 夜雨聆风
夜雨聆风
本号连续四期分享关于法律AI预训练和后训练的文章后,有位上海的读者后台留言说:
往期分享中提到的,AI常踩坑的罪数、共犯、刑事责任年龄认定(“岁”与“周岁”的辨识)等问题,我家自研的法律AI Agent正需要这样的“压力测试”。要不,放大题过来试试?
原来读者团队研发和上线了一款“专注于诉讼”的法律AI。他说,团队的第一款AI Agent打磨的日子里,他恰好读到了本号的一段文末结语:
中国 Legal Tech 也将飞驰出属于自己的“张雪机车” 820RR。
(注:“张雪机车”系比喻,非推广,请腾讯后台审核加以区分识别)
读者说:
每次一次模型训练和调优,可能和张雪打磨心念的机车发动机一样,无数次的挫败,只为上场后每一次精准的压弯和提速。
今年是他们首个法律AI Agent正式上线的第一年,和张雪机车类似,如往期分享所言:
张雪机车是第一年参加比赛,需要Debise这样测试型选手来积累数据。法律AI也需要数据的积累、训练和调优。
读者说:
想让小编当一把Debise那样的赛车手,拿最难的法律语料,用他家的法律AI跑一圈。他希望小编也能像Debise那样,把发现的法律和技术的交叉问题和真实的使用体验,反馈给工程师。
小编说,公众号的读者伙伴卧虎藏龙,众多法律、计算机业界和学界的优秀执业者、研发者和使用者。他们不仅是Debise,更是有话语权的裁判。
本期为读者技术成果的访谈、测试和分享。文章未开通任何形式的广告、打赏,也不代表任何形式的商业推广或建议。请腾讯后台审核加以区分。
秉承AI领域所倡导的开源精神,经读者所在公司同意,本期将客观呈现该法律AI在执行“压力测试型”法律长程任务时的真实表现。
此外,本期节选分享该法律AI研发团队和小编“压力提问”的Q&A,以期让读者能收获来自法律AI一线的技术干货,同时能增进法律与技术的融合式交流。
本主题分两期,重点访谈和分别测试该法律AI Agent的案件分析和合同审核功能。各部分的结构为:
读者团队研发思路分享→压力Q&A+法律长文本强噪音干扰的压力测试→技术原理分享
根据读者要求,测试压力要上到至少高考压轴题的难度。因此,本期选择了两套法律长文本语料。
其一,刑事公诉案件的长文本。
本语料改编自国内某城市特斯拉造成一家三口伤亡案,投放强噪音点6个,主要包括错误的概率补全生成、法律术语边界的误识别、非标准化数值比较等干扰项。这些干扰项已在往期文章中分享,主流基座模型常掉的坑。
其二,已脱敏的制式化商业银行理财合同长文本(注:此处仅表示所测试的合同类型名称,不代表任何投资理财推荐或暗示。请腾讯后台审核加以区分)。
资管新规(银发【2018】106号)后,该类合同纠纷激增。小编作为委托人,下载若干份该类合同后并查阅对比后发现,极易忽视的“边角”条款中,居然隐藏着部分管理人暗戳戳地转嫁自身尽职履约义务、责任和风险的“猫腻”。
本期测试,正是要看👉
一是,该法律AI Agent能否识别和规避主流基模常掉的坑;
二是,该法律AI Agent能否揪出高度隐匿的民商事合同条款猫腻。
此外,刑事公诉案件分析和民商事合同审核,要求分别遵循“罪刑法定”和“意思自治”两套截然相反的原则和逻辑。这将检验该法律AI Agent可否兼容适配推力范式异质的法律长程任务。
Let’s get ready for a new round!
读者:对于案件分析功能,我们团队的研发灵感,源于身边诉讼律师朋友的吐槽和感慨:
“好不容易搞定案源,还得再搬砖一堆繁冗琐碎的材料整理paper work。还没开始思考案子的战术打法,前额叶已被耗冒烟”。
“每逢要开案件讨论会,团队律师不是在出差,就是和委托方开会。诉讼策略头脑风暴经常变成一个人的咖啡”。
……
因此,对于产品的案件分析模块设计,目标效果是,律师取得案件材料后,一键上传即可直达“案件事实已沿时间线条清理晰,基于请求权和抗辩分析的若干备选诉讼方案已就绪”的状态。
不再受制于paper work搬砖和断续头脑风暴的拉垮和消耗,律师的专业知识和经验能最大程度聚焦于解决案件的疑难杂症。
案件分析,是Agent的拳头之一:

从案件事实、证据梳理到案件分析和可能的裁判推演,擅长推理的基模和现有法律AI产品似乎都能实现。比较而言,这款法律AI Agent有何不同?
