 夜雨聆风
夜雨聆风
这两天,Baidu 在 HuggingFace 上悄悄放出了一个很有意思的模型:Unlimited-OCR。 从官方仓库信息来看,它的定位已经不再是“传统 OCR”,而是更接近“通用文档理解 + 超长上下文解析”的一体化方案。
如果你最近在做 PDF 解析、RAG 数据清洗、复杂文档结构抽取,甚至是多页长文档理解,那么这个模型值得认真看一眼。因为它解决的,不只是识别精度问题,而是把“长文档解析”这件事往工程可用性上又推了一步。
更关键的是:现在已经可以一键本地部署了。
本文就分三部分讲清楚: Unlimited-OCR 在做什么、为什么它开始变火、以及如何一键本地跑起来(含 Windows / Docker / macOS)。
Unlimited-OCR 在解决什么问题
从官方 HuggingFace 页面可以看出,Unlimited-OCR 的核心思路非常明确:突破传统 OCR 在“长文档 + 复杂结构”上的限制。
过去的 OCR 或文档解析模型,通常有几个明显问题:
上下文长度有限,多页 PDF 会被切碎处理
表格 / 段落 / 图文关系容易断裂
跨页语义无法对齐(比如标题-正文-附录)
很难直接用于 RAG 或结构化入库
Unlimited-OCR 的“Unlimited”,本质上是在强调:它尝试用更长上下文 + 更强结构理解能力,把整份文档当成一个整体来处理。
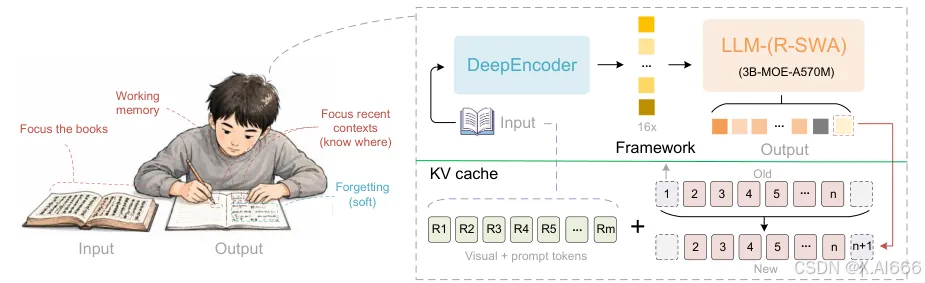
可以理解为:
传统 OCR:逐块识别 Unlimited-OCR:整篇理解 + 结构建模 + 再输出
这在实际工程里影响非常大,比如:
PDF → Markdown / JSON 的一致性明显提升
多页表格可以合并而不是断裂
标题层级、阅读顺序更稳定
更适合直接喂给 RAG pipeline
举个简单例子:
一份 50 页财报:
传统 OCR:你得到 50 页碎片文本
Unlimited-OCR:你更可能得到结构连续的文档语义表示
这就是它的核心价值。
为什么最近开始火
原因其实和 PaddleOCR-VL 很类似,但更进一步。
当前文档处理的趋势已经很清晰了:
不再满足“识别文字”
而是要求“直接变成可用数据”
尤其是在这些场景:
RAG 知识库构建
PDF → Markdown 自动化
法律 / 财务 / 论文解析
企业文档数字化
传统 OCR 最大的问题是:它输出的是“文本”,但工程需要的是“结构”。
Unlimited-OCR 这一类模型,本质是在做:
OCR → Document Understanding → Structured Output
这也是为什么它会突然被很多做 RAG 和文档系统的人关注。
一个关键变化:已经可以一键部署
如果只是模型强,其实还不够。 真正重要的是:能不能快速落地。
这次比较实用的一点是,你可以直接用这个项目一键部署:
GitHub:https://github.com/CHEN010325/paddleocr-local,
运行画面如下所示ui操作也很便利
现在已经直接支持 Unlimited-OCR 一键集成,而且做了两套后端:
Transformers(更稳定,推荐优先)
SGLang(性能更激进,但更挑环境)
Windows / NVIDIA Docker 一键部署
核心一句命令就够:
.\windows-one-click.bat -Models unlimited-ocr -UnlimitedOcrBackend transformers
或者用 SGLang:
.\windows-one-click.bat -Models unlimited-ocr -UnlimitedOcrBackend sglang
这里有几个关键点你需要知道:
Transformers 更稳,基本开箱可用
SGLang 对 CUDA / 显卡架构 / attention backend 要求更高
第一次一定会慢(要拉模型权重 + 构建容器)
另外一个更灵活的方式是:
先只部署 PaddleOCR-VL / PP-OCRv6
然后在 WebUI 里切换 Unlimited-OCR
系统会自动帮你下载 + 构建
这一点对调试非常友好。
macOS(Apple Silicon)也能跑
./macos-one-click.command
但这里一定要注意几个现实问题:
使用的是 MPS 兼容模型(不是完整 GPU CUDA 路径)
默认策略偏保守(避免爆内存)
性能不能和 NVIDIA GPU 对标
简单说:
macOS:能用,适合体验 / demo
NVIDIA:才是主力生产环境
一些你一定会踩的坑(提前说清)
这个模型“强”的代价也很现实:
首次下载非常慢(模型很大)
显存占用高
SGLang 依赖环境容易炸
不同 GPU 架构兼容性差异明显
建议:
Windows + NVIDIA → 先用 Transformers
想极限性能再尝试 SGLang
不要一上来就怀疑代码问题,很多是环境问题
适合哪些人用
结合我自己的测试经验,这类模型更适合:
做 RAG 数据清洗 / 文档预处理的人
搭建企业知识库系统的开发者
需要解析复杂 PDF(论文 / 财报 / 合同)的场景
想做“文档理解 Agent”的项目
如果你只是:
截图识别
简单 OCR
那它其实有点“杀鸡用牛刀”。
总结一句话
Unlimited-OCR 真正有价值的地方,不是“识别更准”, 而是它在尝试解决一个更关键的问题:
如何把“整份文档”直接变成“可用结构数据”。
而现在最关键的一步是: 它已经不是只能看 Demo 的模型,而是可以一键本地跑起来、接入工程、直接用的东西。
如果你觉得这篇文章对你有帮助,也欢迎给我一个三连击:点赞、转发和在看;如果可以,再帮我点一个⭐️。谢谢你看到这里,我们下篇再见。
