
文档内容
必刷大题 18 统计与统计案例
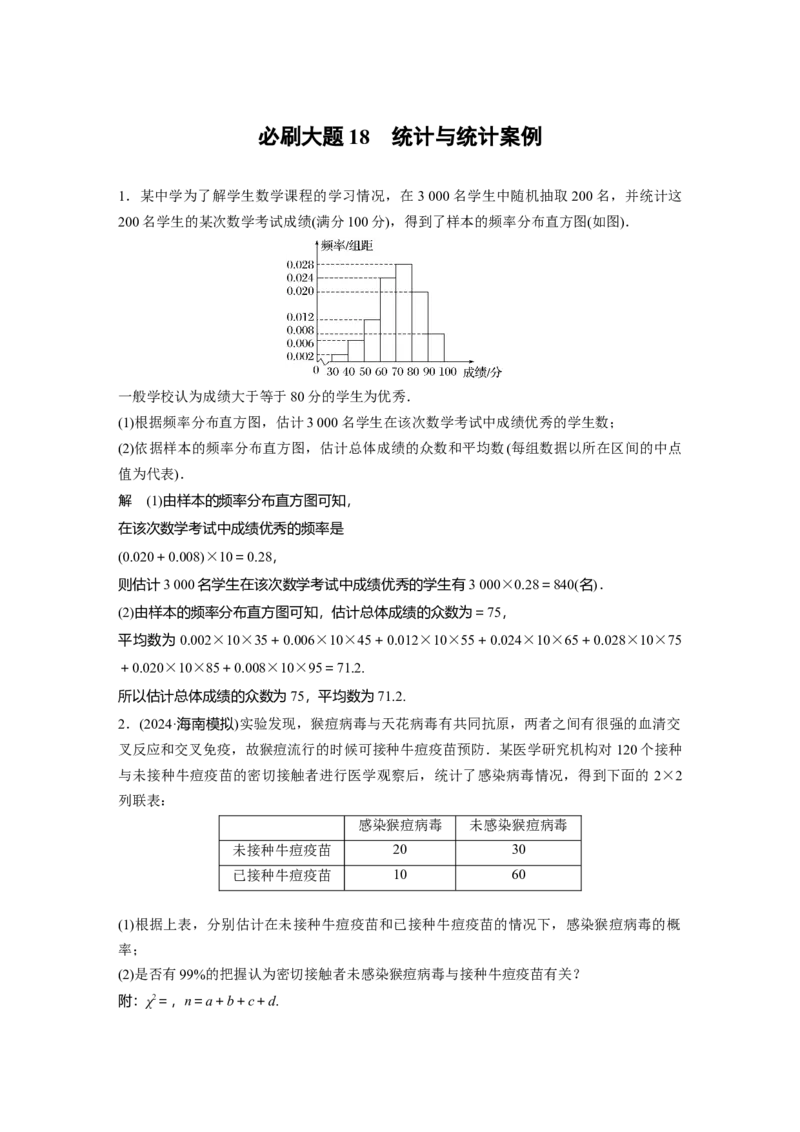
1.某中学为了解学生数学课程的学习情况,在3 000名学生中随机抽取200名,并统计这
200名学生的某次数学考试成绩(满分100分),得到了样本的频率分布直方图(如图).
一般学校认为成绩大于等于80分的学生为优秀.
(1)根据频率分布直方图,估计3 000名学生在该次数学考试中成绩优秀的学生数;
(2)依据样本的频率分布直方图,估计总体成绩的众数和平均数(每组数据以所在区间的中点
值为代表).
解 (1)由样本的频率分布直方图可知,
在该次数学考试中成绩优秀的频率是
(0.020+0.008)×10=0.28,
则估计3 000名学生在该次数学考试中成绩优秀的学生有3 000×0.28=840(名).
(2)由样本的频率分布直方图可知,估计总体成绩的众数为=75,
平均数为0.002×10×35+0.006×10×45+0.012×10×55+0.024×10×65+0.028×10×75
+0.020×10×85+0.008×10×95=71.2.
所以估计总体成绩的众数为75,平均数为71.2.
