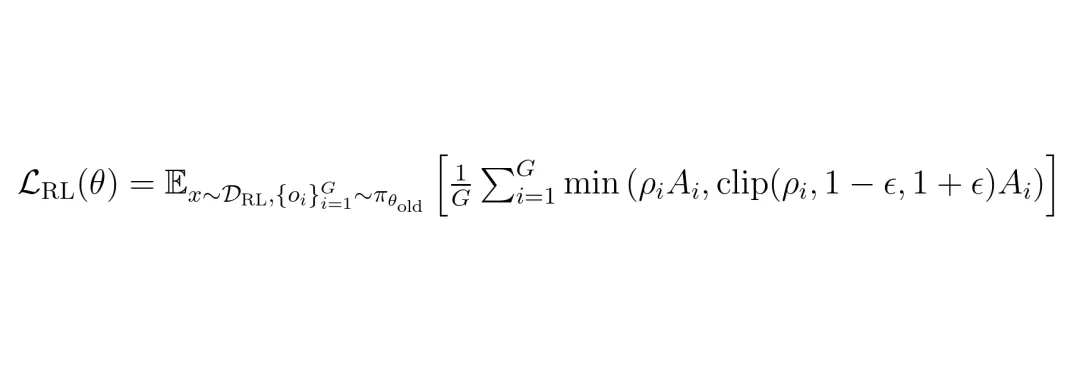辞旧迎新,知识续航!「龙哥读论文」陪你跨年,知识星球会员优惠券限时限量放送!
🐉 「龙哥读论文」知识星球:让你看论文像刷视频一样简单!公众号每日8篇拆解不够看?星球无上限更AI领域论文、资讯、招聘、招博、开源代码,一站式干货,每日2分钟刷完即赚!👇扫码加入「龙哥读论文」知识星球,领取优惠,前沿干货、实用资源一站式拿捏~

龙哥推荐理由:
这篇论文提出了一个非常实用的“大一统”OCR思路。过去,识别文档文字和解析图表网页是两套完全不同的系统,而美团团队用一个轻量级模型就搞定了,还达到了媲美大模型的性能。其“先混合学,再分头练”的两阶段训练策略,巧妙解决了多任务冲突,对做多模态融合的同学很有启发。无论是想了解前沿OCR技术,还是学习如何高效训练多领域模型,这篇都值得一读。
原论文信息如下:
论文标题:
OCRVerse: Towards Holistic OCR in End-to-End Vision-Language Models
发表日期:
2026年01月
发表单位:
Meituan (美团)
原文链接:
https://arxiv.org/pdf/2601.21639v2.pdf
OCR新范式:文本与视觉的统一解读
想象一下这个场景:你的AI助手可以轻松识别你手机拍下的纸质文档,将文字一字不差地提取出来。但是,当你丢给它一张复杂的业务报表、一个科技网站的截图,或是一张化学结构式图片时,它可能就傻眼了,只能认出里面的零星文字,对图表的结构、网页的布局、分子式的连接关系完全“视而不见”。
这就是传统OCR(光学字符识别,Optical Character Recognition)的局限性。长久以来,OCR技术主要聚焦于从图像或扫描文档中提取文本,我们称之为文本中心OCR。但对于那些充满视觉信息密度的图像——比如图表、网页、科学插图等,光认出字是远远不够的。我们需要理解箭头、线条、图例等视觉元素所构建的语义结构,并将它们转换成可编辑、可计算的代码级表示,比如HTML、Python图表代码、LaTeX公式等。这项任务,被称为视觉中心OCR。
过去,这两项任务通常由不同的、专门化的系统来处理。而美团的这篇论文《OCRVerse》提出一个大胆的想法:为什么不造一个“大一统”的模型,让它既能读懂文字,又能看懂图表呢?
