 夜雨聆风
夜雨聆风这不是给视频配音,是把 AI 塞进了直播间
一篇可部署的 AI 实时解说工具文
6月26日,Zico 在 X 上发了一段 39 秒演示:一个叫 WorldCupVoice 的开源项目,把 2022 世界杯决赛画面接进直播台,左侧不断滚出英文解说转录,右侧是比赛画面,下面还显示 AI spend Active。
原帖一句话说得很清楚:AI 像观众一样看同一路直播,抽最新画面,读动作,再把 play-by-play 声音说回直播。
这件事能让人停下来,不是因为 AI 又会给视频配音了。配音是事后加工,直播解说是现场闭环。画面在动,声音要跟上,不能胡编进球,不能慢半拍,还要能随时停掉成本。
做赛事转播、训练课、球馆直播、企业活动的人,最缺的常常不是剪辑软件,而是有人能盯着画面,把正在发生的事说清楚。WorldCupVoice 的可用之处就在这里:它把一个沉默的视频流,变成了可以交付的解说服务。
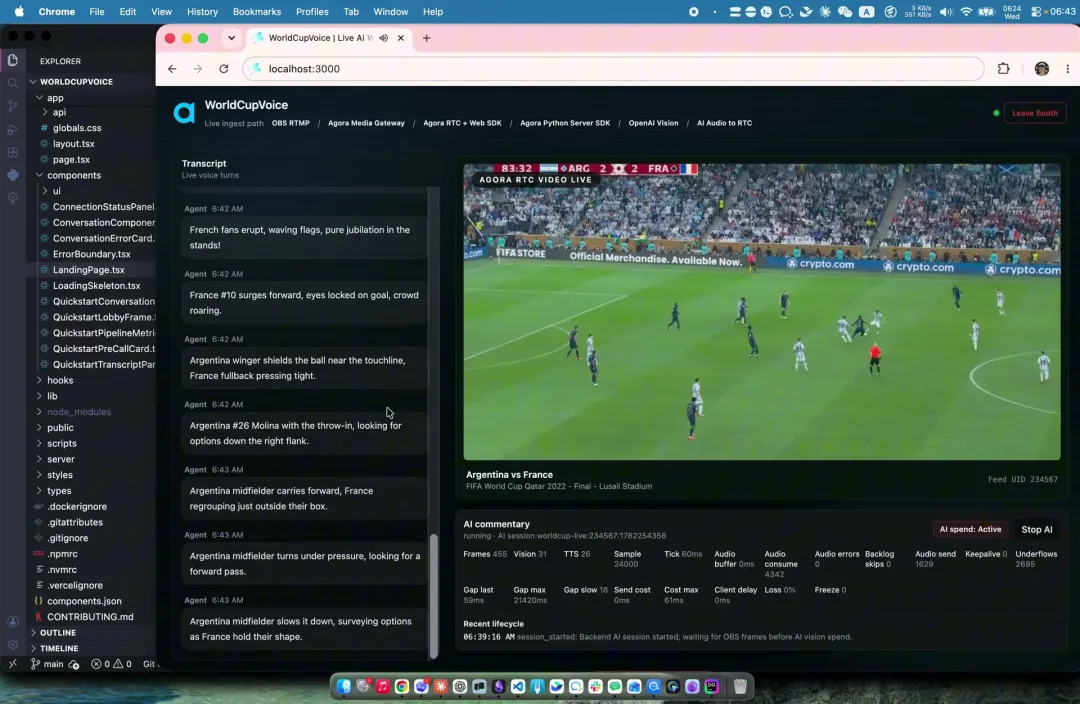
图1:GitHub demo 视频中的 AI 解说台。左侧是转录,右侧是比赛画面,底部显示 AI 解说状态和消耗指标。
看图1最容易理解它的成果:左侧不是一句笼统旁白,而是在追着画面说边线球、逼抢、持球推进和防守回收;右侧仍是同一场比赛;底部指标显示帧数、视觉请求、TTS 次数和音频发送状态。它不是写一段赛后文案,而是在直播过程中持续做“看、判断、说”。
别被视频配音带偏,难点在直播闭环
WorldCupVoice 的链路很硬:OBS 或编码器把比赛画面推成 RTMP;Agora Media Gateway 把 RTMP 转进 Agora RTC 频道;浏览器观看同一路 RTC 画面;Python 后端也作为一个参与者进入频道,抽帧、写解说、合成语音,再把声音推回 RTC。
这就不是“上传一段视频,让 AI 讲两句”的玩法。它更像把一个 AI 解说员安排进直播间。观众看到球从右路推进,AI 后端也看到同一段画面;后端写出一句短解说,TTS 合成 PCM 音频,声音再回到前端。
代码里能看到几个关键默认值:后端每 0.55 秒采一帧,保留 4 帧作为上下文,每 4 秒左右生成一轮解说。视觉模型默认走 OpenAI Responses,TTS 默认是 OpenAI 语音接口,也可以换 ElevenLabs 或 Fish Audio。每个 live session 默认 900 秒封顶,观众心跳 45 秒超时后自动停。
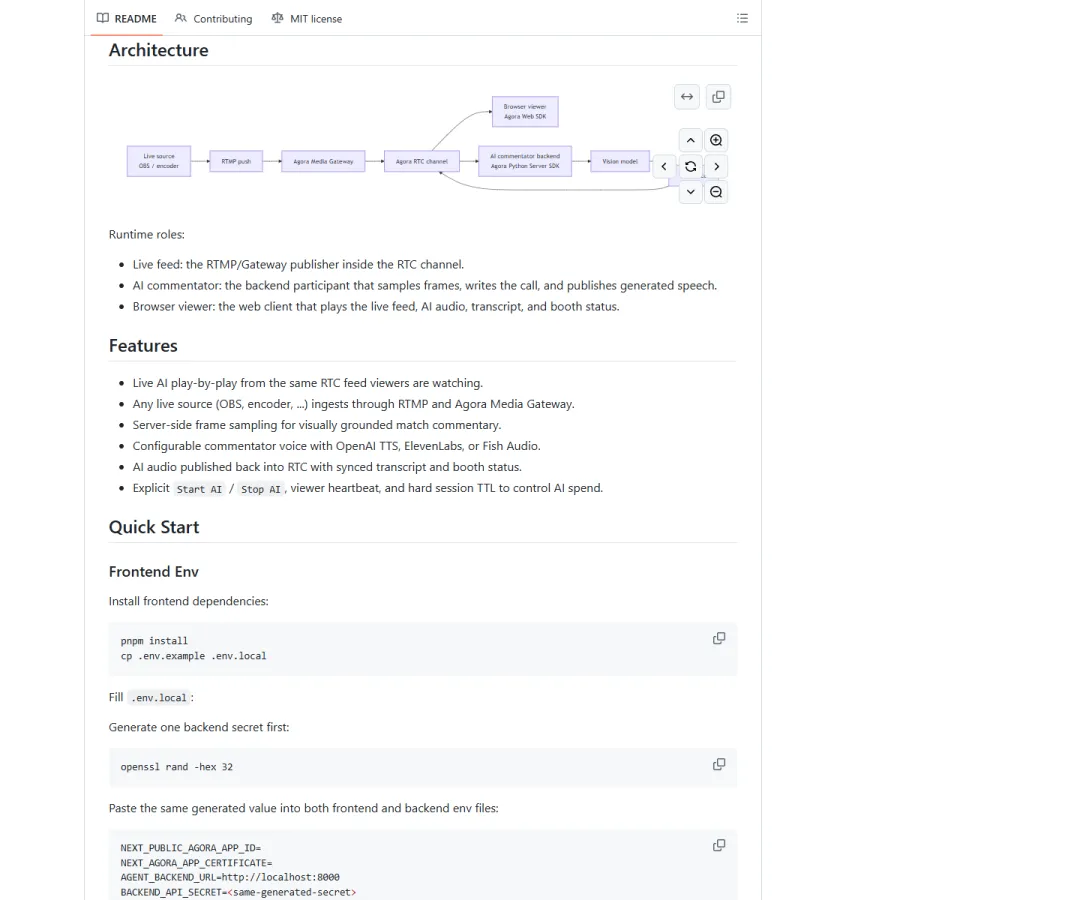
图2:README 里的架构段。OBS/编码器、Agora Media Gateway、RTC 频道、后端视觉模型和 TTS 是同一条线。
搭起来之前,先把账本算清
这套项目不要求本地 GPU。算力主要花在云端视觉模型和云端 TTS,本机负责三件事:跑 Next 前端、跑 FastAPI 后端、用 OBS 或 ffmpeg 做视频推流编码。