2.(2024·海南模拟)实验发现,猴痘病毒与天花病毒有共同抗原,两者之间有很强的血清交
叉反应和交叉免疫,故猴痘流行的时候可接种牛痘疫苗预防.某医学研究机构对 120个接种
与未接种牛痘疫苗的密切接触者进行医学观察后,统计了感染病毒情况,得到下面的 2×2
列联表:
感染猴痘病毒 未感染猴痘病毒
未接种牛痘疫苗 20 30
已接种牛痘疫苗 10 60
(1)根据上表,分别估计在未接种牛痘疫苗和已接种牛痘疫苗的情况下,感染猴痘病毒的概
率;
(2)是否有99%的把握认为密切接触者未感染猴痘病毒与接种牛痘疫苗有关?
附:χ2=,n=a+b+c+d.解 (1)由题意可知,估计未接种牛痘疫苗者感染猴痘病毒的概率为P==,
1
已接种牛痘疫苗者感染猴痘病毒的概率为
P==.
2
(2)列联表如表所示:
感染猴痘病毒 未感染猴痘病毒 总计
未接种牛痘疫苗 20 30 50
已接种牛痘疫苗 10 60 70
总计 30 90 120
则χ2=≈10.286>6.635,
所以有99%的把握认为密切接触者未感染猴痘病毒与接种牛痘疫苗有关.
3.(2022·全国乙卷)某地经过多年的环境治理,已将荒山改造成了绿水青山.为估计一林区
某种树木的总材积量,随机选取了 10棵这种树木,测量每棵树的根部横截面积(单位:m2)
和材积量(单位:m3),得到如下数据:
样本号i 1 2 3 4 5 6 7 8 9 10 总和
根部横
0.04 0.06 0.04 0.08 0.08 0.05 0.05 0.07 0.07 0.06 0.6
截面积x
i
材积量y 0.25 0.40 0.22 0.54 0.51 0.34 0.36 0.46 0.42 0.40 3.9
i
并计算得∑x=0.038,∑y=1.615 8,∑xy=0.247 4.
i i
(1)估计该林区这种树木平均一棵的根部横截面积与平均一棵的材积量;
(2)求该林区这种树木的根部横截面积与材积量的样本相关系数(精确到0.01);
(3)现测量了该林区所有这种树木的根部横截面积,并得到所有这种树木的根部横截面积总
和为186 m2.已知树木的材积量与其根部横截面积近似成正比.利用以上数据给出该林区这
种树木的总材积量的估计值.
附:样本相关系数r==,≈1.377.
解 (1)样本中10棵这种树木的根部横截面积的平均值==0.06(m2),
样本中10棵这种树木的材积量的平均值
==0.39(m3),
据此可估计该林区这种树木平均一棵的根部横截面积为 0.06 m2,平均一棵的材积量为0.39
m3.
(2)r=
=
=≈≈0.97.
(3)设该林区这种树木的总材积量的估计值为Y m3,又已知树木的材积量与其根部横截面积近似成正比,
可得=,
解得Y=1 209.
则该林区这种树木的总材积量的估计值为1 209 m3.
4.(2024·沧州模拟)“绿水青山就是金山银山”的口号已经深入民心,人们对环境的保护意
识日益增强,质检部门也会不时地对一些企业的生产污染情况进行排查,并作出相应的处理,
本次排查了30个企业,共查出510个污染点,其中造成污染点前10名的企业分别造成的污
染点数为58,36,36,35,33,32,28,26,24,22.
(1)求这30个企业造成污染点的80%分位数;
(2)已知造成污染点前10名的企业的方差为92.4,其他20个企业造成污染点的方差为44.7,
求这30个企业造成污染点的总体方差.
解 (1)根据定义可得,此30个数据从小到大排列,且30×80%=24,
所以这30个企业造成污染的80%分位数是第24个数据与第25个数据的平均数,即前10名
中第六名与第七名数据的平均数,即=30.
(2)按照企业造成的污染点数从小到大排列,记为x,x,…,x ,其平均数记为,方差记为
1 2 20
s;
把剩下10个数据记为y,y,…,y ,其平均数记为,方差记为s;
1 2 10
把总样本数据的平均数记为,方差记为s2.
