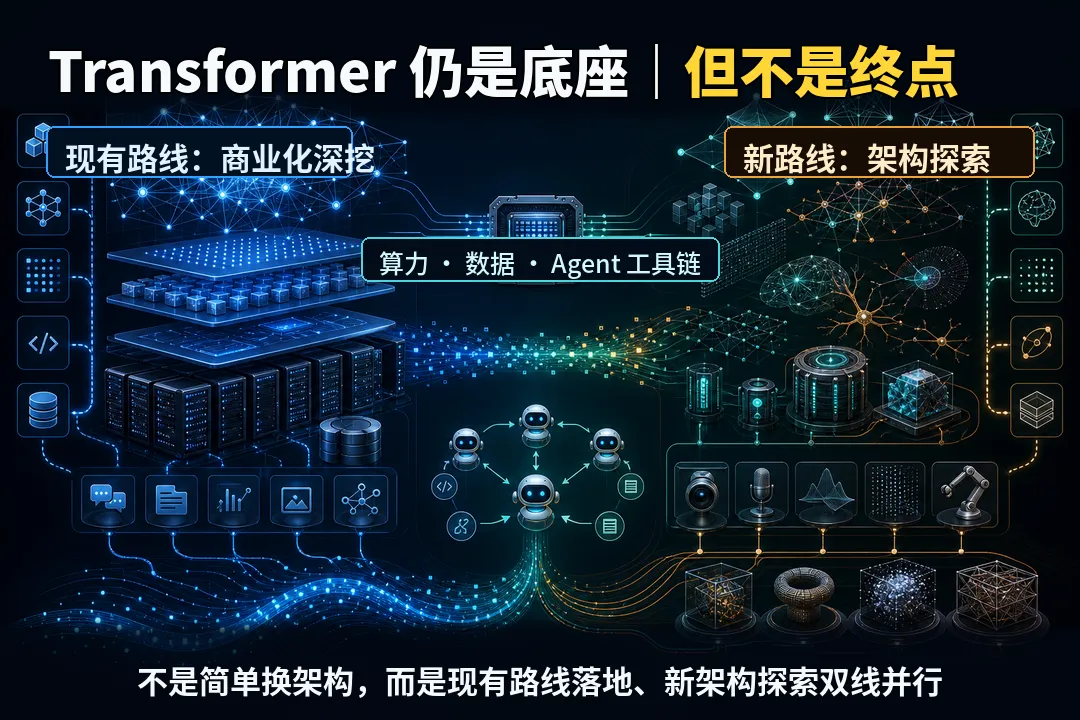
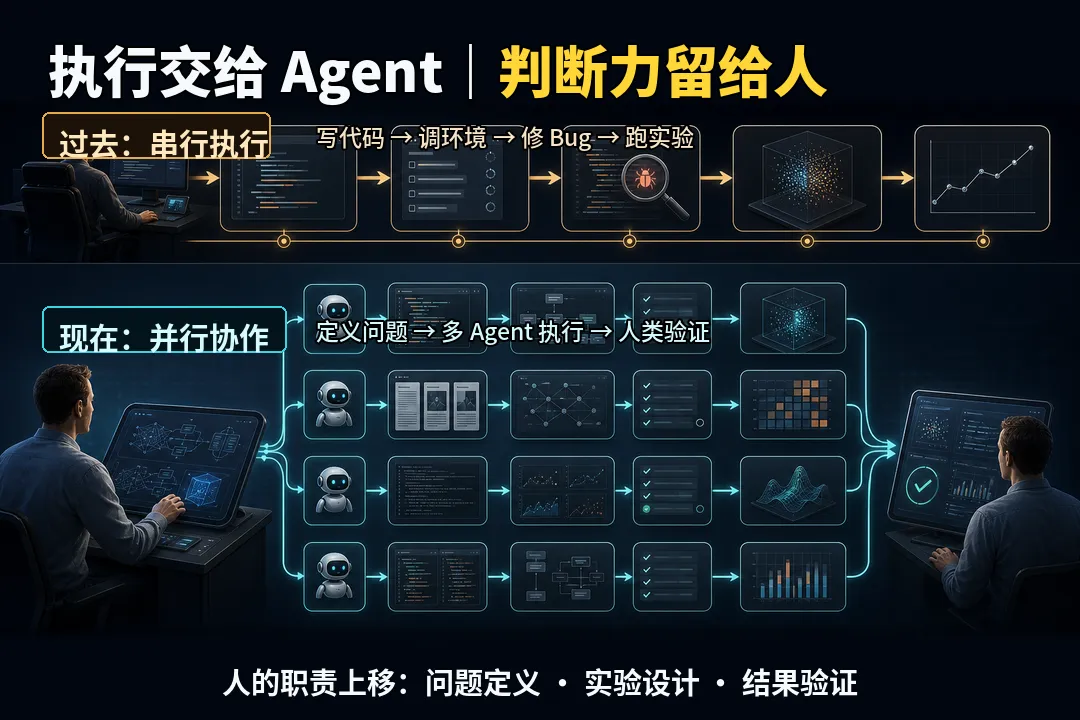
AI科研圈的精神狂热|颠覆性预测|Transformer之父:AI并非像人类一样思考,Agent正在重写技术人的工作方式最近,Transformer 论文《Attention Is All You Need》的作者之一 Lukasz Kaiser,谈到 AI 科研圈正在出现一种轻度的“精神狂热”。这句话容易被理解成行业太兴奋。但我更愿意把它理解成另一件事:技术人的工作方式正在被 Agent、算力和大模型能力边界一起重写。真正值得关注的,不是某个模型又刷新了榜单,而是研究者从“亲手写完每一行代码”,开始转向“定义问题、组织实验、验证结果、管理多个 AI 执行者”。01Transformer 仍是底座,但不是终点2017 年的《Attention Is All You Need》提出 Transformer 架构,用注意力机制替代传统循环和卷积结构,让模型训练更容易并行,也让后来大模型的扩展成为可能。到今天,很多语言模型、多模态模型、代码模型,仍然是在 Transformer 路线上继续放大。它还没有过时,甚至仍是 AI 产业的基本盘。但 Lukasz 的判断很克制:Transformer 并不是终极答案。它在学习效率、长上下文、多模态理解和物理世界泛化上,仍然有明显短板。所以行业更像是在两条线上并行:一边继续深挖现有 Transformer 的商业潜力,一边等待下一代底层架构真正跑出来。消费级 GPU 的进步也降低了早期实验和小规模架构探索的门槛,但这不等于个人电脑可以复制大厂前沿模型。02大模型的泛化,不按人类直觉展开这次访谈里最值得技术人警惕的观点,是“大模型像外星人一样泛化”。人类理解世界,往往依赖少量样本和概念迁移。小孩见过几只猫,就能大致理解“猫”;学过代数后,也能把一些逻辑感迁移到几何。但大模型并不一定这样工作。它可能在某些高难任务上表现惊人,却在一个人类觉得相近的细分场景突然失效。Lukasz 用几何题举例:模型可以攻克很多复杂数学题,却可能长期卡在某类欧式几何问题上,直到补充大量同领域数据后才改善。