夜雨聆风
夜雨聆风





PG 中文分词插件 pg_jieba
一、pg_jieba 简介
1.1 什么是 pg_jieba
pg_jieba 是一个基于结巴分词(jieba)的 PostgreSQL 中文全文检索扩展插件。它将优秀的中文分词库 jieba 集成到 PostgreSQL 数据库中,为 PostgreSQL 提供了强大的中文分词和全文检索能力。
1.2 核心功能
-
中文分词:支持精确模式、全模式和搜索引擎模式三种分词方式 -
词性标注:可以对分词结果进行词性标注 -
自定义词典:支持用户自定义词典,提高特定领域的分词准确度 -
全文检索:与 PostgreSQL 的全文检索功能深度集成 -
高性能:基于 C++ 实现,性能优异
1.3 技术特点
-
基于前缀词典实现高效的词图扫描 -
生成句子中汉字所有可能成词情况所构成的有向无环图(DAG) -
采用动态规划查找最大概率路径 -
支持 HMM 模型处理未登录词
二、使用场景
2.1 典型应用场景
-
电商平台商品搜索
-
商品名称、描述的中文分词和检索 -
支持模糊搜索和同义词搜索 -
提升用户搜索体验 -
内容管理系统
-
文章、新闻的全文检索 -
标签提取和关键词分析 -
相关内容推荐 -
知识库系统
-
技术文档的智能检索 -
问答系统的语义匹配 -
知识图谱构建 -
日志分析系统
-
中文日志的分词和分析 -
异常信息提取 -
趋势分析
2.2 相比其他方案的优势
-
无需外部依赖:分词功能直接在数据库内完成,减少网络开销 -
事务一致性:分词和数据操作在同一事务中,保证数据一致性 -
简化架构:无需额外的搜索引擎服务(如 Elasticsearch) -
维护成本低:统一的数据库运维,降低系统复杂度
三、环境准备
3.1 当前环境信息
# PostgreSQL 版本
PostgreSQL 18.1
