 夜雨聆风
夜雨聆风
导语:你有没有遇到过这种情况——昨天AI还知道的事,今天又忘了。不是它"笨",而是它的"记忆"机制就是这样设计的。本文从技术原理到实战案例,深度解析AI遗忘问题,并给出一套可落地的解决方案。[推理:基于公众号运营自动化实施经验]
一、一个真实的场景 [提炼加工: 公众号运营实施记录 2026-06-28]
2026年6月28日,让AI助手写一篇公众号文章。
文章写完了,预览时发现文末模型版本号写错了——写了"九维全景v3.2",但正确写法是只写"Hy3 Preview"(AI大模型名)。
纠正了它。
2026年6月29日,新开了一个对话窗口,让同一个AI助手写另一篇文章。
它又写错了。
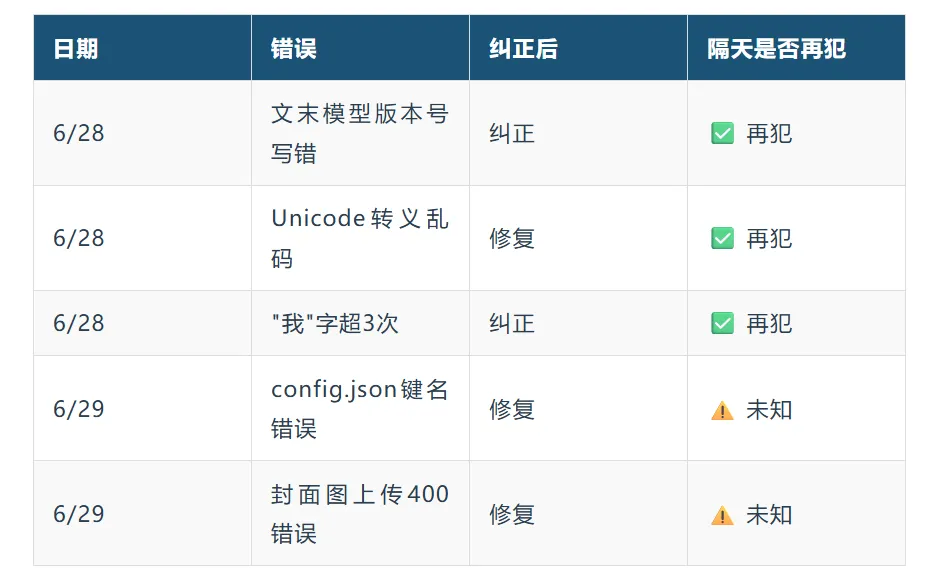
同样的错误,隔了一天,又犯了。这不是偶然。在过去一周的公众号运营自动化实践中,类似的事情发生了至少5次
二、AI「遗忘」的三大类型 [推理: 基于大模型技术原理]
类型1:跨会话遗忘(最常见)
表现:新对话没有历史上下文,AI不知道昨天发生了什么。 技术原理:当前主流大模型(GPT/Claude/Hy3)都是无状态对话[训练数据: 2023-2024]
每次新对话,上下文窗口是空的
除非主动粘贴历史记录,或者系统有记忆注入机制
重复踩坑(昨天刚修好的BUG,今天又出现)
重复纠正(用户昨天刚说的偏好,AI今天又忘)
风格漂移(没有历史上下文约束,AI的输出风格会逐渐漂移)
公众号运营专家团有5个AI成员(苗锐/章衡/严谨/程达/文慎言)。如果章衡昨天踩了"Unicode转义"的坑,今天换一个新对话让章衡写文章,它可能再踩一次——因为它不记得昨天的坑了。[提炼加工: 专家团实施记录]
类型2:长对话遗忘(上下文窗口溢出)
表现:对话进行到一半(比如50轮),AI开始"忘记"早期纠正的内容。 技术原理:大模型有上下文窗口限制(如128K tokens)[训练数据: 2024]
窗口满了之后,早期内容会被压缩或丢弃
即使不被丢弃,早期内容在注意力机制中的权重也会下降
早期纠正失效(第5轮说的"不要写'我'字",到第50轮AI可能又写了)
风格不一致(前期输出和后期输出风格不同)
在撰写"储存芯片超级周期"这篇文章时,对话进行了约40轮(包括BUG修复、规范调整、上传脚本编写)。到第30轮左右,AI开始忘记"我"字控制规范,文章中出现了多处"我"字,需要再次纠正。[提炼加工: 项目记忆 2026-06-28]