这说明大模型不是没有泛化能力,而是它的泛化路径并不平滑。它的能力边界像锯齿,不像人类想象中的圆形扩张。这对产品和工程落地非常关键。不要因为模型在演示里连续答对十个问题,就推断它在真实业务里能稳定处理第一千个问题。越是自动驾驶、医疗、金融、法律这类场景,越要警惕长尾、异常和责任边界。03Agent 让研究从“写代码”变成“管实验”OpenAI 对 Codex 的官方描述,是一个云端软件工程 Agent,可以在隔离环境里处理重构、写测试、修 Bug、草拟文档等边界清晰的工程任务,并支持把多个任务并行交给多个 Agent。这和 Lukasz 在访谈里的体验是同一件事:过去复现一篇旧论文,可能要花几周时间整理代码、修环境、调 bug;现在借助 Agent,同样的工作可以被大幅压缩。但重点不是“AI 帮人少写代码”。真正的变化是,研究链路里的执行成本下降了。当样板代码、接口查询、报错修复和实验脚手架变便宜,研究者的大脑就会从细节泥潭里抬起来,去判断:这个 loss 是否合理?这个指标是否可信?这次提升是不是数据泄漏?模型到底是在学规律,还是在钻验证集的空子?所以 Agent 并没有让技术人变轻松。它让技术人的责任上移了。以前你对代码负责;现在你要对问题定义、实验设计、验证标准和最终判断负责。04所谓“精神狂热”,其实是反馈回路变短AI 科研圈为什么会显得停不下来?因为想法到实验的距离变短了。过去一个灵感要变成可运行实验,中间隔着环境、代码、调试和硬件适配。现在 Agent 能处理大量执行层任务,消费级硬件又降低了小规模验证成本,研究者很容易进入连续试探的状态。这就是“精神狂热”的真实含义:不是相信 AI 已经无所不能,而是反馈回路短到让人不断产生新问题、新实验和新判断。但越是在这种时候,越不能把判断权交出去。模型会自信地犯错,Agent 会主动补一些看似合理、实际危险的逻辑,漂亮的实验曲线也可能来自错误设置。给技术人的建议很简单:把 Agent 当成执行者,而不是老师傅;先建验证框架,再谈自动化;接受大模型的非人类性,把它放进一个可验证、可纠错、可迭代的系统里。AI 科研圈的“精神狂热”,最终给技术人的提醒不是快去追下一个工具,而是当执行变得越来越便宜,真正稀缺的会变成判断力。
 夜雨聆风
夜雨聆风