 夜雨聆风
夜雨聆风6 月 24 日晚,旧金山时间下午。
我盯着 Twitter 上的那段 47 秒视频看了三遍。博通 CEO Hock Tan 双手捧着一个银色小盒子,递给 Sam Altman 和 Greg Brockman 。
盒子里装的不是别的——是 OpenAI 历史上第一颗自研 AI 芯片,代号 Jalapeño(墨西哥辣椒)。
我愣了一会儿。然后我去刷英伟达的盘后股价,几乎没动。
不应该没动。
我心里咯噔一下。
这种感觉很难描述——不是兴奋,是有点慌。盘后没动,意味着市场还没看懂这件事。但对任何一个在芯片圈混了几年的人, 9 个月这个数字已经够炸裂了。
为什么慌?我自己说不太清楚。先往后看吧。

一、一颗叫"辣椒"的芯片,到底是什么
先把事实摆出来。
当地时间 6 月 24 日, OpenAI 联合博通正式发布 Jalapeño 。官方英文名字是 "Intelligence Processor"——它自己发明了一个新词。专为大语言模型( LLM )推理设计,不是训练,是推理。
三方分工极其清楚:
发布现场有四个名字被反复念到——Hock Tan 、 Charlie Kawwas 、 Sam Altman 、 Greg Brockman。
几个关键数字需要记住:
9 个月。 从白纸一张到工程样片跑通 GPT-5.3-Codex-Spark ,只用了 9 个月。行业惯例是 18 到 24 个月。 Google TPU 两年一代, Amazon Trainium 大致也是这个节奏。AI 替 AI 砍掉了那 18 个月里最磨人的"设计—验证—改—再验证"循环。
50%。 官方说推理成本可以省 50%。每瓦性能将大幅优于当前业界最先进水平——这是 Broadcom 投资者关系页面上原话,没给具体数字,但"大幅"两个字在英文公告里只出现一次。
千兆瓦( GW )级。 2026 年底开始首批部署。规模是吉瓦级数据中心——这意味着单单一颗推理芯片要撬动的电力,相当于两到三个核电站的稳态输出。
2%。 博通股价当天盘中一度涨 2%。市场反应不算剧烈——可能因为英伟达跌得也不多,整个故事还在"传言变事实"阶段。
扯。
这哪儿是不剧烈。这分明就是 6 月 24 日当天最大的一件事,只是没几个人敢在收盘前下注。黄仁勋在第二天财报电话会上大概率要直面这个问题。我等不及想看他怎么回。
微软合作。 首批 GW 级数据中心跟 Microsoft 一起搞。 Celestica 负责把芯片变成机柜。
