









文档内容
绝密★考试结束前
2024 年 6 月浙江省普通高校招生选考科目考试
技术
考生须知:
1.答题前,请务必将自己的姓名、准考证号用黑色字迹的签字笔或钢笔分别填写在试题卷和
答题纸规定的位置上。
2.答题时,请按照答题纸上“注意事项”的要求,在答题纸相应的位置上规范作答,在本试
题卷上的作答一律无效。
3.非选择题的答案必须使用黑色字迹的签字笔或钢笔写在答题纸上相应区域内,作图时可先
使用2B铅笔,确定后必须用黑色字迹的签字笔或钢笔描黑。
第一部分 信息技术(共50分)
一、选择题(本大题共 12小题,每小题2分,共24分。每小题列出的四个备选项中只有一
个是符合 题目要求的,不选、多选、错选均不得分)
1. 某校基于线下校史馆创建在线数字校史馆,将学校发展历史及校友的代表性成果、活动影像等资料,以
文本、图像、视频等格式存储。校友可以用手机、电脑等终端登录数字校史馆查阅资料,也可以向在线问
答机器人咨询学校相关信息。关于该数字校史馆中数据的叙述,正确的是( )
A. 数字校史馆中的数据有助于学校传承与发展,体现了数据的价值性
B. 不同格式的数据必须保存在不同的存储设备中
C. 学校的发展历史只能以同一种数据表现形式呈现
D. 文本、图像、视频都是结构化数据
【答案】A
【解析】
【详解】本题考查数据相关内容。数据是对客观事物的符号表示,数据可以是文字、数字、符号、表格、
图像、语音、视频等,它直接来源于事实的记录,可以通过原始的观察或者度量获得。A选项,数据是有
价值的,通过加工数据可以挖掘出数据中隐含的价值,选项正确。B选项,同一存储器(如:硬盘、U
盘)可以存储不同格式的数据,选项错误。C选项,数据的表现形式是多样的,可以是文字、图形、图像、
音频、视频等,选项错误。D选项,结构化数据是一种以特定格式组织和存储的数据,这种格式可以很容
易地被计算机程序理解和处理,并且可以使用表格、电子表格或数据库来表示;非结构化数据是一种不具
有特定格式或结构的数据,它的特点通常是缺乏组织,可以包括文本、图像、音频和视频文件、社交媒体
帖子、电子邮件和其他数据源;文本、图像、视频属于非结构化数据,选项错误。故本题答案是A选项。2. 某校基于线下校史馆创建在线数字校史馆,将学校发展历史及校友的代表性成果、活动影像等资料,以
文本、图像、视频等格式存储。校友可以用手机、电脑等终端登录数字校史馆查阅资料,也可以向在线问
答机器人咨询学校相关信息。下列有关信息安全与保护的做法,合理的是( )
A. 定期备份数字校史馆数据 B. 未经校友同意发布其资料
C. 随意剪辑校友的活动影像 D. 以明文方式保存校友的注册信息
【答案】A
【解析】
【详解】本题考查的是信息安全与保护。未经校友同意发布其资料、随意剪辑校友的活动影像侵犯了校友
的隐私权;以明文方式保存校友的注册信息,容易造成信息泄露。故本题应选A。
3. 某校基于线下校史馆创建在线数字校史馆,将学校发展历史及校友的代表性成果、活动影像等资料,以
文本、图像、视频等格式存储。校友可以用手机、电脑等终端登录数字校史馆查阅资料,也可以向在线问
答机器人咨询学校相关信息。为使问答机器人更准确地回答校史相关问题,下列方法可行的是( )
A. 增加校友的最新作品 B. 提高咨询所用终端的性能
C. 完善语料库中的校史资料 D. 提升数字校史馆的访问速度
【答案】C
【解析】
【详解】本题考查人工智能相关内容。本题涉及到人工智能语料库知识,语料库指的是用于训练人工智能