开发验证用 8GB 内存可以试,16GB 会稳很多;CPU 至少 4 核,直播推 1080p 时更建议有独显或硬件编码。网络比显卡更容易拖后腿:1080p 可从 4500-6500 Kbps 起步,上行最好留到 10 Mbps 以上;如果机器或网络吃紧,就先用 720p。
账号也要提前准备:Agora 项目的 App ID 和 App Certificate,Media Gateway 开关,RESTful API 的 Customer ID 和 Customer Secret;OpenAI API key;如果想要更像体育转播的声音,再准备 ElevenLabs 或 Fish Audio 的 voice id。仓库不带比赛视频,转播画面受版权保护,只能使用自己有权使用的 mp4、摄像机画面或训练素材。
别把这件事理解成“买一张显卡就能做”。显卡可以帮你推流编码更轻松,但项目的核心开销在模型调用和声音合成。省钱的办法不是堆机器,而是调低帧采样、拉长解说间隔、只在有人观看时启动 session,并在无画面时自动停掉。
先让页面跑起来,不急着让 AI 开口
Windows 上可以按这个顺序走。先装 Node 22 以上、pnpm、Python 3.11/3.12 和 ffmpeg。然后拉仓库、装前端依赖:
git clone https://github.com/zicojiao/worldcupvoice.git cd worldcupvoice pnpm install
在根目录复制环境变量文件,填前端要用的 Agora 和访问码:
copy .env.example .env.local NEXT_PUBLIC_AGORA_APP_ID=你的 Agora App ID NEXT_AGORA_APP_CERTIFICATE=你的 Agora App Certificate AGENT_BACKEND_URL=http://localhost:8000 BACKEND_API_SECRET=前后端相同的一串随机密钥 ACCESS_PASSWORD=你自己设置的直播间口令
这一步只负责让网页知道要连哪个 Agora 项目、后端在哪里、谁能进直播间。本机验证时,我用临时环境变量启动前端,页面能正常打开,生产构建也通过了。
你自己搭的时候也按这个标准验收:浏览器能打开 http://localhost:3000,页面能看到直播间入口;pnpm run build 能编译通过;没有填密钥时不要去点 Start AI 硬测,因为这一步本来就要依赖 Agora token、后端 session 和 OpenAI key。
图3:本机启动 Next 前端后的直播间入口。此图只证明页面和前端构建可跑,实时解说还要填入自己的密钥和视频源。
后端启动后,AI 解说员才进场
后端在 server 目录里。它的职责不是展示页面,而是进入 Agora RTC 频道,订阅比赛画面,抽帧,调用视觉模型,再把声音发回频道。
cd server python -m venv .venv .\.venv\Scripts\Activate.ps1 pip install -r requirements.txt -r requirements-dev.txt copy .env.example .env.local