Greg Brockman 发的原话是:"世界正在向算力驱动的经济转变。 Jalapeño 是我们长期全栈基础设施战略的一部分。"
Brockman 还说了句挺刺耳的话——"通过自行设计更多技术栈,我们可以以更高效率提供更多智能。"
更高效率提供更多智能。翻译成大白话就是:我自己造心脏,别让中间商赚差价。
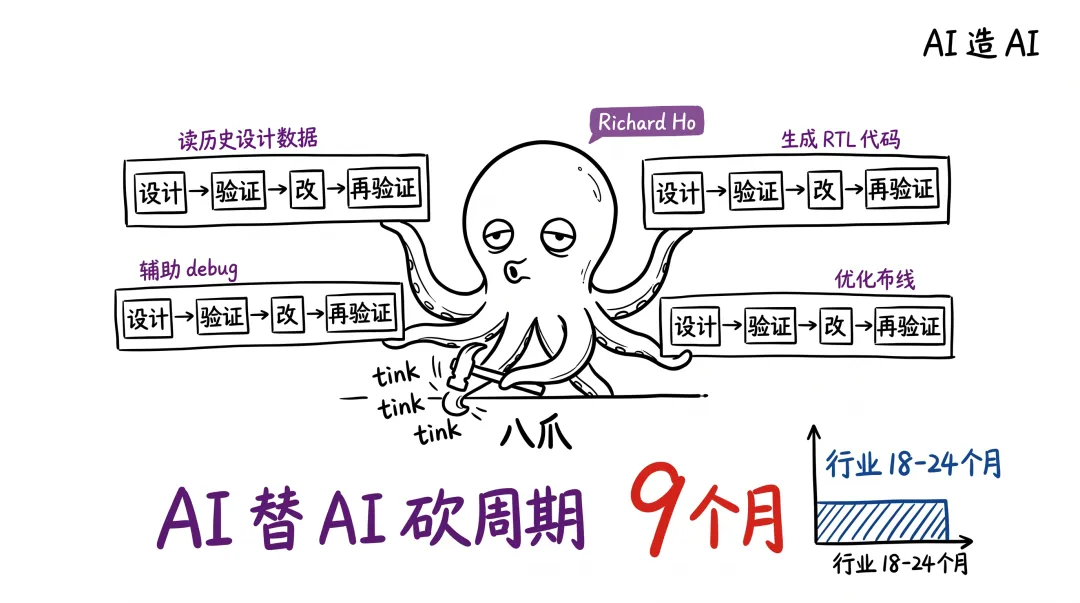
二、 9 个月是怎么挤出来的——AI 给 AI 动手术
我做了八年科技记者,看过无数芯片发布。能 9 个月从零流片到跑通大模型,这在以前是科幻。
核心提速点在三块——
第一块是 Richard Ho 这个名字。 OpenAI 硬件项目负责人,Google TPU 待了将近九年。是 TPU 高级工程总监级别的老人。后来去光子计算公司 Lightmatter 当高级副总裁,又联合创办了 EDA 公司 0-In Design Automation 。这个人的简历,就是 ASIC 工程经验的浓缩包。
第二块是 OpenAI 自家模型直接参与了芯片设计。 读历史设计数据、生成 RTL 代码、辅助验证和 debug 、优化布局布线。不是辅助,是干了一半的活儿。这是 AI 替 AI 砍周期的根本。
恐怖吧?细想。
第三块是 OpenAI 的工作负载极度清晰。 它知道自己要跑什么——ChatGPT 、 Codex 、未来的 agent 。不是造一颗通用芯片,是造一颗专门给 LLM 推理用的窄门芯片。这意味着架构选择可以很激进,不用照顾通用场景。
Greg Brockman 讲得很坦白:"我们对工作负载有深入理解。我们一直在寻找那些服务不足的特定工作负载。"
说白了——OpenAI 比任何一家芯片公司都更懂 LLM 跑起来是什么样子。这才是它敢下场的真正底气。
Richard Ho 的原话更值得琢磨:"为模型要去的方向设计硬件,而不是为它现在的样子。"
一个卖硬件的负责人,先承认自己设计的是为"未来模型"准备的硬件。这话说得漂亮,但也很冒险——如果 GPT-6 走的是另一条路呢?
但反过来想,不冒这个险,永远都是给英伟达打工。
我盯着 OpenAI 的招聘页面看了半天。硬件团队还在招人,从 9 个月前的 20 人小分队,今天已经接近 200 人。这速度,跟 Google TPU 团队的扩张曲线几乎一模一样。
嗯。
这才是真问题。OpenAI 不只是造一颗芯片。它在复制 Google TPU 团队的全部打法。

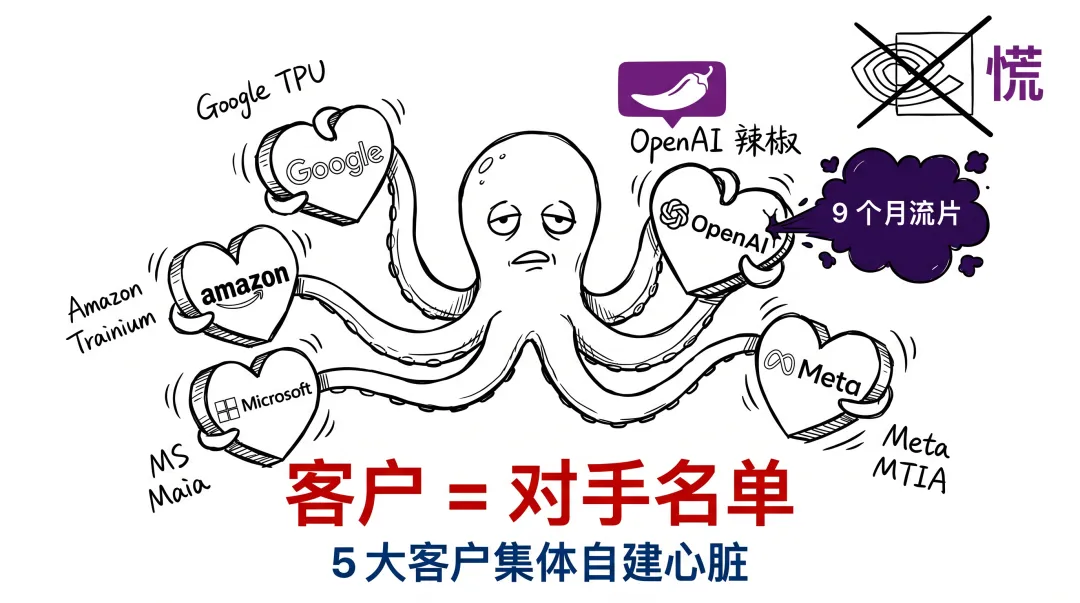