的文本库或数据集合,这个语料库是人工智能审查的材料,以使其在设计时变得智能。A选项,校友最新
作品内容广泛,和校史关系不紧密,不能有效提高机器人回答问题的准确性,选项错误。B选项,提高终
端性能主要影响用户与机器人的交互体验,如响应速度等,但并不影响机器人回答问题的准确性,选项错
误。C选项,问答机器人的回答准确性高度依赖于其所依赖的数据或语料库,完善语料库中的校史资料有
助于建立更加完善的数据模型,提高问答准确性,选项正确。D选项,提升访问速度有助于提升用户体验
感,但并不影响问答机器人回答问题的准确性,选项错误。故本题答案是C选项。
4. 某校基于线下校史馆创建在线数字校史馆,将学校发展历史及校友的代表性成果、活动影像等资料,以
文本、图像、视频等格式存储。校友可以用手机、电脑等终端登录数字校史馆查阅资料,也可以向在线问
答机器人咨询学校相关信息。下列对校史馆资料的处理方式,不合理的是( )
A. 为了方便预览,为高清图像生成缩略图
B. 为了节省存储空间,将JPEG格式的图像转换成BMP格式
C. 为了方便传输,对高清视频进行压缩
D. 为了便于检索,将纸质文稿扫描成图像后识别出文字一并保存
【答案】B
【解析】【详解】本题考查的是数据处理。缩略图用于在 Web 浏览器中更加迅速地装入图形或图片较多的网页,
因其小巧,加载速度非常快,故用于快速浏览,选项A合理;图像格式BMP是未压缩格式,JPEG是有损
压缩后的格式,将BMP转换为JPEG,可以使文件变小,节省存储空间,选项B说反了,故不合理;高清
视频文件通常很大,通过压缩可以显著减小文件大小,方便传输,选项C合理;通过扫描将纸质文稿转为
图像文件,再通过字符识别从图像中识别出文字,通过文字能更方便实现检索,选项D合理。故本题应选
B。
5. 某小区智能回收箱可通过刷卡、扫码等方式开启箱门,箱内的传感器能识别可回收物的种类,当容量达
到上限时,系统通知清运人员及时处理。居民可通过手机APP查看本人投递记录。关于该系统功能与软件
设计的描述,正确的是( )
A. 系统数据处理都可由传感器完成 B. 在设计系统时需考虑数字鸿沟问题
C. 系统中的软件不包括手机APP D. 系统的软件升级是指增加新功能
【答案】B
【解析】
【详解】本题考查信息系统相关内容。A选项,传感器属于信息输入设备,负责信息系统从外部世界采集
信息,而系统数据处理要通过智能终端或服务器来完成,选项错误。B选项,“数字鸿沟”是指不同人群、
行业、区域等在信息基础设施的接入、数字技术的开发与应用、数字资源的获取使用等方面的不平等现象,
信息技术的发展会加剧数字鸿沟,在设计系统时,需要尽可能考虑数字鸿沟问题,以满足更多群体的使用,
选项正确。C选项,手机APP是安装在智能手机上的软件,旨在完善原始系统的不足与个性化,为用户提
供更丰富的使用体验,手机APP属于信息系统的软件,选项错误。D选项,软件升级是指对软件进行较大
规模的改进和更新,可能涉及重要的功能改动、界面优化或架构升级等,不一定增加新功能,选项错误。
故本题答案是B选项。
6. 某小区智能回收箱可通过刷卡、扫码等方式开启箱门,箱内的传感器能识别可回收物的种类,当容量达
到上限时,系统通知清运人员及时处理。居民可通过手机APP查看本人投递记录。下列技术中,不能用于
智能回收箱接入互联网的是( )
A. 5G B. Wi-Fi C. 光纤通信 D. RFID
【答案】D
【解析】
【详解】本题考查网络通信相关内容。A选项,5G是新一代移动通信技术,可以将智能回收箱接入互联网。
