 夜雨聆风
夜雨聆风咨询巨头埃森哲内部录音流出,曝光了一份 PDF 转 PPT 的任务消耗了巨额 Token,远超预期。
一份普通 PDF 转 PPT,能烧多少 Token?说出来你可能不信,光这一项任务就能烧掉普通用户半年的 AI 订阅费。
这不是个案。CNBC 同期报道:越来越多美国企业已经全部把工作流切换到 DeepSeek,核心原因是「Token 节省」。
你以为你在用 AI 省钱,其实你可能在烧钱。
这篇文章带你拆透 3 件事:
埃森哲录音里,企业 AI 账单失控的真实原因 DeepSeek 为啥成了美国企业的香饽饽 - 5 个 Token 节省实战技巧,让你的一人公司也能省钱
承接上周苹果涨价那篇(《苹果涨价 20%,你正在为 AI 数据中心买单》),这是 6 月 AI 成本观察系列的第 4 篇。
📌 事件回放:埃森哲录音里说了啥
先看几个埃森哲内部对话里的真实吐槽:
「一份 PDF 转 PPT,跑了 3 小时,Token 消耗比预期高 100 倍。」
「客户问我们为什么账单失控,我们也解释不清,因为我们自己的团队也在乱用 AI。」
「我们的提示词工程师花了 2 周优化一个工作流,Token 消耗降低了 80%,这才是 AI 落地的真实水平。」

关键洞察: - 不是 AI 工具贵,是用法贵 - 一份 PDF 转 PPT 烧掉 100 万 Token,提示词没优化的情况下很常见 - 企业级 AI 落地,核心是工作流优化,不是买更贵的模型
📌 企业 AI 账单失控的 3 个真实原因
原因 1:用「聊天」的方式用「工作流」
很多人(包括企业)把 AI 当聊天机器人,问一次问题就完事。但企业级任务(转 PPT、写报告、分析数据)需要多轮调用 + 上下文管理,Token 消耗是聊天的几十倍。
典型场景: - 把 50 页 PDF 丢给 AI,让它「总结一下」 - AI 会读完整篇内容,Token 消耗 = 全文字符数 × 4-5 倍 - 如果 PDF 是扫描件(图片),Token 消耗更高(图片 → 文字 → 处理)
原因 2:提示词没优化,反复问同一件事
很多人不会写提示词,反复问同样的问题,每次都让 AI 重新理解上下文。
典型场景: - 「帮我写一份 XX 报告」→ AI 出 v1 → 「不够好,再写」→ AI 重新写 v2 → 「再改」→ v3... - 每次「再改」都是一次完整推理,Token 消耗 = v1 + v2 + v3... - 优化提示词后,一次到位,Token 消耗降低 80%
原因 3:用「高端模型」做「简单任务」
很多人(包括企业)默认用 GPT-4 / Claude Opus,但高端模型做简单任务,性价比不高。
典型场景: - 简单翻译、文本摘要、格式转换,基本可以用便宜模型 - GPT-4 一次调用成本 = GPT-3.5 的 15-30 倍 - 正确做法:简单任务用便宜模型,复杂任务才用高端模型
📌 DeepSeek 为啥成了香饽饽
CNBC 报道的核心数据:部分美国企业已经把工作流整体切换到 DeepSeek。
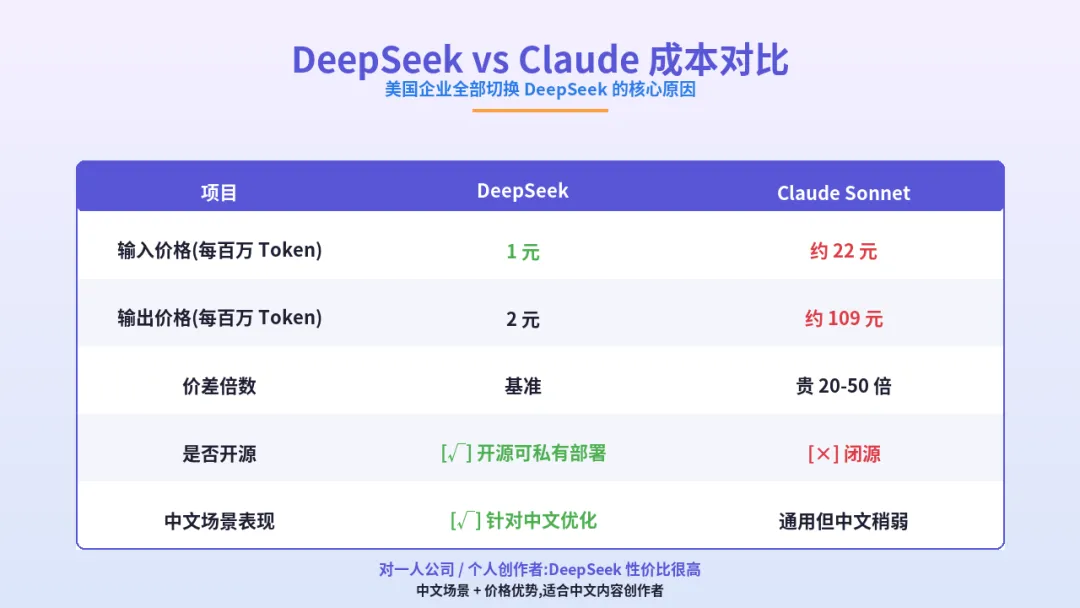
3 个真相:
真相 1:成本可控,价格透明
DeepSeek 的定价是输入 1 元/百万 Token,输出 2 元/百万 Token。
对比 Claude Sonnet:输入 3 美元/百万 Token(约 22 元),输出 15 美元/百万 Token(约 109 元)。
DeepSeek 便宜 20-50 倍。
而且 DeepSeek 价格透明、不锁区、不需要特殊网络。这对企业级采购很关键。
真相 2:开源可私有部署
DeepSeek 是开源模型,企业可以自己部署在自己服务器上。