OCRVerse正是这个想法的实践。它首次以端到端的方式,将文本中心OCR与视觉中心OCR统一在一个轻量级的视觉-语言模型中,实现了所谓的整体OCR(Holistic OCR)。
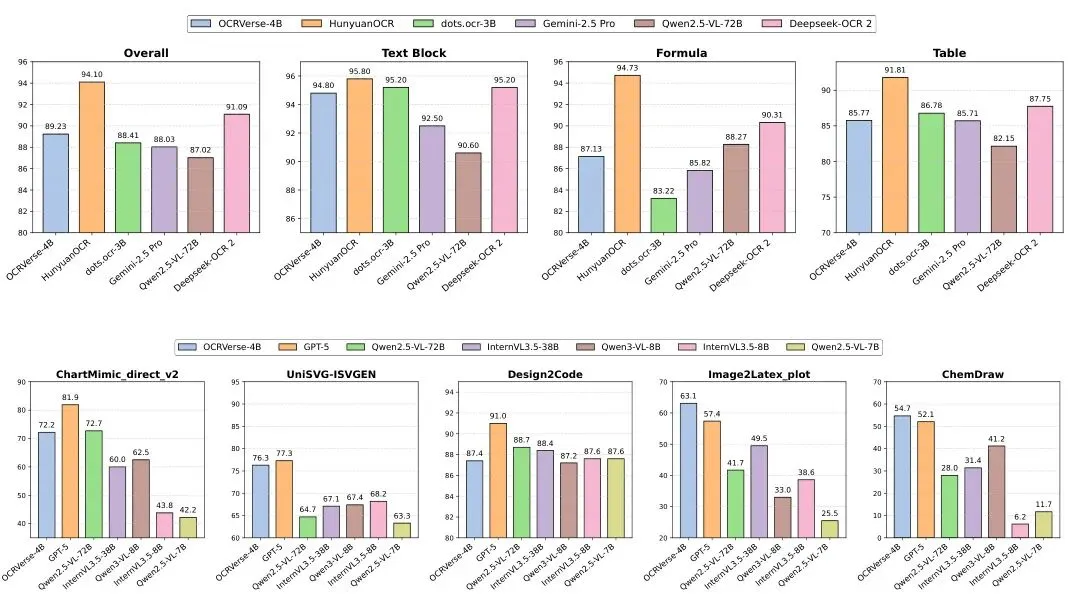 图1:OCRVerse在文本中心OCR任务(上行)和视觉中心OCR任务(下行)上的性能对比。
图1:OCRVerse在文本中心OCR任务(上行)和视觉中心OCR任务(下行)上的性能对比。
从上图的展示可以看出,无论是识别文档中的文字、表格,还是将图表还原成代码,OCRVerse都表现得有模有样。它就像一个刚毕业的通才实习生,文档处理、图表分析都能上手,虽然不一定每项都是世界冠军,但胜在全面和高效。😏
数据为王:构建覆盖八大赛道的训练宝库
要训练一个“全才”模型,首先得给它喂各种各样的“粮食”。OCRVerse的数据工程堪称浩大,覆盖了多达八种数据域,分为两大类:
图2:OCRVerse用于整体OCR的全面数据覆盖。左侧(文本中心数据):包括自然场景、书籍、杂志、论文、报告、幻灯片、试卷、笔记和报纸九种文档场景。右侧(视觉中心数据):包括图表、网页、图标、几何图形、电路和分子六种专业场景。
文本中心数据(九种场景):涵盖了日常生活中高频出现的文本场景。从街头的自然场景文字、标准的书籍杂志,到结构严谨的学术论文、报告、幻灯片,再到风格各异的试卷、手写笔记和报纸。目标是让模型熟悉各种排版、字体和布局。
视觉中心数据(六种场景):这是传统OCR的盲区,也是OCRVerse的亮点。包括需要转换成代码的图表(柱状图、折线图等)、网页(需还原为HTML)、抽象的图标、几何图形、电路图和分子结构式。这些数据要求模型不仅“看见”,更要“理解”并“转译”其结构。
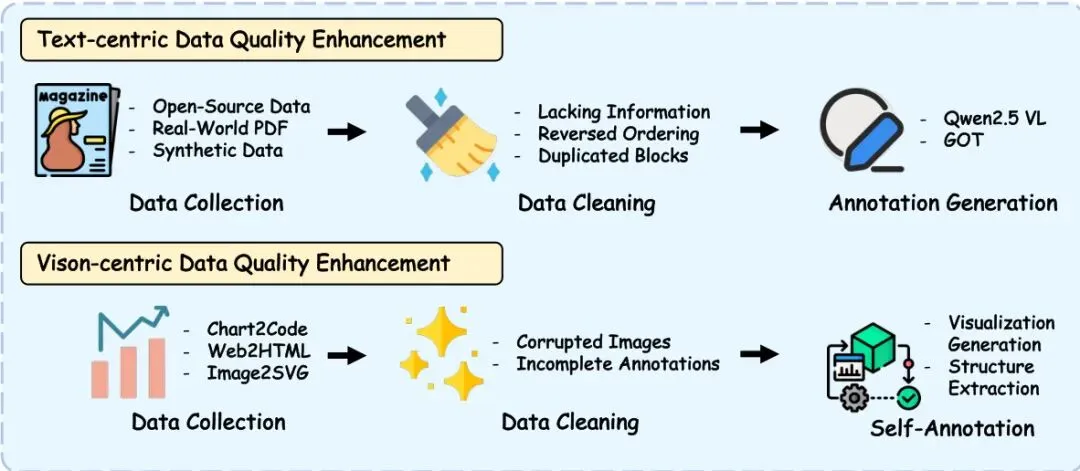 图3:集成文本中心和视觉中心来源的多阶段数据构建流程。
图3:集成文本中心和视觉中心来源的多阶段数据构建流程。
