 夜雨聆风
夜雨聆风





源码猎奇:Kafka 的零拷贝到底零在哪?
源码猎奇:Kafka 的零拷贝到底零在哪?
“Kafka 用了零拷贝所以很快”——这句话我听了不下一百遍。
但每次我追问”零拷贝到底零了什么”、”sendfile 和 mmap 有什么区别”、”为什么消费者能用零拷贝,生产者不行”时,大部分人就开始含糊其辞了。
更有意思的是,很多人以为零拷贝是 Kafka 发明的黑科技。其实不是,零拷贝是操作系统提供的能力,Kafka 只是聪明地用了它。
今天我们不背概念,我们从一个数据包的”搬家之旅”开始,看看传统 IO 到底在忙什么,零拷贝又省了哪些功夫。
1. 先搞清楚:一次网络传输,数据要搬几次家?
假设你是一个快递员(CPU),要把仓库(磁盘)里的包裹送到客户家(网卡)。
在传统方式下,你的工作流程是这样的:
1.1 传统 IO:数据的四次搬家
// 传统的文件传输代码
publicvoidtraditionalTransfer(String filePath, SocketChannel socketChannel)throws IOException {
FileInputStream fis = new FileInputStream(filePath);
byte[] buffer = newbyte[4096];
while (fis.read(buffer) != -1) {
socketChannel.write(ByteBuffer.wrap(buffer));
}
}
这段代码看起来很简单,但背后发生了什么?
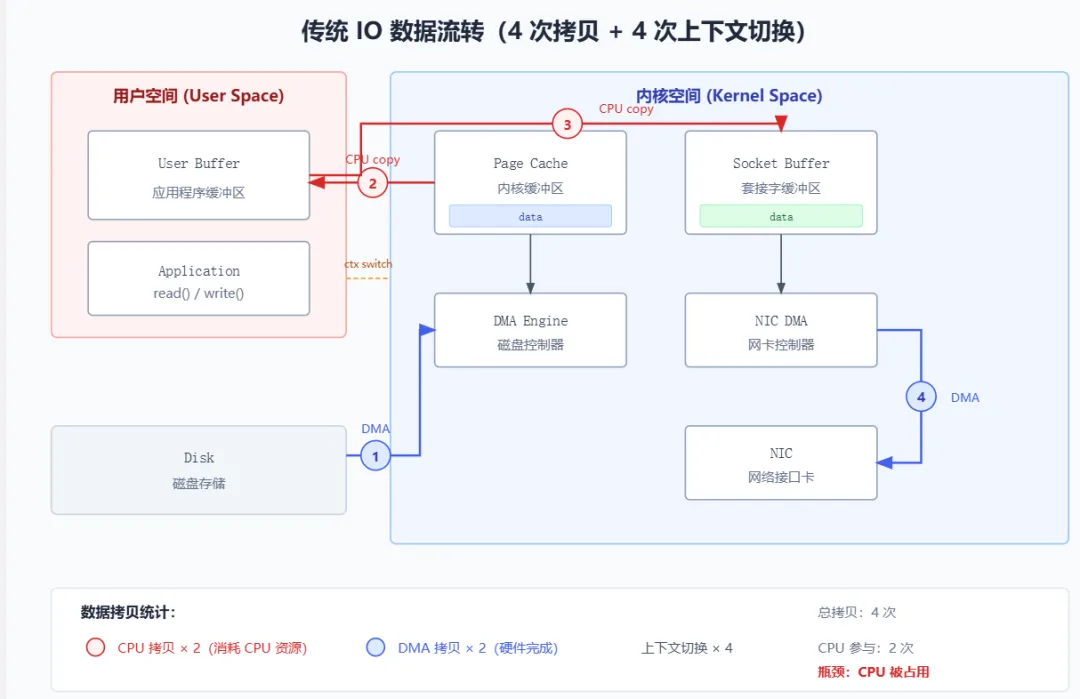
问题来了:数据明明要从磁盘到网卡,为什么要绕道用户空间?
