 夜雨聆风
夜雨聆风
门诊场景中,有两位患者分期一样,PD-L1 表达接近,TMB 也在同一档,用的是同一套免疫检查点抑制剂方案,结局却走向两端。一位拿到长期缓解,另一位毫无应答,还很快冒出难以收拾的 irAE。这种疗效落差的根子在于免疫系统本身就是一个高维、随机、由大量细胞群落和物理微环境共同驱动的复杂自适应系统。我们手里大多数生物标志物依赖线性相关,本就抓不住免疫应答里那种非线性的全局演变。最近,复旦大学附属中山医院、上海交通大学等多家国内外机构在 Cancer Cell 上发表了一篇题为 OpenIO 的观点文章。给出了一张蓝图:怎样把肿瘤免疫治疗,从靠经验和盲筛的旧路,带到由 AI 从底层机制出发去理性设计的新路。
01 /推文概览
OpenIO 的全称是开源免疫肿瘤学。它想搭的,是一套整合生成式 AI、大规模多组学数据和生物学基础大模型的基础设施。一句话概括它的野心:让免疫治疗的药,从生物库里"撞"出来,变成在计算机里"算"出来、"造"出来。
这套设想有底子。作者团队依托过去十余年积累的多中心泛癌种队列,覆盖数千名患者,既有完整的临床治疗轨迹,也有配套的多组学数据。资源不是凭空起步的。
现在的AI工具基本停在描述和回顾:识别切片里的免疫冷热、区分细胞亚群、做个预后分层。OpenIO 想越过分类这一步,直接走到预测和生成。它的终点是让模型在数字空间里推断出虚拟细胞的状态,再亲手生成全新的治疗性肽段、抗体和细胞因子序列。医学 AI 在这里要从一个"读片工具",长成一台"造药引擎"。
02 /框架概览
整套框架可以拆成四层,环环相扣。
第一层:把生物学"符号化"
现代生成式模型能做复杂推理,前提是输入得先变成离散、可计算的基本单元。文本天然好拆,词和字摆在那里。生物数据不行。单细胞测序给的是连续的表达矩阵,空间转录组给的是带坐标的信号。把这些连续模拟量直接喂给模型,它读不懂里面的生物学语法。
OpenIO 的解法,是给生物学也立一套"语言"。它用一种离散加连续的混合表征,把一个细胞的转录组状态映射成类似句子的结构。
离散的部分保住高层的功能语义,连续的部分留住空间坐标、表达丰度这些精细信息。这样一来,模型就能像并行阅读文献那样,大规模地读细胞数据。更实用的一点是跨模态补全:用常规的 bulk 组织测序,反推缺失的空间细胞排布;只凭单细胞数据,预测某个蛋白在细胞膜上的丰度。临床上做不起全套多组学联检的时候,这种推断能补上一块视野。
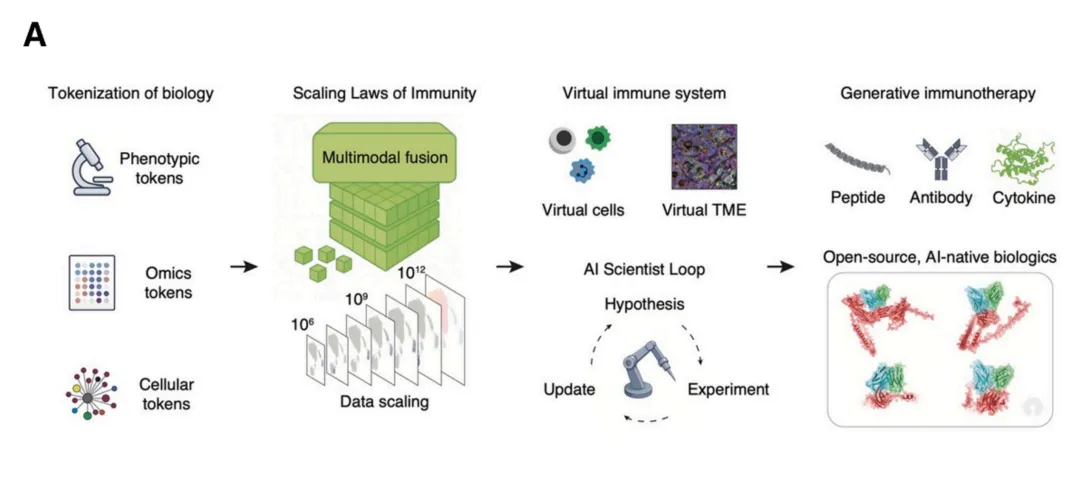
Figure 1A:OpenIO 技术路线图
图注:它画出从生物学符号化开始,多维数据被转成离散可计算的 token,喂给受标度律约束的基础模型,驱动虚拟免疫系统和 AI 科学家闭环,最终生成全新生物制剂的端到端流程。