B选项,Wi-Fi是一种无线网络技术,它是一种短距离、高速的无线网络技术,它的作用是使用无线电波
的方式来提供网络连接,以及在不同的设备之间进行数据传输,Wi-Fi可以将将智能回收箱连接到互联网。
C选项,光纤通信是一种利用光纤作为传输媒介的高速数据传输技术,具有高带宽、长距离传输和抗干扰能力强等优点,为计算机网络、移动通信网络和广播电视网络提供了非常大的带宽和高质量的传输通道,
可以将智能回收箱接入互联网;D选项,RFID技术作为一种非接触识别的技术,无需与被识别物体直接接
触,即可完成物体信息的输入和处理,能快速、实时、准确地采集和处理物体的信息,RFID技术无互联
网连接功能,不能将智能回收箱接入互联网。故本题答案是D选项。
7. 某同学根据下图所示流程图编写的Python程序段如下:
n = int(input())
if n <= 20:
z = 0
if n <= 50:
z = 1
else:
z = 2
用下列输入数据测试程序段与流程图,两者得到的z值不同的是( )
A. 60 B. 50 C. 30 D. 10
【答案】D
【解析】
【详解】本题考查算法描述相关内容。分析流程图及程序段,推知:
程序段:程序段中有两个if语句:第一个if语句是判断n是否小于等于20,若成立z = 0;第二个if语句是
判断n是否小于等于50,若成立,执行z=1,否则执行z=2;(2)流程图:流程图表示的是if语句的嵌套,
当n大于20时,去判断嵌套if语句的情况。两者描述的算法不相同。
分析四个选项,ABC选项,输入的n的值均大于20,第一个if语句均不会执行,执行第二个if语句,则A
选项:n=60,z=2;B选项:n=50,z=1;C选项:n=30,z=1;这三个选项程序段与流程图得到的z值相同。
D选项,程序段:先执行n <= 20成立,z=0,再执行n <= 50成立,z = 1,z最终值为1,而在流程图中得
到的z值为0。故本题答案是D选项。
8. 某完全二叉树包含5个节点,其根节点在后序遍历序列、中序遍历序列中的位置序号分别记为x,y,则
x-y的值为( )A. 0 B. 1 C. 2 D. 3
【答案】B
【解析】
【详解】本题考查树的遍历相关内容。分析题目内容,推知:
该二叉树为完全二叉树且包含5个节点,其结构如图所示: ,由后序遍历规则知,其访问
过程为:3-4-1-2-0,则其根节点的位置x处于第5个,即x=5;由中序遍历的规则知,其访问过程为:3-
1-4-0-2,则其根节点的位置y处于第4个,即y=4;由此得出:x-y=1,故本题答案是B选项。
9. 栈初始为空,经过一系列入栈、出栈操作后,栈又为空。若元素入栈的顺序为“生”“旦”“净”
“末”“丑”,则所有可能的出栈序列中,以“旦”结尾的序列个数为( )
A. 3 B. 4 C. 5 D. 6
【答案】C
【解析】
【详解】本题考查栈操作相关内容。栈的特点是先进后出。入栈的顺序为“生”“旦”“净”“末”
“丑”,且要求以“旦”结尾。分析题目内容,推知:要以“旦”结尾,“生”一定是第一个出栈,剩余
3个元素的排列有6种方案:净、末、丑;末、丑、净;丑、末、净;末、净、丑;净、丑、末;丑、净、
末。但丑、净、末不可能是出栈序列(丑出栈,说明净和末都在栈内,且末在净上面,出栈时,末先于净
出栈),则所有可能的出栈序列为:(1)生、净、末、丑、旦;(2)生、末、丑、净、旦;(3)生、
丑、末、净、旦;(4)生、末、净、丑、旦;(5)生、净、丑、末、旦。即以“旦”结尾的序列个数为
5,故本题答案是C选项。