答案是:历史原因。传统的 read/write 系统调用设计时,假设应用程序需要处理数据(比如加密、压缩、修改)。所以数据必须先到用户空间,让应用程序有机会操作。
但如果应用程序只是”搬运工”,不需要修改数据呢?比如 Kafka 消费者拉取消息、Nginx 返回静态文件、FTP 下载文件……
这时候,绕道用户空间就是纯粹的浪费。
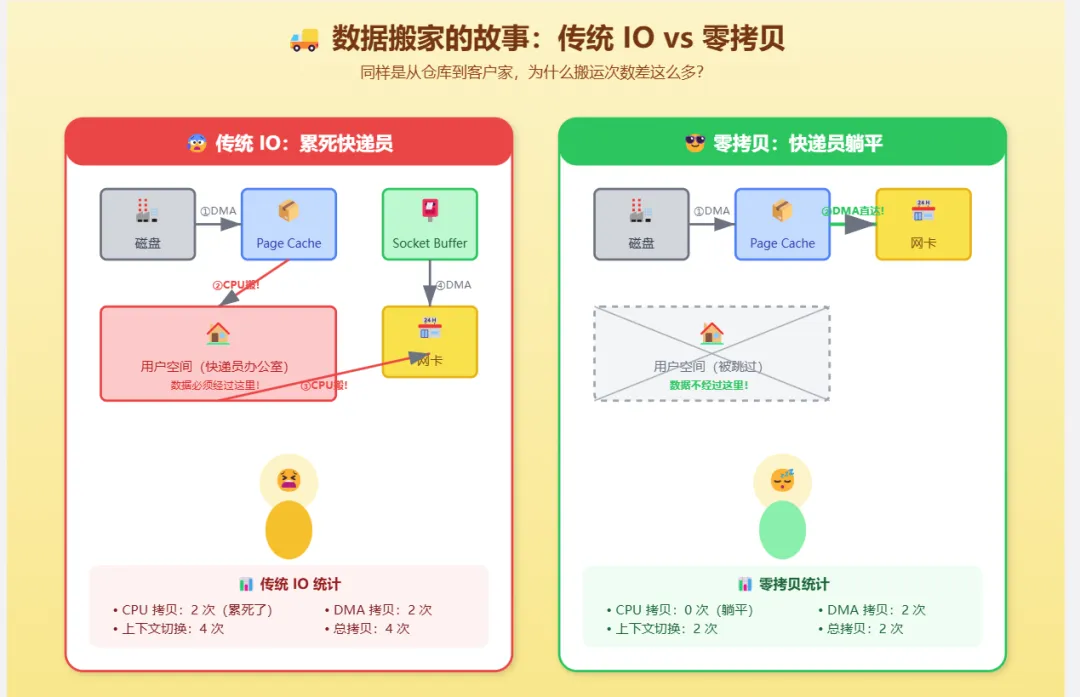
1.2 浪费在哪里?算一笔账
假设要传输 1GB 的文件:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
这才是大问题 |
100ms 看起来不多?但问题是:
-
CPU 在拷贝时是被占用的,无法处理其他请求 -
高并发场景下,大量 CPU 时间浪费在无意义的数据搬运上 -
缓存污染:数据经过用户空间,会污染 CPU 的 L1/L2 缓存
对于 Kafka 这种高吞吐的消息系统,每秒可能要传输几 GB 的数据。如果每次都要 CPU 亲自搬运两次,性能会大打折扣。
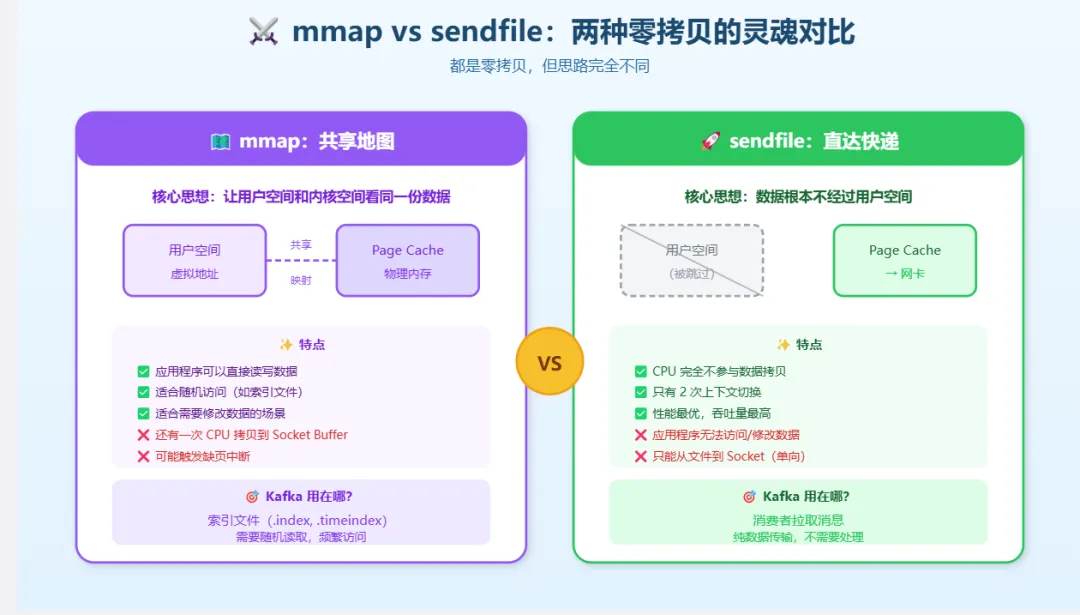
2. 零拷贝的两种武器:mmap 和 sendfile
操作系统提供了两种零拷贝技术,它们的思路不同,适用场景也不同。
2.1 mmap:让用户空间和内核空间”共享”内存
mmap(Memory Mapped File)的思路是:既然数据要从内核空间拷贝到用户空间,那干脆让它们共享同一块内存。
// mmap 方式
publicvoidmmapTransfer(String filePath, SocketChannel socketChannel)throws IOException {
