 夜雨聆风
夜雨聆风前两周阿里开源的 page-agent 不知道各位看官是否了解,一行 <script> 标签就能让你用嘴操控网页。虽然我写了报道,但因为之前某种我吐槽的原因,这家公司的产品我不太敢讲了,一直躺在我的草稿箱,没发出来。
结果这两天 browser-use 团队又丢了个新东西出来:video-use。它可以让你用 Claude Code 剪视频。
今天把这两个项目放在一起讲,虽然它们做的事八竿子打不着,但都源自于同一个思路。
核心思路:别给 LLM 看像素
browser-use 最早出名,是因为它做网页自动化的时候走了一条反直觉的路:不给 AI 截图。
别人的做法是开个无头浏览器,截一张整页图,丢给大模型。模型看着图猜:这个按钮在哪,那个输入框叫什么。50 张图一丢,几百万 token 没了,大部分信息是像素噪音。
browser-use 的做法是直接把 DOM 树脱水成结构化文本:
[button] 提交订单 (id: submit-btn)[input] 收货地址 (placeholder: 请输入详细地址)[text] 订单总额: ¥299.00AI 读这段文本比看截图快得多,也准得多。它不需要做 OCR,不需要猜测元素位置,直接就知道页面上有什么、能干什么。
这个思路从 browser-use 传到 page-agent(阿里照着同样的思路做了个纯前端版),现在又传到了 video-use。
page-agent:让网页能听懂人话
我们先看看 page-agent,它做的事用一句话就能说清楚:把 AI 操控网页这件事,从外部遥控变成了内部驱动。
传统网页自动化(Playwright、Selenium)的本质是用代码模拟人类点击。你得写脚本找到按钮、点击、等待加载、再找下一个元素。每一步都可能因为 DOM 变化而崩溃。
page-agent 不一样。它直接注入到你的网页 JavaScript 运行时里,读取整个 DOM 树后文本化,然后把这个结构化描述丢给你指定的 LLM(通义、DeepSeek、豆包、Ollama 本地模型都行)。LLM 理解用户意图后返回操作指令,page-agent 在浏览器里直接执行。
结果是用户可以说帮我把购物车里价格超过 200 的删掉,page-agent 不用截图、不用 Playwright、不用单独起 Python 进程。就是一行 <script> 标签。
笔者实际体验了下这个脚本,它的场景还是太受限了,经常识别不出来,希望它迭代得越来越好吧,毕竟思路很新鲜,也是对的(笔者以为)。
v1.10.0,1028 个 commits,2 万 stars,MIT 开源。阿里的维护节奏相当密集。
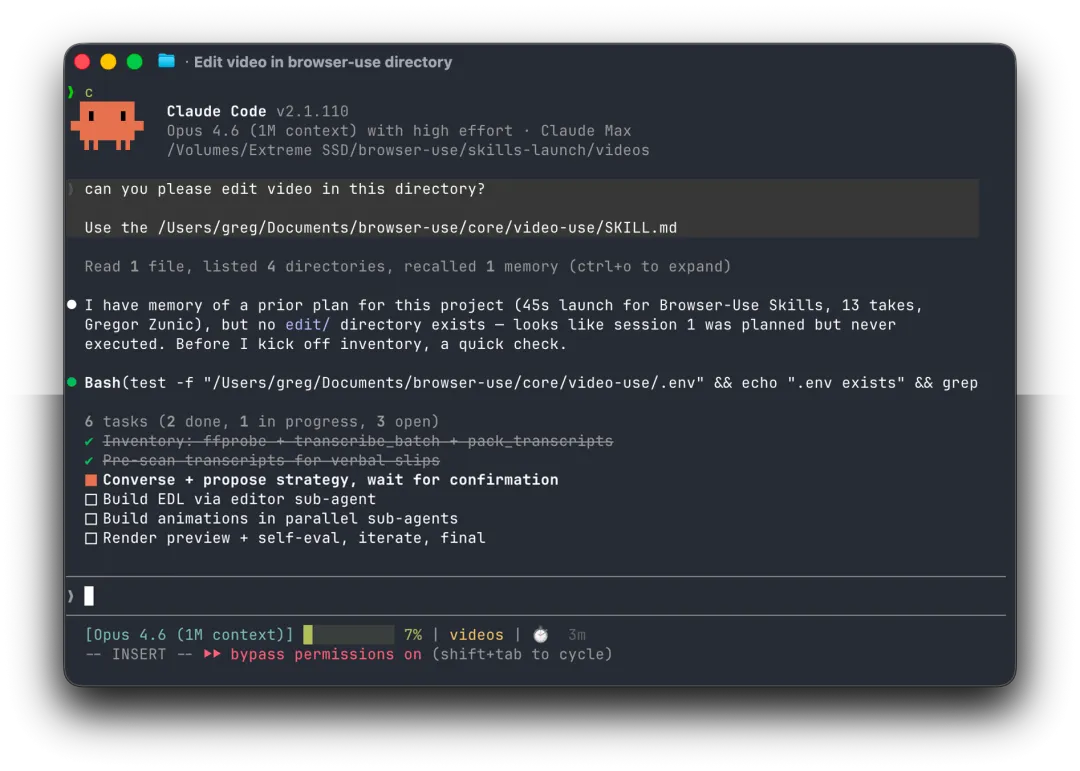
video-use:让 Claude Code 帮你剪片子
再来看看 video-use,它是 browser-use 团队的新项目,同样的核心理念,换了个战场。
常规的 AI 视频工具怎么做的?把视频拆成几万帧,一帧一帧丢进模型看。一段 10 分钟 30FPS(如果是 60 或者 120 帧呢?) 的视频 = 18000 帧,就是 2700 万 token。大部分帧之间几乎一模一样,全浪费了。
video-use 的做法完全相反:AI 从来不看视频画面,它只读文本。
怎么做到的?两层:
