 夜雨聆风
夜雨聆风1年前,我在大厂推 AI 知识问答,上线那天发生了一件事,让我挺意外。
差旅报销、合同审批这种问题,AI 答得又快又准。员工问"出差上海住宿标准多少",秒回。
可同一套 AI,问到车间设备,全废了——老师傅站在机器前问"这台泵异响,但没到报警阈值,该停机还是继续?"AI 给了一段教科书式的答复,听起来都对,没一句能用。老师傅关掉对话框,转身去翻那个皱巴巴的小本子。
那时候(差不多去年折腾RAG知识库体系RAG应用)我有个错觉:AI 喂不饱,是技术问题。换更大的模型、调更细的参数,总能解决。
后来我才明白,问题不在 AI,在我们喂的"知识"。公司级政策(差旅、财务)AI 答得好,是因为这些政策本身就是显性化的知识——规则明确、维护及时、质量高,喂进去就是有效输入。
而车间里那些事——老师傅的判断、权衡、直觉——从来没被真正写进任何文档。我们喂给 AI 的,是"显性化的渣",然后期待它产出"显性化的价值"。这不可能。
那本账,到底是什么
说到"那本账",很多人会下意识想到老师傅口袋里那个皱巴巴的笔记本。其实这只是表象。
"那本账"的真实形态,是一个组织里所有"没有结构化、没有索引、没有进入知识库"的经验资产的总和——它可能是老师傅脑袋里没写下来的判断,可能是 10 年前的项目复盘 PPT 里没人翻的某一页,可能是某个离职员工留在共享盘里的 Excel 表,可能是车间群里转发的零散对话截图,可能是老供应商邮件附件里压着的那份手写工艺参数。
这些散落的、没人整合的、没人维护的内容,才是 AI 时代真正的"金矿"。
在知识管理领域,这种"写不出来、或写出来但没人用、或者藏在文档深处没被索引"的知识,叫 Tacit Knowledge——隐性知识。它可能以纸质本子的形态存在,也可能以电子文档、PPT、Excel、邮件、聊天记录的形态存在——形态不重要,"隐性"才重要。
SOP 是冰山尖,"那本账"是水面下的 90%。我们一直在给 AI 喂冰山尖,却指望它回答整个冰山的问题。
这就是为什么,再贵的 GPU,也只能产出"正确的废话"。
SECI 模型:为什么 SOP 喂不饱 AI 的根因
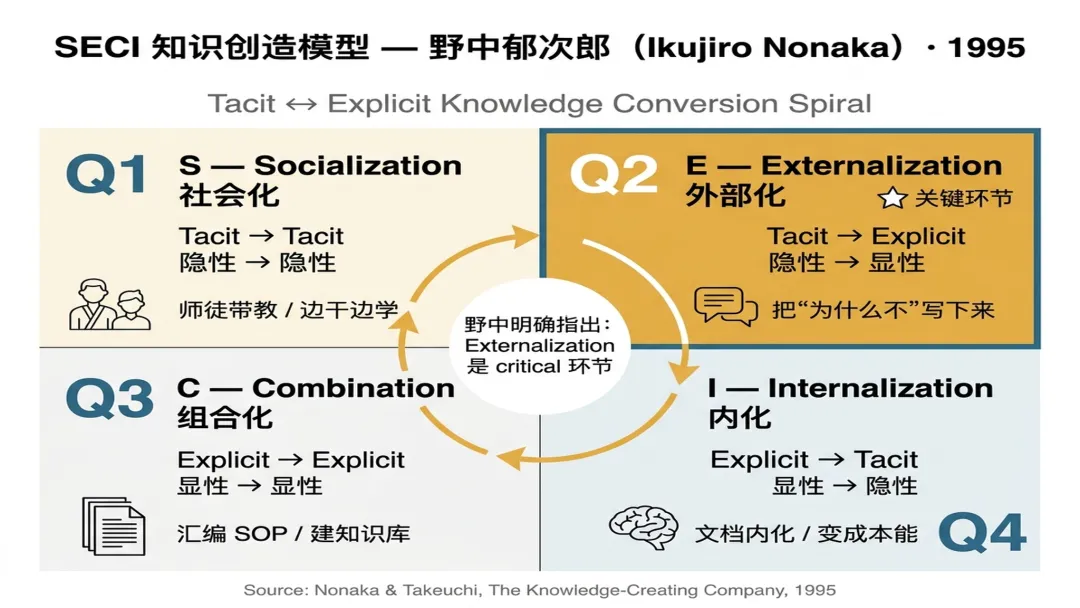
1995 年,日本管理学家 野中郁次郎(Ikujiro Nonaka) 和竹内弘高在《The Knowledge-Creating Company》里提出一个模型——SECI 模型。它后来成了知识管理领域的奠基性框架,全球 MBA 课程几乎必讲。它把企业里的知识分成两种——隐性知识(Tacit) 和 显性知识(Explicit)——然后描述了它们之间四种转化路径:
S - Socialization(社会化):隐性 → 隐性。师徒带教,师傅边干边讲,你跟着学。
E - Externalization(外部化):隐性 → 显性。把"为什么这么做"从脑袋里挖出来,写下来或讲清楚。
C - Combination(组合化):显性 → 显性。把多份 SOP 汇编、建知识库、做交叉引用。
I - Internalization(内化):显性 → 隐性。文档读了,真正用出来,变成自己的本能。
野中郁次郎在原书里明确指出:Externalization 是知识创造过程中"至关重要的环节"(critical)。因为只有把不可表达的隐性知识"翻译"成可表达的显性知识,组织才能真正拥有它。
回头看我们喂 AI 的现状,问题就清楚了——我们一直在 C(组合化) 上卷,汇编、整理、归档、建知识库、做交叉检索;E(Externalization)这一步,根本没人做。老师傅脑袋里的判断、文件夹里没人翻的 PPT、离职员工留下的 Excel、聊天记录里的零碎经验——这些"那本账",从来没有被翻出来过。
我原来以为,AI 喂不饱是技术问题——买了更好的大模型、调了更细的参数,问题应该就解决了。
知识真正的问题——是"显性化的能力"喂不饱,不是"显性化的渣"喂不饱。真正的问题不是 SOP 不够多,是 E(Externalization)这一步根本没做。
企业知识库的失败,往往不是技术问题,是这一环缺位。