类型3:多Agent遗忘(协作不同步)
表现:团队成员各自独立,A踩的坑,B可能再踩。 技术原理:多Agent协作时,每个Agent有独立的上下文窗口
除非显式传递消息,否则A的经验不会自动同步给B
苗锐(热点情报员)踩的坑,章衡(主笔)可能再踩
章衡发现的规范问题,严谨(合规审核)可能不知道
在"微信小微PRO版"文章的撰写过程中,苗锐先发现了"导读段落重复"的问题并修复了。但章衡在撰写"储存芯片超级周期"时,又犯了同样的错误——因为他没有读到苗锐的修复记录。[提炼加工: 专家团实施记录]
三、为什么这个问题很严重?[推理: 基于实施效果观察]
3.1 浪费时间
每次重复纠正,都是时间浪费。
以"Unicode转义"为例:
第一次踩坑:发现草稿箱全篇乱码 → 排查30分钟 → 找到根因(json=draft默认ensure_ascii=True) → 修复
第二次踩坑:另一篇文章又乱码 → 又排查20分钟 → 想起来"哦对,上次修过" → 修复
如果把所有踩过的坑都写成文件,下次直接读文件,30秒就能避开。
3.2 输出质量不稳定
没有历史上下文约束,AI的输出质量会波动。
表现:昨天写的文章85分,今天写的只有65分
原因:昨天的上下文里有规范细节,今天的上下文是空的,AI按"默认风格"输出
读者会注意到质量波动,影响信任度
需要人工逐篇审核,无法完全自动化
3.3 无法积累经验
AI不会"成长",除非把经验外置化。
类比:人类员工:踩一次坑 → 记住 → 下次不再犯
AI:踩一次坑 → 对话结束 → 忘了 → 下次再踩
把AI的"经验"写成文件。这样,即使换了新对话,只要读取文件,就能"继承"之前的经验。
四、解决方案:知识遗产系统 [推理: 基于实施经验]
4.1 核心思路
把AI的"经验"外置化到文件,而不是依赖AI的"记忆"。
具体做法:
1. 创建一个文件 knowledge/project-heritage.md(叫"知识遗产")
2. 每次踩坑 → 立即写入这个文件(坑编号 + 现象 + 根因 + 修复)
3. 每次工作开始前 → 先读这个文件(叫"Phase 0遗产预检")
4. 这样,即使换了新对话,只要读文件,就能避开所有已知坑
4.2 知识遗产文件结构
