 夜雨聆风
夜雨聆风
手里有一份几十页的扫描合同,你想把它变成可搜索、可复制、可交给 AI 分析的文字。
现在最常见的做法,是先把 PDF 拆成图片,再逐页识别,最后把几十份结果重新拼起来。中间遇到表格、跨页段落、歪斜扫描和页眉页脚,还要人工再收拾一遍。
6 月 22 日,百度公开了 Unlimited-OCR;6 月 23 日,论文上线。项目很快登上 Hacker News 首页,讨论达到 400 多分和约 100 条评论,GitHub 也已有约 3400 个 star。
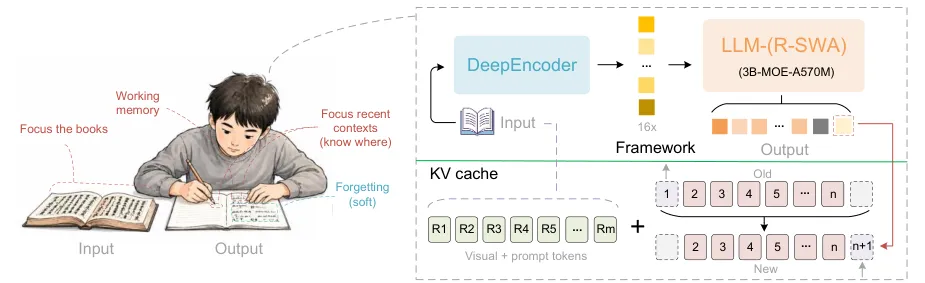
官方最吸引人的说法,是它能在一次推理中处理几十页文档,并把长输出过程中不断增长的 KV cache 控制在固定规模。
但我更关心一个普通得多的问题:
它能不能把长 PDF 最烦人的“拆页、识别、拼接”变成一条连续流程,同时又不把人工复核成本藏起来?
这决定了它是一个漂亮的研究项目,还是一件真能进入文档工作流的工具。
Unlimited-OCR解决的,不只是识别一个字
单页 OCR 已经不新鲜。
拍一张发票、截一页书、识别一张表格,很多工具都能做。真正麻烦的是长文档。
一份合同可能前面定义甲乙双方,后面只写“甲方”“服务方”;一份报告的表头可能在上一页,数据延续到下一页;一本扫描资料里,同一章节会反复引用前文。
如果每页完全分开识别,文本虽然出来了,文档关系却容易断掉。
传统流程通常需要额外写脚本:PDF 转图片,按页调用 OCR,记录页码,处理失败页,合并结果,再用规则删除重复页眉页脚。文档越长,工程上的“胶水”越多。
Unlimited-OCR 想改变的就是这一步。
它不是简单宣布识别率又高了多少,而是试图让模型保持对原始文档的参考,同时只保留有限的近期生成上下文。这样长文档继续输出时,显存占用不会随着已生成文字一直线性上涨。
说白了,它想让 OCR 从“逐页任务”变成“长程解析任务”。
为什么它会在HN引起这么多讨论
Hacker News 的讨论里,有做 OCR 的用户直接提到,现实中常见的办法就是把大图切成小块,再交给模型识别,最后做重叠和拼接。
这种方法不是不能用。
它甚至可能在清晰、规则的资料上非常稳定。但切片本身会引入新的问题:从哪里切、要留多少重叠、会不会把一个单词或表格行切成两半、不同页面的结构如何恢复。
也有人提醒,差扫描、倾斜页面、密集标签和值对、复杂表格,本来就是 OCR 的硬骨头。上下文变长,未必自动等于这些问题被解决。
这正是 Unlimited-OCR 值得关注、又不能被宣传语带跑的地方。
它击中了真实痛点:长文档处理太碎。
但社区讨论也把边界说得很清楚:一次读得更多,不代表每一类文档都读得更准。
第一类值得测的,不是论文,而是扫描合同
如果你想判断它是否适合自己的工作,最先别拿排版完美的数字 PDF。
找一份真实扫描合同更有意义。
最好包含印章、手写批注、页码、跨页条款、金额、日期和多级编号。然后观察五件事:
条款编号有没有连续
第 3.2 条到了下一页,是否还能接住,而不是突然重新编号或漏掉段落。
关键字段有没有被“合理改写”
OCR 最危险的错误,不是完全看不懂,而是把金额、日期、公司名识别成另一个看起来很合理的值。
页眉页脚是否反复混入正文
每页都有的公司名称、保密标识和页码,如果被重复插进段落,会直接影响后续搜索和摘要。
跨页定义是否保持一致
前文的主体名称、缩写和术语,到了后文有没有被换成相近词。
复核能否定位回原页
识别结果再漂亮,如果错误不能回到具体页码和区域,人还是要从头翻文档。
合同场景里,最重要的从来不是“整体看起来像原文”,而是关键字段能不能被快速复核。
第二类值得测的,是带表格的业务报告
很多 OCR 演示喜欢展示连续文字,因为它最容易让人感到“读懂了”。
真正决定生产价值的,往往是表格。
比如月度经营报告里,一张表跨两页,第二页没有重复完整表头;某一列是百分比,旁边一列是金额;表格下方还有口径说明。
这时你要看的不是模型能不能吐出 Markdown,而是结构是否还能用于下一步。
把结果导入 Excel 后,列有没有错位?