三、英伟达的客户名单,正在变成对手名单
更让我心里一紧的是另一张图。
我把过去 5 年主要 AI 客户的"自研芯片"动作摆在一起看:
| 公司 | 自研芯片 | 用途 | 跟英伟达关系 |
|---|---|---|---|
| TPU v4/v5/v6 | 训练 + 推理 | 跟英伟达并存 | |
| Amazon | Trainium / Inferentia | 推理为主 | 跟英伟达并存 |
| Microsoft | Maia 100 / 200 | 推理为主 | 跟英伟达并存 |
| Meta | MTIA v1/v2 | 推理 + 推荐 | 跟英伟达并存 |
| Apple | 神经网络引擎 + M-series | 端侧 + 云侧 | 跟英伟达无直接关系 |
| OpenAI | Jalapeño | 推理 | OpenAI 既是英伟达最大客户之一,又是新对手 |
这不是巧合。这是英伟达的最大客户在集体自建心脏。
反面假设一下——如果 OpenAI 把推理负载 50% 切到 Jalapeño 上, 2027 年会怎样?
按 OpenAI 现在年算力支出"百亿美元级别"算,50% 切走意味着 50 亿美元规模的订单从英伟达账上消失。一年。
50 亿什么概念?差不多是英伟达 2025 年单季净利润的三分之一。
这事儿如果真发生,英伟达那一年的故事会很难讲。
但这还不是最可怕的。
最可怕的是,英伟达的客户每走一个,就多一个会对外卖芯片的对手。
Google TPU 现在已经通过 GCP 对外服务。 Amazon Trainium 也开始接外部客户。未来 Broadcom + OpenAI 这条路跑通, OpenAI 会不会也对外卖 Jalapeño 推理服务?
别说不可能。
Meta 5 月刚裁了 8000 人、亚马逊裁了 3 万、 Microsoft 也在调整。如果这些被裁出来的硬件人才自己组队,用 Broadcom 的网络 + OpenAI 验证过的架构 + Celestica 的机柜,做出一颗 inference-as-a-service 的芯片,对英伟达才是真正的一刀。
扎心。
我说得有点远,但方向不绕。
英伟达的护城河不是 GPU ,是 CUDA 软件生态 + NVLink 网络 + 系统级优化。 这些东西,理论上也能被复制,只是需要时间。
Jalapeño 不直接挑战 CUDA——但它证明了"客户自研"这条路 9 个月就能跑通。
这个信号,比芯片本身更危险。
9 个月。我反复念这个数字。
