 夜雨聆风
夜雨聆风





Go 通道(Channel)源码深度解析
Go 通道(Channel)源码深度解析
基于 Go 1.25.2 源码分析
1. 引言
Go 语言的通道(Channel)是 CSP(Communicating Sequential Processes)并发模型的核心实现,它提供了一种安全的方式让多个 goroutine 之间进行通信和同步。通过”不要通过共享内存来通信,而要通过通信来共享内存”的设计哲学,Go 的通道极大地简化了并发编程的复杂性。
本文将深入分析 Go 运行时中通道的源码实现,帮助读者全面理解通道的内部工作机制。
源码位置
-
主实现: runtime/chan.go -
Select 实现: runtime/select.go -
相关数据结构: runtime/runtime2.go
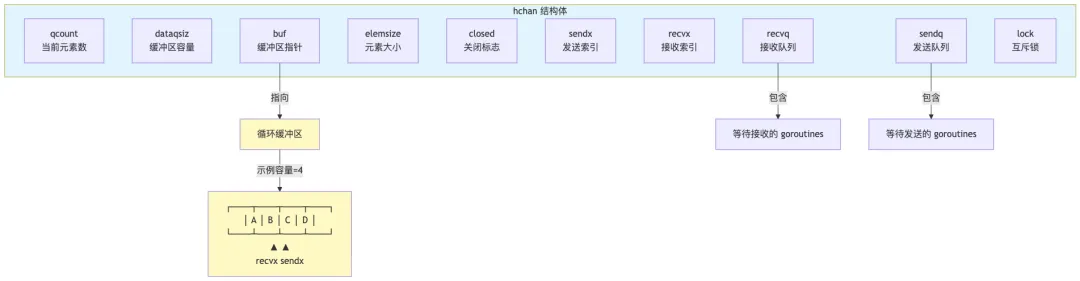
2. hchan 核心数据结构
2.1 完整代码
// runtime/chan.go:34-55
type hchan struct {
qcount uint// 队列中的数据总数
dataqsiz uint// 循环队列的大小
buf unsafe.Pointer // 指向 dataqsiz 个元素的数组指针
elemsize uint16// 元素大小
closed uint32// 关闭标志
timer *timer // 定时器通道专用
elemtype *_type // 元素类型
sendx uint// 发送索引
recvx uint// 接收索引
recvq waitq // 接收等待队列
sendq waitq // 发送等待队列
bubble *synctestBubble
// lock 保护 hchan 中的所有字段,以及在此通道上阻塞的 sudogs 的某些字段
//
// 持有此锁时不要改变其他 G 的状态(特别是不要 ready 一个 G),
// 因为这会与栈收缩产生死锁
lock mutex
}
2.2 字段详解
|
|
|
|
|---|---|---|
qcount |
|
|
dataqsiz |
|
|
buf |
|
|
elemsize |
|
|
closed |
|
|
sendx |
|
|
recvx |
|
|
recvq |
|
|
sendq |
|
|
lock |
|
|
2.3 等待队列 waitq
// runtime/chan.go:57-60
type waitq struct {
first *sudog // 队列头部
last *sudog // 队列尾部
}
waitq 是一个双向链表,存储因通道操作而阻塞的 goroutine(封装为 sudog 结构)。
2.4 内存布局图
2.5 关键不变量(Invariants)
// runtime/chan.go:9-18
// Invariants:
// 至少 c.sendq 和 c.recvq 之一为空,
// 除了在 select 语句中阻塞在无缓冲通道上的单个 goroutine 的情况。
//
// 对于有缓冲通道,还有:
// c.qcount > 0 意味着 c.recvq 为空
// c.qcount < c.dataqsiz 意味着 c.sendq 为空
这些不变量确保了通道操作的正确性和可预测性。
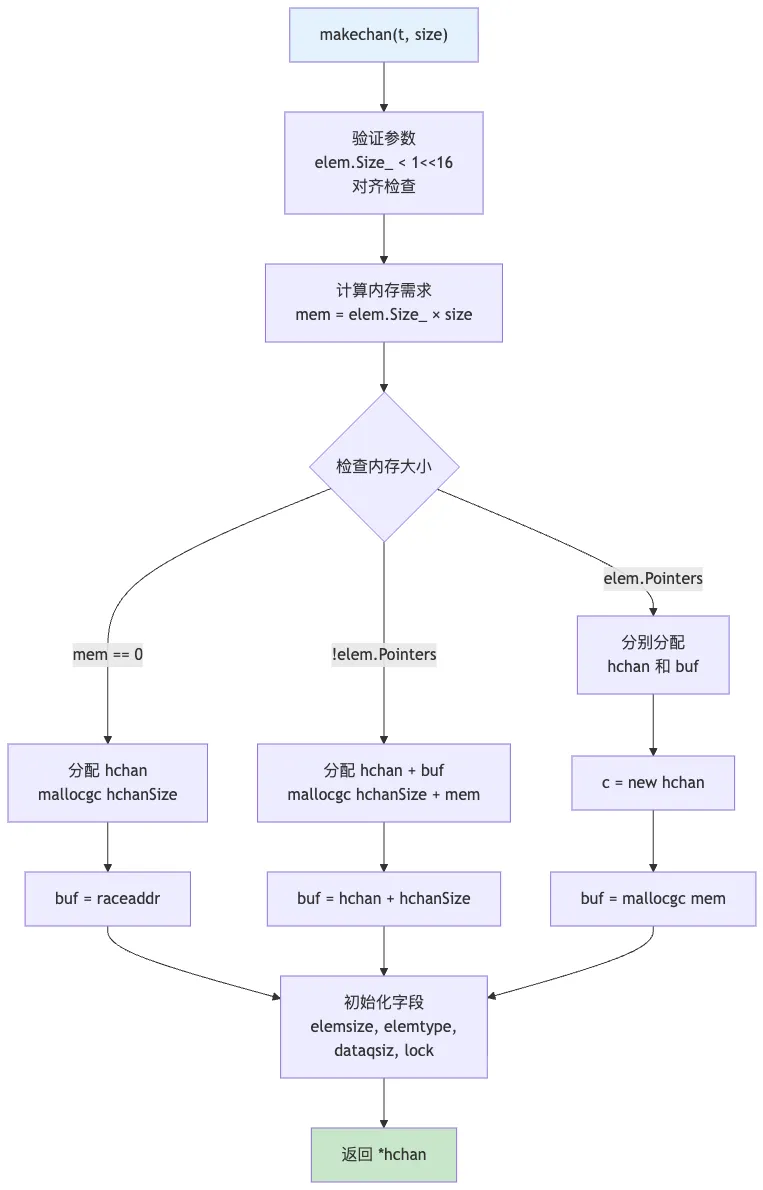
3. 通道创建 – makechan()
3.1 完整源码
// runtime/chan.go:75-125
funcmakechan(t *chantype, size int) *hchan {
elem := t.Elem
// 编译器会检查这个,但要安全起见
if elem.Size_ >= 1<<16 {
throw("makechan: invalid channel element type")
}
if hchanSize%maxAlign != 0 || elem.Align_ > maxAlign {
throw("makechan: bad alignment")
}
// 计算需要的内存大小
mem, overflow := math.MulUintptr(elem.Size_, uintptr(size))
if overflow || mem > maxAlloc-hchanSize || size < 0 {
panic(plainError("makechan: size out of range"))
}
// 当 buf 中存储的元素不包含指针时,hchan 不包含 GC 感兴趣的指针。
// buf 指向同一个分配,elemtype 是持久化的。
// Sudog 从其所属线程引用,因此它们不会被回收。
var c *hchan
