 夜雨聆风
夜雨聆风
今天,我们要解读这篇顶刊,来自国防科技大学等单位的团队,在《IEEE Transactions on Image Processing》上提出了一种全新的解决方案——SARATR-X,首次将“基础模型”(Foundation Model)的理念引入SAR目标识别领域。
当世界失去“可见光”,人类如何继续看见?
在漆黑的夜晚、厚重的云层、甚至暴雨与台风之中,普通摄像头几乎失效。但人类并没有失去“视觉”。
因为有一种技术,正在替代眼睛——合成孔径雷达(SAR)
它可以穿透云层、黑夜,甚至在一定程度上穿透遮挡物,实现全天时、全天候成像。

问题是:我们“拍得清”,但机器“看不懂”。
核心矛盾:SAR 不是不能成像,
而是“太难理解”
SAR 图像与自然图像完全不同:
没有真实颜色
强烈斑点噪声(speckle noise)
目标形态扭曲严重
背景复杂且不稳定
这导致一个长期困境:
❌ 传统 SAR 目标识别的三大问题
1.任务割裂严重
车辆识别一个模型
船舶识别一个模型
飞机识别再训练一个模型每个任务都是“从零开始”
2. 极度依赖标注数据
需要SAR专家逐个标注
成本高、速度慢、规模小
3. 泛化能力极弱
换一个成像角度 → 直接失效
换一个传感器 → 重新训练
关键转折:研究者想做一个
“SAR领域的GPT”
面对这些问题,国防科技大学等团队提出了一个大胆目标:能不能做一个“通用 SAR 基础模型”?
就像:
NLP 的 GPT(语言通才)
CV 的 CLIP / SAM(视觉通才)
他们给出的答案是:
SARATR-X
一个目标明确的愿景:用一个模型,统一解决 SAR 目标识别、检测与泛化问题。
整体思路:三步走打造“雷达视觉大模型”
SARATR-X 的核心可以概括为一句话:
用“海量无标注数据 + 自监督学习 + SAR专用结构”,训练一个通用视觉表征模型。
数据层:构建 SAR 世界的“语料库”
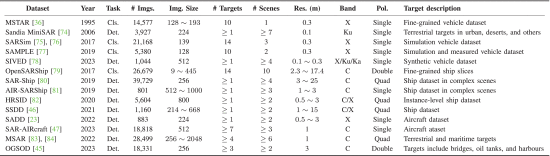
研究者做了一件非常关键但工程量巨大的工作: SARDet-180K 数据集
这是目前公开规模最大的 SAR 目标预训练数据集:
18.66 万 + 样本
来自 14 个公开数据集
车辆/船舶/ 机/油罐/桥梁等
覆盖城市/港口/海洋/机场
多传感器、多分辨率、多成像条件
核心意义:第一次把“碎片化 SAR 数据”统一成可学习的基础语料库;这一步,本质是在做:SAR领域的“ImageNet化”
模型层:为 SAR 定制的视觉Transformer
如果直接用CNN或普通ViT,会出现一个问题:小目标被下采样丢失
因此他们选择并改造了:HiViT(分层 Vision Transformer)
它的优势在于:
保留高分辨率特征
更适合小目标识别
支持多尺度建模
天然适配 Masked Image Modeling(MIM)
为什么适合 SAR?
