 夜雨聆风
夜雨聆风因公众号更改推送规则,请点“在看”并加“星标”第一时间获取精彩技术分享
点击关注#互联网架构师公众号,领取架构师全套资料 都在这里
上一篇:2T架构师学习资料干货分享
大家好,我是互联网架构师!
上周,我花了一下午,把 DeepAudit 跑在了自己一个老项目上。
那是一个三年前的 Python 项目,大概两万行代码,我自己写的,心里大概有数——肯定有坑,但应该不至于太离谱。结果 DeepAudit 跑完,给我报了 17 个「严重」级别的问题,其中 3 个它声称能 PoC 验证通过。
我盯着那个报告看了很久。一方面觉得「这玩意儿有点东西」,另一方面又隐隐不安——它说的这些漏洞,真的存在吗?
先说结论:DeepAudit 确实能挖出来东西。
GitHub 上 6k+ Star,团队拿它跑了一批国内知名开源项目,挖出了 49 个 CVE,全部在 NVD 上能查到。禅道 PMS 的 SSRF、Dataease 的 JNDI 注入、H2o-3 的反序列化、O2OA 的 XSS 批量……这些都不是自娱自乐,是被官方确认过的真实漏洞。
从「能挖到」这个维度,它通过了最硬的考核。
但「能挖到」和「能放心用」之间,隔着一条挺宽的河。
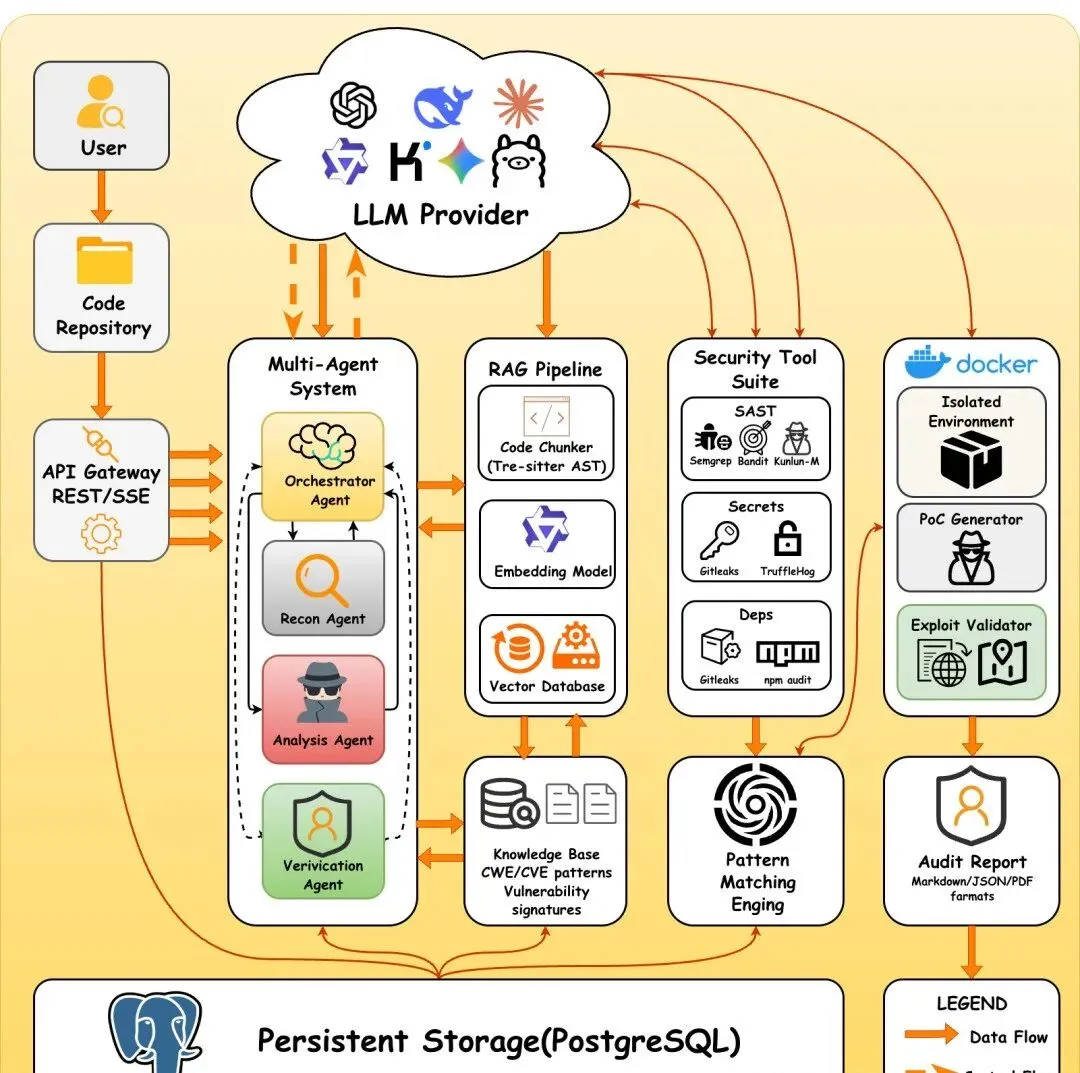
DeepAudit 的架构,设计得挺聪明。
四个 Agent 分工协作,不是那种「包一层 Claude 就敢叫 Agent」的伪智能:
Orchestrator:总指挥,分析项目结构、判断技术栈、拆解任务
Recon Agent:侦察兵,扫描依赖、找 API 入口、画攻击面
Analysis Agent:分析师,挂 RAG 知识库,做语义比对找漏洞
Verification Agent:验证官,写 PoC 脚本,扔进 Docker 沙箱跑,跑通才进报告
Verification Agent 是最核心的差异点。 传统 SAST 工具,比如 Semgrep,告警 100 条,真的可能只有 50 条。DeepAudit 理论上只留能打通的——PoC 跑成功,才算数。
这个设计思路是对的。但问题在于,「理论上」和「实际上」是两回事。
我实际跑下来的感受:
第一,它对模型能力的要求不低。
四个 Agent 都是 ReAct 格式驱动(Thought / Action / Action Input),模型必须稳定遵循这个格式。我用 GPT-4o 跑,基本没问题。换成本地 Ollama 的 Qwen2.5-7B,跑了三步就开始格式漂移,Agent 编排直接断掉。
「支持 Ollama」≠「什么模型都能用好」。 小参数模型在复杂推理任务上,还是撑不住。
第二,大仓库扫起来又慢又贵。
我那两万行代码的项目,GPT-4o 跑了四十多分钟。如果是一个几十万行的大型项目,光 API 费用就不是小数目,时间可能要以小时计。传统 SAST 比如 Semgrep,几秒钟出结果,速度上根本不是一个量级。
第三,PoC 验证不是万能的。