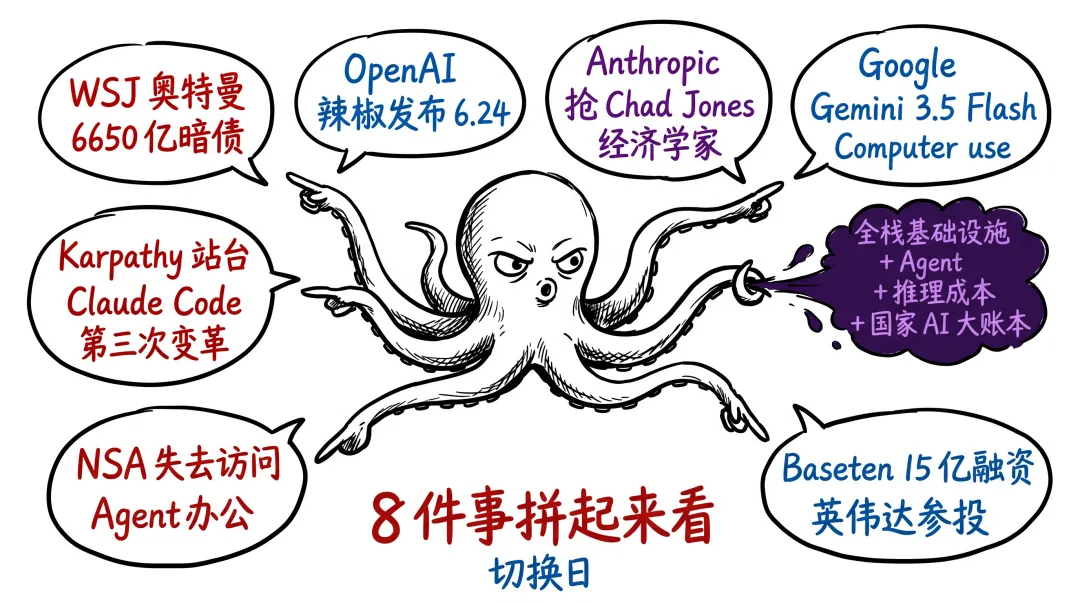
四、 6 月 24 日那 12 小时, OpenAI 之外还发生了什么
真正让我失眠的,是 Jalapeño 只是 6 月 24 日那 12 小时里的第一条新闻。
我把当天主要动作捋一遍——
0:30 早——WSJ 曝光奥特曼的"私人提款机"。 OpenAI 机密 IPO 文件中暴露约 6650 亿美元的潜在债务与或有支出。奥特曼本人对 OpenAI 持股接近 0 ,但通过关联交易形成上百亿美元的造富闭环。
上午——OpenAI 联合博通发布 Jalapeño 。
下午——Anthropic 拿下斯坦福经济学讲席教授 Chad Jones,长期经济增长、技术进步方向。 Anthropic 在 IPO 敲钟前夜密集延揽诺奖级、泰斗级经济学家,它在为"国家 AI 大账本"提前组队。
下午——Google Gemini 3.5 Flash 上线 Computer use 能力。模型可直接读取屏幕内容、驱动浏览器与桌面应用完成任务。Flash 层级——这意味着走的是高频日常任务自动化,跟 OpenAI / Anthropic 的"重型 agent"形成差异化。
下午——Anthropic Claude Code 大升级。Karpathy 直接出来站台——"这是 LLM 用户界面的第三次变革——前两次分别是网页版聊天和桌面应用,这次 Claude Code 直接以系统级 Agent 的形态存在。"
晚间——豆包 2.1 Pro 上线 Agent 办公任务。 36 氪实测对标 Claude Opus 4.6 。豆包日活已破 2 亿——国内第一款把 Agent 办公任务直接放进国民级 AI 应用的尝试。
晚间——纽约时报曝光 NSA 在与 Anthropic 的合同争执中失去对其顶级 AI 模型访问权限。白宫被迫推出"政府专用 / 内网化"的 AI 模型部署方案。
晚间——Baseten 拿下 15 亿美元(约 101 亿人民币)新一轮融资,估值 130 亿美元,英伟达参与。这家做企业级 AI 推理基础设施的公司,过去 18 个月收入暴增 2000%。
8 件事。OpenAI 造自己的芯片、 Anthropic 抢经济学家、 Google 让 Flash 能动鼠标、 Karpathy 站台 Claude Code 、豆包 Pro 抢 Agent 办公、 NSA 被 Anthropic 拒之门外、英伟达一边被客户背刺一边继续投推理基础设施、奥特曼的暗债 6650 亿浮出水面。
你说巧不巧?