第二层:免疫标度律
大语言模型有个规律:参数和数据越多,性能越强,这就是标度律。OpenIO 大胆假设,免疫学里也存在类似的免疫标度律,模型表现会随着高质量"细胞 token"的数量和多样性一起往上走。
但作者也明确指出,生物数据和文本是两码事。文本离散、人工校对过、可复现;免疫数据天生嘈杂、随机,还高度依赖测量方式。所以免疫学的标度曲线,指数大概率和 NLP 不一样。更要紧的是,把细胞数从 10⁶ 硬堆到 10⁹,放大的可能是测量噪声,未必是真实的生物信号。现实里,多中心数据用的平台、试剂各不相同,批次效应会顺着训练一路传下去;不同种族、不同性别的免疫差异如果没覆盖好,模型学到的表征也会带偏。严格的数据治理、质控基准、人群均衡,是谈标度之前必须先做的功课。
作者把标度律拆成三种,临床上可以这么理解。
数据标度。当训练规模推到 10⁸ 到 10⁹ 细胞,跨组织、跨扰动、跨疾病阶段,模型可能开始内化免疫学的语义:细胞间通讯的因果、状态转换的调控逻辑、缺氧和细胞因子梯度这类环境依赖、以及分化和耗竭的概率规律。怎么验证?做受控的标度曲线,固定模型结构、逐步加大数据,看分布外预测和反事实推断有没有平滑提升,比如预判一个 CD8⁺ T 细胞在 TGF-β 阻断下的状态走向。平滑上升说明标度律成立;忽高忽低或者撞墙,可能就是生物学本身的天花板,或者缺了某个模态。
多样性与质量标度。免疫组库是自然界最庞大的序列空间,理论上有 10⁹ 到 10¹⁵ 种可能,任何单一数据集都覆盖不全。作者赌的是,对这个空间的覆盖度,和模型预测抗原结合的能力之间存在幂律关系;并且存在一个临界点,过了这个点,模型才算真正推断出底层的生物物理规则,不只是把序列 motif 背下来。
模态标度。生物学是多模态的。把 1D 的序列数据、3D 的结构数据、4D 的纵向临床动态对齐起来,是一种放大器。作者预期多模态预训练能打破单组学模型的瓶颈,比如只给 bulk 表达,就能补出肿瘤的空间组织结构,甚至预判一个冷肿瘤有没有转热的潜力。
第三层:三类免疫基础模型
有了 token 和标度律的设想,接下来就是在 ImmuneAtlas 这类大数据上,训出能跨任务、能少样本迁移的基础模型。作者点了三类。
免疫语言模型。像 IgLM 这样的模型,吃进上亿条免疫受体序列,学会 VDJ 重组和体细胞高频突变背后的统计规律。再叠加扩散模型,就有机会从"读"免疫组库,走到"写"免疫组库。难点在泛化:模型能不能预测训练里没见过的抗原或受体谱系,这得靠系统的基准测试来回答。
抗原与提呈模型。找对靶点和设计武器同样重要。这类模型要把抗原提呈的整条链路还原出来,从体细胞突变,到 MHC 结合,再到 T 细胞识别。HLApollo 这类近期工作,已经开始把表达、加工、提呈整合进一个统一框架。瓶颈也很现实:预测抗原免疫原性比预测结合难得多,因为经过验证的免疫原性数据太少。