如何做 Externalization:把"那本账"翻出来
理论懂了,问题是——怎么做?
我后来在车间和 IT 部蹲了大半年,结合野中的 SECI 模型和一线实操,整理出一套五步法。每一步我都给具体的"how"——怎么访谈、怎么记录、怎么萃取、怎么追问、怎么整合。方法直接拿走能用。
Step 1 · 选对知识源(Identify the Knowledge Source)
"那本账"不只在老师傅脑袋里,它散落在整个组织。你要做的是列出 4 类知识源的清单,然后按优先级去"挖":
① 人脑里的隐性知识:老师傅、离职返聘专家、有过关键决策的资深员工——选"会干的"而不是"会讲的"
② 个人文件夹里的孤岛文档:离职员工留下的 PPT/Excel、自己电脑里没归档的草稿、邮件附件里压着的手写笔记
③ 协作工具里的隐性资产:聊天群里的经验分享(截图/转发)、会议纪要里的口头决策、邮件链里的关键判断
④ 流程里"走过的弯路":事故复盘报告、被废弃的方案、未通过的审批意见——这些是"反向金矿"
操作要点:先做一份《知识源盘点表》,每类至少列 5-10个具体对象。然后按"判断密度 × 复用频率 "打分,排序出"必须先挖"的 Top3 。不用表也行,但是得想清楚从哪里萃取。
野中郁次郎强调过,隐性知识是高度个人化(highly subjective, experience-based)的——但这只是其中一种形态。真正的隐性知识资产,分布在人、文档、协作工具、流程痕迹四个层面,缺一不可。
Step 2 · 边做边录,不是访谈(Capture in Context, Not Interview)
坐下来的访谈拿不到隐性知识——人在复述时会自动合理化、简化、修饰,丢掉了"现场"那个最值钱的细节。
正确做法是"边做边录":
跟岗记录法:跟着老师傅跑一天业务,手机开录音(先征得同意),同步用笔记 App 记下他做的"小动作"——为什么这里停一下、为什么这个电话先打、为什么这台机器他换了个顺序、设备那个声音他为什么皱眉。事后 24 小时内把录音转成文字+批注,超时就失效。
屏幕录制法:让老师傅打开电脑操作他常用的 Excel/系统,边做边讲——屏幕录屏软件(会议录屏或Bandicam等)录下全过程。重点录他做错又改回来、跳过某个字段又回来填、临时打开另一个文档对照这些瞬间——这些是隐性知识的"动作切片"。
会议萃取法:重要会议(事故复盘、方案评审)必须录像+录音+自动转写。结束后用 AI 工具(比如飞书妙记、通义听悟)自动生成"决策上下文"摘要——这一步 AI 帮你做"对话场(Dialoguing Ba)"的初步萃取,后续 Step 3 你再做精修。
这一步对应 SECI 里的 S(Socialization)——隐性知识必须通过"共享经历 + 现场记录"捕获,而不是通过"问答"。
Step 3 · 追问"为什么不"(The "Why Not" Dialogue)
人脑里的隐性知识,光靠听还不够——必须追问。而最高价值的追问,是针对"不做的事"。
五个必问的"为什么不"问题:
"为什么不这么做?"——揭示被排除的方案和原因
"上次这么干的后果是什么?"——揭示 Historical Lessons
"如果这么做,老板会怎么说?"——揭示 Decision Rationale
"什么情况下,这个方法会失效?"——揭示 Exceptional Cases
"如果出了事,第一反应是什么?"——揭示 Risk Awareness
追问的操作要点:
不要问"是什么"——问"是什么"得到的是 SOP;要问"为什么不"——得到的才是那本账
不要问一次就停——每个"为什么不"问完,得到回答后再追问一层"为什么不",挖到第三层才是真东西
不要当场总结——当场总结会让老师傅顺着你的框架说,丢掉了他的原汁原味。只记关键词,事后整理
这五个问题,对应的就是 SECI 中 E(Externalization) 的核心动作——通过对话、隐喻、类比,把隐性知识显性化。野中在原书里把这一步叫 "Articulating Tacit Knowledge through Dialogue"。