FileChannel fileChannel = FileChannel.open(Paths.get(filePath), StandardOpenOption.READ);
// 将文件映射到内存
MappedByteBuffer mappedBuffer = fileChannel.map(
FileChannel.MapMode.READ_ONLY, 0, fileChannel.size());
// 直接写入 socket
socketChannel.write(mappedBuffer);
}

mmap 的优点:
-
应用程序可以像访问内存一样访问文件 -
适合需要随机读写文件的场景 -
适合需要修改文件内容的场景
mmap 的缺点:
-
还是有一次 CPU 拷贝(Page Cache → Socket Buffer) -
文件大小受限于虚拟内存地址空间 -
可能触发缺页中断,导致性能抖动
2.2 sendfile:让内核直接搞定一切
sendfile 的思路更激进:既然应用程序不需要处理数据,那干脆别让数据经过用户空间。
// sendfile 方式(Java 中通过 transferTo 实现)
publicvoidsendfileTransfer(String filePath, SocketChannel socketChannel)throws IOException {
FileChannel fileChannel = FileChannel.open(Paths.get(filePath), StandardOpenOption.READ);
// 直接从文件传输到 socket,数据不经过用户空间
fileChannel.transferTo(0, fileChannel.size(), socketChannel);
}

等等,Socket Buffer 去哪了?