DeepAudit 在 SQL 注入、命令注入这类通用型漏洞上效果好。但如果漏洞触发需要复杂的多服务环境,沙箱建不起来。或者遇到内存破坏漏洞,自动生成的 PoC 成功率直接打折。
报告显示「验证通过」,不代表真的 100% 可利用。 这个边界,README 里写得不够清楚,容易让人误判。
第四,报告质量有瑕疵。
我遇到的几个具体问题:漏洞路径有时候是绝对路径,有时候又缺失;行号偶尔有偏差,定位代码时要自己再对一遍。这些问题不算致命,但用在正式审计工作里,会增加人工复核的成本。
但这些问题,不代表 DeepAudit 没价值。
它的价值在于方向——用 Multi-Agent + RAG + PoC 验证,把 AI 代码审计从「静态规则匹配」推向「动态验证」。这个思路是对的,而且比传统工具更接近「真实漏洞发现」的本质。
对安全研究人员来说,它是一个很好的辅助工具。对中小团队做自有项目的安全摸底,也有用——至少能帮你发现那些「一眼就能看到」的硬编码密码、SQL 注入、命令注入。
但它现阶段不适合当「主力」。
原因不是功能不够,是成熟度不够。社区反馈里有加载项目失败、镜像拉取失败、偶尔卡死的问题。AGPL-3.0 协议也意味着商业集成需要谨慎。更重要的是,它会漏掉东西,也会误报,你需要有足够的安全背景去判断哪些该信、哪些该 discard。
写到这,我想聊聊「AI 代码审计」这件事本身。
很多人看到「AI + 安全」的组合,第一反应是「安全工程师要失业了」。但用了 DeepAudit 之后,我的感受恰恰相反——AI 不是在替代安全工程师,是在放大他们的能力边界。
以前一个安全工程师审代码,一天能看几千行就不错了。AI 工具能帮你快速扫一遍,把「明显有问题」的地方标出来,省下的时间用来做深度分析、做 PoC 验证、做漏洞利用链的梳理。
但 AI 不会替你做判断。 它报了一个「严重」级别的漏洞,你需要判断:这是真的吗?利用条件是什么?影响范围有多大?修复优先级怎么排?这些决策,AI 做不了,也不该让它做。
DeepAudit 最好的用法,是「第一遍筛子」。 让它快速过一遍,把可疑点标出来,然后人工复核。而不是直接把它当「终审法官」,它说有问题你就修。
最后,给想试试的人几个建议:
优先用 Ollama 本地部署审私有代码,避免代码泄露到第三方 API
大项目分批扫,不要一次性扔进去几十万行,钱包和耐心都扛不住
报告里的每个「严重」都要人工复核,不要直接转给开发团队
小参数本地模型谨慎用,格式漂移会让你怀疑人生
AGPL-3.0 协议读清楚,商业集成前先找法务
项目地址:github.com/lintsinghua/DeepAudit
协议: AGPL-3.0
如果你也是安全工程师,或者正在用 AI 工具做代码审计,欢迎评论区聊聊你的体验——它帮你挖到过什么?又让你踩过什么坑?
最后,关注公众号互联网架构师,在后台回复:2T,可以获取我整理的 Java 系列面试题和答案,非常齐全。
如果这篇文章对您有所帮助,或者有所启发的话,帮忙扫描上方二维码关注一下,您的支持是我坚持写作最大的动力。