因为 SAR 图像有三个特点:
目标小
背景复杂
信息稀疏
HiViT 正好对应解决这些问题。
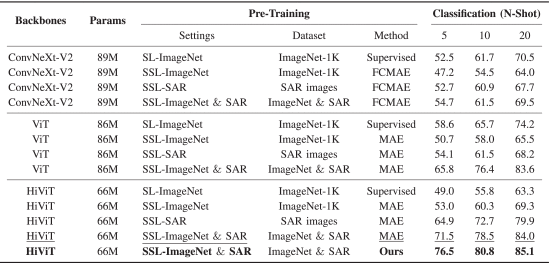
训练策略:两阶段自监督学习
这是整个系统的“灵魂”。
Stage 1:ImageNet 预训练(打基础)
先在自然图像上训练:
边缘
纹理
形状
目的不是迁移语义,而是:给模型一个“视觉常识初始化”,避免模型在 SAR 噪声中“学歪”。
Stage 2:SAR 自监督学习(核心能力)
在 SAR 数据上进行:
Masked Image Modeling(MIM)
类似“图像完形填空”:
随机遮挡图像块
让模型预测被遮挡部分
❗关键挑战:SAR噪声太强
SAR 图像存在严重问题:
相干斑噪声(speckle)
结构不清晰
像素级预测不稳定
如果直接用像素重建:模型会被噪声带偏
关键创新:多尺度梯度特征(MGF)
论文提出一个非常关键的设计:不预测像素,改为预测“结构”
具体做法:
用多尺度梯度比值特征替代原始像素
强化边缘与轮廓信息
抑制随机噪声影响
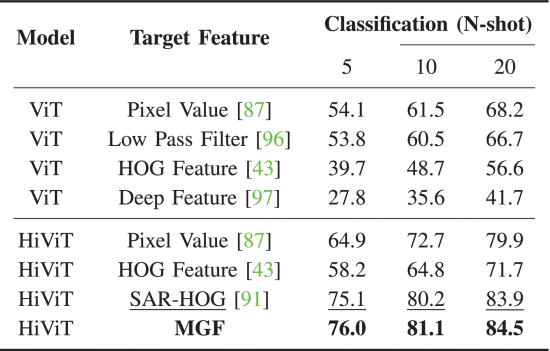
结果:
噪声影响显著下降
目标结构更清晰
模型更关注“形状”而不是“像素”
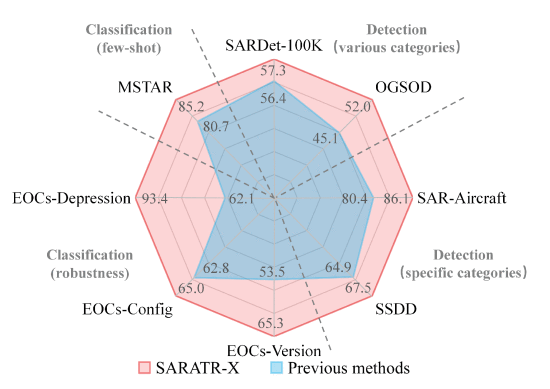
实验结果:全面领先传统方法
小样本分类(最关键能力)
在经典 MSTAR 数据集:
⭐ 1-shot 设置:
SARATR-X:85.2%
传统最优:80.7%
提升:+4.5%
⭐ 5-shot 设置:
达到:95.9%
更难条件(鲁棒性测试)
当条件变化时:
俯仰角变化:显著领先(最高+31.3%)
目标结构变化:+2.2% ~ +8.3%
目标版本变化:+11.8% ~ +20.3%
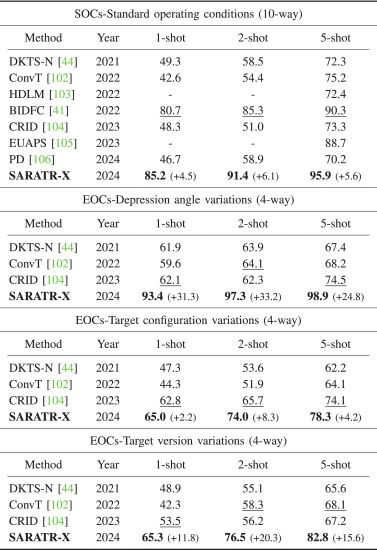
结论:
不只是“会识别”,而是“换环境也能识别”