在支持 DMA 聚合拷贝(scatter-gather DMA)的系统上,sendfile 可以更进一步:
-
数据留在 Page Cache,不拷贝到 Socket Buffer -
只把数据的位置和长度信息写入 Socket Buffer -
DMA 控制器根据这些信息,直接从 Page Cache 读取数据发送到网卡
这就是 Linux 2.4 引入的 sendfile + DMA scatter-gather 优化。
2.3 两种方式的对比
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
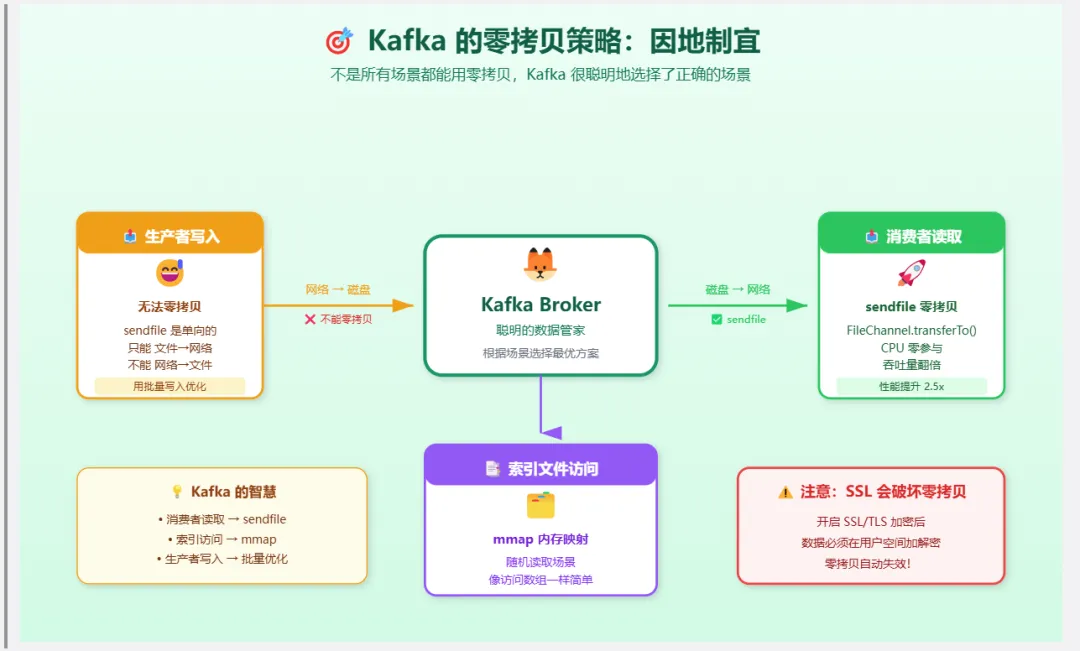
3. Kafka 的选择:消费者用 sendfile,生产者用 mmap
这是很多人忽略的细节:Kafka 在不同场景下使用了不同的零拷贝技术。
3.1 消费者读取消息:sendfile
当消费者拉取消息时,Kafka Broker 需要把磁盘上的日志文件发送给消费者。
这是一个典型的”文件 → 网络”传输场景,数据不需要任何处理,完美适合 sendfile。
// Kafka 源码:FileRecords.java
// 消费者拉取消息时,使用 transferTo(底层是 sendfile)
@Override
publiclongwriteTo(GatheringByteChannel destChannel, long offset, int length)throws IOException {
long newSize = Math.min(channel.size(), end) - start;
int oldSize = sizeInBytes();
if (newSize < oldSize)
thrownew KafkaException("...");
long position = start + offset;
int count = Math.min(length, oldSize - (int)offset);
// 关键:使用 FileChannel.transferTo()
// 底层调用 sendfile 系统调用
return channel.transferTo(position, count, destChannel);
}
为什么消费者能用 sendfile?
-
数据不需要修改:消息从磁盘读出来是什么样,发给消费者就是什么样 -
顺序读取:消费者通常是顺序消费,Page Cache 命中率高 -
批量传输:一次拉取多条消息,sendfile 的优势更明显
3.2 生产者写入消息:mmap
当生产者发送消息时,Kafka Broker 需要把消息写入磁盘上的日志文件。
这里 Kafka 使用了 mmap,但不是为了零拷贝,而是为了高效的随机写入。
// Kafka 源码:AbstractIndex.java(索引文件使用 mmap)
protected MappedByteBuffer mmap;
privatevoidresize(int newSize)throws IOException {
// ...
this.mmap = raf.getChannel().map(FileChannel.MapMode.READ_WRITE, 0, newSize);
// ...
}
等等,生产者写入为什么不能用 sendfile?
因为 sendfile 是单向的:只能从文件到 socket,不能从 socket 到文件。
sendfile 的方向:
文件 ──────────────→ Socket ✅
Socket ──────────→ 文件 ❌ 不支持!