switch {
case mem == 0:
// 队列或元素大小为零
c = (*hchan)(mallocgc(hchanSize, nil, true))
// 竞态检测器使用此位置进行同步
c.buf = c.raceaddr()
case !elem.Pointers():
// 元素不包含指针
// 一次性分配 hchan 和 buf
c = (*hchan)(mallocgc(hchanSize+mem, nil, true))
c.buf = add(unsafe.Pointer(c), hchanSize)
default:
// 元素包含指针
c = new(hchan)
c.buf = mallocgc(mem, elem, true)
}
c.elemsize = uint16(elem.Size_)
c.elemtype = elem
c.dataqsiz = uint(size)
if b := getg().bubble; b != nil {
c.bubble = b
}
lockInit(&c.lock, lockRankHchan)
if debugChan {
print("makechan: chan=", c, "; elemsize=", elem.Size_, "; dataqsiz=", size, "\n")
}
return c
}
3.2 内存分配策略
makechan() 根据元素类型和通道大小采用三种不同的内存分配策略:
策略 1:零大小元素(mem == 0)
当元素大小为零或通道容量为零时:
c = (*hchan)(mallocgc(hchanSize, nil, true))
c.buf = c.raceaddr() // 指向竞态检测器使用的地址
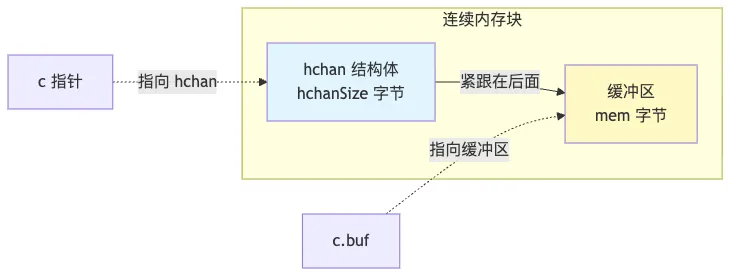
策略 2:非指针元素(!elem.Pointers())
当元素不包含指针时,可以将 hchan 和缓冲区在单次分配中完成:
c = (*hchan)(mallocgc(hchanSize+mem, nil, true))
c.buf = add(unsafe.Pointer(c), hchanSize) // buf 紧跟在 hchan 后面
优点:减少一次内存分配,提高缓存局部性。
策略 3:包含指针的元素
当元素包含指针时,需要分别分配:
c = new(hchan)
c.buf = mallocgc(mem, elem, true)
原因:GC 需要正确跟踪 buf 中的指针,独立分配可以确保正确的 GC 扫描。
为什么区分有指针和无指针元素
Go 运行时根据元素类型是否包含指针,采用不同的内存分配策略。这是一个精妙的设计,兼顾了性能和正确性。
策略 2 深入:!elem.Pointers() – 单次连续分配
当元素不包含指针时,运行时选择将 hchan 和 buffer 在一次 malloc 中完成分配:
// runtime/chan.go:167-171
case !elem.Pointers():
// 元素不包含指针
// 一次性分配 hchan 和 buf
c = (*hchan)(mallocgc(hchanSize+mem, nil, true))
c.buf = add(unsafe.Pointer(c), hchanSize)
内存布局:
三大优势:
-
性能提升:减少一次 malloc 调用
-
一次内存分配调用代替两次 -
减少内存分配器开销 -
缓存局部性:hchan 和 buffer 在连续内存
-
访问 hchan 后再访问 buffer,缓存命中率高 -
减少 cache miss -
GC 优化:GC 不需要扫描 buffer
-
无指针元素不包含 GC 感兴趣的指针 -
GC 只需扫描 hchan 结构本身的字段
为什么可以这样?
关键在于 Go 的类型系统和 GC 设计:
-
编译器在编译时就确定元素类型 -
elemtype字段指向持久化的类型信息 -
GC 只扫描”可能包含指针”的内存区域 -
对于无指针 buffer,GC 可以安全跳过
策略 3 深入:elem.Pointers() – 分离分配
当元素包含指针时,运行时选择分离分配:
// runtime/chan.go:172-175
default:
// 元素包含指针
c = new(hchan)
c.buf = mallocgc(mem, elem, true)
内存布局:
graph LR
Hchan["hchan 结构体<br/>独立分配"]
Buffer["缓冲区<br/>独立分配<br/>包含指针的元素"]
Hchan -->|"buf 字段指向"| Buffer
style Hchan fill:#e1f5fe
style Buffer fill:#ffccbc
为什么必须分离?
