 夜雨聆风
夜雨聆风文档解析这种没人想干的脏活,MinerU 把它拆成了两套后端、一个跑分、一条命令。
◇ ◇ ◇
先看一条命令的输出
我手头有一份 47 页的招股书,扫描件,带三栏表格、竖排批注、还有几个手写印章盖在数字上。这种东西丢给任何一个 RAG 流程,出来的都是一锅糊。
上周我把它丢给 MinerU,跑了一条命令:
mineru -p prospectus.pdf -o ./out -b vlm-transformers
七分多钟,./out 里躺着一份 Markdown:标题层级对的,表格转成了 HTML,公式是 LaTeX,连那个盖在数字上的印章文字都被单独识别出来了。我盯着那份 .md 看了一会儿,说实话,有点意外。这活儿三年前我们团队外包出去做,一页两块钱,还经常返工。
MinerU 3.4 是 2026/06/18 发的版本。GitHub 上 70k+ 个 star,我刷到它那天单日涨了 960。一个做文档解析的工具,凭什么。
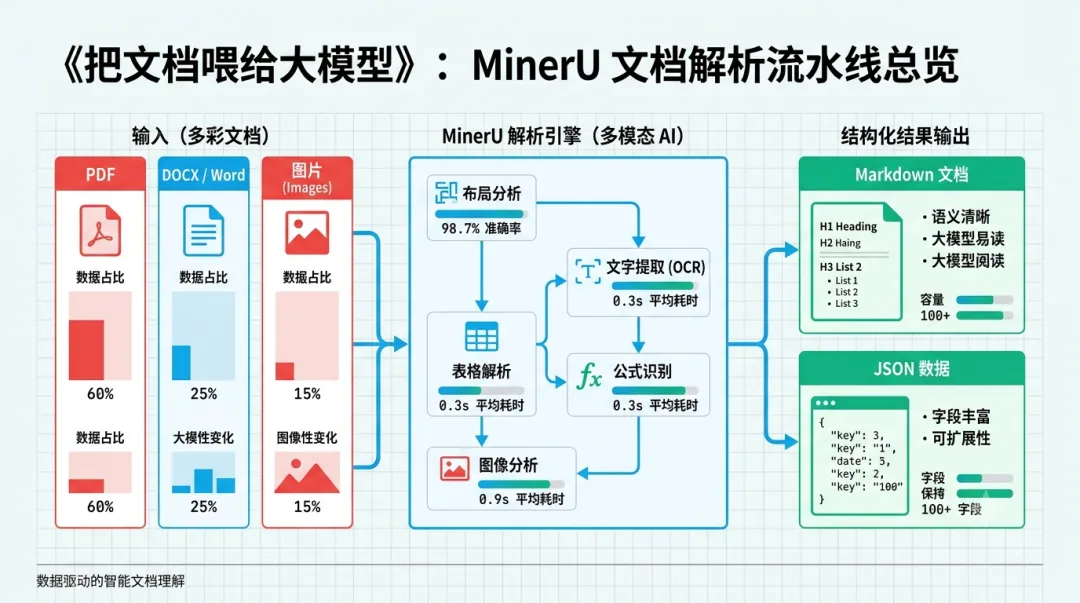
MinerU 把复杂 PDF 转成结构化 Markdown 的流程示意
◇ ◇ ◇
它其实只分两套后端
别被那一长串 feature list 唬住。MinerU 的核心,就两条路:pipeline 和 VLM。搞清楚这俩的取舍,基本就搞懂了它。
pipeline 是老派打法——版面分析、OCR、公式识别、表格识别,一层层串起来。它跑在 CPU 上也能动,最低 4GB 显存,16GB 内存。OCR 模型这版换成了 PP-OCRv6,在 OmniDocBench v1.6 上识别准确率提了大概 11%。它在跑分榜上是 86.47。
VLM 是另一套——直接上多模态大模型,一张图进去,结构化结果出来。模型叫 MinerU2.5-Pro-2605-1.2B,1.2B 参数,不大,但要 GPU(Volta 架构往上,或者苹果的 M 芯片),最低 8GB 显存。它的跑分是 95.39(高精度)/ 95.26(中等)。
