 夜雨聆风
夜雨聆风把资料放进知识库,只是第一步。
真正困难的是,AI 查到资料以后,如何判断它能不能用。
在 CAE 场景里,一个相似案例、一段历史脚本、一条报错解释,表面上都可能和当前问题有关。但只要版本、单位、材料参数或适用范围不一致,它就不能直接进入脚本。
很多知识库失败,不是因为没有召回资料,而是因为召回以后没有判断:这份资料能不能用于当前模型?能不能支撑当前参数?能不能变成脚本里的默认设置?
所以,第二个问题不是“AI 有没有查到”,而是:
查到的资料,凭什么能作为仿真脚本的依据?
这一步如果省掉,RAG 只是在把相似内容更快地送到 AI 面前,并没有让脚本更可靠。
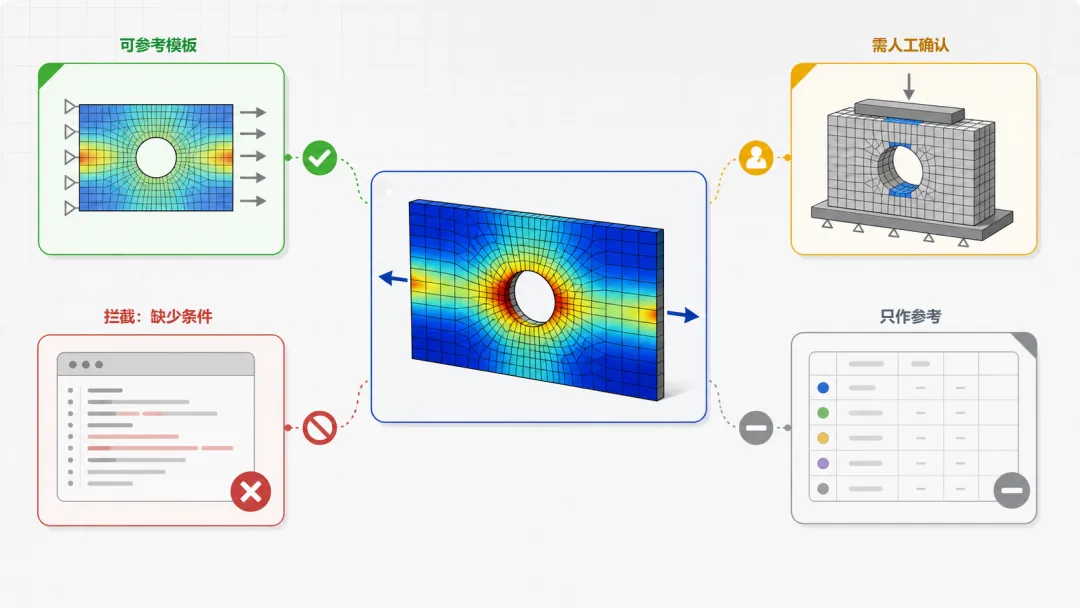
图 1|相似资料只是候选。 看起来相似,也要先判断适用边界。
●1. 相似资料:候选不是依据
在 CAE 知识库里,"查到"只说明资料进入了候选池,不说明它已经能进入工程流程。
一段历史脚本可能确实做过带孔板拉伸,但它也可能绑定了当时项目里的特殊几何、材料、单位和边界条件。
一个错误案例可能看起来很像,但如果没有触发条件,就不能直接变成当前模型的修复结论。
在 CAE 知识库里,"相似"只是候选,不是依据。
这也是 RAG 很容易被误用的地方。向量相似度可以帮 AI 找到可能相关的资料,却不能自动判断 Abaqus 版本是否一致、单位体系是否一致、分析类型是否一致。
比如同样是"带孔板拉伸":
●3D 实体接触模型,只能参考建模思路。
●旧版本 Abaqus 脚本,API 写法需要核对。
●没有单位体系的历史模板,不能直接使用材料参数。
●没有禁用场景的错误案例,不能直接当修复依据。
查到资料以后,第一件事不是写脚本,而是问:这段资料适用于当前问题吗?