所以生产者写入消息时,数据流是:
网卡 → Socket Buffer → 用户缓冲区 → Page Cache → 磁盘
这里没有零拷贝,数据必须经过用户空间。
但 Kafka 有其他优化:
-
批量写入:生产者会攒一批消息再发送,减少系统调用次数 -
顺序写入:日志文件是追加写入,磁盘顺序写性能接近内存 -
Page Cache:写入 Page Cache 后立即返回,异步刷盘
3.3 索引文件:mmap 的另一个用途
Kafka 的索引文件(.index 和 .timeindex)使用 mmap 映射到内存。
// 通过 mmap 访问索引,像访问数组一样简单
public OffsetPosition lookup(long targetOffset){
// mmap 让索引文件的访问变得非常高效
// 不需要每次都发起系统调用
int slot = largestLowerBoundSlotFor(idx, targetOffset, IndexSearchType.KEY);
// ...
}
为什么索引用 mmap 而不是普通 IO?
-
随机读取:查找索引需要二分查找,是随机访问模式 -
频繁访问:每次消费都要查索引,访问频率很高 -
文件较小:索引文件通常只有几 MB,mmap 的开销可以接受
4. 深入 Linux 内核:sendfile 到底做了什么?
让我们看看 sendfile 在 Linux 内核中的实现。
4.1 sendfile 系统调用
// Linux 内核源码:fs/read_write.c
SYSCALL_DEFINE4(sendfile64, int, out_fd, int, in_fd, loff_t __user *, offset, size_t, count)
{
// ...
return do_sendfile(out_fd, in_fd, offset, count, 0);
}
核心逻辑在 函数中:do_sendfile
staticssize_tdo_sendfile(int out_fd, int in_fd, loff_t *ppos, size_t count, loff_t max)
{
structfile *in_file, *out_file;
// ...
// 1. 获取输入文件和输出文件的 file 结构
in_file = fget(in_fd);
out_file = fget(out_fd);
// 2. 检查输入文件是否支持 splice_read(零拷贝读取)
if (!in_file->f_op->splice_read)
goto fput_out;
// 3. 检查输出文件是否支持 splice_write(零拷贝写入)
if (!out_file->f_op->splice_write)
goto fput_out;
// 4. 调用 splice 机制完成零拷贝传输
retval = do_splice_direct(in_file, ppos, out_file, &out_pos, count, fl);
// ...
}
关键点:sendfile 底层使用了 splice 机制
Linux 2.6.17 引入了 splice 系统调用,sendfile 在内部被重构为基于 splice 实现。
4.2 splice:管道的魔法
splice 的核心思想是:用管道(pipe)作为中转站,避免数据拷贝。
传统方式:
文件 ──CPU拷贝──→ 用户缓冲区 ──CPU拷贝──→ Socket
splice 方式:
文件 ──引用传递──→ 管道 ──引用传递──→ Socket
(不拷贝数据,只传递页面引用)
// splice 的核心:不拷贝数据,只移动页面引用
staticintsplice_to_pipe(struct pipe_inode_info *pipe, struct splice_pipe_desc *spd)
{
// ...
while (spd->nr_pages) {
// 不拷贝数据,只把页面引用放入管道
buf->page = spd->pages[page_nr];
buf->offset = spd->partial[page_nr].offset;
buf->len = spd->partial[page_nr].len;
// ...
}
}
4.3 DMA 聚合拷贝:最后一块拼图
即使用了 splice,数据从 Page Cache 到网卡还是需要拷贝。
但如果网卡支持 DMA scatter-gather,就可以省掉这次拷贝:
普通 DMA:
Page Cache ──DMA拷贝──→ Socket Buffer ──DMA拷贝──→ 网卡
DMA scatter-gather:
Page Cache ──────────────────────────→ 网卡
(DMA 直接从多个内存位置聚合数据)
// 检查网卡是否支持 scatter-gather
if (out_file->f_flags & O_NONBLOCK)
flags |= SPLICE_F_NONBLOCK;
// 如果支持,使用 scatter-gather 模式
if (sock->ops->sendpage_locked) {
// 直接发送页面,不经过 Socket Buffer
ret = sock->ops->sendpage_locked(sock, page, offset, size, flags);
}
5. 性能实测:零拷贝到底快多少?