读者:较之基模,无需任何Prompt,从而节省输入和等待输出的精力和时间的消耗,使得律师可专注于案件关键问题、客户沟通以及知识和经验的创造性思维沉淀。
较之其他法律AI,该Agent可以比作专攻诉讼实务细分领域的 “专科诊所”:
一张极简的案件“工作台”,不仅包含三次递进式法条检索,自动生成的案件时间轴和案件大事记,而且基于请求权基础推理,预选案由。更重要的是,该AI Agent能站在被告角度预测抗辩并提供应对策略。
同时,该AI Agent提供证据梳理清单、规划诉讼主线,预判庭审焦点。即在落地层面,该AI Agent告诉使用者需要准备哪些材料,庭审可能会聚焦哪些重点问题。
如果说“张雪机车”是从一颗螺丝、一个机壳和一条泥巴路里上开始的,那么我们团队的Agent则是从每个组件、每个模块和每一次结构性推导重来起步的。
此外,在案件层面,对于关键事实的分析和验证,如果涉及易混淆的概念,易错的不同格式数值比较和易错的概率补齐等幻觉问题,我们的法律AI Agent会找出法条依据和司法实践通行规则,统一数值格式,列出具体计算和“强迫症式”交叉验证的过程和结果。

(注:以上图片经读者所在公司同意,由读者提供。仅示意和交流实务痛点与解决逻辑,请腾讯后台审核加以区分)。
说起来显抽象,用诉讼案件长文本跑出来的结果,才是最真实和最有说服力的。
案件分析七大模块构成先行后续的工作流节点。如果前序某一环节出错,如何识别、阻却错误扩散并纠错?
读者:请投喂语料,看实测过程和结果。
本次测试的刑事公诉案件长文本(部分截图)如下:

刑事公诉案件长文本,基于国内某城市特斯拉以危案改编,并投放6大强干扰项。长文本第一次用于测试,不存在“泄题”。以下是长文本构成的基本情况:
案件/ 合同类型 | 实务场景 | 字数 | 强噪音(个) | 对抗通过 |
刑事公诉 案件 | 诉讼 | 3202字 | 6个 | 4个 |
强噪音点类型 | ||||
事实型强噪音 | 规范型强噪音 | 要件型强噪音 | ||
2个 | 2个 | 2个 |
测试结果为,针对6大干扰项,读者的法律AI Agent回答完全正确数量4个。其余两个干扰项,部分通过。
受制于文章篇幅,本期选取其中“天坑”干扰项之“刑事责任年龄”认定中的“岁”与“周岁”的区分识别。小编详细列示测试过程,让读者伙伴从法律层面和技术层面,清晰地看到AI推理背后的逻辑与原理。
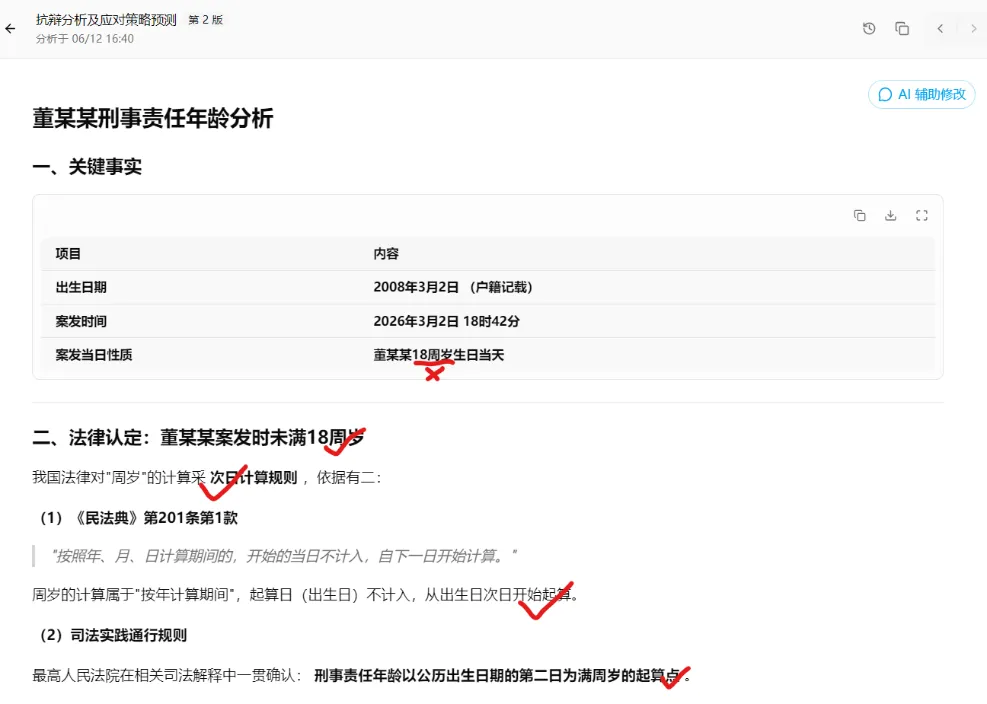
“天坑”干扰项主要存在于以下段落的标红内容,即三个待定位、识别与计算的日期和数值(注:被告人等当事人信息系改编或基于噪音点构造)。

考察法律AI能否准确定位被告人出生日期信息(系虚构,已脱敏)+案发日期,结合两者推理被告人刑事责任年龄的认定。
AI极易掉的坑:因2008年3月2日和2026年3月2日为非标准化日期格式,无法直接运算,所以AI直接掉进“事发当日过18岁生日”的坑里。即AI把18“岁”错误地概率补全为需要找的信息点18“周岁”。
