 夜雨聆风
夜雨聆风上篇尝试了Dify内置的两种记忆机制:上下文记忆让AI记住“刚聊了什么”,会话变量让AI记住“用户是什么样的人”。但两者都有一个共同的边界——记忆止步于单次会话,会话结束即清零。
本文正式进入Dify记忆能力的第2阶段:外部持久化记忆,基于Mem0插件实现跨会话、永不过期的智能记忆。笔者采用Mem0官方推荐的轻量私有化部署模式:只需要一个PostgreSQL数据库(带pgvector扩展),加上LLM和Embedding模型的API密钥,在Dify插件里配好JSON即可。不需要部署完整的Mem0 API服务、认证和Dashboard,适合快速上手验证。
1. 安装PostgreSQL + pgvector
Mem0的记忆存储依赖向量数据库。我们使用官方的pgvector/pgvector:pg16镜像,它已经预装了vector扩展,开箱即用。
docker run -d \--name pgvector-db \-p 5432:5432 \-e POSTGRES_USER=postgres \-e POSTGRES_PASSWORD=postgres \-e POSTGRES_DB=mem0db \-v $(pwd)/pgvector_data:/var/lib/postgresql/data \pgvector/pgvector:pg16
参数解释:
POSTGRES_USER和POSTGRES_PASSWORD:账号密码都设置为postgres;
POSTGRES_DB:自动创建一个名为mem0db的数据库;
-v $(pwd)/pgvector_data:数据持久化到本地目录,防止容器删除后数据丢失;
⚠️ 关键:虽然镜像自带了vector插件,但必须在数据库中手动开启扩展,否则Mem0自动建表时会报错。
docker exec -it pgvector-db psql -U postgres -d mem0db -c "CREATE EXTENSION IF NOT EXISTS vector;"输出“CREATE EXTENSION”,说明扩展已成功开启。

2. 在Dify中配置Mem0插件
在Dify插件市场中搜索mem0,笔者推荐使用“mem0ai ”插件。它功能最全,提供了包括添加、搜索、更新、删除在内的12项记忆管理工具,并且专门支持私有化部署模式(Self-Hosted Mode)。
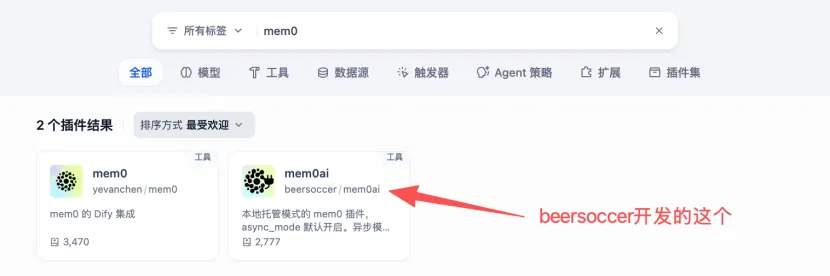
🌈 Mem0插件的价值,就在于把“记忆”从黑盒变成了你可以查看、编辑、删除的白盒资产。
笔者下载的插件版本为0.3.1,在插件配置界面中,需要填写LLM配置、向量模型配置、向量数据库配置三个必填项。笔者采用硅基流动的LLM、Embedder模型,向量表的纬度需要和Embedder模型纬度保持一致。
LLM配置
{"provider": "openai","config": {"model": "Qwen/Qwen2.5-72B-Instruct","api_key": "sk-xxx(API秘钥)","openai_base_url": "https://api.siliconflow.cn/v1","temperature": 0.1,"max_tokens": 256}}
向量模型配置
{"provider": "openai","config": {"model": "BAAI/bge-large-zh-v1.5","api_key": "sk-xxx(API秘钥)","openai_base_url": "https://api.siliconflow.cn/v1"}}
向量数据库配置