原因 1:GC 扫描需要类型信息
GC 必须知道 buffer 中每个元素的类型才能正确扫描其中的指针:
// 分配时指定 elem 作为类型信息
c.buf = mallocgc(mem, elem, true)
这样 GC 在扫描时知道:
-
buffer 每个元素的大小 -
每个元素中哪些位置是指针 -
如何找到和更新这些指针
原因 2:避免 hchan 被 GC 扫描
如果连续分配 [hchan+buffer],会带来问题:
-
GC 需要知道整个区域的类型 -
这会是一个复杂的复合类型 -
hchan 本身的字段不需要 GC 扫描(除了 buf 指针)
分离后:
-
hchan 可以按普通结构体分配 -
buffer 按元素类型数组分配 -
各自独立,类型信息清晰
原因 3:写屏障正确性
GC 的写屏障需要准确的类型信息来处理指针更新。分离分配确保:
-
写屏障能正确识别 buffer 中的指针 -
避免将 hchan 结构体误认为包含指针的 buffer
权衡:
-
代价:多一次 malloc 调用 -
收益:GC 正确性得到保证 -
结论:正确性优先于性能
GC 工作原理对比
无指针 buffer 的 GC 扫描:
GC 扫描流程:
1. 扫描 hchan 结构
2. 检查 buf 字段指针
3. buf 指向的内存不包含指针 → 跳过扫描
4. 完成
有指针 buffer 的 GC 扫描:
GC 扫描流程:
1. 扫描 hchan 结构
2. 检查 buf 字段指针
3. buf 指向的内存包含指针 → 需要扫描
4. 遍历 buffer 中每个元素
5. 根据 elemtype 信息找到元素中的指针
6. 标记/更新这些指针
7. 完成
类型信息的持久性
源码注释中提到:
// 当 buf 中存储的元素不包含指针时,hchan 不包含 GC 感兴趣的指针。
// buf 指向同一个分配,elemtype 是持久化的。
// Sudog 从其所属线程引用,因此它们不会被回收。
elemtype 持久化的含义:
-
elemtype 指向 runtime 中的类型描述符 -
这个描述符在程序运行期间不会改变 -
GC 可以信任这个信息,不会出现类型变化
为什么重要:
-
单次分配策略依赖于类型信息不变 -
GC 依赖类型信息来决定扫描策略 -
如果类型可能变化,整个设计需要重新考虑
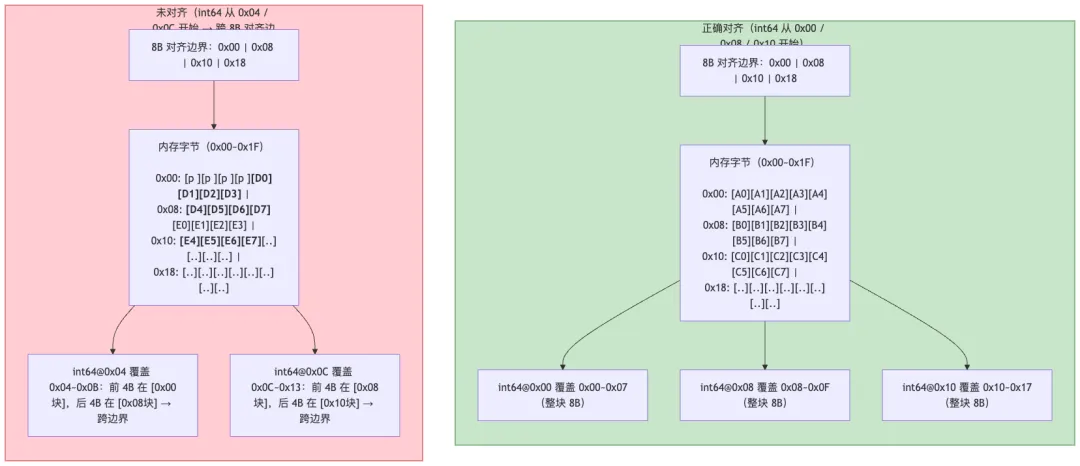
3.2.1 内存对齐详解
什么是内存对齐
内存对齐(Memory Alignment)是指数据在内存中存储时,其起始地址必须是某个数(对齐边界)的倍数。
为什么需要内存对齐?
-
CPU 访问效率:现代 CPU 通常以”缓存行”或”字”为单位访问内存。如果数据未对齐,CPU 可能需要多次内存访问才能读取一个数据 -
原子操作要求:某些原子操作要求地址必须对齐 -
性能惩罚:未对齐访问可能导致严重的性能下降
示例:在 64 位系统上,int64 类型应该存储在 8 的倍数地址上(0x00, 0x08, 0x10…)
Go 中的对齐要求
Go 运行时定义了平台相关的对齐要求:
-
maxAlign = 8:64 位系统上的最大对齐边界(8 字节) -
类型对齐:每种类型都有 Align_字段 -
int8,uint8: 1 字节对齐 -
int16,uint16: 2 字节对齐 -
int32,uint32,float32: 4 字节对齐 -
int64,uint64,float64,*T: 8 字节对齐
makechan() 中的对齐检查
// runtime/chan.go:147-149
if hchanSize%maxAlign != 0 || elem.Align_ > maxAlign {
throw("makechan: bad alignment")
}
检查 1:hchanSize % maxAlign != 0
-
确保 hchan 结构体的大小是 8 的倍数 -
这样分配的 hchan 地址自然对齐到 8 字节边界 -
后续的 buffer 也能正确对齐
检查 2:elem.Align_ > maxAlign
-
确保元素类型的对齐要求不超过 maxAlign -
如果超过,无法保证 buffer 中每个元素都正确对齐
内存对齐示意图
hchan 结构体的内存布局
hchan 结构体本身也需要考虑字段对齐:
// runtime/chan.go:34-55(简化版本)
type hchan struct {
qcount uint// 8 字节,偏移 0
dataqsiz uint// 8 字节,偏移 8
buf unsafe.Pointer // 8 字节,偏移 16
elemsize uint16// 2 字节,偏移 24
closed uint32// 4 字节,偏移 26 + 2 字节 padding
timer *timer // 8 字节,偏移 32
// ... 其他字段
}
内存布局示意:

编译器会自动插入 padding(如偏移 30 处的 2 字节)确保每个字段正确对齐。
为什么这对通道很重要
-
lock 字段正确工作:mutex 的原子操作要求对齐 -
buffer 元素对齐:连续分配时,buffer 必须在 hchanSize 之后正确对齐 -
跨平台兼容性:不同平台的对齐要求可能不同
3.3 数据流图
3.4 关键设计考虑
-
内存对齐:确保 hchan 按 maxAlign(8 字节)对齐 -
GC 友好:根据元素是否包含指针选择不同的分配策略 -
竞态检测:为零大小通道提供特殊的地址用于竞态检测器同步
4. 发送操作 – chansend()
4.1 完整源码