## 四、安装部署
### 4.1 下载源码
```bash
# 切换到工作目录
cd /tmp
# 下载 pg_jieba 源码
git clone https://github.com/jaiminpan/pg_jieba.git
# 进入源码目录
cd pg_jieba

`
4.2 编译安装
# 确保环境变量已设置
export PATH=/opt/pgsql/bin:$PATH
export PGHOME=/opt/pgsql
# 初始化子模块(包含 jieba 核心库)
git submodule update --init --recursive
# 创建编译目录
mkdir build
cd build
# 配置编译选项
cmake -DCMAKE_INSTALL_PREFIX=$PGHOME ..
# 编译(使用多核加速)
make -j4
# 安装
make install
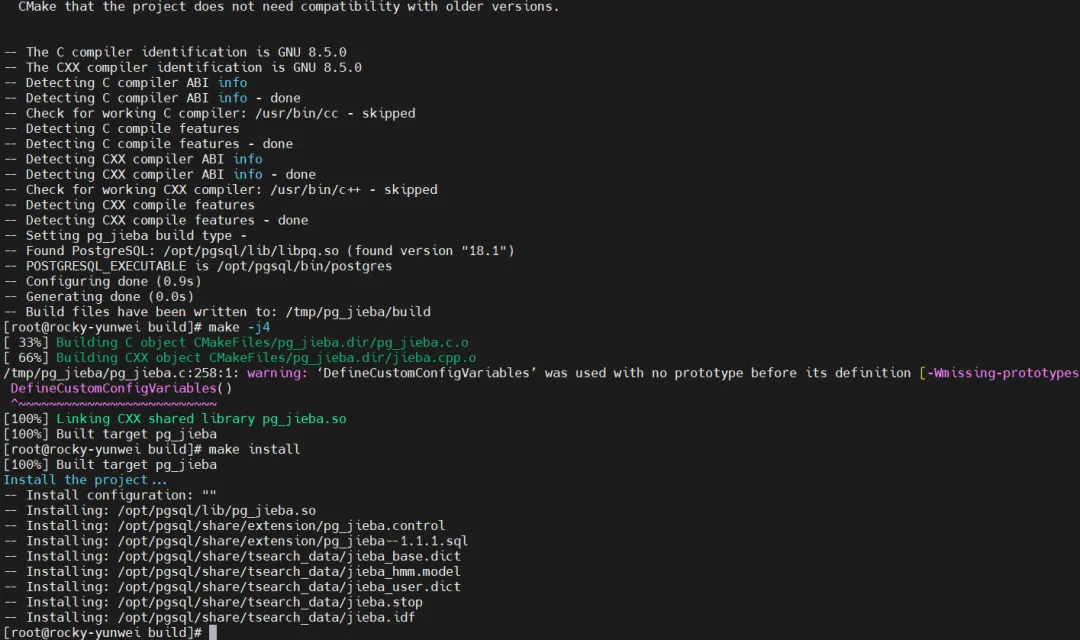
4.3 安装验证
# 检查插件文件是否安装成功
ls -lh $PGHOME/lib/pg_jieba.so
ls -lh $PGHOME/share/extension/pg_jieba*

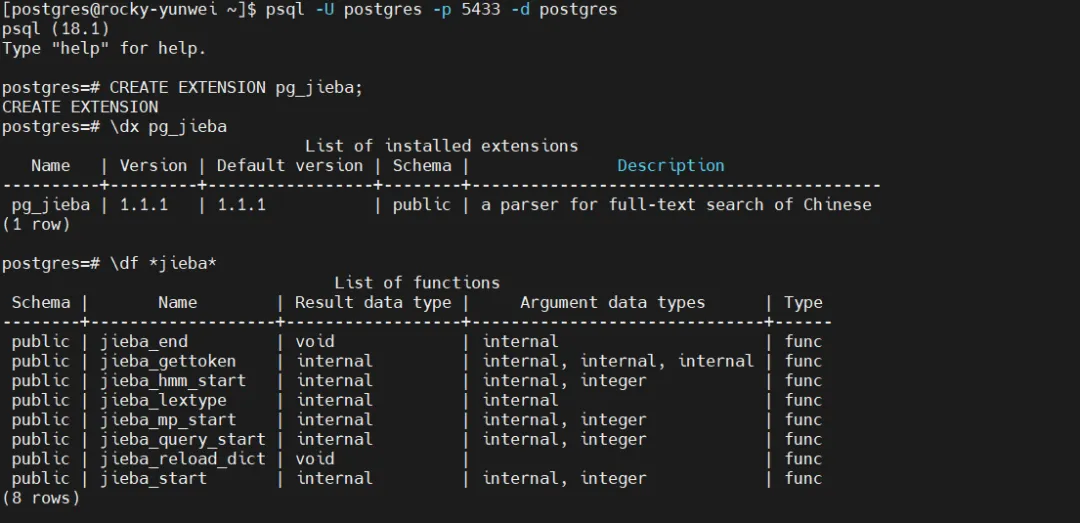
4.4 创建扩展
-- 连接到目标数据库
psql -U postgres -p 5433 -d postgres
-- 创建扩展
CREATE EXTENSION pg_jieba;
-- 验证扩展安装
\dx pg_jieba
-- 查看扩展提供的函数
\df *jieba*
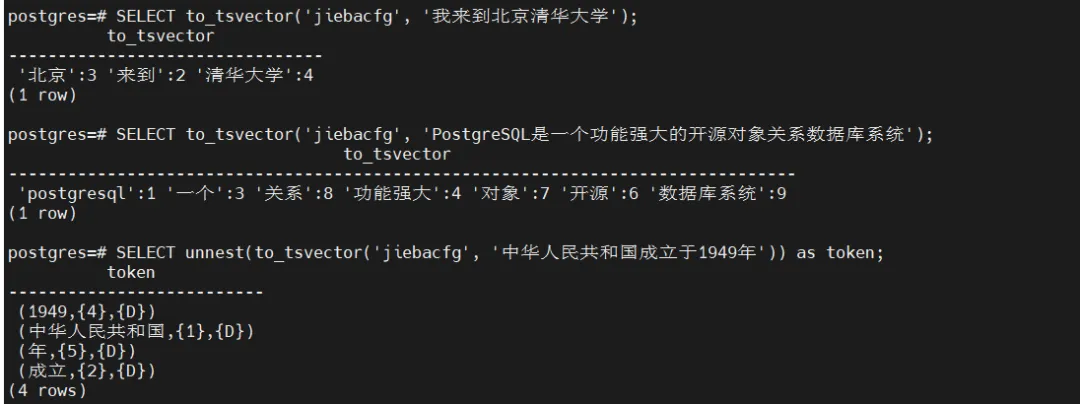
五、功能测试
5.1 基础分词测试
5.1.1 简单分词
-- 测试基本分词功能