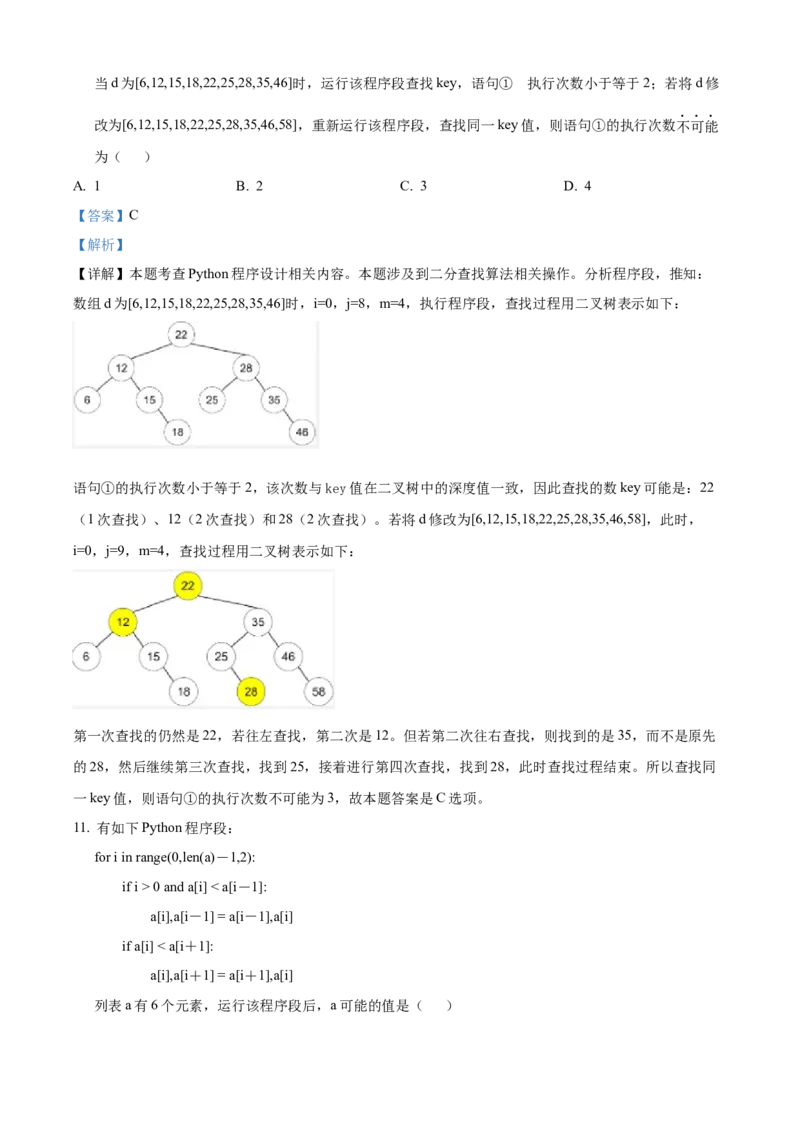
10. 某二分查找算法的Python程序段如下:
i,j = 0,len(d)-1
while i <= j:
m = (i+j)//2 # 语句①
if key == d[m]:
break
elif key < d[m]:
j = m-1
else:
i = m+1的
当d为[6,12,15,18,22,25,28,35,46]时,运行该程序段查找key,语句① 执行次数小于等于2;若将d修
改为[6,12,15,18,22,25,28,35,46,58],重新运行该程序段,查找同一key值,则语句①的执行次数不可能
为( )
A. 1 B. 2 C. 3 D. 4
【答案】C
【解析】
【详解】本题考查Python程序设计相关内容。本题涉及到二分查找算法相关操作。分析程序段,推知:
数组d为[6,12,15,18,22,25,28,35,46]时,i=0,j=8,m=4,执行程序段,查找过程用二叉树表示如下:
语句①的执行次数小于等于2,该次数与key值在二叉树中的深度值一致,因此查找的数key可能是:22
(1次查找)、12(2次查找)和28(2次查找)。若将d修改为[6,12,15,18,22,25,28,35,46,58],此时,
i=0,j=9,m=4,查找过程用二叉树表示如下:
第一次查找的仍然是22,若往左查找,第二次是12。但若第二次往右查找,则找到的是35,而不是原先
的28,然后继续第三次查找,找到25,接着进行第四次查找,找到28,此时查找过程结束。所以查找同
一key值,则语句①的执行次数不可能为3,故本题答案是C选项。
11. 有如下Python程序段:
for i in range(0,len(a)-1,2):
if i > 0 and a[i] < a[i-1]:
a[i],a[i-1] = a[i-1],a[i]
if a[i] < a[i+1]:
a[i],a[i+1] = a[i+1],a[i]
列表a有6个元素,运行该程序段后,a可能的值是( )A. [2,9,8,6,9,3] B. [9,9,8,6,3,2] C. [9,3,6,2,8,9] D. [6,3,9,2,9,8]
【答案】D
【解析】
【详解】本题考查Python程序设计相关内容。分析程序段,推知:列表a有6个元素,由“for i in range(0,
len(a)-1,2)”知,列表a的索引i为0、2、4,且当i的值为2、4时,若a[i] < a[i-1],则交换两个元素,若
a[i] < a[i+1],则交换两个元素,即:a[2]的值不能小于前面的a[1]和后面的a[3];a[4]的值不能小于前面的
a[3]和后面的a[5]。AB选项中,8比前面相邻的9小,选项结果不可能。C选项,8比后面相邻的9小,选
项结果不可能。D选项为可能结果,故本题答案是D选项。
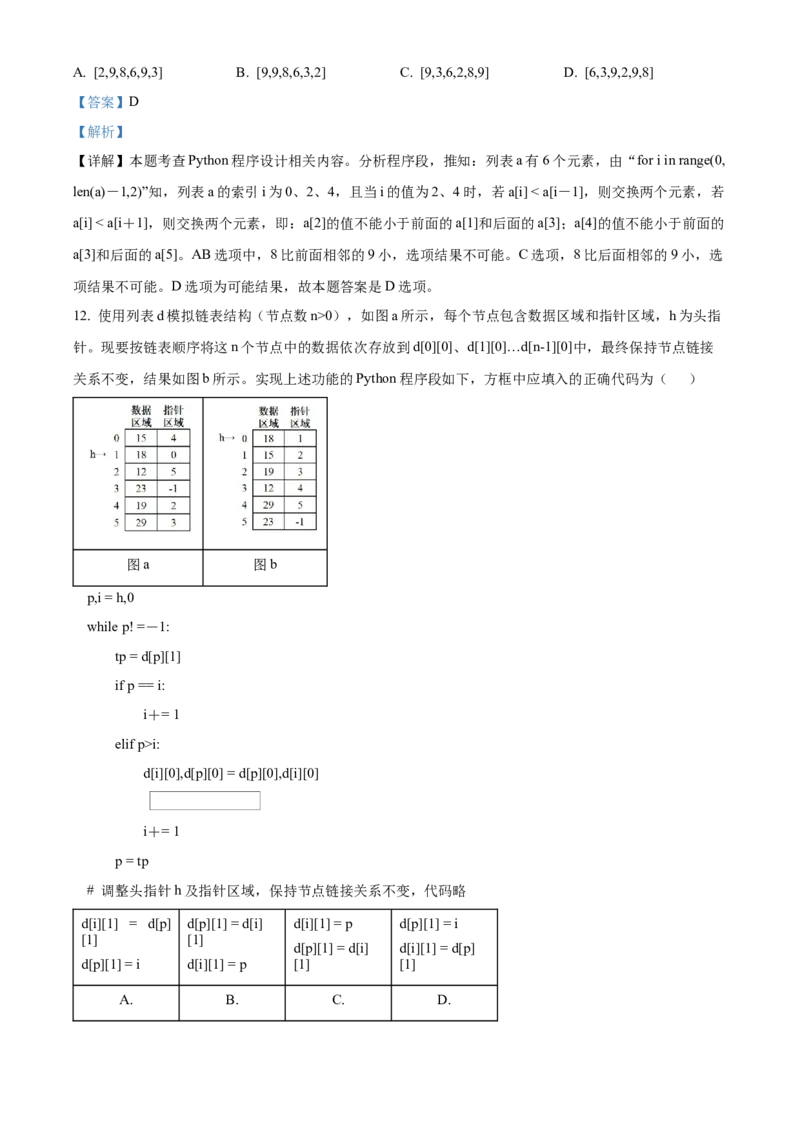
12. 使用列表d模拟链表结构(节点数n>0),如图a所示,每个节点包含数据区域和指针区域,h为头指
针。现要按链表顺序将这n个节点中的数据依次存放到d[0][0]、d[1][0]…d[n-1][0]中,最终保持节点链接
关系不变,结果如图b所示。实现上述功能的Python程序段如下,方框中应填入的正确代码为( )
图a 图b
p,i = h,0
while p! =-1:
tp = d[p][1]
if p == i:
i+= 1
elif p>i:
d[i][0],d[p][0] = d[p][0],d[i][0]
i+= 1
p = tp
# 调整头指针h及指针区域,保持节点链接关系不变,代码略
d[i][1] = d[p] d[p][1] = d[i] d[i][1] = p d[p][1] = i
[1] [1]
d[p][1] = d[i] d[i][1] = d[p]
d[p][1] = i d[i][1] = p [1] [1]
A. B. C. D.A. A B. B C. C D. D
【答案】B
【解析】
【详解】本题考查Python程序设计相关内容。本题涉及到数据结构链表操作知识。分析程序段,推知:
当前节点为p节点,p从头结点开始进行遍历。而变量i是从0开始递增的,当p和i相等时,表明链表是
按链表顺序依次存放到d[0][0]、d[1][0]…d[n-1][0]的,符合题意,此时只需依次进行简单的迭代即可。若p
和i不相等时,即数据的存放不符合题意,由于i是从0开始的,因此若p和i不等,则肯定是p>i,此时由
代码可知将节点i和节点p的数据域进行交换,由于在链表中p的位置比节点i更加靠前,即p→i。而数据
交换后两者的关系刚好逆转了,即i→p,因此可以先删除节点i,然后将节点i插入到p节点的前面,这样
即可实现题意,故先执行代码 d[p][1]=d[i][1],删除节点i,然后再将节点i指向节点p,故代码为d[i]
[1]=p。……,以此类推直到循环结束。至此链表已实现按照顺序将这n个节点中的数据依次存放到d[0]
[0]、d[1][0]…d[n-1][0]中的目的,但循环结束后,还需要修改头指针h的值,以及重新调整每个节点的指
针域数据(即代码略部分)。故本题答案是B选项。
二、非选择题(本大题共 3小题,其中第13小题7分,第14小题10分,第15小题9分,共
26分)
13. 某监控设备可定时采集红绿信号灯状态数据,数据格式记为[a,b],其中a、b分别为红灯和绿灯的状态
值,0表示灯灭,1表示灯亮,如[0,1]表示红灯灭、绿灯亮。
现要编写程序,每隔1秒采集并检测信号灯是否存在如下异常状态:第一类,红绿灯同亮或同灭;第二类,
红灯或绿灯超时,即保持同一状态时长大于上限值(如300秒)。检测到异常状态就发送相应信息。请回
答下列问题:
(1)若检测到“红绿灯同亮”异常,则采集到的数据是____(单选,填字母)。
A.[0,0] B.[0,1] C.[1,0] D.[1,1]
(2)实现上述功能的部分Python程序如下,请在划线处填入合适的代码。
tlimit = 300 # 设置信号灯保持同一状态时长上限值
pre = [-1,-1]
t = [0,0] # t[0]、t[1]分别记录红灯、绿灯保持同一状态的时长
while True:
# 接收一次采集到的状态数据,存入d,代码略
if①____:
if d[0] == 1:
# 发送“红绿灯同亮”信息,代码略else:
# 发送“红绿灯同灭”信息,代码略
for i in②_____:
if d[i] == pre[i]:
t[i]+= 1
if③_____:
if i == 0:
# 发送“红灯超时”信息,代码略
else:
# 发送“绿灯超时”信息,代码略
else:
t[i] = 1
pre = d
# 延时1秒,代码略
【答案】 ①. D ②. d[0] == d[1] ③. range(2) 或 range(len(pre)) 或 range(len(d)) ④.