●2. 元数据与排序:用工程条件拦住误用
元数据(metadata),就是给每份资料附带的描述标签。
在 CAE 场景里,它更像一组工程审查条件:资料来源、适用版本、单位体系、分析类型,以及不能用于哪些情况。
如果这些条件不清楚,资料就算语义很接近,也只能停在参考层。
●来源和版本:避免 API、规范和历史模板混用;不满足只能参考,不直接套用。
●单位体系:避免材料、载荷和几何尺寸失真;不满足则不使用材料参数。
●分析类型:区分静力、显式、热结构等场景;不满足则不写工程结论。
●模型维度:区分 2D、壳、三维实体模板;不满足则不直接生成脚本。
●禁用场景:暴露旧经验不能用的情况;不满足则先人工确认。
元数据过滤(metadata filter)先按条件拦掉明显不适用的资料。重排序(rerank)再把当前任务带回排序过程:版本、单位、模型维度、边界条件、输出目标。
重排序排第一的,应该是最适合当前问题的资料,而不只是最像的。
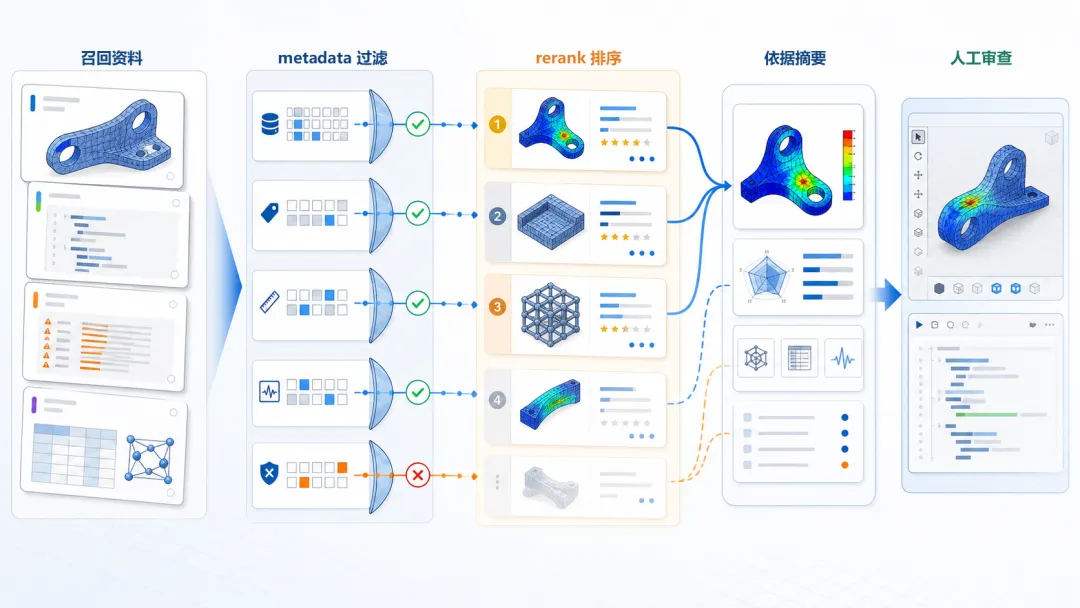
图 2|从召回到可审查依据。 元数据和重排序把候选资料带回工程条件。
重点在于每一步都要能回答一个问题:这份资料为什么能用,为什么不能用,或者只能用到什么程度。流程完整不完整反而是其次。
●3. 报错案例:先暴露依据,再给修改方向
用户运行一个带孔板拉伸脚本,日志提示 DisplacementBC 创建失败,region 为空。右端本来应该施加 x 向位移。
这时,AI 不应该直接给一段"修好后的脚本"。
更稳的做法,是先精确查 DisplacementBC、region、RIGHT_EDGE,再用元数据过滤和重排序筛出适用的模板,把依据链摆出来。
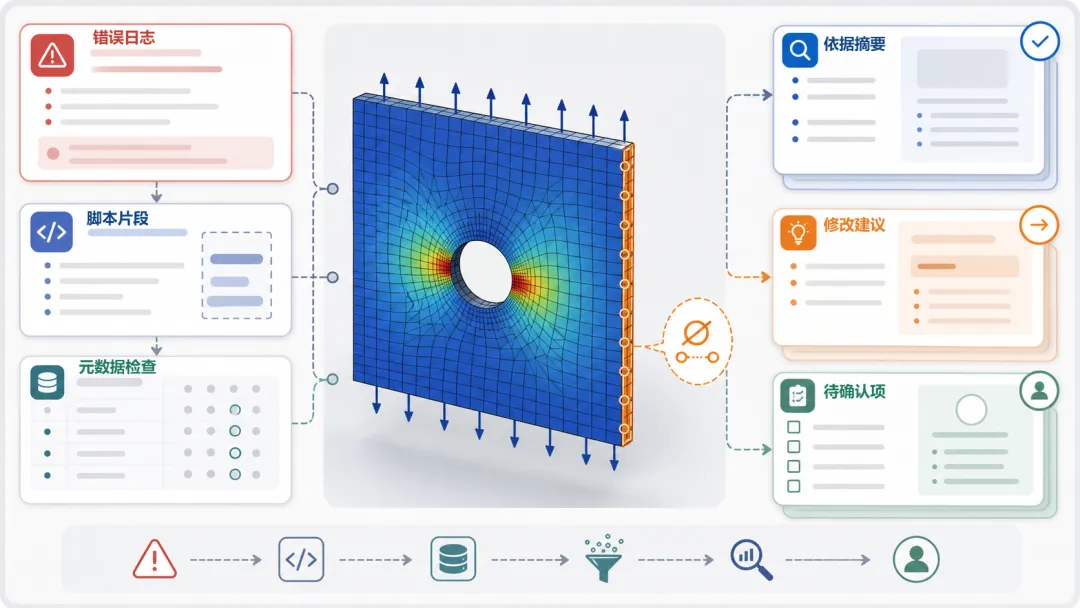
图 3|Abaqus 报错诊断依据链。 先整理日志、模板和待确认项,再给修改方向。