负号和小数点有没有丢?
合并单元格是否制造了错误对应?
表头、数据和脚注能不能分开?
如果最后仍要逐行重新对齐,所谓“一次处理几十页”只是把识别跑得更连续,并没有真正缩短交付时间。
OCR 的价值不在于输出了多少字,而在于少了多少人工重新整理。
第三类值得测的,是论文和旧资料
论文、年鉴、说明书和扫描书籍,是 Unlimited-OCR 更容易体现长文档优势的场景。
这些资料通常有连续章节、脚注、公式、图注和参考编号。逐页识别后,最常见的问题是章节关系断裂、图注跑位、双栏顺序混乱。
这里可以用一个很简单的测试方法:
选取一段跨两页的正文、一张带图注的图片、一页双栏内容和一段脚注,分别对照原文检查。
不要只抽查第一页和最后一页。
长文档工具最容易出问题的地方,往往是中间某一页开始偏移,后面仍然继续生成,让人误以为任务正常完成。
如果用于资料检索,还应再做一次关键词回查:随机挑 20 个姓名、数字、专有名词和章节标题,确认它们能否被准确找到。
“本地运行”也不是下载模型就结束
Unlimited-OCR 提供了代码和模型权重,这是它很有吸引力的一点。对合同、内部报告、客户资料这类不适合上传云端的文件,本地处理确实有明确价值。
但官方仓库当前给出的 Transformers 推理方式依赖 NVIDIA GPU,并使用 CUDA 环境。PDF 也需要先转成页面图片,再交给多页推理接口。
这意味着“本地”并不等于“任意电脑都能轻松运行”。
你还要计算显卡、显存、环境安装、文件预处理、失败重跑和结果存储。对偶尔识别几份资料的人,租用现成 OCR 服务可能更省事;对长期处理敏感文档、批量档案或内部知识库的人,本地部署才更有可能摊薄成本。
所以别只问它开不开源。
要问的是:你的文档量、敏感程度和返工时间,是否足以覆盖部署成本。
一套更靠谱的试用记录
如果准备测试,我建议不要只记“成功”或“失败”,而是给三类文档各做一张表:
原始页数与文件大小; 首次运行时间; 峰值显存与失败次数; 漏页、错序和重复页数量; 关键数字错误数; 表格需要人工重排的单元格数; 人工复核和修正分钟数; 最终结果能否直接进入搜索、摘要或 Excel。
其中最重要的一列,是人工修正分钟数。
因为模型演示最容易展示的是“几十页一次跑完”,使用者真正付钱的却是“跑完以后还要收拾多久”。
如果它把 30 次逐页调用变成一次任务,却仍然需要两小时校对,价值有限。
如果识别率没有宣传得那么惊艳,但把拆页、拼接、页码管理和失败重跑省掉一半,反而可能更值得留下。
别把“一次读完”理解成“一次交付”
Unlimited-OCR 的新意是真实的。
它把 OCR 的竞争从单页准确率,往长文档连续解析和固定缓存成本推进了一步。HN 的热度也说明,很多人确实受够了切片、重叠和拼接这套旧流程。
但在合同、报告和旧资料里,最终责任仍然落在人身上。
金额要核,条款要核,表格要核,权限也要核。
更准确的期待不是“以后不用复核”,而是让人把时间从机械拼接,移到真正重要的错误检查上。
长 PDF 工具真正成熟的标志,不是它能一次输出多少页,而是人能更快知道哪几页不该相信。