server/.env.local 里至少要填这些:
AGORA_APP_ID=你的 Agora App ID AGORA_APP_CERTIFICATE=你的 Agora App Certificate BACKEND_API_SECRET=和前端一致 OPENAI_API_KEY=你的 OpenAI API key
默认 OpenAI TTS 就能跑。想换中文口播,可以把 TTS_PROVIDER 设成 fish_audio,再填 FISH_AUDIO_API_KEY 和 FISH_AUDIO_VOICE_ID;想做英语体育转播感,可以用 ElevenLabs 创建一个 sportscaster voice,再把 voice id 写进去。
后端启动命令是:
python -m uvicorn app.main:app --reload --host 127.0.0.1 --port 8000
这里要分清一件事:后端能启动,不等于 AI 已经开始花钱。代码里只有 /sessions/start 被前端触发后,后端才会拉起解说会话;没有 OPENAI_API_KEY,start session 会报错,这是保护,不是故障。
让画面进 RTC,才会有解说
直播画面进来有两种常用方式。做演示,可以用 ffmpeg 推本地 mp4;做活动,可以用 OBS 推摄像头、屏幕或导播画面。无论哪种方式,目标都是同一个:把画面推到 Agora Media Gateway 生成的 RTMP server 和 stream key。
先在 Agora Console 打开 Media Gateway,再在 Developer Toolkit 里准备 RESTful API 的 Customer ID 和 Customer Secret,把它们写到根目录 .env.local:
AGORA_CUSTOMER_ID=你的 Customer ID AGORA_CUSTOMER_SECRET=你的 Customer Secret AGORA_MEDIA_GATEWAY_REGION=na
然后生成 stream key:
pnpm run media-gateway:key
拿到 RTMP server 和 stream key 后,用本地视频推流:
$env:RTMP_STREAM_KEY="生成的 stream key" $env:RTMP_INPUT="D:\clips\your-match.mp4" pnpm run stream:sample
OBS 的设置更适合活动现场:Service 选 Custom,Server 填 rtmp://rtls-ingress-prod-区域.agoramdn.com/live,Stream Key 填生成的 key。编码用 H.264,30 fps,关键帧间隔 2 秒,CBR,1080p 先用 4500-6500 Kbps。