这些数据并非简单收集而来,而是经过了一套精密的“加工流水线”。如图3所示,对于文本数据,团队整合了开源数据集、真实PDF和合成数据,并通过清洗和基于大模型的重新标注来提升质量。对于视觉数据,则从图表、网页等源头收集,进行质量过滤,并通过可视化渲染和结构提取来生成高质量的“图像-代码”配对标注。
这个覆盖文本与视觉、横跨十五种具体场景的庞大数据宝库,是OCRVerse能够“见多识广”的基石。
两阶段训练秘诀:SFT打基础,RL精调优
有了海量数据,如何高效地教给模型是另一个核心挑战。直接把所有数据混在一起训练行吗?可能会“打架”——学习网页布局的规则可能会干扰识别数学公式的准确性。
OCRVerse的解决方案非常巧妙:分两步走,先“混合通识教育”,再“分科强化训练”。这就是其核心的两阶段 SFT-RL 多域训练方法。
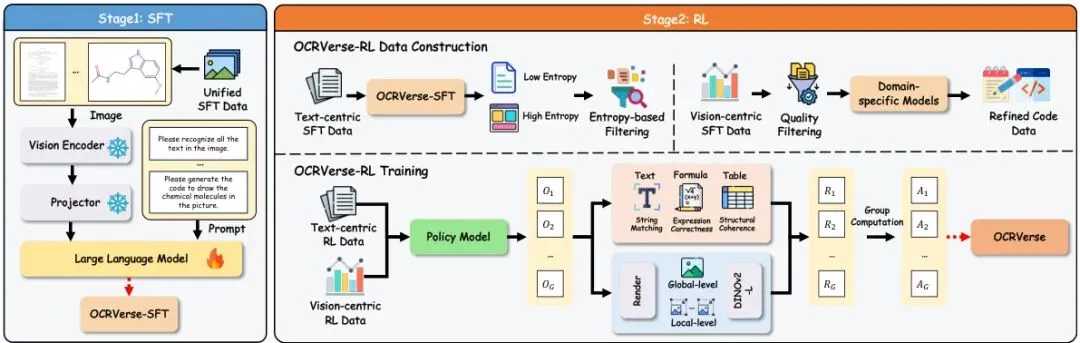 图4:OCRVerse训练流程。阶段1:使用统一的跨域数据进行SFT。阶段2:使用领域特定数据构建和个性化奖励机制进行RL,针对文本中心(基于规则)和视觉中心(视觉保真度)进行优化。
图4:OCRVerse训练流程。阶段1:使用统一的跨域数据进行SFT。阶段2:使用领域特定数据构建和个性化奖励机制进行RL,针对文本中心(基于规则)和视觉中心(视觉保真度)进行优化。
这个阶段的目标是让模型“开眼看世界”。团队以Qwen3-VL-4B这个轻量但性能不错的视觉-语言模型为基础,将八个域的所有数据直接混合进行训练。
训练的目标函数是标准的自回归语言建模损失,即让模型根据之前的文字和输入的图像,预测下一个词的概率,并最大化正确序列的概率。
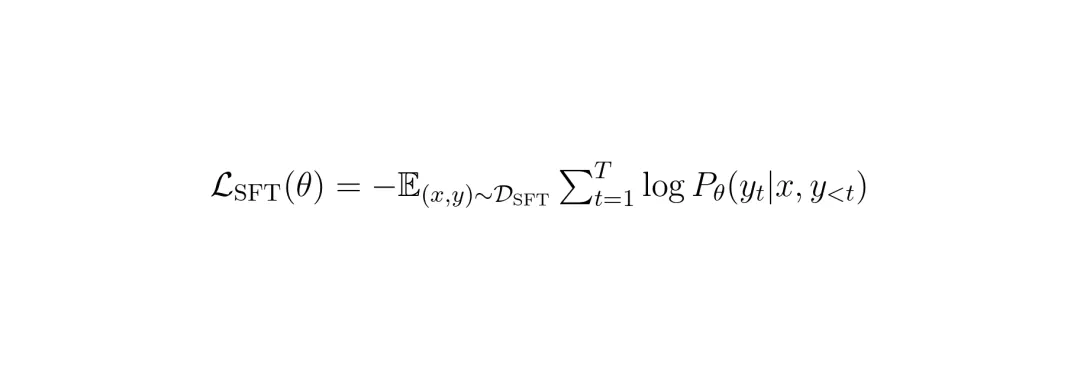
公式1:SFT阶段的训练损失函数。其中x是输入图像,y是目标输出序列,θ是模型参数。
通过这种“大杂烩”式的学习,模型初步建立了对各种视觉模式和输出格式的理解,形成了一个统一的表征空间。但此时它可能还是个“博而不精”的泛泛之辈。
