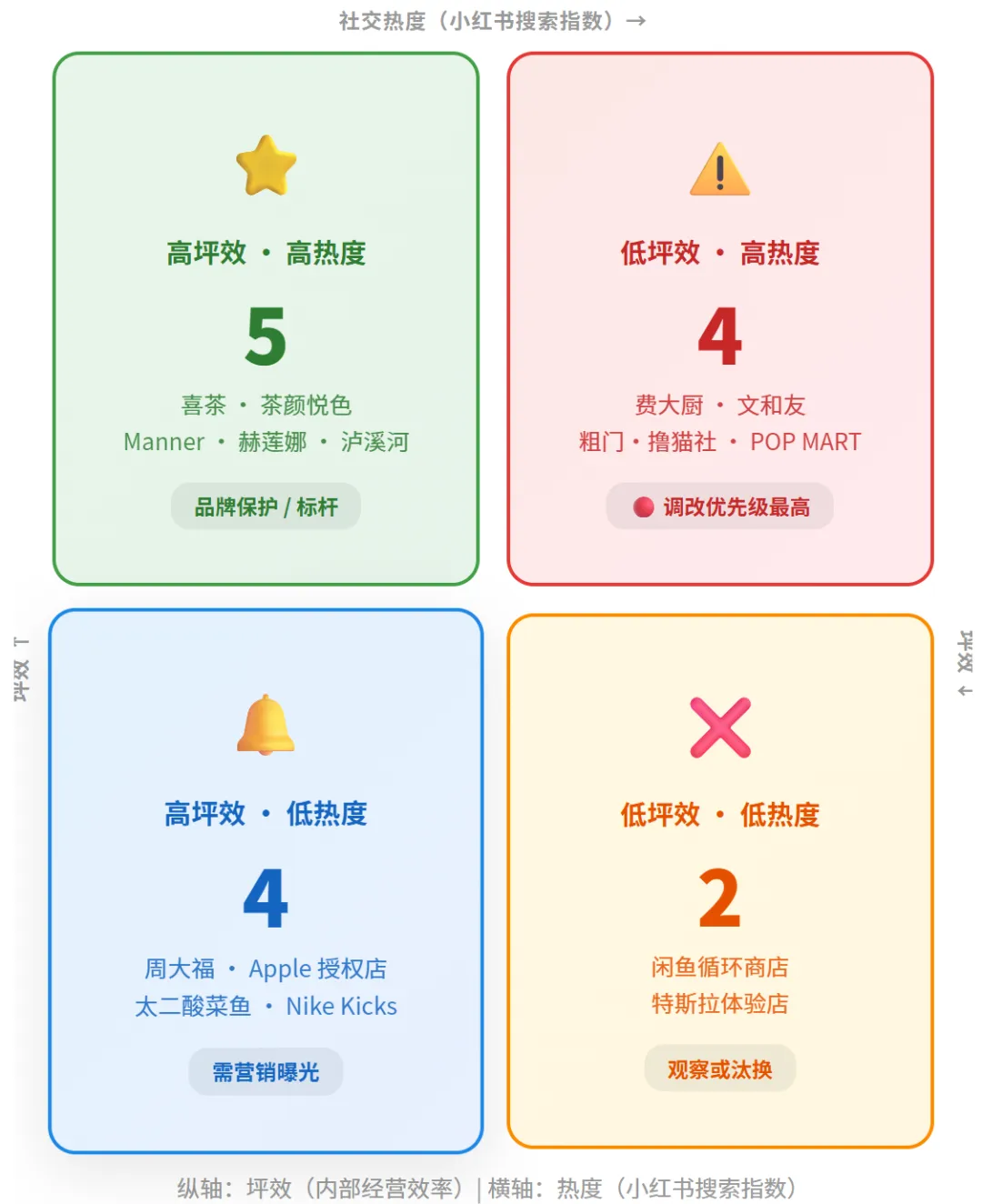
▲ 四象限决策矩阵:横轴坪效 × 纵轴热度,四个区域四种打法
高坪效 · 高热度(5家)喜茶 · 茶颜悦色 · Manner · 赫莲娜 · 泸溪河→ 策略:品牌保护 / 推标杆店
低坪效 · 高热度(4家)费大厨 · 文和友 · 粗门撸猫社 · POP MART→ 策略:调改优先级最高
高坪效 · 低热度(4家)周大福 · Apple 授权店 · 太二酸莱鱼 · Nike Kicks→ 策略:需营销曝光炒热
低坪效 · 低热度(2家)闲鱼循环商店 · 特斯拉体验店→ 策略:观察或汰换
再按品类维度聚合一下:
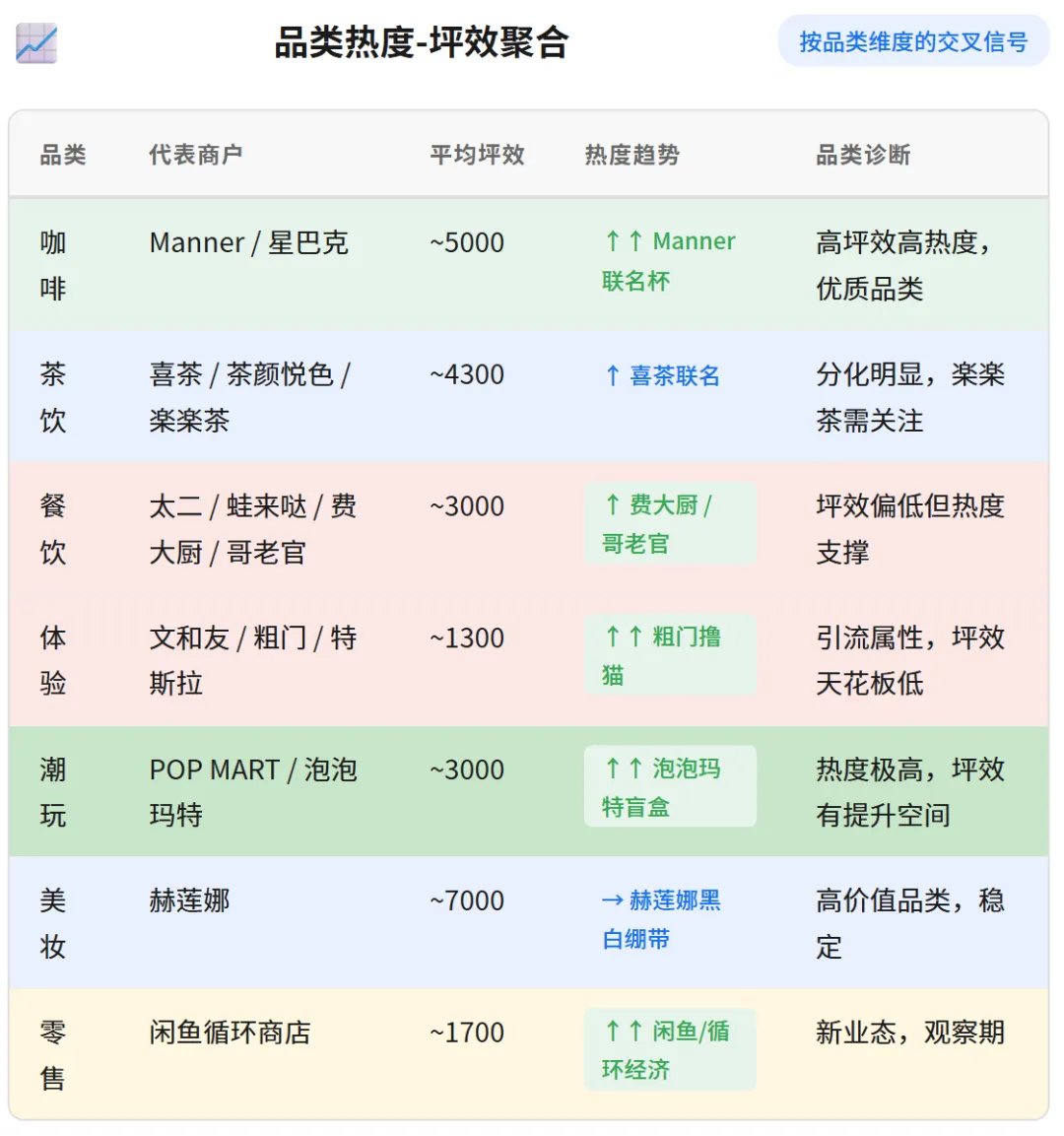
▲ 品类热度-坪效聚合:咖啡 ~5000 高坪效高热度;体验 ~1300 引流属性天花板低
这张表对品类规划非常有价值。比如咖啡品类(Manner/星巴克)平均坪效 ~5000 且 Manner 联名杯热度飙升,属于高坪效高热度的优质品类;而体验业态虽然文和友/粗门/特斯拉热度不低,但坪效只有 ~1300——需要重新审视其租金定价逻辑。
05 / 从分析到行动:P0-P3 洞察清单
分析的终点不是图表,是行动。基于上述四象限矩阵,AI 输出了一套分级可执行洞察:

▲ P0 立即行动:POP MART / 费大厨 / 文和友 / 粗门撸猫社——4家商户涉及3个品类
P0 立即行动 · 低坪效 × 高热度POP MART — 小红书热度 95.6 万,但坪效仅 3094 且连续下滑。典型「叫好不叫座」。→ 建议:推动升级 L1 旗舰店(85m²→120m²+);或增加限定品发售排期费大厨 — 热度 78.6 万↑,坪效 2515 连续两月下滑→ 建议:增加外带窗口 / 优化翻台率文和友 — 热度 79.8 万↑,坪效仅 1336。若 Q3 无改善则缩减面积
P1 近期营销 · 高坪效 × 低热度周大福(坪效 9833,热度一般)→ 策划「周大福传承」系列联名快闪Apple 授权店(坪效 10133,热度 45.2 万)→ Vision Pro 体验活动 + 内容种草太二酸莱鱼(坪效 3656,热度 80.3 万↑)→ 酸菜鱼挑战赛 / 联名周边
P2 维护关系 · 高坪效 × 高热度喜茶 · 茶颜悦色 · Manner Coffee · 赫莲娜 · 泸溪河这 5 家是项目的「现金牛」和口碑支撑。Manner 环比 +24.2% 最亮眼;茶颜悦色 +9.1% 持续稳定→ 优先续约、提供位置升级选项、作为招商案例展示