第一层,音频转录。 用 ElevenLabs Scribe 把每段素材转成带毫秒级时间戳的文字,包括说话人识别、音频事件(笑声、掌声、叹息)。所有素材打包成一个大约 12KB 的 takes_packed.md 文件:
## C0103 (duration: 43.0s, 8 phrases) [002.52-005.36] S0 一个网页 Agent 百分之九十的动作都是浪费。 [006.08-006.74] S0 我们修好了这个问题。怎么样?像不像某些电影字幕文件?🤣
第二层,按需截图。 只在决策点调 timeline_view,生成音频波形+关键帧+字幕对齐的合成图。LLM 不用看全片,只在某个时刻需要决策这个地方要不要切时看一眼。
不用看视频,AI 就能确定哪里要剪、哪里要删死词(um、ah、false start)、哪里加 30ms 音频淡入防止爆音、哪里烧字幕。
工作流是这样的:
用户丢素材进文件夹 → LLM 读转录文本 → 提出剪辑策略 → 用户确认 → 生成 EDL 剪辑表 → ffmpeg 渲染 → 自动自检每一个剪切点 → 没问题才给你看
final.mp4
MIT 开源,目前 12K stars,还在快速迭代。
不同团队,同一套思路
browser-use → page-agent → video-use,这三个项目跨越了两个组织,但串成了一条共同的逻辑线:
不再让 AI 去看世界,而是把世界翻译成 AI 读得懂的文本。
网页自动化:不给截图,读 DOM。视频剪辑:不送帧,读时间轴+字幕。这条线再推一步,你觉得会是什么?
文档处理不需要给 PDF 截图,读 Markdown 就够了。3D 建模不需要渲染图,读网格参数。代码审查更不用看 diff 截图,读 AST 就行。
核心逻辑都是一样的:大模型擅长理解结构化文本,不擅长理解像素。 你把现实世界的问题翻译成它擅长的输入格式,它就能做对。
不搞花里胡哨的多模态框架,不堆几十万 token 的上下文窗口,不给模型灌 99% 的噪音信息。就是老老实实把数据提取干净,用最小的信息密度喂给 LLM。
这个思路一点都不炫,但真的很实用。
这对我们意味着什么
如果你是做工具的,以后考虑 AI 集成的时候,想想这个模式:你的数据里什么对 LLM 有用?什么只是噪音?把有用的文本化,噪音扔掉。别一刀切地截图或者 dump 整个文件。
如果你是前端,page-agent 值得试试。不需要后端,不需要 Python,一行 JS 就能让你维护的产品学会听懂用户说什么。Chrome 扩展和 MCP Server 都在 beta 了,以后浏览器本身可能就是一个 Agent 运行环境。
如果你做内容创作,video-use 是肉眼可见的实用。不是替换 Premiere 或达芬奇,是为那些知道想怎么剪但不想花两小时拖时间轴的场景准备的。你描述意图,它执行。
browser-use 这个团队一直在做一件事:把现实世界的交互界面翻译给 LLM。有意思的是,大洋彼岸的阿里也看到了同一个方向,用几乎相同的思路做了 page-agent。两拨人没有开会、没有对口径,但得出的结论一模一样。说明这条路不是巧合,是规律。
从网页到视频,下一个是什么,我不知道。但我知道这种翻译层中间件,会是 Agent 时代最值钱的一层。
视野决定终点,与君共勉。如果本文对您有帮助,不妨动动手指点下 👍 和 💗,让更多人看到,谢啦!
欢迎关注 前沿信标。
