 夜雨聆风
夜雨聆风





Claude Code 源码揭秘:一个 while 循环如何干翻所有 Agent 框架
↑阅读之前记得关注+星标⭐️,😄,每天才能第一时间接收到更新
现在造 Agent 的框架一大堆,LangChain、AutoGPT、MetaGPT… 各种花里胡哨的 DAG 编排、状态机、工作流引擎。看架构图一个比一个复杂,但真正跑得好的产品没几个。

前段时间有人把 Claude Code 的代码给逆向出来了,我花了几天时间翻了翻,发现一个让我意外的事实:
Claude Code 的核心架构,就是一个 while 循环。
没有复杂的 DAG,没有花哨的状态机,没有什么编排引擎。src/core/loop.ts 大概 900 行代码撑起整个系统。
我第一反应是不信。这玩意儿能干那么多事,就靠一个循环?
直接上源码:
while (turns < maxTurns) { turns++; // 清理旧的大输出,防止上下文爆炸 const cleanedMessages = cleanOldPersistedOutputs(messages, 3); // 调 API response = await this.client.createMessage(cleanedMessages, this.tools, systemPrompt); // 遍历响应内容 for (const block of response.content) { if (block.type === 'text') { finalResponse += block.text || ''; } else if (block.type === 'tool_use') { const result = await toolRegistry.execute(block.name, block.input); toolResults.push({ type: 'tool_result', tool_use_id: block.id, content: result }); } } // 把工具结果塞回消息列表 if (toolResults.length > 0) { this.session.addMessage({ role: 'user', content: toolResults }); } // 模型说结束了,就退出 if (response.stopReason === 'end_turn' && toolResults.length === 0) { break; }}就这么点东西。让我用一个具体的例子来说明这个循环是怎么工作的。
假设你输入:”帮我看看 package.json 里的项目名称是什么”

两轮循环,搞定。如果任务更复杂,比如”找到所有 TODO 注释并生成报告”,可能要跑十几轮,但逻辑是一样的:调 API → 执行工具 → 把结果喂回去 → 再调 API。
我之前带团队做过一个工作流引擎,当时画的架构图比这个复杂十倍。状态机、事件总线、任务队列、回滚机制… 搞了三个月,最后发现大部分场景用一个简单的循环就够了。那些复杂设计,要么是为了应对极端情况,要么纯粹是过度设计。
Claude Code 这个设计让我反思了很多。
当然,简单不代表简陋。这个循环里藏着不少精心设计的细节。
模型没有记忆——这事儿有点反直觉
第一个让我意外的点:Claude 模型是无状态的。
什么意思?每次调 API,模型都是”失忆”的状态。它不记得五秒钟前读了你的 package.json,也不记得刚才报了什么错。每一轮循环调用 API,CLI 都要把完整的对话历史从头发一遍。
第1轮: [用户问题]第2轮: [用户问题, 模型回复, 工具结果]第3轮: [用户问题, 模型回复, 工具结果, 模型回复, 工具结果]...消息数组随着交互越滚越大。一个简单的问题”package.json 里版本号是多少”,就会产生四条消息:用户问题、模型请求读文件、工具返回文件内容、模型最终回答。复杂任务跑几十上百条消息很正常。
你可能觉得这设计挺浪费的,每次都要发完整历史。但仔细想想,这设计其实挺聪明。
CLI 成了唯一的”真相源”。它掌控对话状态,决定给模型看什么上下文。出问题了?可以操作历史记录、用不同上下文重试、截断旧消息腾空间。模型的无状态反而让整个系统变得可预测、好调试。
我之前做过一个工单系统,状态散落在各个服务里,出了 bug 排查起来要命。后来重构成单一状态源,维护成本直接降了一半。道理是相通的。
看到这你可能会问:每次都发完整的对话历史,这不是很浪费吗?几十轮对话下来,每次都要重新处理几万个 token,成本和延迟不都爆炸了?