86.47 和 95.39,差了快 9 分。这 9 分是什么概念?就是我那份招股书,pipeline 跑出来三栏表格会串行,VLM 跑出来基本不串。但 VLM 要 GPU,pipeline 不要——这才是真正决定你用哪套的东西。
我自己的判断:批量处理几十万页、机器是一堆 CPU 服务器,用 pipeline;追求质量、手头有卡、量不大,用 VLM。别纠结跑分,先看你有没有卡。
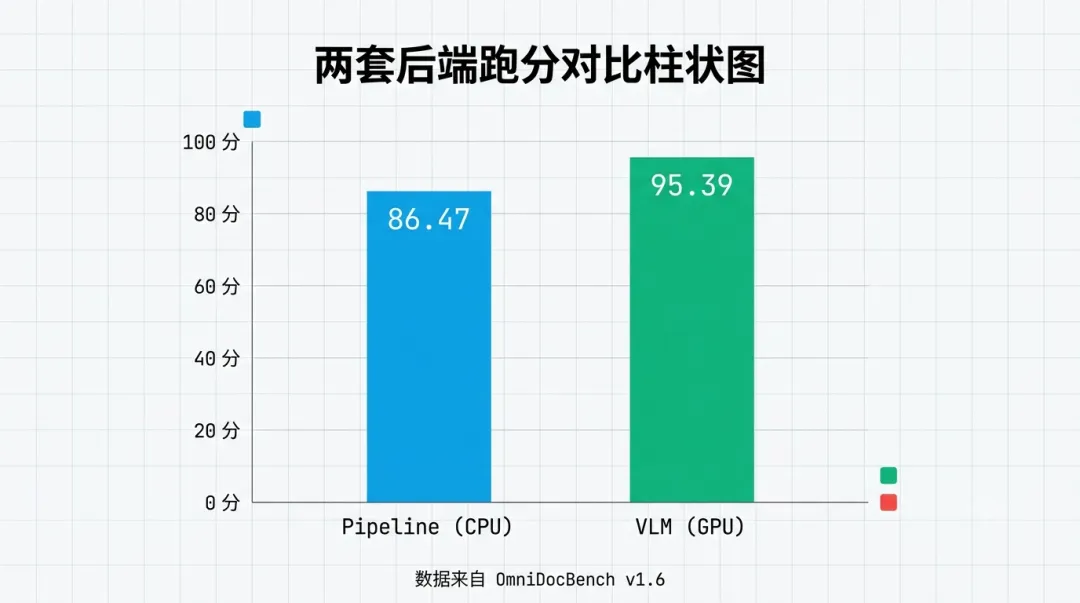
pipeline 与 VLM 两套后端的跑分与硬件对比
◇ ◇ ◇
输入输出这块,是它真正的护城河
跑分高的项目多了。MinerU 让我愿意装在生产线上的,是它对格式的覆盖。
输入端:PDF、DOCX、PPTX、XLSX、图片、网页,全收。OCR 认 109 种语言。我试过塞一个日语的竖排 PDF 进去,竖排文字居然没乱——这个细节很多商业 API 都做不好。
输出端更关键。它不是吐一坨纯文本就完事:
标题、段落、列表的层级结构保留;图片连同图片描述一起抽出来;表格转成 HTML;公式自动转 LaTeX。
这意味着什么?意味着出来的东西可以直接进向量库,不用你再写一堆正则去补结构。我之前自己缝的解析脚本,光是"判断这一行是标题还是正文"就写了两百行 if-else。现在这部分可以删了。

结构化输出:层级、表格、公式、图片描述各归各位
3.4 这版还加了原生 DOCX 解析。以前 DOCX 得先转 PDF 再解,绕一圈。现在直接啃,官方说端到端速度快了几十倍。我没测到"几十倍",但确实从十几秒掉到了一两秒。长文档还上了滑动窗口机制压峰值显存——我跑那种几百页的年报,内存不再爆了。这个改动闷声,但救命。
扯远了,回到正题。
◇ ◇ ◇
部署方式多到有点过分
这块我得吐槽一句:MinerU 的部署入口多到让人选择困难。
- ◆
mineru命令行,最直接 - ◆FastAPI,起个 REST 服务
- ◆Gradio WebUI,给不写代码的同事用
- ◆MCP Server,直接挂到 Cursor、Claude Desktop、Windsurf 里
- ◆Docker
- ◆还有个桌面客户端