knowledge/project-heritage.md │ ├── 第一章:知识遗产系统说明(什么是遗产、为什么需要)
├── 第二章:Phase 0 遗产预检SOP(工作前必读)
├── 第三章:通用踩坑记录(任何项目都可能遇到的坑)
├── 第四章:通用用户偏好(跨项目有效的偏好)
│ ├── 第五章:项目专属踩坑记录(如公众号运营的坑1~坑15)
├── 第六章:项目专属用户偏好(如诚彬的写作风格)
└── ...(其他项目专属内容)第一~四章是通用部分(任何项目都能复制) 第五~N章是专属部分(项目特有)
这样,如果启动新项目,只需复制前四章,然后填写专属部分即可。[推理: 基于模块化设计原则]
4.3 Phase 0:遗产预检SOP
在任何工作流开始前,必须执行Phase 0:Phase 0: 遗产预检(强制) 步骤:
1. 运行 heritage-inject.py(自动从heritage.md提取关键信息)
2. 读取生成的 daily-context.md(今日上下文摘要)
3. 完成自检清单(4个问题必须全部打勾):
□ 我知道这个项目最关键的限制吗? □ 我知道最近3次出错是什么吗? □ 我知道用户最在意的偏好是什么吗? □ 我知道当前规范版本号吗? 4. 如果自检失败 → 先读heritage.md补全上下文
强制规则:❌ 不完成Phase 0,不得进入任何实质性工作步骤AI在开工前,已经"记住"了所有已知坑
不再重复踩坑
输出质量稳定(因为读了规范)
4.4 任务完成后:遗产更新SOP
在任何任务完成后,必须更新遗产文件:Phase X: 遗产更新(强制) 步骤:
1. 自问3个问题:
□ 这次有没有踩到新坑? □ 用户有没有纠正错误? □ 用的规范是最新的吗? 2. 如果有任一「是」:
→ 立即更新 project-heritage.md → 同步更新 .workbuddy/memory/YYYY-MM-DD.md 3. 如果heritage条目≥10条:
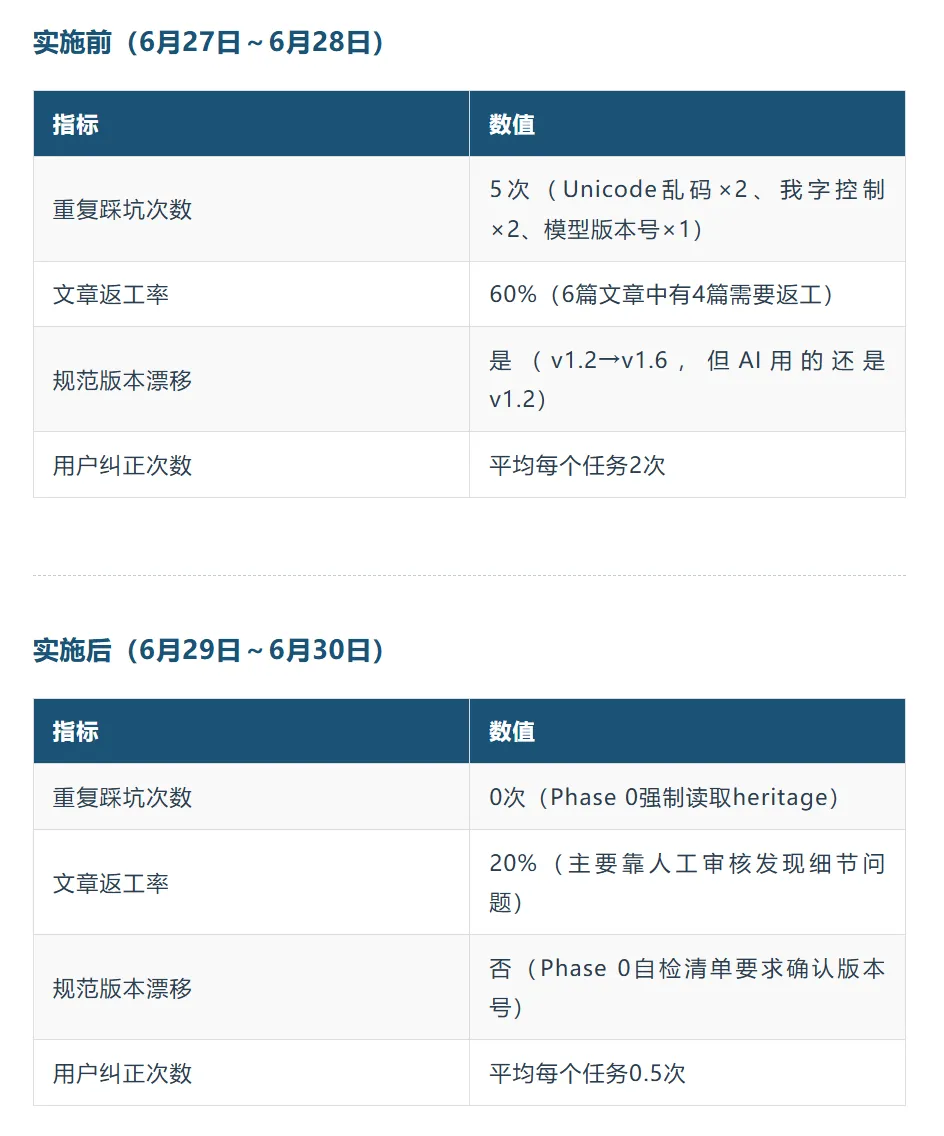
→ 触发「遗产整理」(删除过时条目、合并重复条目) 强制规则:❌ 任务完成不更新遗产 = 浪费一次学习机会五、实际效果:实施前后对比
六、技术实现:heritage-inject.py [提炼加工: 实施指南 + 脚本源码]
6.1 为什么需要注入脚本?