SELECT to_tsvector('jiebacfg', '我来到北京清华大学');
-- 测试长文本分词
SELECT to_tsvector('jiebacfg', 'PostgreSQL是一个功能强大的开源对象关系数据库系统');
-- 查看详细分词结果
SELECTunnest(to_tsvector('jiebacfg', '中华人民共和国成立于1949年')) as token;
5.1.2 不同分词模式
-- 精确模式(默认)
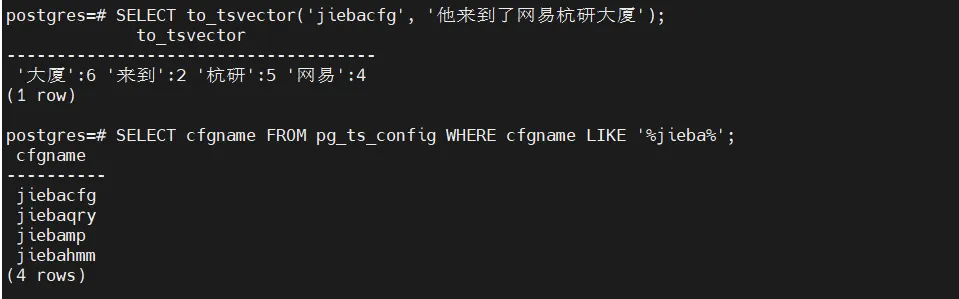
SELECT to_tsvector('jiebacfg', '他来到了网易杭研大厦');
-- 全模式需要通过配置参数调整(如果支持)
-- 查看可用的分词配置
SELECT cfgname FROM pg_ts_config WHERE cfgname LIKE'%jieba%';
5.2 全文检索测试
5.2.1 创建测试表
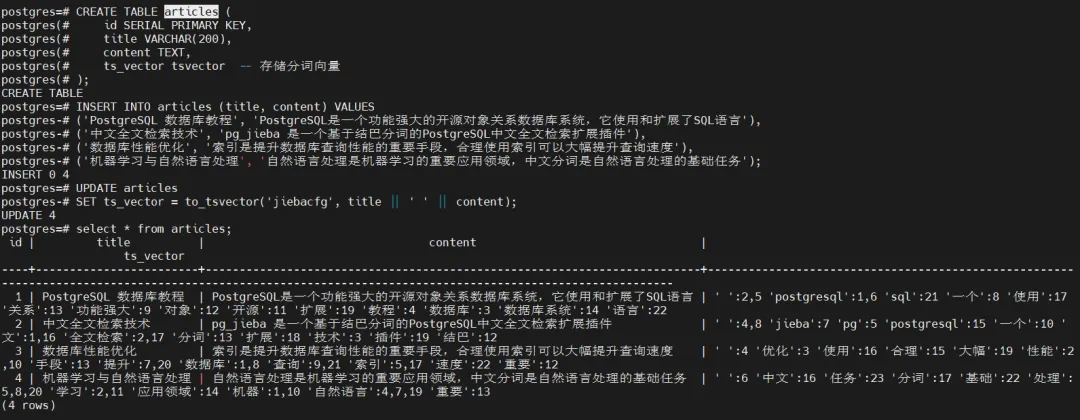
-- 创建测试表
CREATETABLE articles (
idSERIAL PRIMARY KEY,
title VARCHAR(200),
contentTEXT,
ts_vector tsvector -- 存储分词向量
);
-- 插入测试数据
INSERTINTO articles (title, content) VALUES
('PostgreSQL 数据库教程', 'PostgreSQL是一个功能强大的开源对象关系数据库系统,它使用和扩展了SQL语言'),
('中文全文检索技术', 'pg_jieba 是一个基于结巴分词的PostgreSQL中文全文检索扩展插件'),
('数据库性能优化', '索引是提升数据库查询性能的重要手段,合理使用索引可以大幅提升查询速度'),