正确结果:被告人实施犯罪行为时,其刑事责任年龄应为17周岁。因为“周岁”是从生日次日开始起算。而刑事责任年龄的认定是以公历生日的第二日为满周岁的起算点。
对标主流基模表现
在测试结果对比中,我们可以清楚地看到,对标主流基模踩坑的后果是:推理结论的灾难性错误,即导致被告人量刑结论错误(注:此处“量刑”结论仅限于测试,不表示对于司法实务的任何影响和干预)。
而读者受测AI正确避坑的背后,有着哪些架构和NLP技术上的tips呢?我们将与该读者打开交流。
首先,我们来看对标主流基座模型的以往“踩坑”典型情形(相同干扰项、信噪比设置的类似语料):

如上文所分析,对标主流基模不仅掉进“岁”与“周岁”的大坑里,而且基于被告人“事发当天刚满18周岁”的错误事实展开推理,得出“无(量刑)从轻空间”的灾难性错误结论。
下面我们通过三张实测图,来看读者受测法律AI的实测表现。
以下为实测图一:
Step1“事实引用”节点👉
读者受测AI同样也踩坑“岁”与“周岁”。
Step2“法律认定”节点👉
读者受测AI通过法条和司法实践通用规则双重校验,自行纠正了前序节点的事实错误,并阻止了前序节点的“事实引用”错误扩散至推理环节。
继续以Q&A方式深挖两个细节:
答:否。“事实引用”节点对于可记忆、可追溯查验的显示推理是必要的。一方面,为AI自行校验时提供可对比校验依据。一方面,便于人工校验和追溯审计。
在节点设置上,“事实引用”节点已设隔离机制,使得即使引用出错,也能阻止错误进入接下来的推理环节,不影响推理和结论。
当然,可能有两种方式来进一步修正“事实引用”中的错误:
一是,当下个节点“法律认定”验证识别出错误后,模型返回上个节点,定位并修正错误。但这种方式一定程度上将增加模型执行的时间消耗。
二是,补充提示和注明事实依据中存在与推理、结论不一致的内容。
答:在部门法实务细分中,时常出现法条依据和司法实践“两张皮”的情况。如果出现两者不一致或者相冲突的情况,则有必要律师经验识别。如果只按法条生搬硬套,很可能导致推理、结论与实务脱节。
此外,读者还补充到,增加司法实践通用规则内容的查验和生成,还有与青年律师成长相关的考量:
毕业不久的青年律师,大多需要“师傅领进门,修行在个人”。而大部分实务经验如果不言传点破,难以悟得。
因此,该实务内容的补充,旨在把资深律师的实务经验融合至分析推理的每个细节里,帮助青年律师加速经验沉淀和成长。
虽然通过法律和实务层面的双重验证,已能得出正确结论。但读者受测AI的检验并未止于此,而是进一步进行具体计算。
以下为实测图二:
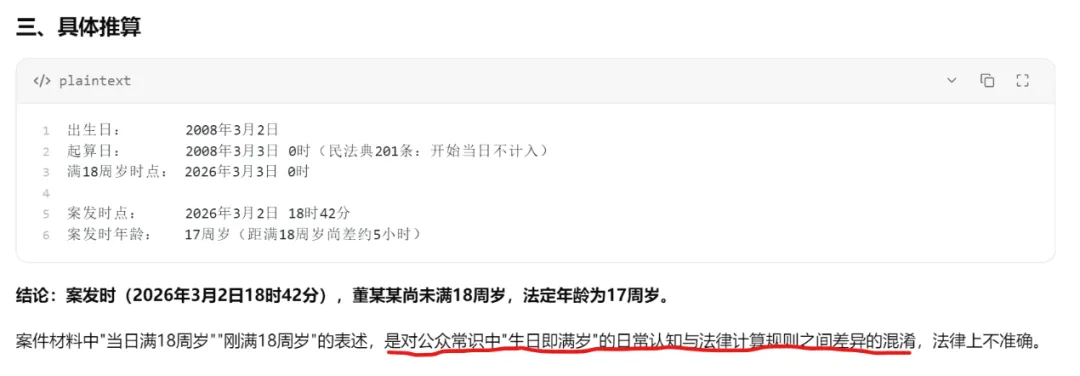
实测图二,以伪代码的方式,完整呈现了刑事责任年龄的计算数值来源和计算过程。
答:不是。具体推算过程的显示,主要解决:日期格式统一的标准化,从而实现日期的可计算性。
如上文所述,防止AI在遇到未处理、不可直接计算的日期类数值时,跳转引用错误的事实作为替代,导致错误扩散。这也是众多主流模型常掉的大坑(更多类似实例和相关数值处理技术,请见往期技术分享中AI莫用数值幻觉忽悠法律人:1/3≠30%)。
为什么读者受测AI可以实现并显示具体推算过程的呢?