微环境世界模型。免疫活性来自肿瘤微环境的拓扑和动态。作者提出用多智能体强化学习来建这个世界模型:每个虚拟细胞当成一个智能体,行为由自身的基因调控网络决定;细胞做节点,信号分子做连边。模型不追求还原每一次原子级碰撞,它要学的是空间动态的统计生成规律,再用 in silico 扰动去探。
这一层给临床研究一种反事实推演的能力。我可以直接在平台上扰动虚拟微环境:阻断 TGF-β 通路,或者掐断肿瘤局部的营养供应,看某群 CD8⁺ T 细胞的耗竭轨迹会怎么偏。它能算的不止单一细胞群的命运,还有整个微环境重新排布的过程。本来要靠动物模型、又慢又贵的筛选,就有机会前移到计算机里先跑一遍。
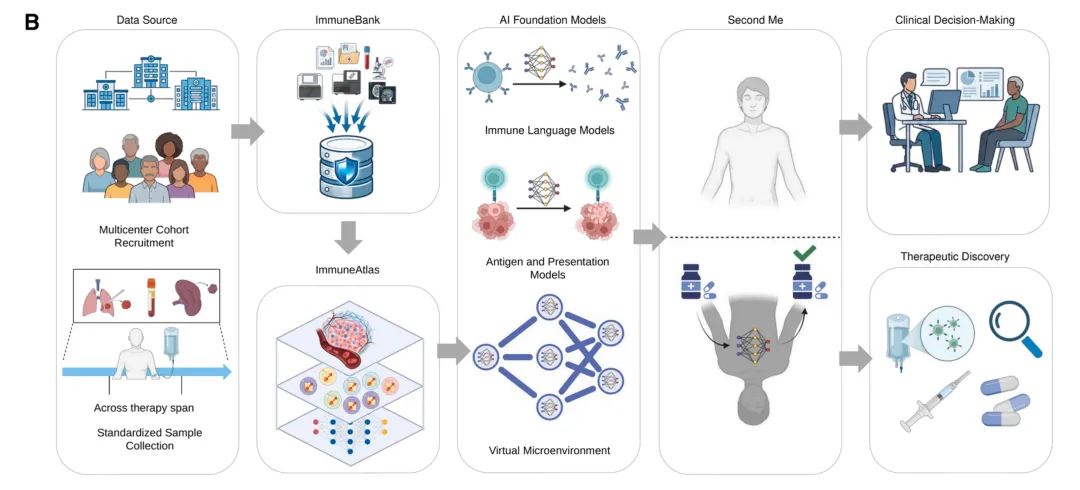
Figure 1B:OpenIO 数据与建模架构
图注:Figure 1B。它呈现从多中心队列招募、标准化采样,到联邦化的 ImmuneBank 与统一的 ImmuneAtlas,再训练出免疫语言模型、抗原提呈模型、虚拟微环境模型三类基础模型,汇成 Second Me 数字免疫孪生,驱动临床决策和治疗发现的完整链路。
第四层:AI 科学家闭环
医学是实证科学。AI 设计的分子,如果在实验室里表达不出来,或者一进体液就聚集、沉淀,这些计算结果就没有转化价值。更麻烦的是,现在的流程要人工把序列搬到湿实验室验证,"阴性结果不发表"的惯例又让大量失败数据被丢掉,算法也就失去了从错误里学习的机会。
OpenIO 设想了一个 AI 当"科学家"的闭环。模型既是设计者,也是实验的指挥者:先提假设,比如某条序列能结合某个靶点,再把合成和检测指令发给自动化的湿实验机器人;机器人测完,无论阳性阴性,都实时回传,用来更新模型。团队成员此前做的 OriGene 系统,是这个想法的一次早期验证。它跨基因组、蛋白组、药理和临床证据做自主推理,已经为肝癌和结直肠癌提名了经过实验验证的新靶点,相关结果目前发表在预印本上。
作者也留了句话:实验噪声、模型不确定性、生物学先验,都必须留在闭环里。自动化能加速发现,它替代不了机制层面的理解和人的把关。
03 /从发现到设计:药是怎么"造"出来的
OpenIO 的落点,是改写药物研发的逻辑:从在现有库里靠运气筛,转向有意图地从头生成。
为了给这件事定个标尺,作者提出了一个指标,叫生成良率,指的是在临床候选药物里,靠计算从头设计出来的那一部分占了多大比例,区别于传统的生物库盲筛。现在这个数字不到 1%。作者把大幅抬高它,定为整个联盟的核心目标。这个基线也诚实地照出了制药业的现状:高度依赖偶然和高通量试错。作者同时声明,这个指标目前还是个愿景,需要随领域成熟去实证检验。我觉得这句声明很关键,它把"良率"从一句口号,拉回到了可被检验的位置。
