 夜雨聆风
夜雨聆风我越来越警惕一种体验:一个 AI 工具第一次用起来太顺。
不是因为顺有什么不好,而是屏幕上那个突然出现的“成品”,很容易让人误判——以前那么麻烦的事,是不是已经被解决了?
输入一句话,Gamma 做出一套像模像样的演示文稿;描述一个需求,Lovable 直接跑起一个应用;把复杂问题交给 Perplexity Deep Research,过一会儿得到一份结构完整、带着引用的报告。
三个瞬间都很爽,也都很像“未来已经来了”。
可第一次体验结束后,一个更朴素的问题才刚刚开始:
下次遇到同样的任务,我还会不会打开它?
我的判断是:
第一次惊艳看的是能力上限,长期留下看的是产品下限。
上限决定你会不会截图、转发、拉同事过来看;下限决定你敢不敢把下一次真实任务交给它。
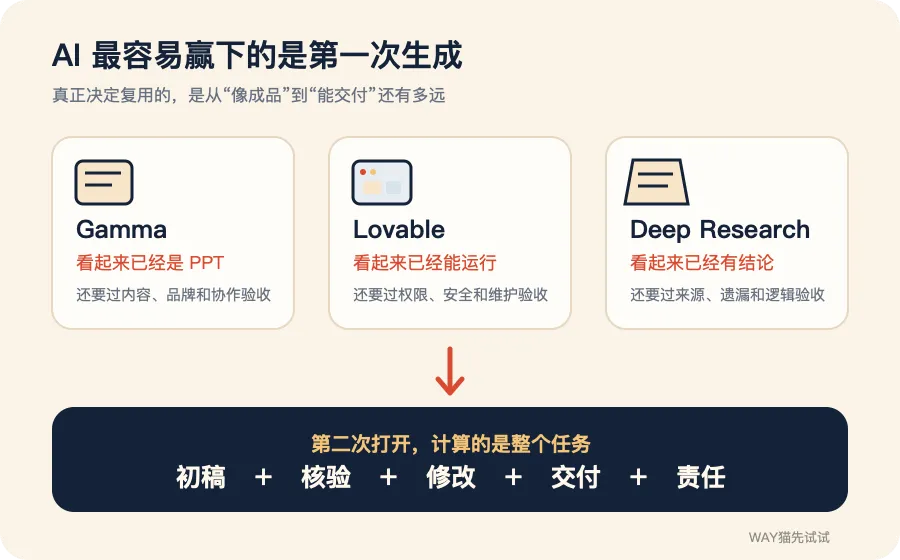
图:第一版生成与真实交付之间,仍隔着验收与收尾。
我挑了三个很适合观察这个问题的工具。
它们不是失败产品。恰恰相反,它们都在各自领域做出了非常强的“第一眼体验”。真正值得研究的是:为什么一种能力明明成立,却仍然可能没有进入一些人的长期工作流。
Gamma:看起来已经是 PPT,真正的工作可能刚开始
Gamma 的第一眼体验很有冲击力。
图:Gamma 的演示式生成界面。
给它一个主题或一份材料,它可以快速生成结构、文案、配图和版式。相比从空白 PowerPoint 开始拖文本框,那种“整套东西突然出现”的感觉,确实会让人松一口气。
而且今天的 Gamma 已经不是简单的一次性生成器。它支持自定义主题、API 批量生成,也能导出 PDF、PNG 和 PPTX。2026 年 5 月至 6 月,它还持续改善了 PowerPoint 和 Google Slides 导出的字体、背景、图标与文本容器。
所以现在还用一句“AI PPT 导出不行”评价它,既过时,也不公平。
真正的问题是:你最终需要的是一套看起来不错的演示,还是一份必须通过业务验收的 PPT?
后者通常还包括这些麻烦事:
• 哪一页应该删,哪个结论值得放大; • 数据口径对不对,图表有没有误导; • 是否符合公司的字体、颜色和版式规范; • 复杂表格、公式和流程图能不能精确编辑; • 交给同事以后,能否继续在 PowerPoint 里协作。
Gamma 官方帮助中心也提醒,导出内容以演示模式为准,第三方软件中的字体、渐变和布局可能存在差异;超长或图片很多的内容,也可能需要拆分处理。
这些并不意味着 Gamma 不好用。
如果是个人分享、早期提案、课程材料,或者直接用网页链接演示,它可能已经完成了大部分工作。
如果是严格的汇报模板、精确图表和多人修改,那么第一次生成之后,真正昂贵的部分才开始出现。
如果有人最后减少使用,未必是生成结果差,而是“在 Gamma 生成,再回 PowerPoint 收尾”这条额外流程,并没有比原来更省心。
Lovable:应用已经跑起来,谁来为它负责?