经与读者交流,这得益于在案件工作台配套了包括日期推导在内的法律计算器,专门解决法律文本中的计算幻觉问题。
此外,小编发现,在具体推算结束后,读者受测AI仿佛生怕用户被蒙在鼓里,一语道破了埋在案件材料中的坑 。即“公众常识中‘生日即满岁’的日常认知与法律计算规则之间差异的混淆”。
。即“公众常识中‘生日即满岁’的日常认知与法律计算规则之间差异的混淆”。
经法条依据、实务规则和具体计算多重校验后,读者受测AI最终得出正确结论。更重要的是,包括数据格式标准化和计算推导在内的每个分析推理步骤,可追溯回查,构成一份清晰、扎实的办案“底稿”。
以下为实测图三:

读者指出,在结论部分,受测AI会根据用户选择的分析立场,全面且结构化地阐述、强调和被选当事人相关主要法律后果。其结构化体现于,每个要点均先列示相应的法条依据,即做到句句言之有据,防控推理终点幻觉。
此外,当看到读者受测AI生成这句补充说明“‘应当’为强制规范,非‘可以’”,让小编感觉重回法理学课堂,仿佛看到熟悉的教授敲黑板强调着“应当”与“可以”的区别……
以上是本期分享。下期将继续分享关于读者受测AI Agent的合同审核实测。
关于该受测AI的名称,这位来自上海的读者只让说一个谜语:
把1234567音阶哼一遍,第4和第58个音连在一起是谜底。
若五音不全,谜底则藏在《音乐之声》其中两句的开头:
Far, a long long way to run
So, a needle pulling thread~
而这两句歌词,感觉恰预示着我国法律AI的“张雪机车”之远征……
法律AI四大语料系列(二):当法律 RLHF × 翁家翌 HL,能修炼出姚顺雨 CL-Bench 期待的上下文自我精进模型吗?
法律AI四大语料系列(三):当法律 RLHF × 翁家翌 HL,能修炼出姚顺雨 CL-Bench 期待的上下文自我精进模型吗?
人大高瓴LawThinker智能体,知识探索-显式验证-记忆策略:突破性挑战法律AI那么多的不可能(一)
人大高瓴LawThinker智能体,知识探索-深度验证-记忆机制:突破性挑战法律AI那么多的不可能(二)
终篇 | 人大高瓴LawThinker智能体,知识探索-深度验证-记忆机制:突破性挑战法律AI那么多的不可能(三)
腾讯姚神团队的CL-bench论文:别被全球法律科技股的暴跌吓倒!
Legal Agent”靠谱度“怎么看?HTC框架当”裁判“!
Jieba 不结巴?法律 NLP 实战干货| 告别法律 paper work 搬砖,高效处理法律文本(长文收藏)
聊透 RAG 不迷糊,再看 LawThinker 如何精准突围RAG去幻死角
全国首例 AI 幻觉侵权案刷屏:小搓“去幻”代码,专治AI“擅自表态”
400起商标侵权案背后的AI大模型欺诈恶意诉讼:小搓 “反样本污染”去幻觉代码
AI 幻觉案五国裁判盘点:典型案件及其审判逻辑异同(纯干货贴)
本公众号内所有原创文章、图片、音频、视频等内容,包括但不限于文字表述、创意构思等,其著作权均归本公众号Pat-Rainbow所有。未经本公众号运营主体明确书面授权,任何单位或个人不得擅自复制、转载、摘编、修改、链接、传播或以其他任何方式使用本公众号内的内容。若需转载,请提前联系我们并获取书面同意,同时需在转载时注明文章来源、作者及原文链接,且不得对内容进行任何实质性修改或删减。
免责声明:本公众号部分内容可能来源于互联网,如有涉及版权问题,请版权所有者及时与我们联系,我们将在核实后第一时间予以删除或处理。