这是论文最具创新性的部分。SFT之后,模型虽然啥都见过,但不同任务的要求截然不同:识别普通文本要求一字不差;还原表格要求结构严谨;生成图表代码则要求渲染出来的图像和原图越像越好。
于是,OCRVerse在RL阶段为不同域设计了个性化的奖励策略,相当于给不同科目的学生请了不同的家教:
文本中心域奖励(基于规则):采用非常直观的度量。对于普通文本,用编辑距离(需要修改多少字符才能匹配正确答案)来打分,错得越少分越高。对于公式,用归一化后的BLEU分数(一种衡量机器翻译质量的指标)评估。对于表格,则用专门的TEDS-S分数(评估表格结构相似度)来评判。
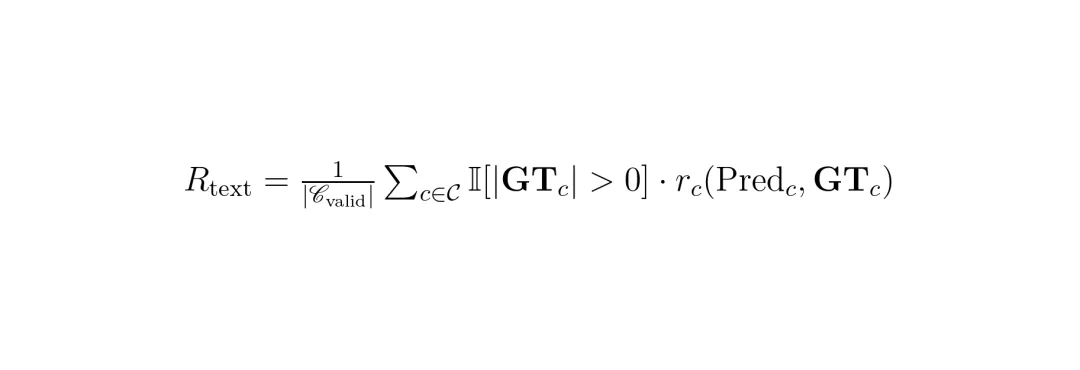
公式2:文本中心域的总体奖励计算方式,综合了不同类型内容(c)的特定奖励函数。
视觉中心域奖励(视觉保真度):这里的核心思想是“不看广告看疗效”。模型生成代码后,用代码渲染(画)出一张新图,然后对比新图和原始输入图的相似度。团队使用强大的DINOv2视觉编码器提取图像特征,计算它们之间的余弦相似度作为奖励。为了兼顾整体和细节,还采用了多尺度奖励(全局缩略图相似度 + 局部图像块相似度)。
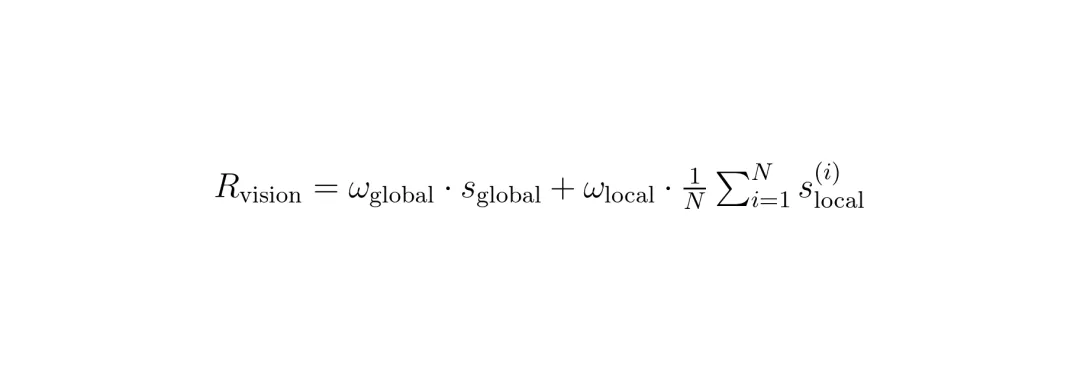
公式3:视觉中心域的奖励计算,结合了全局和局部的视觉相似度。
在优化策略上,论文采用了GRPO(Group Relative Policy Optimization,组相对策略优化,引用自[66])。简单理解,它不是让模型去追求一个绝对的分数,而是在同一组生成的多个结果中比较,鼓励模型产生比同组其他结果更好的输出。这种方式更稳定,避免了奖励尺度不一带来的问题。
通过这种“先通识,后专精”的两阶段策略,OCRVerse巧妙地平衡了跨域统一学习与域内性能优化的矛盾,让一个模型真正掌握了多项技能。
以小搏大:4B参数挑战巨头,多项任务表现亮眼
OCRVerse的模型本身是基于Qwen3-VL-4B的,这意味着它只有40亿参数。在今天动辄百亿、千亿参数的大模型时代,这绝对算是个“小模型”。那么,它的实际表现如何?能跟那些“巨无霸”们掰手腕吗?