// runtime/chan.go:176-310
funcchansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr)bool {
// nil 通道处理
if c == nil {
if !block {
returnfalse
}
gopark(nil, nil, waitReasonChanSendNilChan, traceBlockForever, 2)
throw("unreachable")
}
// 快速路径:无需获取锁即可检查非阻塞操作是否失败
if !block && c.closed == 0 && full(c) {
returnfalse
}
var t0 int64
if blockprofilerate > 0 {
t0 = cputicks()
}
lock(&c.lock)
// 检查通道是否已关闭
if c.closed != 0 {
unlock(&c.lock)
panic(plainError("send on closed channel"))
}
// 场景1: 有等待的接收者 - 直接发送
if sg := c.recvq.dequeue(); sg != nil {
// 找到等待的接收者,直接传递值,绕过缓冲区
send(c, sg, ep, func() { unlock(&c.lock) }, 3)
returntrue
}
// 场景2: 缓冲区有空间 - 入队
if c.qcount < c.dataqsiz {
// 通道缓冲区有空间,将元素入队
qp := chanbuf(c, c.sendx)
if raceenabled {
racenotify(c, c.sendx, nil)
}
typedmemmove(c.elemtype, qp, ep)
c.sendx++
if c.sendx == c.dataqsiz {
c.sendx = 0
}
c.qcount++
unlock(&c.lock)
returntrue
}
// 场景3: 非阻塞模式 - 立即返回
if !block {
unlock(&c.lock)
returnfalse
}
// 场景4: 阻塞发送
// 在通道上阻塞,某个接收者将为我们完成操作
gp := getg()
mysg := acquireSudog()
mysg.releasetime = 0
if t0 != 0 {
mysg.releasetime = -1
}
// 在分配 elem 和将 mysg 入队到 gp.waiting 之间不能有栈分裂
mysg.elem = ep
mysg.waitlink = nil
mysg.g = gp
mysg.isSelect = false
mysg.c = c
gp.waiting = mysg
gp.param = nil
c.sendq.enqueue(mysg)
gp.parkingOnChan.Store(true)
reason := waitReasonChanSend
if c.bubble != nil {
reason = waitReasonSynctestChanSend
}
gopark(chanparkcommit, unsafe.Pointer(&c.lock), reason, traceBlockChanSend, 2)
// 确保发送的值保持存活,直到接收者复制它出去
KeepAlive(ep)
// 有人唤醒了我们
if mysg != gp.waiting {
throw("G waiting list is corrupted")
}
gp.waiting = nil
gp.activeStackChans = false
closed := !mysg.success
gp.param = nil
if mysg.releasetime > 0 {
blockevent(mysg.releasetime-t0, 2)
}
mysg.c = nil
releaseSudog(mysg)
if closed {
if c.closed == 0 {
throw("chansend: spurious wakeup")
}
panic(plainError("send on closed channel"))
}
returntrue
}
4.2 send() 函数
// runtime/chan.go:318-351
funcsend(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skipint) {
if c.bubble != nil && getg().bubble != c.bubble {
unlockf()
fatal("send on synctest channel from outside bubble")
}
if raceenabled {
if c.dataqsiz == 0 {
racesync(c, sg)
} else {
// 假装我们通过缓冲区传输,即使我们是直接复制
racenotify(c, c.recvx, nil)
racenotify(c, c.recvx, sg)
c.recvx++
if c.recvx == c.dataqsiz {
c.recvx = 0
}
c.sendx = c.recvx
}
}
if sg.elem != nil {
sendDirect(c.elemtype, sg, ep)
sg.elem = nil
}
gp := sg.g
unlockf()
gp.param = unsafe.Pointer(sg)