这意味着: - 数据不出企业,合规要求满足 - 长期成本可控(不用一直付费给闭源 API) - 可以根据自己的业务微调
对企业来说,这不是省 Token 的事,是商业模式的事。
真相 3:对中文和代码场景优化好
DeepSeek 在中文场景和代码生成场景,实测效果接近 GPT-4 级别,但价格只是零头。
对国内一人公司 / 个人创作者,DeepSeek 可能是当下性价比很高的 AI 工具。
📌 一人公司 / 个人创作者的 Token 节省 5 个实战
企业级优化太复杂,但你可以从这 5 个动作开始,立刻降低 AI 账单 50%-80%。

实战 1:大文件先压缩,再丢给 AI
问题:50 页 PDF 直接丢给 AI,Token 爆炸。
解法: - 先用工具把 PDF 压缩成关键内容(提取正文、删除图片说明、合并重复段落) - 如果只需要总结某几章,只复制那几章的内容 - 扫描件先 OCR(用百度 Unlimited OCR 或类似工具)
Token 节省:50%-70%
实战 2:提示词一次到位,别反复改
问题:「再写」「再改」「再优化」,每次都是一次完整推理。
解法: - 写提示词前,先列清楚你的要求(长度 / 风格 / 结构 / 受众) - 一次写完整的提示词(参考「角色 + 任务 + 要求 + 例子 + 输出格式」五要素框架) - 一次性给 AI 全部信息,别分多次补充
Token 节省:40%-60%
实战 3:任务分级,便宜模型干简单活
问题:用 GPT-4 做翻译、摘要、格式转换,大材小用。
解法(工具组合): - 翻译/摘要/改写 → Claude Haiku 或 DeepSeek(便宜) - 代码/数据/分析 → Claude Sonnet 或 GPT-4(中等) - 复杂推理/创意 → Claude Opus 或 GPT-4(高端)
Token 节省:30%-50%
实战 4:用「缓存」功能,避免重复算同一段
问题:同一份文档,每次问不同问题,AI 都重新读一遍。
解法(如果工具支持): - Claude / GPT 的「缓存」(prompt caching)功能,同一份上下文只算一次 Token - DeepSeek 的「system prompt」+「user message」分离,system 部分可复用
Token 节省:50%-90%(看场景)
实战 5:先用便宜模型试,再用高端模型精修
问题:直接用高端模型出稿,烧钱。
解法: - 初版:用便宜模型出 v1(DeepSeek / Claude Haiku) - 精修:用高端模型精修 v1(Claude Opus / GPT-4) - 比直接用高端模型便宜 70%-80%
Token 节省:70%-80%
📌 工具组合策略(豆包 + DeepSeek + Claude 怎么搭配)
如果是你一人公司 / 个人创作者,推荐这个组合:
| 日常写作 | ||
| 中文长文 / 总结 | ||
| 代码 / 数据分析 | ||
| 复杂推理 / 创意 | ||
| PDF / 图片处理 |
预算建议(月成本): - 轻度用户(每天用 1-2 次):¥0(全免费) - 中度用户(每天 3-5 次):¥50-100(DeepSeek + 偶尔 Claude) - 重度用户(每天 10+ 次):¥200-500(组合工具)
💡 一句话总结
埃森哲录音曝光的不是 AI 太贵,是 AI 用法太野。 同样的任务,优化过的提示词 + 工具组合,可以让你从烧钱变成省钱。 一人公司省钱的核心,不是买更便宜的 AI,是用对场景 + 用对模型。
你怎么看?
你平时用 AI,有没有觉得账单超出预期? DeepSeek 你用过吗?对比 Claude / GPT-4 效果怎么样? 你觉得 Token 节省,还有哪些我没提到的方法?
评论区聊聊 👇