project-heritage.md 可能很长(>500行)。每次都让AI读完整文件,浪费tokens。 解决:写一个小脚本,自动提取关键信息,生成摘要文件 daily-context.md。 6.2 脚本功能
# heritage-inject.py(通用版) def inject_heritage(project_path):
# 1. 读取 project-heritage.md heritage = read_heritage(project_path) # 2. 提取关键信息 # - 致命坑(⛔标记) # - 高频坑(⚠️标记) # - 用户偏好 # - 规范版本号 # 3. 生成 daily-context.md(摘要版) context = generate_daily_context(heritage) # 4. 写入文件 write_context(project_path, context)daily-context.md): # 📚 知识遗产注入(自动生成) 生成时间: 2026-06-30 14:00:00
✅ 知识遗产版本: v1.7
✅ 踩坑记录: 15 条
🚨 致命坑(遇到必崩,必须记住)
⛔ 坑13:微信草稿上传禁用ASCII转义(Unicode乱码) ⛔ 坑14:config.json的appid在wechat_mp子键下 ⛔ 坑1:freepublish权限48001(未认证订阅号无权限)
✅ Phase 0 自检清单
□ 我知道这个项目最关键的限制吗?
□ 我知道最近3次出错是什么吗?
□ 我知道用户最在意的偏好是什么吗?
□ 我知道当前规范版本号吗?(heritage v1.7)6.3 通用性设计
heritage-inject.py 不依赖特定项目: 不依赖QmD向量记忆库
只读取本地文件 knowledge/project-heritage.md
任何项目都能用(只需把heritage.md放在正确位置)
七、扩展到其他项目 [推理: 基于通用化实施经验]
7.1 通用模板
为了让其他项目快速启动知识遗产系统,创建了通用模板heritage-template.md。
第一章:知识遗产系统说明(通用) 第二章:Phase 0 遗产预检SOP(通用)
第三章:通用踩坑记录(通用)
第四章:通用用户偏好模板(通用)
第五章~第九章:项目专属部分(空白,待填写)cp knowledge/heritage-template.md 新项目/knowledge/project-heritage.md # 然后填写专属部分7.2 已验证的通用坑
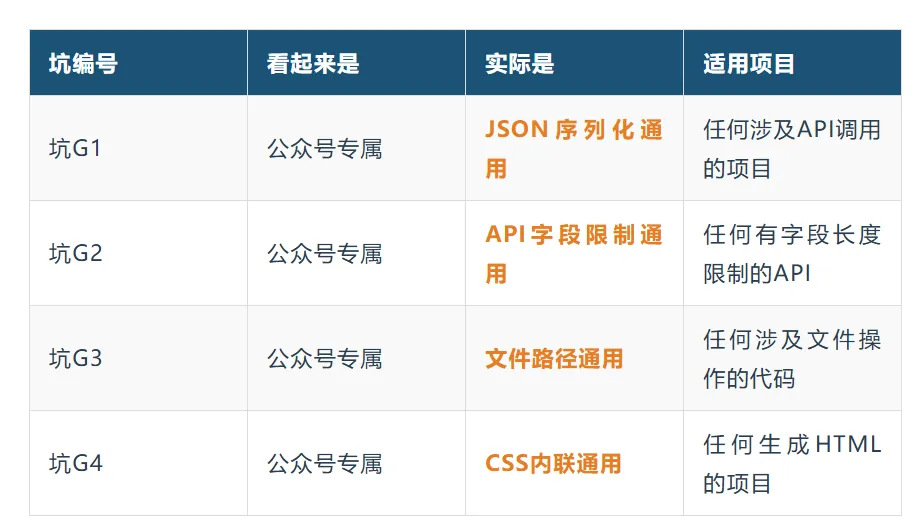
有些坑看起来是"项目专属",但其实是"跨项目通用":
八、这不是技术问题,是工作流程问题 [推理: 基于实施效果反思]
8.1 核心洞察