P3 观察 · 低坪效 × 低热度闲鱼循环商店(坪效 1578 连续下滑)→ 属新业态,给 3-6 个月爬坡期,设定坪效底线 2000特斯拉体验店(无直接租金收入)→ 评估引流价值:到店客群画像、连带消费率
06 / 招商线索:隔壁老王有什么,我没有?
除了运营调改,这套体系还能输出招商线索——通过 A↔B 跨表匹配,找出那些已经入驻竞品但还没进你场的品牌:

▲ 招商线索卡牌:每个品牌附带面积、位置、热度趋势等关键决策信息
其中特别值得关注的是:
- 霸王茶姬
(万象城·60m²·热度 65.2 万↑↑)— 茶饮赛道势能最强的新锐品牌之一 - MELAND CLUB
(龙湖天街·800m²·热度 81.5 万↑)— 亲子业态头部玩家,面积需求大 - X11 潮玩集合
(万达广场·200m²)— 潮玩赛道代表,与场内 POP MART 形成互补 - M Stand Coffee
(万象城·80m²·热度 48.3 万↑)— 第三波咖啡浪潮的代表
这些不是凭空猜出来的——每一个都有竞品落位实据 + 热度数据支撑。拿着这份名单去跑招商,效率完全不一样。
07 / 完整数据管线总览
最后,让我们退一步,看看整套工作流的完整面貌:
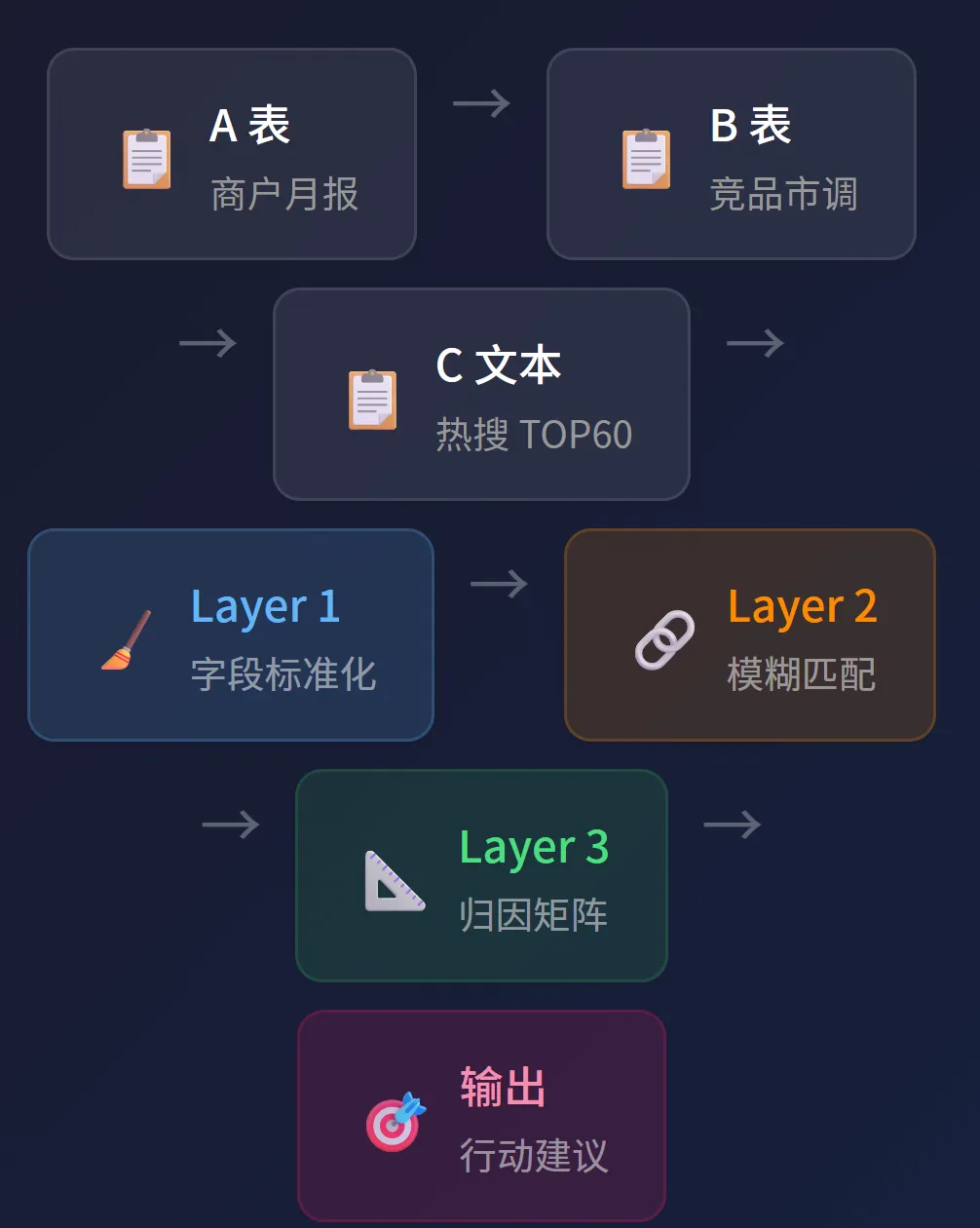
▲ 三表汇入 → Layer1 字段标准化 → Layer2 模糊匹配 → Layer3 归因矩阵 → 输出行动建议