不巧。这是必然。
我看到的是一张图: AI 行业正在从"模型能力比拼"切换到"全栈基础设施 + 系统级 Agent + 推理成本 + 国家 AI 大账本"四线并进。 Jalapeño 只是其中最响的一声枪。
但如果只盯 Jalapeño ,你会漏掉一个更狠的信号——Baseten 那一轮,英伟达自己投了。英伟达最清楚推理侧要变天了。它押注的不只是 GPU ,是"GPU + 自研 ASIC 混合架构"会成为新常态。
这跟甲骨文 6 月 22 日 10-K 披露的"21,000 人 AI 替代"逻辑是通的——算力不是越来越贵,是单位算力的成本要塌方式下降。 Jalapeño 是这场塌方的第一块多米诺。
整条链上的每一家,都在重新算账。
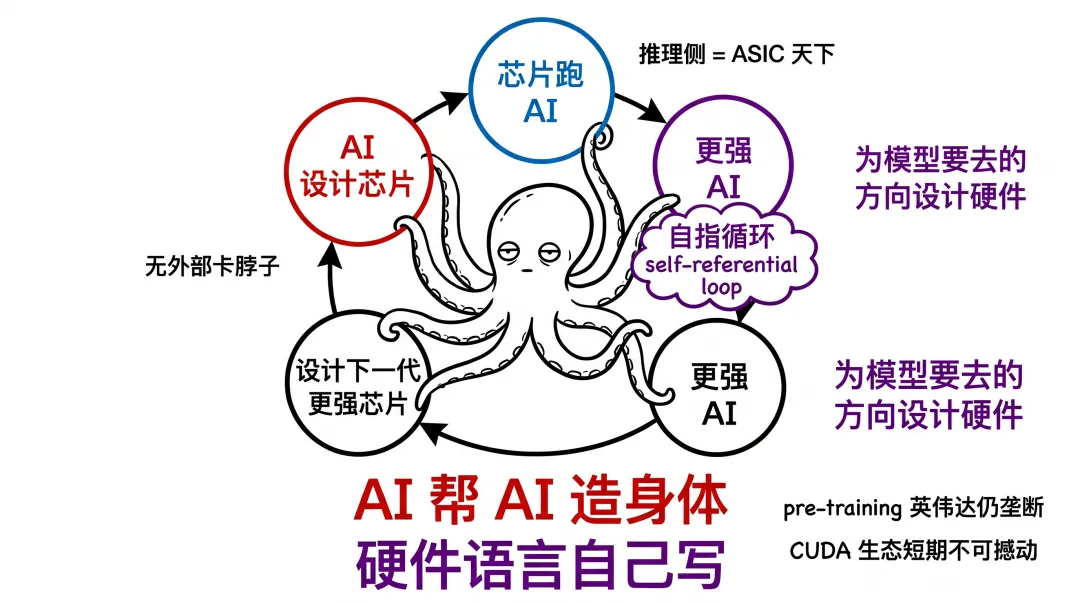
五、真正的剧本: AI 开始给自己写硬件语言
Jalapeño 真正的剧本,不在博通的硅片上。
在 OpenAI 自己的模型里。
AI 设计芯片 → 芯片跑 AI → 更强 AI 设计下一代更强芯片。
这是自指循环( self-referential loop )。一旦跑起来,没有外部力量能再卡住它的脖子。
Richard Ho 讲:"为模型要去的方向设计硬件。" 这话的潜台词是——AI 自己知道未来的硬件该长什么样。这不是人类工程师的判断,是 AI 自己的判断。
等等。那英伟达的设计师呢?他们的判断还作数吗?
细想,这问题其实有点冒犯。但我必须问出来。
Greg Brockman 讲得更哲学:"世界正在向算力驱动的经济转变。"
翻译过来——未来 10 年最重要的生产资料是算力,最重要的公司是掌握算力的公司。 OpenAI 不再满足于做最聪明的模型,它要做最便宜、最高效的算力本身。
反面假设再走一步——
如果 2027 年英伟达不降价 30%, Anthropic 和 Google 会不会也下场自研推理芯片?
如果 Anthropic 学 OpenAI 找博通做一颗自己的 Jalapeño , AWS 会不会把它放进 Trainium 3 的机柜?
如果三大云都这么做, 2028 年的推理市场会变成什么样?
我不知道答案。但 Jalapeño 给了我一个观察框架——
9 个月。
9 个月前, OpenAI 还在买 GPU 。
9 个月后,它把自己最大的供应商变成了一个"还在卖 GPU 、但被客户背刺"的尴尬角色。
这个速度,所有人——包括英伟达自己——都低估了。
糟心。
剩下的问题不是"英伟达会不会被替代"。英伟达在 pre-training 高性能计算上还是垄断地位, CUDA 生态短期不可撼动。
问题更像是——"推理侧"正在变成 ASIC + 自研芯片的天下,而"训练侧"可能 2-3 年后也会被分走一块。
留给英伟达的时间窗口,比所有人以为的都要短。
说回那颗叫"辣椒"的芯片。
为什么叫 Jalapeño ? 因为这是辣度较温和的品种。 Sam Altman 给第一颗芯片起这种名字,潜台词很可能是——这只是入门级,后面可能还有更辣的。
这话在硅谷的语境里,等于"我们的芯片路线图至少三代"。
Jalapeño 是 starter 。
主菜还在后头。
剩下的事,我们继续看。