sg.success = true
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
goready(gp, skip+1) // 唤醒接收者
}
4.3 sendDirect() 函数
// runtime/chan.go:392-403
funcsendDirect(t *_type, sg *sudog, src unsafe.Pointer) {
// src 在我们的栈上,dst 在另一个栈上
// 一旦我们从 sg 中读出 sg.elem,如果目标栈被复制(收缩),
// 它将不再被更新。所以确保在读取和使用之间不能发生抢占。
dst := sg.elem
typeBitsBulkBarrier(t, uintptr(dst), uintptr(src), t.Size_)
// 不需要 cgo 写屏障检查,因为 dst 总是 Go 内存
memmove(dst, src, t.Size_)
}
注意:这是 Go 中唯一一个运行中的 goroutine 写入另一个运行中 goroutine 栈的场景。GC 假设栈写入只在 goroutine 运行时发生,并且只由该 goroutine 自己完成。使用写屏障足以弥补违反这个假设的问题。
4.4 发送操作数据流图
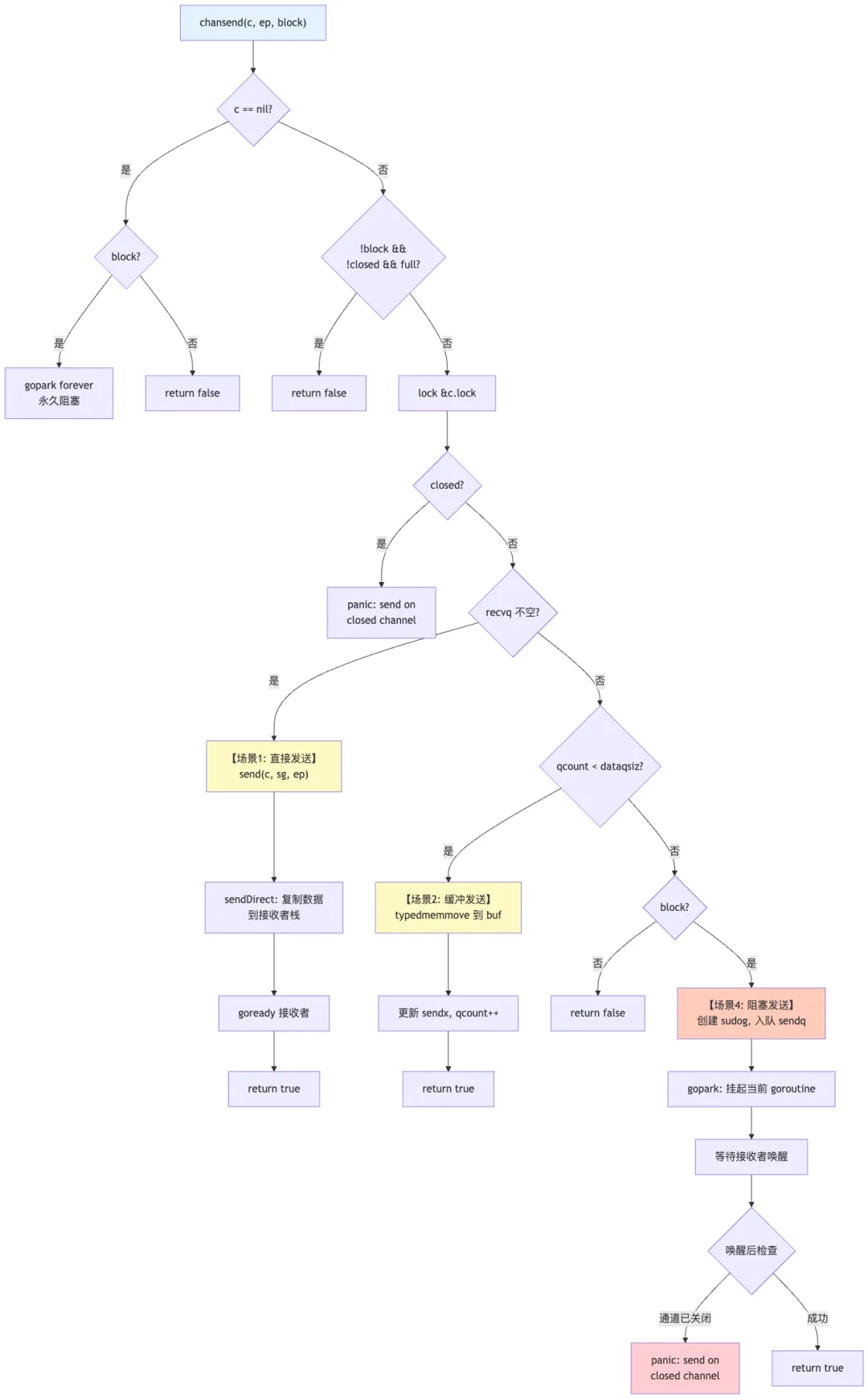
4.5 四种发送场景详解
场景 1:直接发送(有等待接收者)
当发现 recvq 非空时,说明有 goroutine 正在等待接收数据。此时可以直接将数据复制到接收者的栈中,完全绕过缓冲区。
if sg := c.recvq.dequeue(); sg != nil {
send(c, sg, ep, func() { unlock(&c.lock) }, 3)
returntrue
}
优点:
-
避免额外的内存复制 -
减少同步延迟 -
这是 Go 通道高效的关键设计之一
场景 2:缓冲发送(缓冲区有空间)
当缓冲区未满时,将数据放入循环缓冲区:
if c.qcount < c.dataqsiz {
qp := chanbuf(c, c.sendx)
typedmemmove(c.elemtype, qp, ep)
c.sendx++
if c.sendx == c.dataqsiz {
c.sendx = 0
}
c.qcount++
returntrue
}
场景 3:非阻塞发送失败
在 select 语句的 default 分支中调用,如果无法立即完成则返回 false。
场景 4:阻塞发送
当没有接收者且缓冲区已满时,当前 goroutine 需要阻塞等待:
// 创建 sudog 并入队
mysg := acquireSudog()
mysg.elem = ep
mysg.g = gp
c.sendq.enqueue(mysg)
// 挂起当前 goroutine
gopark(chanparkcommit, unsafe.Pointer(&c.lock), reason, traceBlockChanSend, 2)
5. 接收操作 – chanrecv()
5.1 完整源码
// runtime/chan.go:524-686
funcchanrecv(c *hchan, ep unsafe.Pointer, block bool)(selected, received bool) {
if c == nil {
if !block {
return
}
gopark(nil, nil, waitReasonChanReceiveNilChan, traceBlockForever, 2)
throw("unreachable")
}
if c.bubble != nil && getg().bubble != c.bubble {
fatal("receive on synctest channel from outside bubble")
}
if c.timer != nil {
c.timer.maybeRunChan(c)
}
// 快速路径:无需获取锁检查非阻塞操作是否失败
if !block && empty(c) {
if atomic.Load(&c.closed) == 0 {
return
}
// 通道已不可逆地关闭,重新检查是否有待接收的数据
if empty(c) {
if raceenabled {
raceacquire(c.raceaddr())
}
if ep != nil {
typedmemclr(c.elemtype, ep)
}
returntrue, false
}
}
var t0 int64
if blockprofilerate > 0 {
t0 = cputicks()
}
lock(&c.lock)
if c.closed != 0 {
if c.qcount == 0 {
if raceenabled {
raceacquire(c.raceaddr())
}
unlock(&c.lock)
if ep != nil {
typedmemclr(c.elemtype, ep)
}
returntrue, false
}
// 通道已关闭但缓冲区还有数据
} else {
// 场景1: 有等待的发送者
if sg := c.sendq.dequeue(); sg != nil {
// 找到等待的发送者
recv(c, sg, ep, func() { unlock(&c.lock) }, 3)
returntrue, true
}
}
// 场景2: 从缓冲区接收
if c.qcount > 0 {