t[i]>tlimit
【解析】
【详解】本题考查的是Python综合应用。
(1)依据题干数据说明可知,1表示灯亮,若检测到“红绿灯同亮”异常,则采集到的数据是:
[1,1]。选D。
(2)①处,由嵌套的分支可知,该分支处理的是:红绿灯同亮或同灭(即红绿灯状态相同),故此处应
为:d[0] == d[1] ;②处,从for循环中语句的调用来看,i是数组d和pre的下标索引,i取0到1,故此处
应为:range(2)或 range(len(d))或range(len(pre));③处,若d[i]==pre[i],表示i所对应的红绿灯相邻两个时
刻的状态相同,则相应的红绿灯时长t[i]计数;若时长超过上限值,则表示异常状态;若此时i==0表示红
灯异常;否则表示绿灯异常,故此处应为:t[i]>tlimit。
14. 某研究小组拟采集某水域水位及周边土壤含水量等数据,进行地质灾害监测。该小组在实验室搭建了
一个模拟系统,该系统的智能终端获取传感器数据,并通过无线通信方式将数据传输到Web服务器,服务
器根据数据判断出异常情况后,通过智能终端控制执行器发出预警信号。请回答下列问题。
(1)该模拟系统中的传感器和执行器____(单选,填字母:A.必须连接在不同智能终端 / B.可以连接在
同一智能终端)。
(2)水位传感器和土壤水分传感器连接在同一智能终端,服务器能正常获取土壤含水量数据,但不能正
常获取水位数据,以下故障与该现象无关的是____(单选,填字母)。A.水位传感器故障 B.水位传感器与智能终端连接故障 C.智能终端无法与服务器通信
(3)下列关于该系统设计的说法,正确的有____(多选,填字母)。
A.水位、土壤含水量等数据的采集时间间隔不能相同
B.水位、土壤含水量等数据可用数据库存储
.
C可以基于Flask Web 框架编写服务器程序
D.系统获取数据的程序可以只部署在服务器端
(4)现场实地测试时需要设置多个监测点,每个监测点配备一个智能终端。为使服务器能区分出数据的
监测点来源,从智能终端的角度写出一种可行的解决方法。____
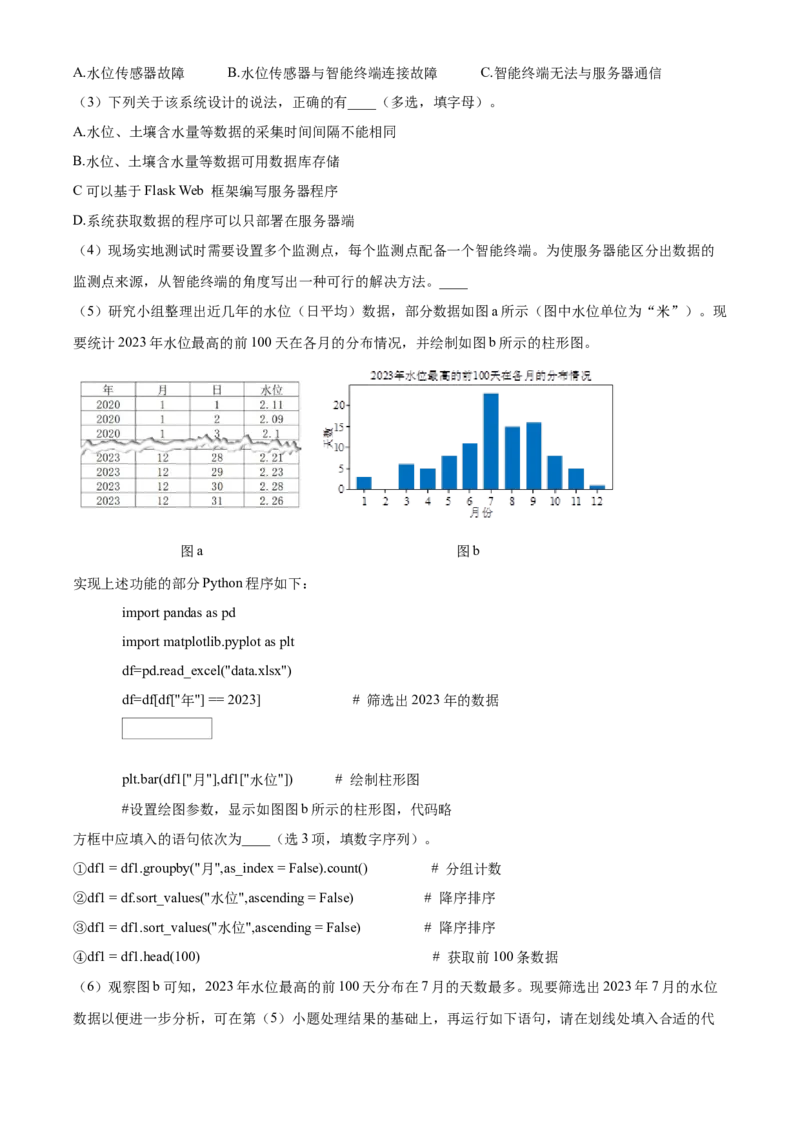
(5)研究小组整理出近几年的水位(日平均)数据,部分数据如图a所示(图中水位单位为“米”)。现
要统计2023年水位最高的前100天在各月的分布情况,并绘制如图b所示的柱形图。
图a 图b
实现上述功能的部分Python程序如下:
import pandas as pd
import matplotlib.pyplot as plt
df=pd.read_excel("data.xlsx")
df=df[df["年"] == 2023] # 筛选出2023年的数据
plt.bar(df1["月"],df1["水位"]) # 绘制柱形图
#设置绘图参数,显示如图图b所示的柱形图,代码略
方框中应填入的语句依次为____(选3项,填数字序列)。
①df1 = df1.groupby("月",as_index = False).count() # 分组计数
②df1 = df.sort_values("水位",ascending = False) # 降序排序
③df1 = df1.sort_values("水位",ascending = False) # 降序排序
④df1 = df1.head(100) # 获取前100条数据
(6)观察图b可知,2023年水位最高的前100天分布在7月的天数最多。现要筛选出2023年7月的水位
数据以便进一步分析,可在第(5)小题处理结果的基础上,再运行如下语句,请在划线处填入合适的代码。
df2 = df[____]
【答案】 ①. B ②. C ③. BC ④. 对每个智能终端进行信息编码,在上传数据过程中,将该
编码作为参数传送到服务器(或其它正确答案) ⑤. ②④① ⑥. df["月"]==7
【解析】
【详解】本题考查信息系统相关内容。分析题目内容,推知:
(1)传感器是能感受到被测量的信息,并能将感受到的信息,按一定规律变换成为电信号或其他所需形
式的信息输出,以满足信息的传输、处理、存储、显示、记录和控制等要求的检测装置。执行器是指一种
能够将电子信号或控制命令转化为机械运动或物理效应的设备。智能终端通过传感器获取水域水位及周边
土壤含水量等数据,然后将这些数据传输到服务器;服务器下达指令给智能终端,去控制执行器发出预警
信号;一个智能终端可以通过不同的引脚连接不同的传感器和执行器。故本题答案是:B。