在具体能"造"什么上,作者列了几条方向。它们是设想中的能力,距离成品还有路要走,读的时候心里有数。
抗体。用 de novo 抗体设计模型生成功能性结合物,覆盖从 scFv、纳米抗体到复杂融合蛋白的多种格式。关键是同时优化结合力和成药性,把溶解度、稳定性、免疫原性一起算进去。
CAR。实体瘤 CAR-T 最大的坎,是 on-target/off-tumor 毒性,因为肿瘤表面的抗原,正常器官往往也有一点。生成模型可以设计带布尔逻辑的 CAR 回路,只有同时满足多抗原条件才启动杀伤,比如"抗原 A 且抗原 B",或者"有抗原 A 且没有抗原 C"。这要求模型在序列、结构、细胞环境上联合推理,所有设计还得嵌入明确的安全约束,防止回路误激活或引发免疫病理。
合成细胞因子。IL-2、IL-12、干扰素这些细胞因子抗肿瘤潜力强,但治疗窗窄、系统毒性大,一直让临床头疼。生成模型可以从第一性原理出发,造出自然界没有的诱饵分子或超级细胞因子,把疗效和毒性解耦:让它优先结合 IL-2Rβγ,避开既带来毒性、又促调节性 T 细胞增殖的 IL-2Rα;或者设计成只在肿瘤微环境那种酸性 pH 下才露出活性构象。
可编程载体。光有载荷不够,递送也得设计。作者预期用生成方法做自组装蛋白纳米颗粒和病毒载体,让它们带上组织趋向性,把 mRNA 疫苗或基因编辑工具直接送到淋巴器官或肿瘤核心,绕开肝脏,降低全身免疫原性。
落地节奏上,联盟给了一张三阶段时间表。作者自己把这些时间点定性为有待努力的目标。
作为对照,传统新一代抗肿瘤药从靶点发现到进入人体,往往要十年以上。OpenIO 想用计算推演,把早期研发的时间和试错成本压下来。
04 /延伸讨论
数字免疫孪生:把试错搬进计算机
作者抛出的一个远景,是给每位患者在数字空间里建一个高保真、可运行的数字免疫孪生体。它的定位是一个动态模拟引擎,会随病情进展自我校准,不像存放静态报告的电子病历夹那样一成不变。设想中的用法是这样:面对晚期、要在多种高毒性联合方案里做取舍的患者,先把他的多组学基线输进系统,生成成千上万个带微小参数扰动的虚拟分身,让它们在计算里把未来几周到几个月的用药轨迹跑一遍。系统回答的,是临床最关心的几个问题:肿瘤会不会缩?T 细胞什么时候开始耗竭?会不会爆发细胞因子风暴?医生因此能提前看到疾病的几条可能走向,再去定干预时机和剂量。
同样的逻辑能搬到临床试验里。在招真实受试者之前,先用覆盖广人群免疫特征的虚拟队列,在服务器上跑一轮 in silico 试验,零风险地找出决定响应与否的生物标志物,再回到真实试验里做精准分层。后期临床试验又贵、失败率又高,这种前置筛查有机会把成功率抬一抬。
开源底座:可能比 AI 愿景更早见效的一步