Step 4 · 把散落文档整合成"决策上下文"(Integrate Scattered Artifacts)
这是最容易被忽略、但决定 Externalization 成败的一步。
散落的 PPT、Excel、邮件、聊天截图——单独看是垃圾,整合起来是金矿。
整合方法:四象限归档法:
第一象限:决策依据(Decision Rationale)——所有"为什么这么做"的解释。来源:邮件里老板的批示、会议纪要里的口头决策、PPT 里被加粗的那句话。
第二象限:历史教训(Historical Lessons)——所有"上次这么干的后果"的复盘。来源:事故报告、被废弃方案、聊天群里的"以后别这样"提醒。
第三象限:例外处理(Exceptional Cases)——所有"什么情况下不能这么做"的边界条件。来源:流程里的"特殊情况说明"、老师傅的"小本子"、Excel 里的批注列。
第四象限:风险预判(Risk Awareness)——所有"这样做的最大风险"的预判。来源:审批意见里的"风险提示"、聊天群里的"小心 XXX"、PPT 里被删除又被恢复的那页。
整合工具:用 顺手的工具(Obsidian/Notion / 语雀 ) 建一个"决策上下文库",每条记录强制填四象限,哪个象限为空就不让保存——这能逼着你回头追问,闭环。
野中模型里 E 的输出形态,就是这个四要素结构。小本子、PPT、Excel、邮件——无论它原本以什么形态存在,整合之后都收敛到这四个维度,才能被 AI 学。

Step 5 · 把"那本账"装进 Ba,让它持续流动(Build the Ba)
野中模型里有个关键概念——"Ba(场)",指知识转化发生的"场所"。Externalization + Combination 对应的 Ba 叫 Interacting/Systemizing Ba(对话场 + 系统化场)。
实操做法是建一个"三角色例会":
老师傅/老员工:主讲真实场景和决策过程
流程官(你):负责追问"为什么不",挖掘决策上下文
记录员:当场把对话按 Step 4 的四象限结构实时归档到文档库
频率:每周 1-2 次,每次 1 小时,覆盖 1-2 个具体决策场景。
配套机制:
会前:流程官提前选好"要挖掘的主题"(从 Step 1 的知识源清单里挑)
会中:全程录音录像,会后 24 小时内整理成四象限文档
会后:把整理好的"决策上下文"喂给 AI 知识库——这才是 AI 真正能学的东西
没有 Externalization 的 Combination,就是给沙子建城堡。
我们以前花 80% 精力建知识库(C),花 20% 精力写文档(半成品 C)。真正的 E——把隐性知识从老师傅脑袋、文件夹、聊天记录、流程痕迹里挖出来——基本是 0。
算力 vs 经验,未来到底价值怎么体现
回到开头那个问题——你说,AI 算力更值钱,还是老员工的经验更值钱?
二选一,经验贵。算力是商品,价格透明,可以云租赁,可以按小时买。老师傅脑袋里的判断、文件夹里没人翻的 PPT、离职员工留下的 Excel、聊天记录里的零碎经验——这些"那本账"是个体经验、长期判断、组织情境的耦合,不可复制、不可下载、不可压缩。你买不到,也租不来。
看未来,必然是隐性知识显性化的过程。AI 会越来越强,但"把人的判断翻译成 AI 能学的东西"这件事,永远稀缺。我有个越来越强的判断:未来 5 年,最稀缺的岗位不是 AI 工程师,是"知识工程师"(或小A说的“流程官”)——能把隐性知识显性化的人。这是流程官最值钱的功课,也是流程官最被低估的本事。
数据告诉 AI "是什么","那本账"告诉 AI "为什么"和"接下来会怎样"。SOP 是冰山尖,"那本账"是水面下的 90%,不挖出来,AI 永远只能喂尖。算力谁都能买到,老师傅那本账买不到——未来不缺更强的 AI,缺的是更会"翻译"的流程官。
你呢?你身边有没有这样的"老师傅"?他那本账——不管是在他脑袋里、在文件夹里、还是在聊天记录里——你翻出来过吗?
这是聊企业知识库转型应用的第2篇文章,欢迎大家点赞转发收藏关注,后续会把这一段时间攒的料陆续发出来~