回顾一下整个流程:
- 三表汇入
— A 表(商户月报)、B 表(竞品品牌)、C 文本(小红书 TOP60) - Layer 1 字段标准化
— 金额统一 → 日期归一 → 异常值识别 → 商户名清洗 - Layer 2 模糊匹配
— Levenshtein 编辑距离 + 别名映射 + OCR 纠错 + 热搜关联 - Layer 3 归因矩阵
— 坪效 × 热度四象限 + 品类聚合诊断 - 输出行动建议
— P0/P1/P2/P3 分级洞察 + 招商线索清单
写在最后
这篇文章讲的是一套具体的数据分析方法论,但我真正想说的是一件事:
AI 不会替代商业地产的运营人。但它能让运营人从 Excel 里抬起头来,去思考更重要的事情。
以前洗数据要花大半天,现在 10 分钟搞定。以前做竞品对比要一行一行 VLOOKUP,现在模糊匹配自动完成。以前写报告要自己琢磨措辞,现在四象限矩阵直接告诉你该干什么。
省下的时间拿来干嘛?
去跟 POP MART 的店长聊聊为什么线上那么火但线下坪效起不来。去跟费大厨的运营研究翻台率怎么提升。去跟招商同事一起盘一盘霸王茶姬能不能落地。
——这些才是 AI 替代不了的东西。
免责声明:文章中所有涉及的项目及品牌均为虚拟
Bob.商业趋势观察
聚焦商业地产AI应用