由题意可知,==17,
=×(58+36+36+35+33+32+28+26+24+22)=×330=33,
则=×(510-330)=9,
由题知s=44.7,s=92.4,
s2=×{20[s+(-)2]+10[s+(-)2]}
代入数据可得s2=×{20×[44.7+(9-17)2]+10×[92.4+(33-17)2]}=188.6,
所以这30个企业造成污染点的总体方差为188.6.
5.某网红奶茶品牌公司计划在W市某区开设加盟分店,为了确定在该区开设分店的个数,
该公司对该市已开设分店的5个区域的数据作了初步处理后得到下列表格,记X表示在5个
区域开设分店的个数,Y表示这X个分店的年收入之和.
X(个) 2 3 4 5 6
Y(十万元) 2.5 3 4 4.5 6
(1)该公司经过初步判断,可用线性回归模型拟合Y与X的关系,求Y关于X的线性回归方
程;
(2)如果该公司最终决定在该区选择两个合适的地段各开设一个分店,根据市场调查得到如
下统计数据,第一分店每天的顾客平均为 30人,其中5人会购买该品牌奶茶,第二分店每天的顾客平均为80人,其中20人会购买该品牌奶茶.是否有90%的把握认为两个店的顾客
下单率有差异?
参考公式:b=,a=-b;χ2=.
解 (1)由题意可得,==4,
==4,
y=2×2.5+3×3+4×4+5×4.5+6×6=88.5,
i i
=22+32+42+52+62=90,
设Y关于X的线性回归方程为Y=bX+a,
则b===0.85,
a=-b=4-0.85×4=0.6,
∴Y关于X的线性回归方程为Y=0.85X+0.6.
(2)由题意可知2×2列联表如表所示:
不下单 下单 总计
分店一 25 5 30
分店二 60 20 80
总计 85 25 110
∴χ2==≈0.863<2.706,
∴没有90%的把握认为两个店的顾客下单率有差异.
6.(2023·福州模拟)国内某大学想了解本校学生的运动状况,采用简单随机抽样的方法从全
校学生中抽取2 000人,调查他们平均每天运动的时间(单位:小时),统计表明该校学生平
均每天运动的时间范围是[0,3],记平均每天运动的时间不少于2小时的学生为“运动达人”,
少于2小时的学生为“非运动达人”.整理分析数据得到的列联表如表所示(单位:人):
运动时间
性别
“运动达人” “非运动达人” 总计
男生 1 100 300 1 400
女生 400 200 600
总计 1 500 500 2 000
根据列联表中的数据,算得χ2≈31.746,所以有99%的把握认为运动时间与性别有关.
(1)如果将表中所有数据都缩小为原来的,在相同的检验标准下,再用独立性检验推断运动
时间与性别之间的关联性,结论还一样吗?请用统计语言解释其中的原因;
(2)采用分层随机抽样的方法抽取20名同学,并统计每位同学的运动时间,统计数据为男生
运动时间的平均数为2.5,方差为1;女生运动时间的平均数为1.5,方差为0.5,求这20名
同学运动时间的均值与方差.附:χ2=,其中n=a+b+c+d.
解 (1)方法一 改变数据之后的列联表为
运动时间
性别
“运动达人” “非运动达人” 总计
男生 110 30 140
女生 40 20 60
总计 150 50 200
则调整后的χ2==≈3.175<6.635.
则没有99%的把握认为运动时间与性别有关.
与之前结论不一样,
原因是每个数据都缩小为原来的,相当于样本容量缩小为原来的,导致推断结论发生了变化,
当样本容量越大,用样本估计总体的准确性会越高.
方法二 调整后的χ2=
==≈3.175<6.635,
则没有99%的把握认为运动时间与性别有关.
与之前结论不一样,原因是每个数据都缩小为原来的,相当于样本容量缩小为原来的,导致
推断结论发生了变化,
当样本容量越大,用样本估计总体的准确性会越高.
(2)男生抽取×20=14(人),女生抽取×20=6(人),
由已知男生运动时间的平均数为=2.5,样本方差为s=1;女生运动时间的平均数为=1.5,
样本方差为s=0.5.
记样本均值为,则==2.2,
记样本方差为s2,则s2==1.06,
所以这20名同学运动时间的均值为2.2,方差为1.06.