一个可审查的输出应该像这样:
依据摘要:- 类似错误常见于边界条件 region 为空,可能原因是集合创建失败。- 更稳的历史模板使用坐标范围创建 RIGHT_EDGE,而不是依赖固定边索引。- 当前资料只支持给出修改方向,不支持写工程强度结论。待确认:1. RIGHT_EDGE 是否确实为空?2. 右端位移是否施加在整条边上?3. 本次是否只用于流程调试,不作为工程强度结论?
可靠的知识库不会直接把报错翻译成答案,它会把日志、模板、规范和待确认项组织成一条可追溯的修正依据。
●4. 输出边界:AI 给摘要,工程师下判断
AI 检索后的第一产物,是依据摘要。
依据摘要要说清楚:来源是什么,适用范围是什么,关键假设是什么,冲突点在哪里,还有哪些地方需要人工确认。
在进入 MCP 执行、脚本生成或报告草稿之前,这些边界尤其重要:
●单位不一致,不写材料结论。
●版本不匹配,不直接套用 API。
●历史脚本没有适用范围,不作为规范。
●ODB 结果没有复核,不写设计通过。
●工程假设没有确认,不让 AI 自动执行。
RAG 能减少无依据生成,但不能保证建模判断天然正确。
本期这个 Abaqus 报错案例只是方法推演,不是本地复现实测,说明的是依据链怎么组织,不代表某个脚本已经被修复。
回到本期的问题:查到资料以后,AI 怎么判断它能不能用?答案是别让模型自己相信相似度,把每一段资料都放回工程语境去审——来源、版本、单位、场景、禁用范围。
这些条件说清楚了,检索结果才能变成依据摘要;依据摘要能被工程师审查通过,脚本草稿才能进入下一步执行。
下一步问题|依据说清楚以后,动作也要可审查。
知识库解决的是“凭什么这么做”。进入工具调用之前,还要说明“准备做什么、谁来确认、什么时候停止”。这一步,决定 AI 是在辅助工程流程,还是只是在更快地生成风险。