这就是 Claude Code 的另一个精妙设计:Prompt Caching(提示缓存)。
先看调用链路:
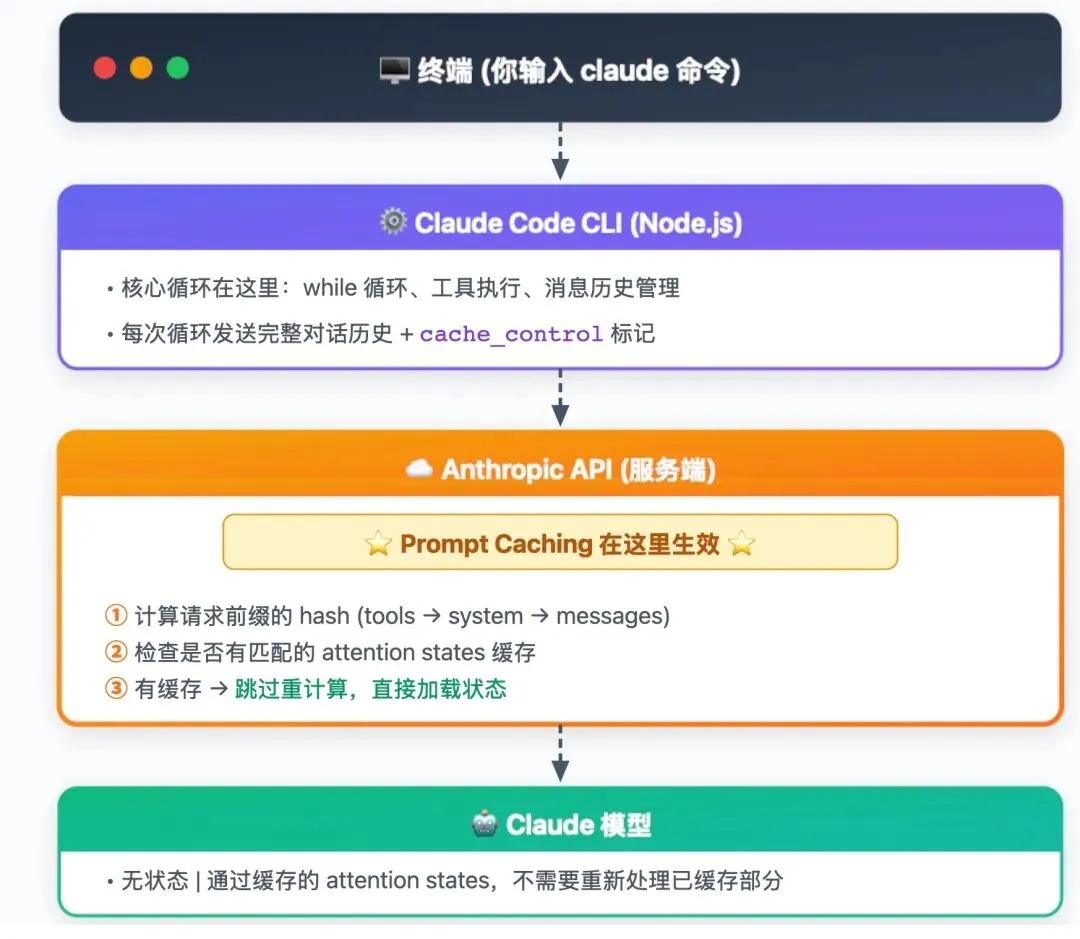
关键点:缓存不是发生在 CLI 本地,而是在 Anthropic API 服务端。
模型处理 prompt 的时候,会构建一个叫 “attention states” 的内部状态映射——可以理解成”理解了这段话”的中间产物。Prompt Caching 的本质就是把这个中间产物缓存起来,下次遇到相同前缀的请求,直接加载状态,跳过重新计算。
Claude Code 在发送请求时会自动插入缓存标记:
// Claude Code 发送的请求结构示意{ "model": "claude-sonnet-4-5", "system": [ { "type": "text", "text": "You are a coding assistant...", "cache_control": {"type": "ephemeral"} // ← 标记缓存点 } ], "tools": [...], // 工具定义 "messages": [ // 历史对话... { "role": "user", "content": [...], "cache_control": {"type": "ephemeral"} // ← 对话末尾标记 } ]}缓存是增量生效的。随着对话进行,前面的内容会被越来越多地缓存住:
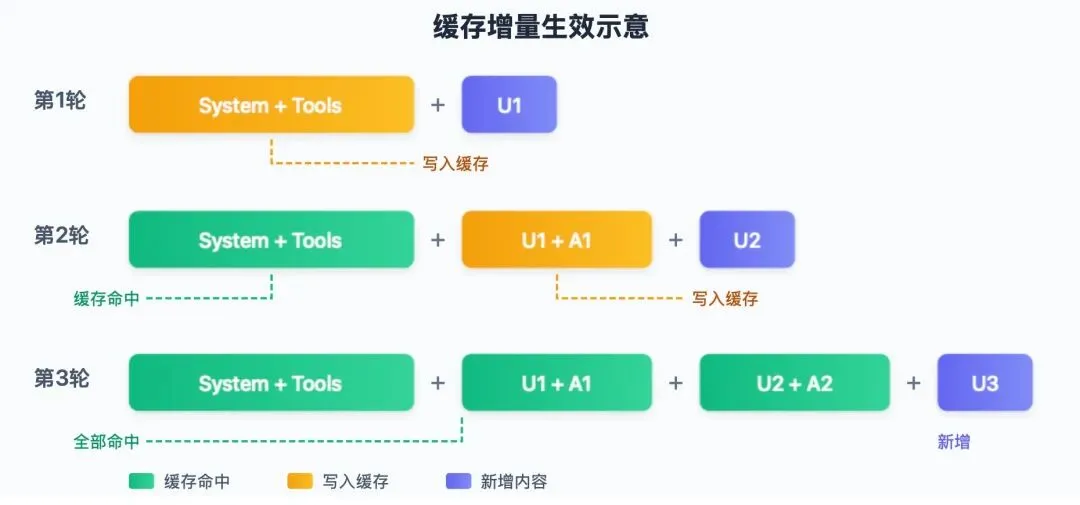
第10轮时,可能 90% 的内容都是缓存命中,只有最新的一点点需要计算。
你可以用 /cost 命令验证缓存效果:
/cost⎿ Total cost: $0.0827⎿ cache_creation_input_tokens: 5000 ← 首次写入缓存⎿ cache_read_input_tokens: 45000 ← 从缓存读取(便宜 90%)⎿ input_tokens: 500 ← 新增的、未缓存部分几个关键数字:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
所以答案是:每次确实发完整历史,但不心疼。因为大部分内容都是缓存命中,只付 10% 的钱。对话越长,缓存命中率越高,反而越划算。
什么会破坏缓存?修改 system prompt、改工具定义、改历史消息内容——任何一个变化,后续的缓存全部失效。这也解释了为什么 Claude Code 的 system prompt 和工具定义都是固定的,只在消息列表末尾追加新内容。
有个细节值得注意:在 AWS Bedrock 上使用 Claude 4 系列时,prompt caching 的支持还不完善(GitHub Issue #1347)。如果你发现成本异常高,可能就是缓存没生效。用 Anthropic 官方 API 就没这个问题。
这个设计让我想起数据库的查询缓存。道理类似:首次查询贵一点,但后续相同查询直接返回缓存结果。只不过 LLM 的”查询”是整个 prompt,缓存的是理解 prompt 的中间状态。
流式响应——不只是为了好看
Claude Code 的响应不是一坨 JSON 砸过来,而是通过 SSE(Server-Sent Events)一点点流过来,像看别人打字一样。
事件序列是固定的:
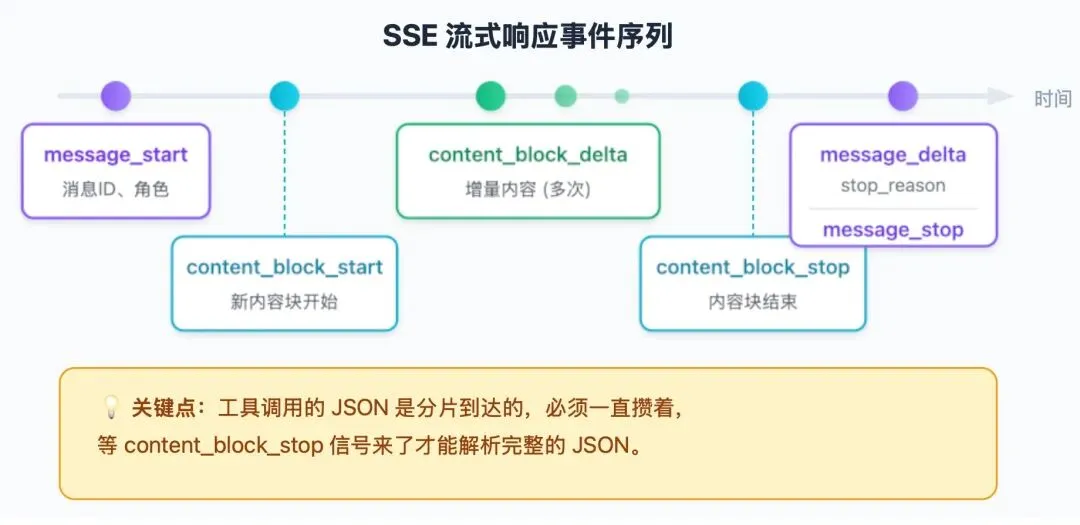
文本内容通过 text_delta 事件到达,CLI 收到一片就渲染一片。但工具调用就复杂了——输入的 JSON 是分片到达的,必须一直攒着,等 content_block_stop 信号来了才能解析完整的 JSON,才知道模型到底想调什么工具。