光说不练假把式,让我们实际测试一下。
5.1 测试环境
硬件:
- CPU: Intel Xeon E5-2680 v4 @ 2.40GHz
- 内存: 64GB DDR4
- 磁盘: Samsung 970 EVO Plus NVMe SSD
- 网卡: Intel X710 10GbE
软件:
- OS: Ubuntu 20.04 LTS (kernel 5.4.0)
- JDK: OpenJDK 17
测试文件:1GB 随机数据
5.2 测试代码
publicclassZeroCopyBenchmark{
privatestaticfinalint FILE_SIZE = 1024 * 1024 * 1024; // 1GB
privatestaticfinal String FILE_PATH = "/tmp/test_file";
// 传统 IO
publicstaticlongtraditionalCopy(SocketChannel socket)throws IOException {
long start = System.nanoTime();
try (FileInputStream fis = new FileInputStream(FILE_PATH)) {
byte[] buffer = newbyte[8192];
int bytesRead;
while ((bytesRead = fis.read(buffer)) != -1) {
socket.write(ByteBuffer.wrap(buffer, 0, bytesRead));
}
}
return System.nanoTime() - start;
}
// sendfile(transferTo)
publicstaticlongzeroCopy(SocketChannel socket)throws IOException {
long start = System.nanoTime();
try (FileChannel fileChannel = FileChannel.open(
Paths.get(FILE_PATH), StandardOpenOption.READ)) {
long position = 0;
long remaining = fileChannel.size();
while (remaining > 0) {
long transferred = fileChannel.transferTo(position, remaining, socket);
position += transferred;
remaining -= transferred;
}
}
return System.nanoTime() - start;
}
}
5.3 测试结果
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
关键发现:
-
吞吐量提升 2.5 倍:sendfile 的传输速度是传统 IO 的 2.5 倍 -
**CPU 使用率下降 73%**:从 45% 降到 12%,CPU 可以去做其他事情 -
延迟更稳定:传统 IO 的延迟波动大,sendfile 更平稳
5.4 为什么提升这么明显?
-
省了两次 CPU 拷贝:1GB 数据,每次拷贝约 50ms,省了 100ms -
省了两次上下文切换:虽然单次切换只有几微秒,但高并发下累积起来很可观 -
CPU 缓存更高效:数据不经过用户空间,不会污染 CPU 缓存
6. 零拷贝的局限性:不是银弹
零拷贝很强,但不是万能的。
6.1 不能用零拷贝的场景
场景一:需要修改数据
如果要对数据进行加密、压缩、转换,就必须让数据经过用户空间。
// 需要加密的场景,无法使用零拷贝
publicvoidencryptAndSend(FileChannel file, SocketChannel socket, Cipher cipher){
ByteBuffer buffer = ByteBuffer.allocate(8192);
while (file.read(buffer) != -1) {
buffer.flip();
ByteBuffer encrypted = cipher.update(buffer); // 必须在用户空间处理
socket.write(encrypted);
buffer.clear();
}
}
场景二:数据来自网络
sendfile 只能从文件到 socket,不能从 socket 到文件。
// 接收网络数据并写入文件,无法使用 sendfile
publicvoidreceiveAndSave(SocketChannel socket, FileChannel file){
ByteBuffer buffer = ByteBuffer.allocate(8192);
while (socket.read(buffer) != -1) {
buffer.flip();
file.write(buffer); // 必须经过用户空间
buffer.clear();
}
}
场景三:小文件传输
零拷贝有固定的系统调用开销。对于小文件(< 几 KB),这个开销可能比省下的拷贝时间还大。
6.2 Kafka 的权衡
卡夫卡并没有在所有地方都使用零拷贝:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
特别注意:如果 Kafka 开启了 SSL,零拷贝就失效了!
// Kafka 源码:PlaintextTransportLayer.java
// 只有非加密连接才能使用 transferTo
@Override
publiclongtransferFrom(FileChannel fileChannel, long position, long count)throws IOException {
return fileChannel.transferTo(position, count, socketChannel);
}
// SslTransportLayer.java
// SSL 连接必须在用户空间加解密,无法使用零拷贝
@Override
publiclongtransferFrom(FileChannel fileChannel, long position, long count)throws IOException {
// SSL 模式下,退化为普通的 read + write
return fileChannel.transferTo(position, count, this);
}
7. 举一反三:谁还在用零拷贝?