Lovable 的第一眼甚至更像魔法。
图:Lovable 的需求生成应用界面。
输入一句需求,或者丢进去一张草图,它就能生成一个可以操作的 Web 应用。页面、交互、数据库、身份认证和接口,不再必须从空项目一点点搭起来。
它最容易让人混淆的是两件事:
能运行,和能上线。
今天的 Lovable 已经提供了不少面向真实开发的能力:代码可以查看、修改、下载并同步到 GitHub;项目支持版本回退、后端、域名、协作和安全扫描。
把它简单归类成“只能做 Demo”,同样不准确。
但一个应用只要真的迎来用户,问题就会迅速变化:
• 用户能不能看到不属于自己的数据; • API 密钥有没有被放进前端; • 登录、权限和服务端校验是否正确; • 需求改了以后,原有结构会不会被破坏; • 第三方接口失败时怎样恢复; • 谁来测试、监控和维护。
这些也不是我替 Lovable 挑出的毛病。它自己的安全文档明确要求检查服务端认证、密钥管理、数据验证和数据库行级权限,也说明自动安全扫描不能保证完整安全;涉及敏感数据或关键功能时,仍然需要额外的专业审查。
这反而说明 Lovable 对自己的边界很清楚。
它真正压缩的,是从想法到第一个运行版本的时间,而不是把软件工程责任一并消除。
对于原型、内部工具、落地页和低风险 MVP,这个缩短非常有价值。特别是有人能够接管代码、测试和安全时,Lovable 完全可能成为长期工作流的一部分。
但如果一个人期待的是“说一句话,后面什么都不用管”,第一次生成越惊艳,等他撞上权限、调试和维护,落差反而越大。
如果他后来减少使用,未必是 Lovable 能力不足,而是一个真实软件项目的后半程,超出了他原本想解决的问题。
Deep Research:报告已经有引用,结论就可靠吗?
第三类惊艳来自研究工具。
图:Perplexity Deep Research 的研究结果界面。
Perplexity 在 2026 年 6 月刚刚把 Deep Research 整合进 Computer。按照官方介绍,它会先规划,再进行多轮搜索,阅读结果、记录矛盾,最后合成报告;它还可以接入授权的内部资料,把结果继续做成 PDF、演示文稿、仪表盘或网页。
当一个陌生问题很快变成一份有结构、有小标题、还有引用的报告时,人很容易把“看起来像研究”理解成“研究已经完成”。
但引用的存在,只能证明一句话后面有链接,不能自动证明:
• 这个来源足以支撑结论; • 它用的是一手资料,而不是二手转述; • 关键反例没有被漏掉; • 不同数据的统计口径可以比较; • 三个月前的结论今天仍然成立。
这不是 Perplexity 独有的问题,而是所有自动化研究工具都会面对的验收成本。
Perplexity 自己在 2026 年发布了 DRACO 基准,把深度研究拆成准确性、完整性和客观性分别评估。它使用来自真实请求的 100 个复杂任务,每个任务平均有大约 40 项专家评价标准。
这件事本身就很有启发:研究质量不是“有没有生成报告”这样一个开关,而是很多条件同时成立的结果。
如果目标是快速进入陌生领域、建立资料地图、找到候选来源,Deep Research 能省掉大量标签页切换。
如果目标是医疗、投资、法律,或者一项重要业务决策,它更适合成为研究起点,而不是直接成为最终判断。
还有一种更简单的原因:对不少人而言,复杂研究并不是高频任务。普通问题用搜索或通用助手已经够快,为偶尔才出现一次的任务建立新习惯,本身就不容易。
三个工具,其实遇到了同一个问题
Gamma、Lovable 和 Deep Research 分别生成 PPT、应用和报告,看起来完全不同。
但它们让人第二次犹豫的原因很像。
1. 看起来像成品,不等于通过验收
PPT 要通过业务和品牌验收,应用要通过功能与安全验收,研究报告要通过来源与逻辑验收。
AI 大幅降低了第一版出现的成本,却没有替用户定义“什么才算完成”。
2. 生成速度很显眼,收尾成本很隐蔽
快速生成一套 PPT、跑起一个应用、写出一份报告,这些都很容易测量。
检查、修改、迁移、沟通和承担责任的时间,则安静地散在后面。
真正应该比较的是:
从开始任务,到得到可交付结果,一共花了多少时间。
3. AI 展示的是能力,用户需要的是稳定任务
一个功能再强,如果对应的任务不重复,就很难形成习惯。
做 PPT 的频率、开发应用的真实需求、进行复杂研究的次数,会直接影响第二次打开。
这不是简单的产品质量问题,而是使用频率和价值密度的问题。
4. AI 可以执行,但责任没有消失
内容是否准确、应用是否安全、研究结论是否站得住,最终仍然需要一个人负责。
当用户发现“我还是得认真检查”时,有的人会继续用 AI 加速,有的人会觉得不如回到熟悉的方法。
这两种选择都合理。
说到底,这三个工具并没有做错什么。
Gamma 把空白页变成第一版演示,Lovable 把想法变成第一个可运行版本,Deep Research 把陌生问题变成一张资料地图。它们解决的,都是启动阶段最费力的那一下。
真正容易让人失望的,是我们把“第一版出现了”误认为“事情已经做完了”。
所以,我的结论是:
AI 工具最容易赢下的是第一次生成,真正困难的是降低完成整个任务的总成本。
第一次惊艳,证明技术能做什么。
第二次打开,才证明产品对谁真正成立。
你有没有用过一个第一次特别惊艳、后来却很少再打开的 AI 工具?让你不再使用的,是结果不合适,还是后面的收尾成本太高?
资料来源
• Gamma:官方更新记录 • Lovable:安全说明 • Perplexity:Deep Research 更新、DRACO Benchmark
本文仅代表个人观察,不代表所在公司立场。具体产品能力会持续变化,文中资料查询于 2026-06-27。