let toolInput = "";for await (const event of stream) { if (event.type === "content_block_delta") { if (event.delta.type === "input_json_delta") { toolInput += event.delta.partial_json; } } if (event.type === "content_block_stop") { const parsed = JSON.parse(toolInput); // 现在才知道模型想干啥 }}流式设计还有个关键好处:支持取消。用户按 Escape,CLI 可以中途打断请求。不用流式的话,你得等完整响应回来才能说”我不要了”。
我们之前做实时数据大屏的时候也用了类似的设计。数据量大的查询,边算边推,用户能看到进度,也能随时打断。体验比干等十几秒好太多。
stop_reason——模型的”举手信号”
每个响应都带一个 stop_reason,决定接下来干啥。可以理解成模型举手打的不同手势。
end_turn:模型说”我说完了,轮到你了”。循环退出,等用户下一条输入。
tool_use:模型说”我需要先干点事”。响应里带着 tool_use 块,指明要调什么工具、传什么参数。CLI 执行工具、收集结果、打包成新消息,然后继续循环。
{ "type": "tool_use", "id": "toolu_01ABC", "name": "Read", "input": { "file_path": "/project/src/main.ts" }}max_tokens:模型话说到一半,撞上了 20000 token 的输出上限。循环自动继续,让模型接着说。不用加工具结果,模型自己知道要续上。
这个设计把决策权完全交给模型。CLI 不需要判断”用户想干嘛”、”下一步该做什么”,模型说啥就干啥。简单直接。
大输出管理——偷偷帮你省空间
你用 Claude Code 跑过大文件吗?比如让它 grep 出几千行匹配结果。按理说,这些大输出会直接塞进上下文窗口,几轮下来窗口就撑爆了。但实际用起来,跑几十轮都没问题。
秘密在这里:
const OUTPUT_THRESHOLD = 400000; // 400KBconst PREVIEW_SIZE = 2000; // 2KBfunction wrapPersistedOutput(content: string): string { if (content.length <= OUTPUT_THRESHOLD) { return content; } // 超过 400KB,只保留 2KB 预览 const { preview } = truncateOutput(content, PREVIEW_SIZE); return `<persisted-output>\nPreview:\n${preview}\n...</persisted-output>`;}工具输出超过 400KB?只留 2KB 预览。但光这样还不够,随着对话进行,即使每个输出都压缩到 2KB,累积起来也会很大。所以每次调 API 之前,还要清理旧的大输出,只保留最近 3 个。
这就是为什么 Claude Code 能一直跑下去而不会上下文溢出。不是窗口真的无限大,而是它在”偷偷”帮你管理。
我之前做日志审计系统的时候也遇到过类似的问题。日志量太大,查询的时候内存直接爆掉。后来也是用了类似的策略——只加载摘要,需要详情的时候再去取原文。这种”懒加载 + 摘要”的思路,在处理大数据量的时候特别有用。