qp := chanbuf(c, c.recvx)
if raceenabled {
racenotify(c, c.recvx, nil)
}
if ep != nil {
typedmemmove(c.elemtype, ep, qp)
}
typedmemclr(c.elemtype, qp)
c.recvx++
if c.recvx == c.dataqsiz {
c.recvx = 0
}
c.qcount--
unlock(&c.lock)
returntrue, true
}
// 场景3: 非阻塞模式
if !block {
unlock(&c.lock)
returnfalse, false
}
// 场景4: 阻塞接收
gp := getg()
mysg := acquireSudog()
mysg.releasetime = 0
if t0 != 0 {
mysg.releasetime = -1
}
mysg.elem = ep
mysg.waitlink = nil
gp.waiting = mysg
mysg.g = gp
mysg.isSelect = false
mysg.c = c
gp.param = nil
c.recvq.enqueue(mysg)
if c.timer != nil {
blockTimerChan(c)
}
gp.parkingOnChan.Store(true)
reason := waitReasonChanReceive
if c.bubble != nil {
reason = waitReasonSynctestChanReceive
}
gopark(chanparkcommit, unsafe.Pointer(&c.lock), reason, traceBlockChanRecv, 2)
// 有人唤醒了我们
if mysg != gp.waiting {
throw("G waiting list is corrupted")
}
if c.timer != nil {
unblockTimerChan(c)
}
gp.waiting = nil
gp.activeStackChans = false
if mysg.releasetime > 0 {
blockevent(mysg.releasetime-t0, 2)
}
success := mysg.success
gp.param = nil
mysg.c = nil
releaseSudog(mysg)
returntrue, success
}
5.2 recv() 函数
// runtime/chan.go:702-746
funcrecv(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skipint) {
if c.bubble != nil && getg().bubble != c.bubble {
unlockf()
fatal("receive on synctest channel from outside bubble")
}
if c.dataqsiz == 0 {
// 无缓冲通道:直接从发送者接收
if raceenabled {
racesync(c, sg)
}
if ep != nil {
recvDirect(c.elemtype, sg, ep)
}
} else {
// 有缓冲通道:从队列头部接收,将发送者的数据放入队列尾部
qp := chanbuf(c, c.recvx)
if raceenabled {
racenotify(c, c.recvx, nil)
racenotify(c, c.recvx, sg)
}
// 从队列复制数据到接收者
if ep != nil {
typedmemmove(c.elemtype, ep, qp)
}
// 从发送者复制数据到队列
typedmemmove(c.elemtype, qp, sg.elem)
c.recvx++
if c.recvx == c.dataqsiz {
c.recvx = 0
}
c.sendx = c.recvx
}
sg.elem = nil
gp := sg.g
unlockf()
gp.param = unsafe.Pointer(sudog)
sg.success = true
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
goready(gp, skip+1)
}
5.3 recvDirect() 函数
// runtime/chan.go:405-412
funcrecvDirect(t *_type, sg *sudog, dst unsafe.Pointer) {
// dst 在我们的栈或堆上,src 在另一个栈上
// 通道已锁定,因此 src 在此操作期间不会移动
src := sg.elem
typeBitsBulkBarrier(t, uintptr(dst), uintptr(src), t.Size_)
memmove(dst, src, t.Size_)
}
5.4 接收操作数据流图
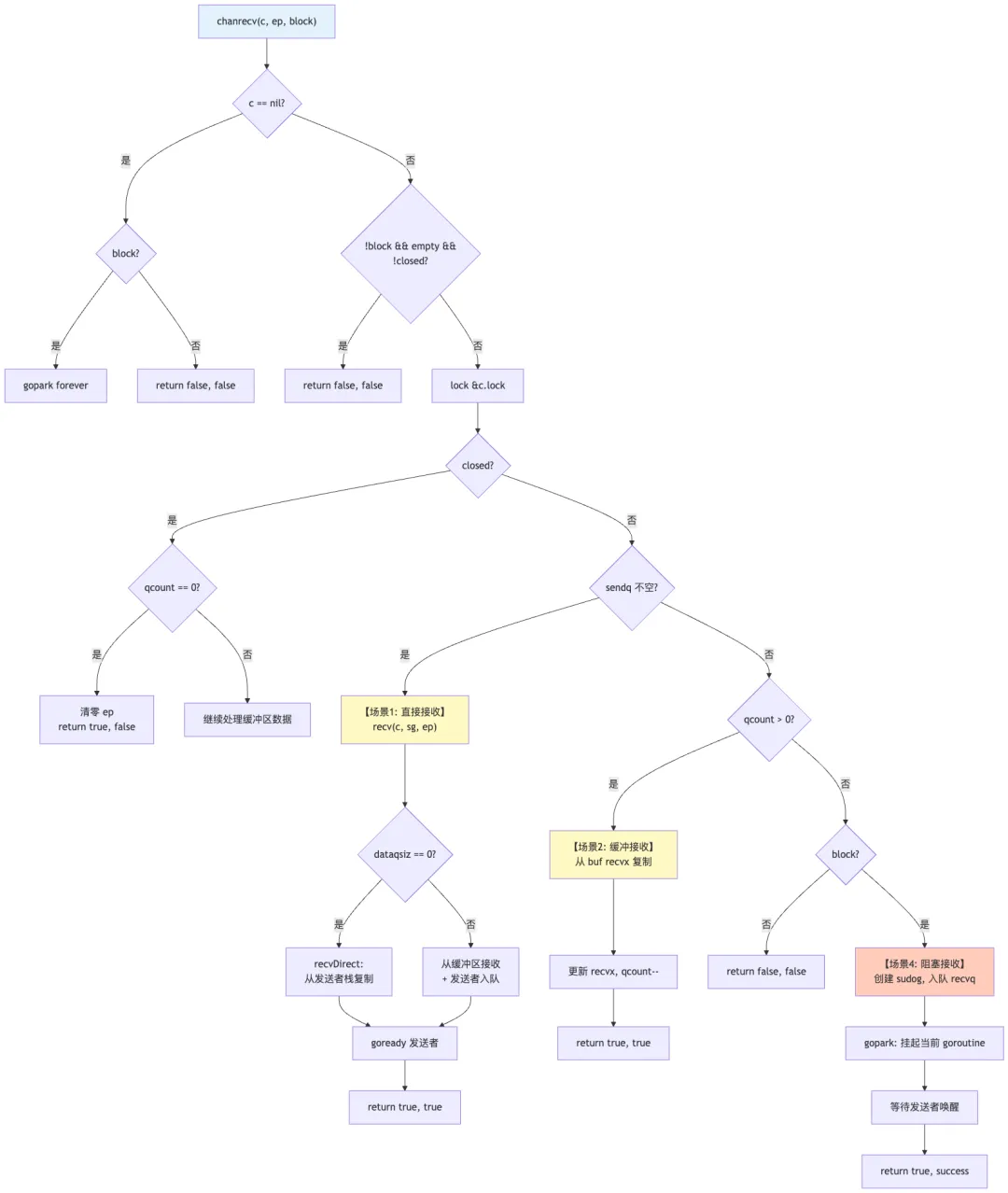
5.5 四种接收场景详解
场景 1:直接接收(有等待发送者)
if sg := c.sendq.dequeue(); sg != nil {
recv(c, sg, ep, func() { unlock(&c.lock) }, 3)
returntrue, true
}
-
无缓冲通道:直接从发送者的栈复制数据 -
有缓冲通道:从缓冲区接收数据,同时将发送者的数据放入缓冲区