目标检测任务
在多个检测数据集上:
SARDet-100K:mAP 57.3%
SSDD 船舶检测:AP 67.5%
飞机检测:mAP 58.7%,mAP50 86.1%
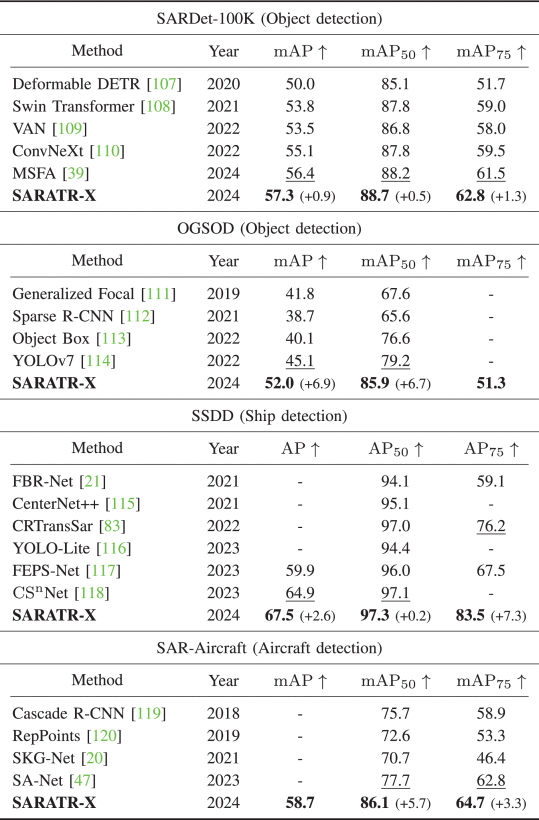
全面超越或持平专用模型
可解释性与扩展性
研究还发现:
模型不同层关注不同尺度信息
早期层关注边缘
深层关注整体结构
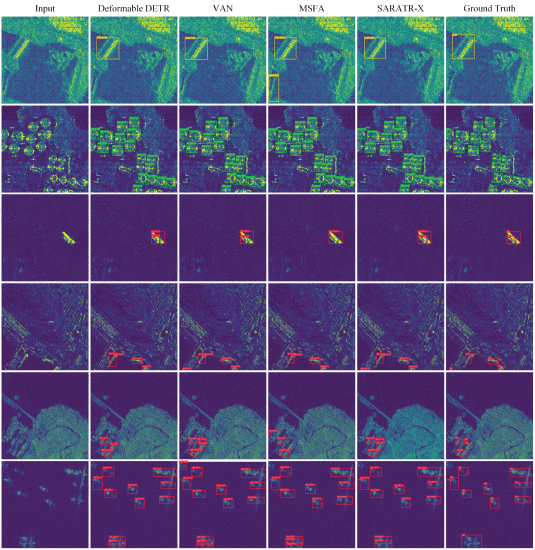
同时表现出明显“规模效应”:
数据越多、模型越大,效果持续提升,这是典型“基础模型特征”
本质总结:SARATR-X 为什么成立?
A
它的成功来自三层统一优化:
① 数据层革命
SARDet-180K
把“碎片数据”变成“统一语料库”
② 模型层优化
HiViT结构
解决:
小目标
多尺度
高分辨率保留
③ 学习层创新
MGF + 自监督学习
从:
“学像素” → “学结构”
意义:SAR 领域正在进入“基础模型时代”
A
SARATR-X 的意义不只是一个模型,而是一种范式转变:
从过去:
一个任务一个模型
强依赖标注
泛化能力差
到现在:
一个模型多任务统一
少样本甚至零样本适配
强泛化能力
结尾:雷达视觉的“GPT时刻”已经开始
A
SARATR-X 释放了一个非常明确的信号:
SAR 图像理解,正在从“手工工程时代”,进入“基础模型时代”。
未来可能出现:
通用SAR识别系统
全天候智能监测网络
自动灾害感知与军事解译系统
而这一切的起点,就是:
一个让机器“看懂雷达世界”的基础模型。
(注:本文基于2025年发表于《IEEE Transactions on Image Processing》的学术论文《SARATR-X: Toward Building a Foundation Model for SAR Target Recognition》进行解读,数据引用均来自原论文,仅供学术与技术交流,若有侵权行为,请联系我们删除。)