并行执行——读操作可以一起跑
模型可以一次请求多个工具。比如同时读五个文件,如果串行执行就太慢了。
Claude Code 按安全等级分类工具:只读操作(Read、Glob、Grep)可以并行跑,写操作(Edit、Write、Bash)必须串行,防止竞态条件。
const readOnlyTools = toolUseBlocks.filter(t => ['Read', 'Glob', 'Grep', 'LS'].includes(t.name));const writingTools = toolUseBlocks.filter(t => ['Edit', 'Write', 'Bash'].includes(t.name));// 只读操作可以并行const readResults = await Promise.all( readOnlyTools.map(tool => executeSingleTool(tool)));// 写操作必须串行for (const tool of writingTools) { await executeSingleTool(tool);}所有结果不管执行顺序,最后打包成一条用户消息,包含多个 tool_result 块。模型看到的是合并后的结果,可以综合分析。
这个设计在我们做批量数据处理的时候也用过。能并行的操作尽量并行,有依赖的必须串行。简单的原则,但效果明显。
安全机制和错误处理——生产环境的必修课
循环里有几道保险:
迭代次数上限:默认最多 100 轮。防止模型陷入死循环,反复尝试同一个失败的方法。
const MAX_ITERATIONS = 100;let iterations = 0;while (iterations < MAX_ITERATIONS) { iterations++; const response = await callAPI(); if (response.stop_reason === "end_turn") break; // ... 工具执行}用户中断:按 Escape 触发 AbortController,取消当前 API 调用。流立刻停止,循环优雅退出,不用等模型说完。
上下文窗口管理:每次调 API 前检查消息数组是不是快撑爆了(通常是 200K token 窗口的 85%)。快满了就自动压缩,把老消息总结一下腾出空间,但保留关键上下文。
API 调用会失败,这是事实。Claude Code 对常见错误有专门处理:
429 限流:API 返回 retry-after 头,告诉你等多久。循环就睡那么久,然后重试。
529 服务过载:指数退避,每次等更久。
const RETRYABLE_ERRORS = ['overloaded_error', 'rate_limit_error', 'api_error', 'timeout'];private async withRetry<T>(operation: () => Promise<T>, retryCount = 0): Promise<T> { try { return await operation(); } catch (error) { if (isRetryable && retryCount < this.maxRetries) { const delay = this.retryDelay * Math.pow(2, retryCount); // 指数退避 await this.sleep(delay); return this.withRetry(operation, retryCount + 1); } throw error; }}指数退避,最多重试 4 次。如果主模型一直挂,还能自动切换到备用模型——Opus 挂了切 Sonnet,Sonnet 挂了至少给用户一个友好的错误信息。