场景 2:缓冲接收
if c.qcount > 0 {
qp := chanbuf(c, c.recvx)
if ep != nil {
typedmemmove(c.elemtype, ep, qp)
}
typedmemclr(c.elemtype, qp) // 清空槽位,帮助 GC
c.recvx++
if c.recvx == c.dataqsiz {
c.recvx = 0
}
c.qcount--
returntrue, true
}
场景 3:已关闭的空通道
if c.closed != 0 && c.qcount == 0 {
if ep != nil {
typedmemclr(c.elemtype, ep)
}
returntrue, false// received = false
}
返回 received = false 表示通道已关闭,没有接收到有效数据。
场景 4:阻塞接收
当没有发送者且缓冲区为空时,当前 goroutine 阻塞等待。
6. 关闭操作 – closechan()
6.1 完整源码
// runtime/chan.go:414-486
funcclosechan(c *hchan) {
if c == nil {
panic(plainError("close of nil channel"))
}
if c.bubble != nil && getg().bubble != c.bubble {
fatal("close of synctest channel from outside bubble")
}
lock(&c.lock)
if c.closed != 0 {
unlock(&c.lock)
panic(plainError("close of closed channel"))
}
if raceenabled {
callerpc := sys.GetCallerPC()
racewritepc(c.raceaddr(), callerpc, abi.FuncPCABIInternal(closechan))
racerelease(c.raceaddr())
}
c.closed = 1
var glist gList
// 释放所有接收者
for {
sg := c.recvq.dequeue()
if sg == nil {
break
}
if sg.elem != nil {
typedmemclr(c.elemtype, sg.elem)
sg.elem = nil
}
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
gp := sg.g
gp.param = unsafe.Pointer(sg)
sg.success = false// 接收失败
if raceenabled {
raceacquireg(gp, c.raceaddr())
}
glist.push(gp)
}
// 释放所有发送者(它们将 panic)
for {
sg := c.sendq.dequeue()
if sg == nil {
break
}
sg.elem = nil
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
gp := sg.g
gp.param = unsafe.Pointer(sg)
sg.success = false
if raceenabled {
raceacquireg(gp, c.raceaddr())
}
glist.push(gp)
}
unlock(&c.lock)
// 现在已经释放了通道锁,唤醒所有 goroutine
for !glist.empty() {
gp := glist.pop()
gp.schedlink = 0
goready(gp, 3)
}
}
6.2 关闭操作数据流图
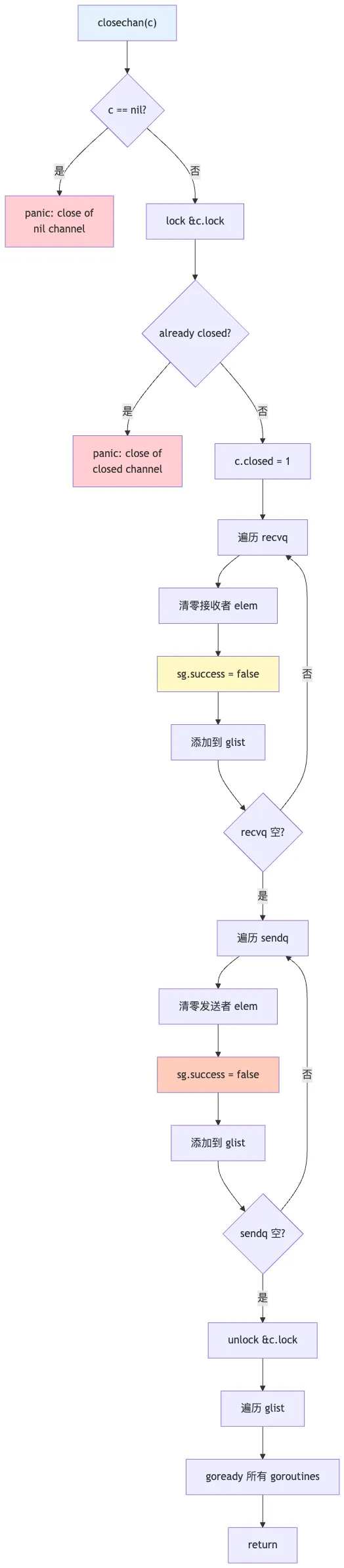
6.3 关闭行为详解
-
设置关闭标志: c.closed = 1 -
处理等待接收者: -
清零接收位置的数据 -
设置 success = false -
唤醒所有接收者 -
处理等待发送者: -
设置 success = false -
唤醒所有发送者(它们恢复后会 panic) -
批量唤醒:先收集所有等待的 goroutine,再统一唤醒
注意:释放锁后再唤醒 goroutine,避免死锁。
7. Select 语句实现
7.1 selectgo() 算法
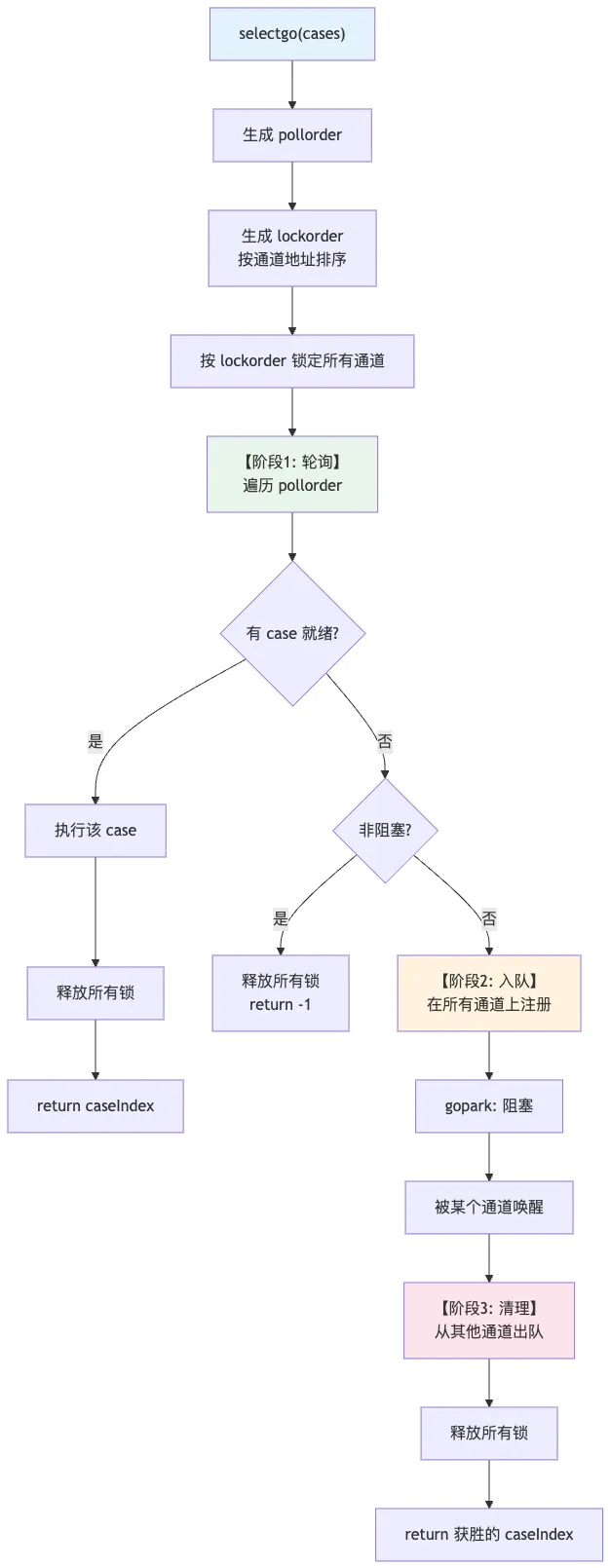
Select 语句通过 selectgo() 函数实现,使用三阶段算法:
阶段 1:轮询(Poll)
随机化轮询顺序,检查是否有 case 可以立即执行:
// 生成随机轮询顺序
for i := 0; i < ncases; i++ {
pollorder[i] = uint16(i)
}
shuffle(pollorder) // 随机化,防止饥饿
// 轮询所有 case
for _, casei := range pollorder {
cas = &scases[casei]
// 检查是否可以执行
}
阶段 2:入队(Enqueue)
如果没有 case 可以立即执行,将当前 goroutine 注册到所有相关通道的等待队列:
// 按地址顺序锁定所有通道(防止死锁)
for _, casei := range lockorder {
// 创建 sudog 并入队
}
// 挂起当前 goroutine
gopark(...)