那个 MCP Server 是我最近真在用的。配好之后,在 Claude Desktop 里直接说"解析这个 PDF",它后台就调 MinerU 把结果喂回来。文档解析从一个"预处理步骤"变成了 agent 能随手调的工具。这个方向我觉得是对的。
集成层也给足了:LangChain、LlamaIndex、RAGFlow、Dify、FastGPT,主流的 RAG 框架基本都接好了。还适配了一堆国产芯片——昇腾、寒武纪、燧原、沐曦、摩尔线程。这个名单本身就说明它的目标用户是谁:要在国产算力上跑、又不能用境外 API 的那批团队。
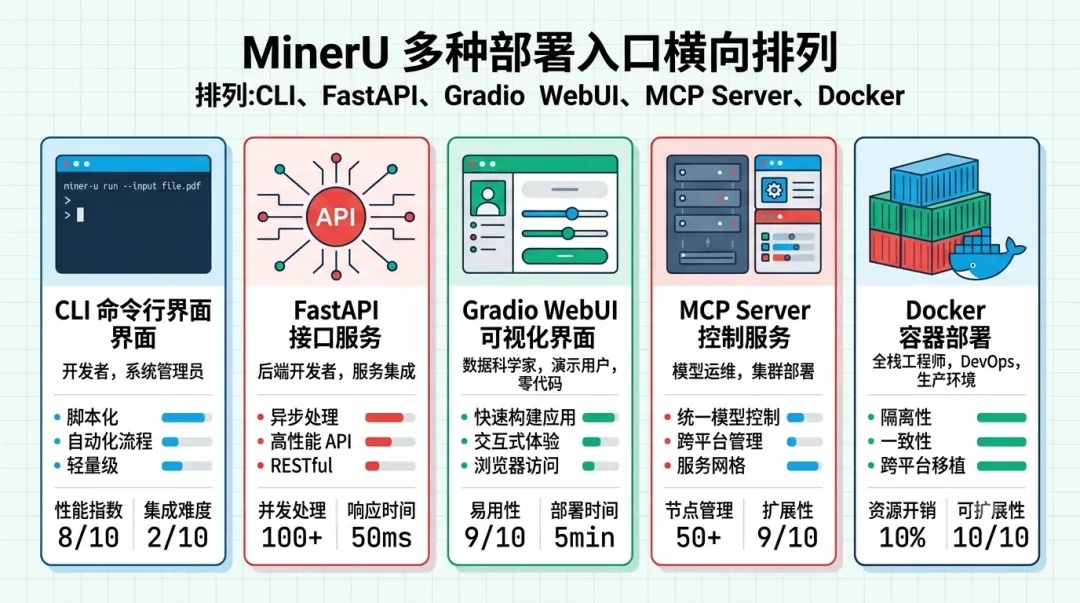
MinerU 的多种部署入口:CLI、API、WebUI、MCP
◇ ◇ ◇
用之前,有两件事得说清楚
夸了这么多,泼两盆冷水。
第一,License 不是纯 Apache 2.0。从 v3.1.0 起,它用的是"MinerU Open Source License",底子是 Apache 2.0,但加了附加条款。你要商用,尤其是想拿它的模型去做闭源产品,先把那份 License 读完。别看见 "open source" 四个字就往生产环境怼,这是我踩过的坑——不是在这个项目上,是在别的项目上,代价不小。
第二,95 分不等于 100 分。OmniDocBench 是个 benchmark,你的文档不是 benchmark。我那份招股书里,有一个跨页的合并单元格,VLM 还是判错了。文档解析这事儿,到今天依然没有"一键全对"的银弹。MinerU 把及格线从 60 抬到了 90+,但最后那几分,该人工核对还得核对。
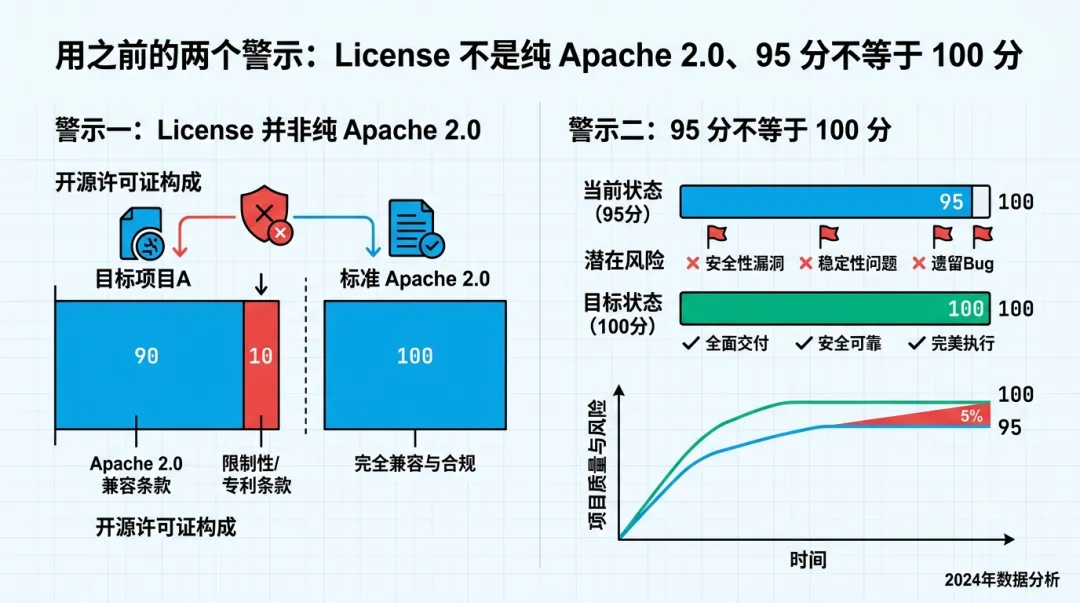
用之前的两盆冷水:License 与 95 分的边界
那它到底值不值得用?我的答案是值。它把文档解析从"要专门招个人维护的脏活",降成了"装个包跑条命令的事"。 对绝大多数 RAG 项目来说,这一步省下的工,够你把精力放到真正该死磕的地方了。
讲真,文档解析这种没人愿意干、又绕不过去的活,有人把它做到 70k star,还开源,我是挺服气的。剩下的问题只有一个——你的卡,够跑 VLM 吗?
配图由 AI 辅助生成 · 内容为个人观察