('机器学习与自然语言处理', '自然语言处理是机器学习的重要应用领域,中文分词是自然语言处理的基础任务');
-- 更新 tsvector 字段
UPDATE articles
SET ts_vector = to_tsvector('jiebacfg', title || ' ' || content);
5.2.2 创建索引
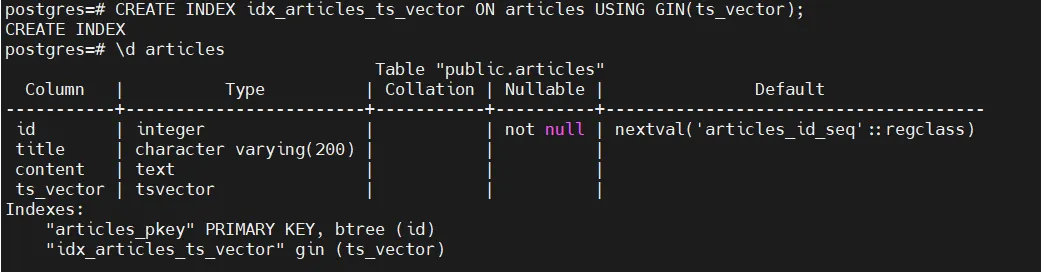
-- 创建 GIN 索引(推荐用于全文检索)
CREATEINDEX idx_articles_ts_vector ON articles USING GIN(ts_vector);
-- 查看索引信息
\d articles
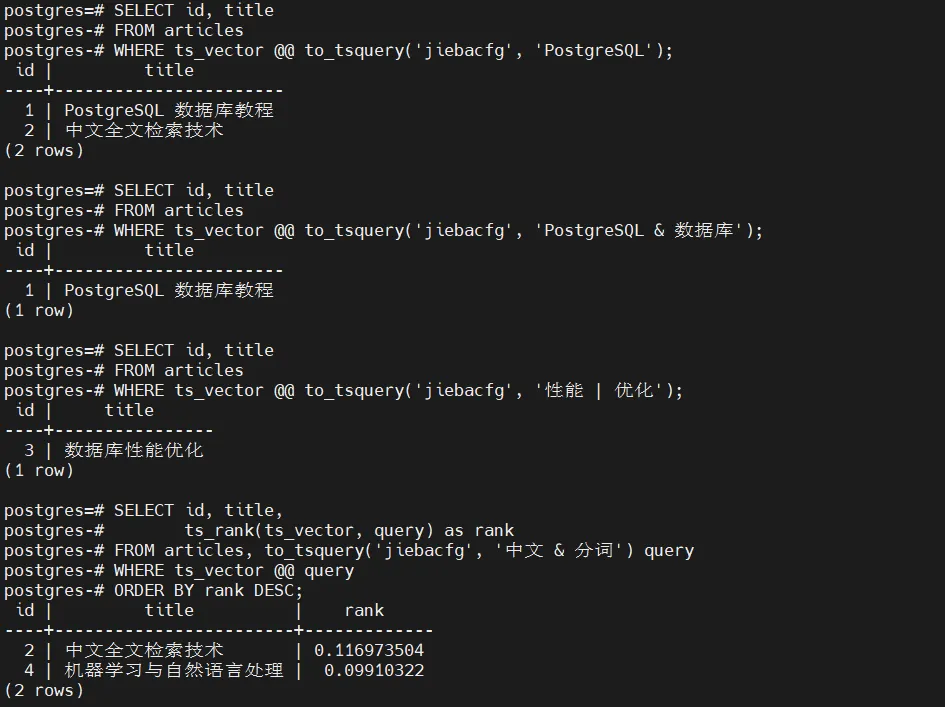
5.2.3 执行全文检索
-- 基础检索
SELECTid, title
FROM articles
WHERE ts_vector @@ to_tsquery('jiebacfg', 'PostgreSQL');
-- 多关键词检索(与)
SELECTid, title
FROM articles
WHERE ts_vector @@ to_tsquery('jiebacfg', 'PostgreSQL & 数据库');
-- 多关键词检索(或)
SELECTid, title
FROM articles
WHERE ts_vector @@ to_tsquery('jiebacfg', '性能 | 优化');
-- 带排名的检索
SELECTid, title,
ts_rank(ts_vector, query) asrank
FROM articles, to_tsquery('jiebacfg', '中文 & 分词') query
WHERE ts_vector @@ query
ORDERBYrankDESC;