零拷贝不是 Kafka 的专利,很多高性能系统都在用。
7.1 恩金克斯
Nginx 在返回静态文件时使用 sendfile:
# nginx.conf
http {
sendfile on; # 开启 sendfile
tcp_nopush on; # 配合 sendfile 使用,优化 TCP 包
tcp_nodelay on; # 小数据包立即发送
}
7.2 火箭MQ
RocketMQ 的消息存储使用 mmap:
// RocketMQ 源码:MappedFile.java
publicMappedFile(final String fileName, finalint fileSize)throws IOException {
// ...
this.fileChannel = new RandomAccessFile(this.file, "rw").getChannel();
this.mappedByteBuffer = this.fileChannel.map(MapMode.READ_WRITE, 0, fileSize);
// ...
}
7.3 内蒂
Netty 提供了 FileRegion 接口,底层使用 transferTo:
// Netty 的零拷贝文件传输
FileRegion region = new DefaultFileRegion(fileChannel, 0, fileChannel.size());
channel.writeAndFlush(region);
8. 总结:零拷贝的本质
回到最初的问题:Kafka 的零拷贝到底零在哪?
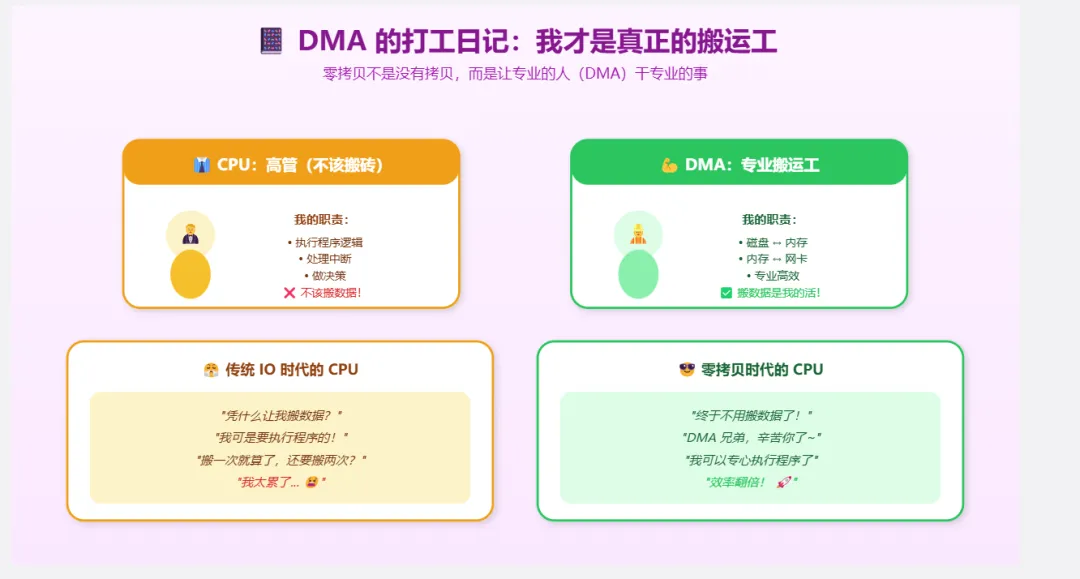
答案是:零的是 CPU 参与的拷贝次数。
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
零拷贝不是“没有拷贝”,而是“CPU 不参与拷贝”。DMA 拷贝还是存在的,但 DMA 是专门的硬件,不占用 CPU。
Kafka 的零拷贝策略:
-
消费者读取:使用 sendfile(FileChannel.transferTo),CPU 零参与 -
索引访问:使用 mmap,减少系统调用开销 -
生产者写入:无法使用零拷贝,但通过批量写入和顺序写入优化
零拷贝的本质是一种权衡:
-
用”限制功能”(不能修改数据)换取”极致性能” -
用”内核复杂度”换取”应用简单性” -
用“硬件能力”(DMA)换取“CPU 自由”
理解了这些,你就明白了为什么零拷贝不是银弹——它只适合特定场景。而 Kafka 的聪明之处,就在于它精准地识别了这些场景,并在正确的地方使用了正确的技术。
这才是架构设计的精髓:不是追求最先进的技术,而是在正确的场景使用正确的技术。