为了对付实验数据的可重复性危机,联盟承诺建一个非营利的公共资产池,无偿放出一批高价值序列和工具:针对 PD-1、CTLA-4 这些经典检查点的无专利对照抗体序列,针对 EGFR、HER2 等高频肿瘤抗原的验证结合物库,还有用于 IHC 诊断的标准化抗体序列和配套流程。它的意义,在于给全球计算免疫学立一套通用的度量衡,让从亚洲队列里挖出的洞察,能和欧美队列在同一条基准线上比较和转化。
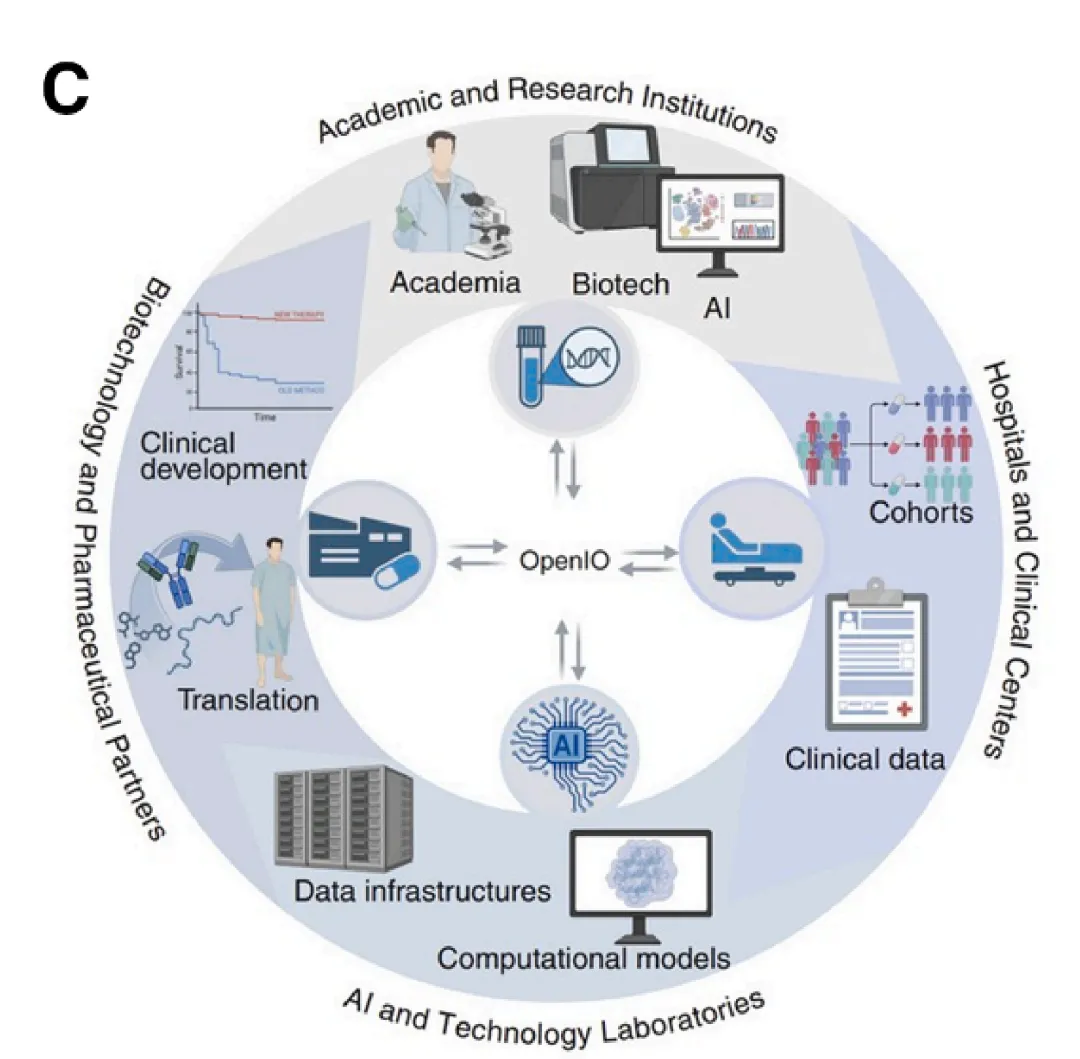
Figure 1C:OpenIO 协作生态系统图
图注:围绕中央协调枢纽,连接基础科研机构、临床中心、AI 实验室和生物医药企业四方,用双向箭头表示数据、模型和序列在四者之间循环反哺。
局限性与展望
这套框架难点在哪里:
模型预测和计算幻觉之间,边界还很模糊。基础大模型在巨大的化学空间里搜索,完全可能给出物理世界里没有活性的假阳性分子。在高通量湿实验真实数据还不够的当下,怎么建一套高效的检验和校准框架,把真正的生物学发现和模型陷在局部最优里的幻觉分开,这块需要大量的探索。
训练数据的系统性偏倚,短期内消不掉。多中心样本库里有测序批次效应,也有种族、性别代表性的失衡。模型如果大量吃进单一来源的免疫特征,它对不同族裔或有性别免疫差异患者的预测,泛化能力会打折扣。源头的标准化和多样性审查跟不上,再大的模型,也只会把偏见用黑箱的方式放大。
高保真数字孪生在急重症场景下有算力和时间的硬约束。要建一个能反映患者当下全身状态的分身,得走完穿刺取样、多组学深测序、原始数据上云、个体化参数微调这一长串流程。这套既慢又贵的工作流,根本接不住那些进展很快、需要医生马上拍板的急重症患者。再加上伦理和监管:对一个由黑箱算法从头生成的全新分子甚至逻辑细胞,临床前毒理怎么评、安全边界怎么划,全球都还没理清。
把肿瘤免疫学从描述性科学,推向更理性的计算工程,这条路注定不好走,时间表里也写满了探索未知的不确定。但随着多组学数据规模上去、底层算法持续迭代,做出更可预测、更可生成的实体瘤工具,已经从纯理论设想,变成正在推进的方向。
原文出处:
Wu Y, Xiao H, Jiang N, Hua W, Ma J, Ge J, Liu Y, Zhang Z, Chen JX, Jin R, Wang Y, Zhou J, Fan J, Zheng Z, Bai L, Ye H, Liu Q, Guo G, Zhang Z, Sun S, Guo T, Zheng S, Gao Q. OpenIO: An open framework for AI-native immunotherapy. Cancer Cell. 2026 Jun 25:S1535-6108(26)00289-8.
— END —