工具执行失败:这个处理方式不太一样。失败了也要把结果发给模型,但标记 is_error: true。模型看到错误,可以换个方法再试。文件读取失败?模型可能会先检查文件是否存在。编辑失败?模型可能会重新读文件再试。
这种”告诉模型失败了让它自己想办法”的设计,比硬编码一堆异常处理逻辑灵活多了。
我们之前做支付系统的时候,也是类似的策略。主通道挂了切备用通道,备用通道也挂了走人工审核。这种多层兜底的设计,在生产环境里太重要了。双十一那种流量高峰,没有这些兜底机制根本扛不住。
模型当指挥官——设计哲学
再说说这个循环里最有意思的设计:模型当指挥官。
传统的 Agent 框架喜欢搞一套复杂的编排逻辑:先做意图识别,再路由到不同的处理器,然后按照预定义的流程一步步执行。
Claude Code 完全反过来——你看这个循环里,没有任何 if-else 来判断”用户想干嘛”。模型说调 Bash 就调 Bash,说读文件就读文件,说写代码就写代码。决策完全交给模型。
背后的赌注是:现代大模型的推理和规划能力已经足够好,不需要你去编排每一步。
一年前这个赌注可能输,但现在看来赌对了。Claude 3.5 Sonnet 及以后的模型,指令遵循和任务规划能力确实够强。
这让我想起我们之前做智能客服的时候,花了大量时间在意图识别上。各种分类模型、规则引擎、决策树… 现在回头看,如果当时有足够好的大模型,很多代码都是多余的。
那你可能会问:那些复杂的 Agent 框架都是白搞了?
不完全是。问题在于,很多框架是在模型能力不够的时代设计的。那时候模型的规划能力弱,你不得不用代码去”辅助”它。但现在模型能力上来了,这些”辅助”反而成了累赘。
Claude Code 的设计哲学很清晰:能让模型干的事,就让模型干。代码只负责执行和兜底。
当然这不是说状态机和 DAG 没用。如果你的业务流程真的需要严格的步骤控制,确定性比灵活性更重要,那复杂编排还是有价值的。但对于 Coding Agent 这个场景——用户需求多变、任务边界模糊、需要灵活应对——简单循环可能就是最优解。
执行节奏
理解了循环的节奏,就能预判行为。
API 调用是大头,通常 500-2000ms,取决于响应长度和服务器负载。工具执行一般更快,文件操作 10-500ms,但 shell 命令可能跑很久——跑个测试套件几分钟很正常,所以 Bash 支持后台执行和超时。
20000 token 的输出上限会影响响应模式。长解释或大段代码生成可能撞上这个限制,需要跨多轮继续。循环自动处理这种情况,但意味着一个逻辑上的完整响应可能跨好几次 API 调用。
翻完这部分代码,印象最深的是它的”克制”。没有过度设计,该简单的地方简单,该处理的边界情况一个不少。
几点收获:先用简单循环跑起来,遇到真正的瓶颈再加复杂度。很多人一上来就想搞复杂架构,结果调试困难、维护成本高。大输出一定要管理,上下文窗口再大也是有限的。模型回退是刚需,API 服务不可能 100% 可用。
核心循环讲完了,但这只是 Claude Code 的骨架。下一篇聊聊消息结构——为什么工具结果要伪装成用户消息,角色的严格交替又带来了哪些约束。
本文基于 Claude Code 2.0.76 版本源码分析,主要文件:src/core/loop.ts、src/core/client.ts。
最后记得⭐️我,每天都在更新:欢迎点赞转发推荐评论,别忘了关注我