(2)由题目描述可知,服务器能正常获取土壤含水量数据,说明从智能终端到服务器的传输没有问题,
但服务器不能正常获取水位数据,说明水位传感器出现了故障或者是水位传感器和智能终端之间的连接出
现了故障。故本题答案是:C。
(3)A选项,获取数据的时间间隔可以通过代码分别设定,可以相同,也可以不相同,选项错误。B选项,
信息系统中的数据存放在数据库中,选项正确。C选项,Flask是一个轻量级的Python Web框架,它可以让
你快速地构建Web应用程序,选项正确。D选项,系统获取数据的程序一般部署在客户端或者智能终端,
数据采集完成后,由智能终端将数据传输至服务器端,选项错误。故本题答案是:BC。
的
(4)为使服务器能区分出数据 监测点来源,可以给每个智能终端进行信息编码。赋予不同的标识,并
将该编码通过路由传送到服务器,以区分数据来源。故本题答案是:对每个智能终端进行信息编码,在上
传数据过程中,将该编码作为参数传送到服务器(或其它正确答案)。
(5)若要统计2023年水位最高的前100天在各月的分布情况,其操作步骤为:对2023年的水位数据按照
水位值进行降序排序-->选取前100条记录-->对前100条记录根据月份分组统计计数-->分析水位最高的前
100天在各月的分布情况。故本题答案是:②④①。
(6)结合题干描述,上文“df=df[df["年"] == 2023]”已筛选出2023年的相关记录,此处需要在此基础上筛
选出7月份的数据,故本题答案是:df["月"]==7。
15. 某数据序列data中的元素均为小于127的正整数。现在要对data进行加密,处理过程分“变换”和
“重排”两步。“变换”处理方法是用指定的n组序列 、 … 依次对data进行变换。利用R对
i
data进行变换的过程是:在data中查找所有与R相同的子序列,将找到的每个子序列中的元素值加上R的
i i
长度值L,并在各子序列前插入一个标记元素(值为127+L),这些子序列及标记元素不再参与后续的变
i i换。
如data为[3,5,1,6,3,8,7,5,1,8,7],指定的两组序列为[5,1]、[3,8,7],“变换”处理后的data为
[3,129,7,3,6,130,6,11,10,129,7,3,8,7]。对data“重排”处理通过给定的shuff函数实现。
请回答下列问题:
(1)若data为[3,5,1,6,3,8,7,5,1,8,7],指定的两组序列为[5,1]、[8,7],经过“变换”处理后,data中插入的
标记元素个数为______。
(2)“重排”处理的shuff函数如下:
def shuff(data, c): # 根据列表c对列表data进行重排
的
# 若列表data 长度不是列表c长度的整数倍,则用0补足,代码略
m = len(c)
s = [0] * m
k = 0
while k < len(data):
for i in range(m):
s[i] = data[k + i]
for i in range(m):
data[k + i] = s[c[i]]
k += m
若data为[3,129,7,3,130,6,11,10],c为[1,3,0,2],调用shuff(data, c)后,data的最后一个元素值为______。
(3)实现加密功能的部分Python程序如下,请在划线处填入合适的代码。
def compare(data, i, r):
# 函数功能:返回data从索引i位置、r从索引0位置开始的连续相等元素的个数
# 例如r为[7, 3, 6],data从索引i位置开始的元素依次为7, 6, 7, 3, …,函数返回1
j = 0
while j < len(r) and i + j < len(data):
if①______:
break
else:
j += 1
return j
def trans(data, r, segs):
newsegs = []for s in segs:
if s[0] == 0:
h = i = s[1]
m = len(r)
while i + m <= s[2] + 1:
,
if compare(data i, r) == m:
if i > h:
newsegs.append([0, h, i-l]) # 为newsegs追加一个元素
newsegs.append([m, i, i + m-1])
i += m
②_____
else:
i += 1
if h <= s[2]:
newsegs.append([0, h, s[2]])
else:
newsegs.append(s)
return newsegs
def update(data, segs):
for s in segs:
if s[0] != 0:
data.append(0)
p = len(data)-1
for i in range(len(segs)-1, -1,-1):
for j in range(segs[i][2], segs[i][1]-1,-1):
③____
p-= 1
if segs[i][0] > 0:
data[p] = 127 + segs[i][0]
p-= 1
# 读取待加密数据存入data,读取指定的若干组用于变换的序列存入rs,代码略
'''列表segs用于记录data的变换信息,segs[i]包含三个元素,segs[i][0]、segs[i][1]、segs[i][2]分别表
示data中一个子序列的状态、起始位置和结束位置,如果segs[i][0]为0,则表示该子序列未经过变
换。
'''
segs = [[0,0,len(data)-1]]
for r in rs:
segs = trans(data,r,segs) # 根据r更新segs
update(data, segs) # 利用segs完成对data的变换操作
c = [1,3,0,2]
shuff(data, c)
# 输出加密后的data序列,代码略
【答案】 ①. 4 ②. 11 ③. r[j]!=data[i+j] ④. h=i ⑤. data[p]=data[j]+segs[i][0]
【解析】
【详解】本题考查Python程序设计相关内容。本题涉及到索引数组和双指针知识。结合题目内容,分析程
序段,推知:
(1)考查基本的数据模拟能力,变换数组r = [[5, 1], [8, 7]],在序列data中,分别以索引号1、5、7、9为
起始的包含两个元素的子序列与r序列中的子序列相等,则有4个子串进行变换。题目要求在各子序列前
插入一个标记元素,则共插入4个标记元素,故本题答案为:4。
(2)考查索引数组。由题目描述知,索引数组的长度可能小于原数组,当原数组索引超过索引数组的索
引范围时,需要对原数组进行分组,应以索引数组的长度m作为每一组的元素个数,若不足,则用0补齐。
data长度为c的整数倍,则调用shuff函数后,data的最后一个元素是分组后最后一组重排结果的最后一项,
c[3] = 2,最后一组的元素值为[130, 6, 11, 10],所以索引2处的值为11。故本题答案为:11。
(3)考察用变换实现加密功能。compare函数返回data从索引i位置、r从索引0位置开始的连续相等元
素的个数,trans函数处理序列变换,update函数用于完成子串的变换和标记元素的插入。③处,compare
函数中,j是r的索引,i是data的索引,该函数用于检查data中是否存在从索引i开始的连续j项均与r相
同,返回相同项的数量。若data[i + j] != r[j]成立,表明查询结束,应结束循环,故③处答案为:r[j]!
=data[i+j]。④处,trans函数的3个参数:data表示原始数据,r是当前变换数组,segs记录了当前data的
变换信息。对于其中一条变换信息s,s[0] == 0表明该信息所描述的子串没有经过标记,可以进行变换。
若compare(data, i, r) == m成立,表明找到了需要进行变换的子串data[i: i + m],此时,若i > h成立,则需
要新增data[h: i]的未标记子序列和data[i: i + m]的标记子序列(标记值恰为m),与此同时,该子序列中
data[h: i + m]均为已处理状态,在i += m后更新h = i的作用是更新该子序列的头部标记,故④处答案为:
h=i。⑤处,update函数根据变换信息处理data数据中的具体更新,函数中需要实现元素插入的功能,因此需要逆序遍历data,trans函数采用队列保证变换信息的有序性,逆序遍历变换信息的同时可以逆序遍历
data,以免因数据的插入而影响原始数据。索引p用于逆向遍历插入后data,索引j从变换信息的“结束索
引”逆向遍历到“开始索引”,由于变换信息中存储的是data的原始数据信息,因此data[p] = data[j] +
segs[i][0]即为对data[j]的变换值的更新并移动到最终的位置上,故⑤处答案为:data[p]=data[j]+segs[i][0]。