实验给出了令人印象深刻的答案。论文在两个维度进行了全面评测:文本中心OCR和视觉中心OCR。
在权威的文档理解基准OmniDocBench v1.5上,OCRVerse与众多专业OCR模型和通用大模型同台竞技。
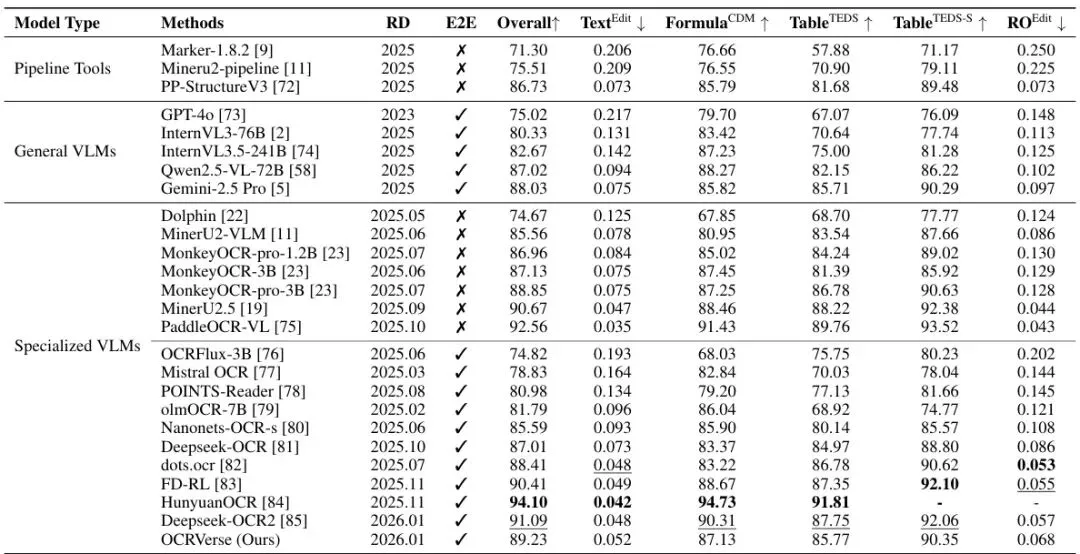
表1:在OmniDocBench v1.5上的性能对比。加粗和下划线分别表示端到端专用VLM中的最佳和次佳性能。RD:发布日期,E2E:端到端(✓)或基于流水线(X),RO:阅读顺序。
从表1可以看到,OCRVerse的综合得分(Overall)达到了89.23。这个成绩在所有端到端的专用视觉-语言模型(VLM)中排名第一,甚至超过了参数量大得多的DeepSeek-OCR(77B)和GOT-OCR(?B)。虽然相较于一些结合了传统OCR流水线的混合方法(如MinerU 2.5)仍有差距,但考虑到OCRVerse是纯粹的端到端模型,且参数量极小,这个表现已经足够亮眼。
特别值得注意的是,它在表格识别(Table)和公式识别(Formula)这两个极具挑战性的任务上,在端到端模型中同样名列前茅,显示了其强大的结构化内容理解能力。
在视觉中心任务上,由于没有专门做“整体OCR”的模型,论文主要将OCRVerse与各种通用多模态大模型进行对比,评估其将图像转换为代码的能力。
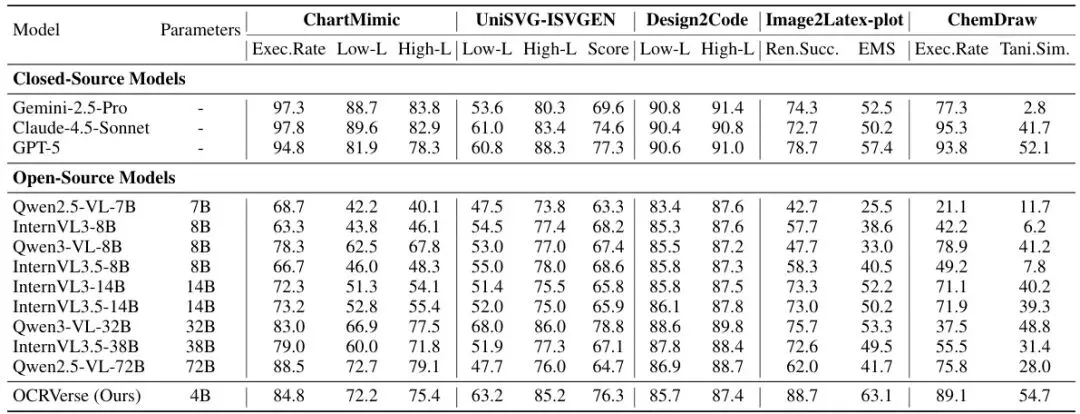
表2:在多模态代码生成基准上,OCRVerse与各种基线模型的评估结果对比。
从表2的结果来看,OCRVerse在图表到代码(Chart)、网页到HTML(Webpage)等任务上,与当前一些优秀的开源模型(如CogAgent、Qwen2.5-VL)相比,表现相当或具有竞争力。考虑到它同时还要兼顾文本识别任务,这个结果证明了其多任务学习策略的有效性。
总的来说,OCRVerse用一个4B的“小身板”,在文本和视觉两大类、共计八个赛道的任务中,取得了全面且具竞争力的成绩,真正实现了“小而全,小而强”的设计目标。
未来展望:布局感知与复杂表格的突破