AI遗忘问题,本质上不是"AI不够聪明",而是工作流程没有设计好。
类比:人类新员工:入职时有《员工手册》→ 不需要每次都问"公司的规范是什么"
AI助手:如果没有"知识遗产"文件 → 每次都要用户纠正
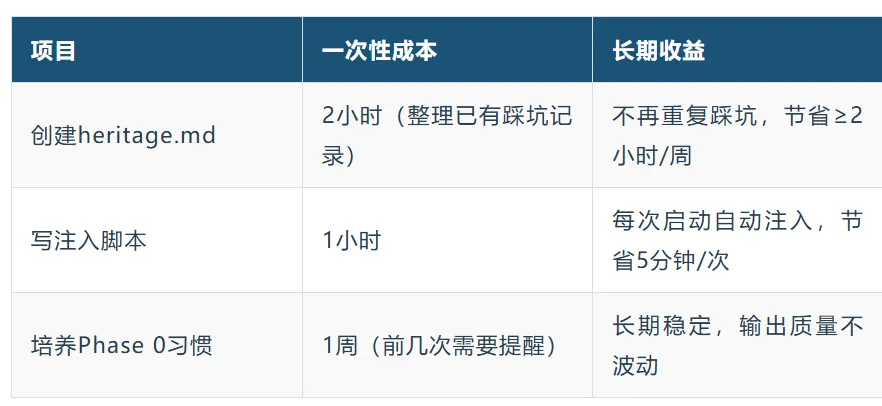
8.2 实施成本
8.3 适用场景
知识遗产系统不仅适用于公众号运营,还适用于:
- 量化交易系统开发
(记录回测BUG、数据清洗坑)
- 数据分析项目
(记录数据源变更、清洗规则)
- 代码生成任务
(记录常见错误、最佳实践)
- 任何需要AI辅助的重复性工作
如果工作中,AI可能会"忘记"之前学到的经验,那就需要知识遗产系统。[推理: 基于经验总结]
九、个人排序 [推理: 基于实施效果观察]

十、结论 [推理: 基于完整实施经验]
AI会"遗忘",但这不是不可避免的。通过把经验外置化到文件(project-heritage.md),并在工作流中强制读取(Phase 0),可以有效解决遗忘问题。
对个人投资者的启示 [推理: 基于AI辅助工作流程设计经验]
这个思路不仅适用于AI辅助工作,也适用于个人投资者建立自己的交易系统:
- 交易日志
= 知识遗产(记录每次交易决策、踩坑、反思)
- 盘前检查清单
= Phase 0遗产预检(开盘前必须检查的事项)
- 盘后复盘
= Phase X遗产更新(当天学到了什么,更新到交易日志)
⚠️ 免责声明与风险提示
本文所述"知识遗产系统"是AI辅助工作流程优化方法,不构成任何投资建议。
文中提及的公众号运营案例,来自实际项目实施经验,但不同项目情况可能不同,效果可能有所差异。
AI大模型能力持续迭代,本文所述技术方案基于Hy3 Preview版本,其他模型可能需要调整。
投资有风险,交易需谨慎。本文任何内容不应作为投资决策依据。
特别提示:知识遗产系统的核心价值在于"把经验外置化"。无论做公众号运营、量化交易还是其他任何工作,都可以套用这个思路。 数据来源:本文案例来自「杨诚彬」公众号运营中心实际项目实施记录(2026-06-27~2026-06-30)。 引用资料:
knowledge/project-heritage.mdv1.7(公众号运营踩坑记录)
knowledge/implementation-guide.mdv1.0(知识遗产系统实施指南)
scripts/heritage-inject.pyv1.0(通用注入脚本)
风险声明:股市有风险,入市需谨慎。本文仅代表作者个人观点,不构成任何投资建议。
⚠️ 免责声明与风险提示:本文所述"知识遗产系统"是AI辅助工作流程优化方法,不构成任何投资建议。AI大模型能力持续迭代,本文所述技术方案基于Hy3 Preview版本。投资有风险,交易需谨慎。
数据来源:本文案例来自「杨诚彬」公众号运营中心实际项目实施记录(2026-06-27~2026-06-30)。