如果要放到云上,前端可以放 Vercel,后端按仓库建议放 Railway Docker 服务。前端的 AGENT_BACKEND_URL 指向 Railway 公网地址,Railway 和 Vercel 里的 BACKEND_API_SECRET 必须一致。上游推流可以继续用 OBS,也可以把 StreamFlow 放到 VPS,用它循环推预录素材。
解说准不准,靠的不只是一句提示词
真正影响效果的是比赛资料。仓库把每场比赛做成 data/matches 下的一个 JSON:队名、球衣颜色、球员号码、短名、故事线、画面开头状态。你推自己的视频,就要复制 _template.json,改成自己的比赛,再在 lib/commentary.ts 里注册。
后端提示词里有一个重要约束:看得清号码和球衣颜色时才叫球员名;看不清时用位置或角色;画面不可读、没有足球动作,返回 NO_CALL。这个设计很关键,付费交付时最怕 AI 把不存在的进球、犯规、比分说出来。
所以搭建顺序不是先调花哨声音,而是先把画面、阵容、球衣、码率和延迟调稳。声音可以后面换,错叫球员会立刻伤害信任。
可复制的变现,不在世界杯本身
别去碰大版权赛事的搬运,那条路成本高,也容易出问题。更可复制的场景在身边:校园联赛、青训比赛、球馆直播、企业运动会、电竞训练赛、线下发布会、外贸产品直播、工厂巡检直播。只要有一条持续变化的画面,又缺人盯场讲解,这套链路就有用。
可以卖的不是“AI”两个字,而是一套交付包:直播间搭建、摄像机或 OBS 接入、专属解说音色、赛事资料录入、实时转录、赛后短视频文案。收费方式可以按场,也可以按月维护。给小型赛事,一场收费覆盖技术搭建和现场值守;给机构客户,可以做多语言解说和可访问性音轨;给内容团队,可以把解说转录变成切片标题和回放素材。
更容易成交的包装可以分三档:入门档只做一场活动的直播解说和转录;进阶档加入专属声音、队伍资料和赛后切片;长期档给场馆或机构做固定频道,按月维护推流、账号、素材库和故障响应。客户不会为“用了什么模型”买单,但会为“少请一个人、活动能播、回放能复用”付款。
这类服务的核心,是帮客户省掉一位全程盯画面的专职解说,同时保留可复查的文字记录。客户买的不是模型名,而是少出错、能开播、有人负责的结果。
要交付,先管住三件事
第一件事是素材来源。自己拍的训练赛、活动现场、产品演示最稳;转播素材只能在授权范围内使用。第二件事是延迟。AI 每几秒看一组帧,再生成语音,天然会慢一点,适合补充解说,不适合替代专业赛事的毫秒级口播。第三件事是人工兜底。正式活动里要有人看状态面板,必要时按 Stop AI,切回人工或静音。
WorldCupVoice 已经把成本控制写进代码:Start AI/Stop AI、心跳、session TTL、后端密钥。真正做成服务时,还要把这些按钮变成操作规程:谁开播,谁停播,谁看日志,谁处理无画面和无声音。
别只盯世界杯。去看你手里有没有一条正在直播、没人讲、但有人愿意听明白的画面。AI 解说台真正打开的,不是体育评论的幻想,而是把沉默画面变成可交付服务的能力。