{"provider": "pgvector","config": {"connection_string":"postgresql://postgres:postgres@host.docker.internal:5432/mem0db?sslmode=disable&keepalives=1&keepalives_idle=30&keepalives_interval=10&keepalives_count=3&connect_timeout=5","collection_name": "mem0","embedding_model_dims":1024}}
⚠️ 注意:Mac上Docker容器内访问宿主机服务,请使用host.docker.internal而非localhost。
保存配置后,如果连接成功,插件状态会自动点亮绿灯。
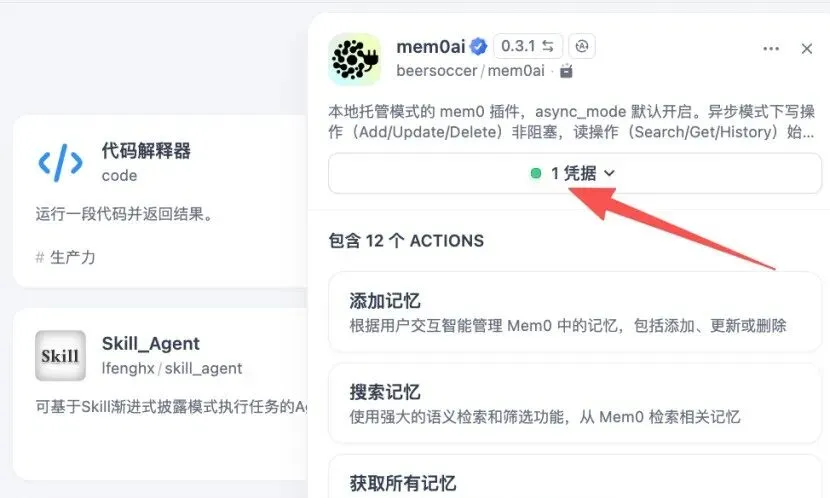
在Dify中创建一个Chatflow(关注本公众号,在后台【私信】中回复“手抄报”,获取本案例DSL),引入mem0ai插件。核心架构如下:
开始节点 → mem0检索节点 → LLM节点 → mem0存储节点 → 回答节点关键配置:user_id 隔离机制
在测试环境下,如何固定user_id?有两种方式:
方式一(推荐):在mem0插件的user_id字段中直接填入{{sys.user_id}}。Dify会自动映射当前用户的唯一标识,无论测试还是发布都有效。
方式二:在流水线中自定义一个变量节点A,设置user_id值,然后在插件中填入{{节点A.user_id}}。手动控制更灵活,适合多用户模拟测试。
🧨 排除干扰:为了避免LLM节点自带的上下文记忆干扰测试结果,需要关闭LLM节点的记忆功能。这样每一次提问都是“失忆”状态,AI完全依赖Mem0来回忆——这才是对记忆能力的真正考验。
笔者在记忆相关模块后添加了输出节点,在测试面板中可以直接看到记忆的检索和存储过程。
轮次01:保存记忆
告诉聊天助手一些信息:“我叫小明,正在参与一个项目,项目编号是9527。”助手提示记忆写入(Mem0已经将这条信息向量化后存入pgvector)。当前的user_id为a94fb6ae-991c-4c69-86f3-26c94d3fc4c7。
轮次02:查询记忆
问下聊天助手:“我叫什么名字?我参与的项目编号是什么?”助手通过Mem0检索到历史记忆,准确返回了刚才的输入信息。
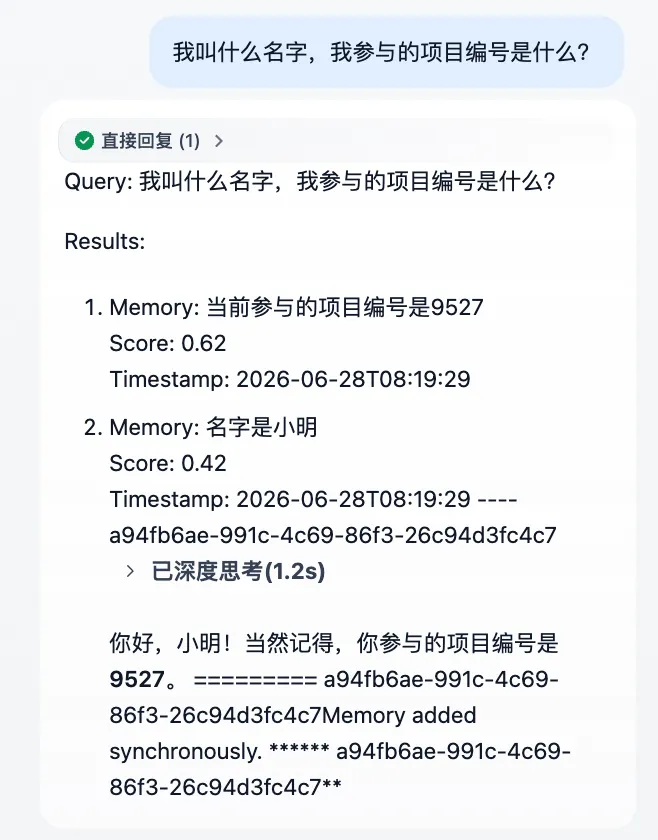
✅记忆能力验证通过!
在终端执行以下命令进入数据库查看原始数据:
docker exec -it pgvector-db psql -U postgres -d mem0db查询记忆表:
SELECT id, payload FROM mem0;可以看到表中完整记录了user_id、交互内容、向量嵌入等结构化数据

👏🏻 你的记忆资产,完全掌握在自己手里!
下篇预告:完全体·本地Mem0服务搭建
至此,我们通过“轻量私有化模式”跑通了Mem0插件,实现了Dify的跨会话记忆。但这个方案仍有局限——记忆只服务于当前这一个Dify应用。
如果我有多个Dify应用,或者还有OpenClaw、Hermes等其他Agent框架,它们之间能否共享同一个记忆库?答案是肯定的。
下一篇,我们将基于docker-compose部署完整的Mem0服务,包含:
API服务:统一记忆读写接口
Dashboard:可视化管理所有记忆
持久化存储:一套记忆库,供多个Dify应用、多个Agent框架共享
届时,你的智能体将拥有一套全局统一的记忆系统——无论哪个Agent、哪个应用,都认得你、记得你。敬请期待!