OCRVerse已经迈出了“整体OCR”坚实的第一步,但论文也坦诚地指出了当前模型的局限性与未来的改进方向。
1. 复杂的布局理解:对于阅读顺序混乱、元素重叠严重的文档(比如某些杂志或宣传单),纯端到端的模型容易产生“幻觉”,出现内容错序或遗漏。未来的工作需要考虑显式地引入布局感知模块,例如将传统的版面分析技术以某种形式与大模型的语义理解能力更深度地结合,以提升在处理复杂文档时的稳定性和准确性。
2. 高度复杂表格的解析:虽然OCRVerse在表格识别上表现不错,但对于包含合并单元格、嵌套表头、大量空白等极端情况的复杂表格,其性能仍有提升空间。这可能需要设计更精细的表格结构建模方法和更强大的训练数据。
此外,将模型的能力扩展到更多视觉中心领域(如工程图纸、思维导图等),以及探索更高效的多模态融合与压缩技术,以进一步降低模型计算开销,都是值得探索的方向。
OCRVerse为我们描绘了一个未来:一个轻量的、统一的模型,可以像瑞士军刀一样,处理我们遇到的各种各样的图文信息提取任务。从扫描文档到网页截图,从数据图表到专业图纸,AI都能“一眼看懂”,并给出结构化的结果。这无疑是通往更智能、更便捷的人机交互道路上的一块重要基石。🚀
龙迷三问
这篇论文解决的核心问题是什么?这篇论文解决的是传统OCR(光学字符识别)技术只能识别文字,无法理解图表、网页等视觉信息密集图片的问题。它提出了一个名为OCRVerse的“整体OCR”模型,首次用一个统一的、端到端的轻量级模型,同时搞定文本识别(如文档文字、表格、公式)和视觉信息转译(如图表转代码、网页转HTML)两大类任务。
文中的SFT和RL阶段分别是什么意思?SFT(Supervised Fine-Tuning,监督微调)和RL(Reinforcement Learning,强化学习)是训练模型的两个阶段。SFT阶段就像“通识教育”,把所有类型的数据混在一起让模型学习,建立广泛的知识基础。RL阶段则像“分科强化训练”,针对不同任务(如识别文本、生成图表代码)设计不同的评分标准(奖励),引导模型在通用基础上,把每一项专业技能都打磨得更精。