阶段 3:清理(Dequeue)
被唤醒后,从其他通道的等待队列中移除自己:
// 从未选中的通道中出队
for _, casei := range lockorder {
if casei != casi {
// 从对应通道的等待队列中移除
}
}
7.2 Select 数据流图
7.3 防止死锁的锁排序
// 按通道地址排序,确保全局一致的锁顺序
sort.Slice(lockorder, func(i, j int)bool {
return scases[lockorder[i]].c < scases[lockorder[j]].c
})
这种设计确保了:
-
所有 goroutine 以相同的顺序获取多个通道的锁 -
避免循环等待条件 -
防止死锁
8. 循环缓冲区详解
8.1 索引管理
// 发送索引更新
c.sendx++
if c.sendx == c.dataqsiz {
c.sendx = 0// 循环回到开头
}
// 接收索引更新
c.recvx++
if c.recvx == c.dataqsiz {
c.recvx = 0// 循环回到开头
}
8.2 缓冲区内存布局
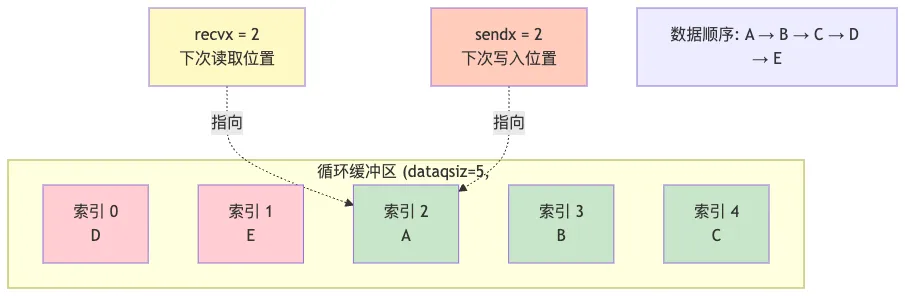
8.3 循环缓冲区的优势
-
无内存分配:初始化后不需要动态分配内存 -
O(1) 操作:发送和接收都是常数时间 -
缓存友好:连续内存访问模式 -
避免内存碎片:固定大小的连续内存块
9. 场景对比分析
9.1 有缓冲 vs 无缓冲通道
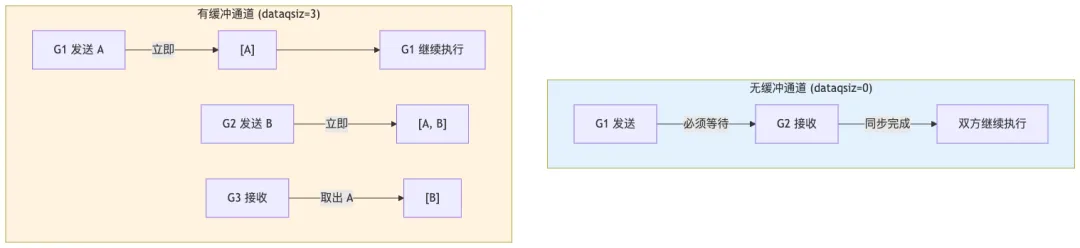
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
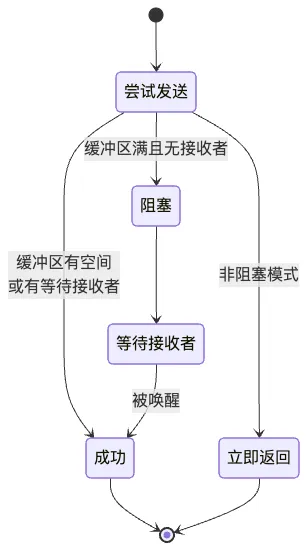
9.2 阻塞 vs 非阻塞操作
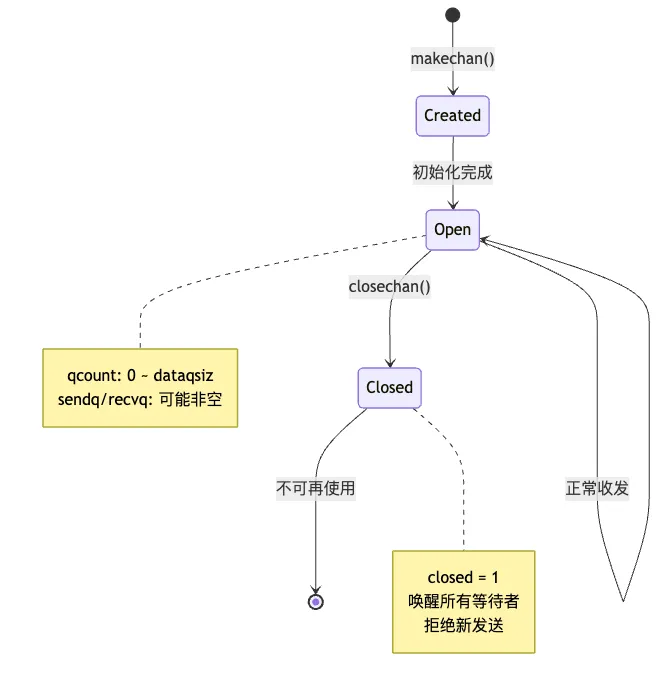
9.3 通道生命周期状态图
10. 总结
10.1 核心设计要点
-
循环缓冲区:高效的数据存储和访问 -
等待队列:管理阻塞的 goroutine -
直接传输:有等待者时绕过缓冲区,提高效率 -
锁策略:单一互斥锁保护所有字段 -
GC 友好:根据元素类型选择内存分配策略
10.2 性能特征
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
10.3 关键优化
-
快速路径检查:非阻塞操作在获取锁前检查条件 -
直接传输:避免不必要的缓冲区复制 -
Sudog 池化:复用 sudog 结构 -
批量唤醒:关闭时统一唤醒等待者 -
类型驱动的内存分配:根据元素是否包含指针选择分配策略 -
内存对齐优化:确保 hchan 和 buffer 正确对齐,提升访问效率
10.4 内存对齐与 GC 设计
内存对齐的重要性
通道实现中,内存对齐是确保正确性和性能的关键因素:
-
hchanSize 必须对齐到 maxAlign:确保结构体地址和后续 buffer 都正确对齐 -
元素对齐要求检查:防止元素类型对齐要求超过平台限制 -
原子操作依赖:mutex 等原子操作要求地址对齐才能正确工作 -
缓存友好性:对齐的数据访问效率更高,减少 cache miss
GC 友好的分配策略
Go 运行时根据元素类型智能选择内存分配策略:
无指针元素(单次分配):
-
减少 malloc 调用次数 -
提高缓存局部性(hchan 和 buffer 连续) -
GC 无需扫描 buffer(性能优势)
有指针元素(分离分配):
-
确保 GC 能正确扫描 buffer 中的指针 -
类型信息清晰,避免复合类型问题 -
保证写屏障正确性
设计哲学:正确性优先于性能。当 GC 正确性与性能冲突时,Go 运行时选择牺牲性能(多一次分配)来保证 GC 的正确工作。
10.5 最佳实践
-
根据场景选择通道类型:
-
需要强同步 → 无缓冲通道 -
需要解耦生产消费 → 有缓冲通道 -
避免通道泄漏:
-
及时关闭不再使用的通道 -
确保所有 goroutine 能正确退出 -
Select 中的 default:
-
用于非阻塞操作 -
注意避免 CPU 忙等待
Go 的通道实现展示了如何在保持简单 API 的同时,在底层实现复杂的并发原语。通过深入理解其源码,我们可以更好地使用通道,编写出高效、可靠的并发程序。
参考源码版本: Go 1.25.2源文件位置: runtime/chan.go, runtime/select.go, runtime/runtime2.go