OCR是什么?OCR是光学字符识别(Optical Character Recognition)的缩写。它是一种技术,可以让计算机“看懂”图片或扫描件中的文字,并将其转换为可编辑、可搜索的文本数据。比如你用手机扫描纸质文件转换成Word文档,背后就用到了OCR技术。本篇论文将OCR的概念扩展到了不仅识别文字,还能理解并转换图片中的视觉结构信息。
如果你还有哪些想要了解的,欢迎在评论区留言或者讨论~
龙哥点评
论文创新性分数:★★★★☆
提出“整体OCR”的统一框架,并设计了两阶段SFT-RL多域训练策略来解决任务冲突,思路清晰且有创新性。
实验合理度:★★★★☆
评测维度全面,覆盖了文本和视觉两大类主流基准,并与专用模型和通用大模型进行了充分对比。实验设计能有效支撑其“全面且具竞争力”的结论。
学术研究价值:★★★★☆
为多模态理解中的“统一多任务学习”提供了一个优秀范本。其数据处理、多域奖励设计等具体方法,对后续相关研究有很强的启发和参考价值。
稳定性:★★★☆☆
作为纯端到端模型,在处理布局极其复杂或质量较差的输入时,可能仍会出现幻觉和错误,稳定性不如结合了传统OCR流水线的混合方法。
适应性以及泛化能力:★★★★☆
覆盖了多达八个数据域,展示了强大的跨域适应能力。对于训练数据分布内的类似任务,应具备良好的泛化性。
硬件需求及成本:★★★★★
基于4B参数的轻量模型,推理成本低,易于部署,这是其最突出的优势之一,非常适合实际应用落地。
复现难度:★★☆☆☆
虽然方法描述清晰,但构建其涵盖十五种场景的高质量、大规模训练数据集需要巨大的工程投入和资源,个人或小团队极难复现。
产品化成熟度:★★★☆☆
在文档质量较好、布局标准的场景下已具备实用价值。但对于复杂、非标场景,仍需与传统方法结合或进一步优化以提升鲁棒性,方可大规模产品化。
可能的问题:论文本身是一篇扎实的技术报告,工程价值显著。若以顶会论文标准衡量,在核心方法原理的深度创新(如新的网络结构、理论突破)上稍显不足,更多是工程整合与策略设计的优秀实践。
[1] Liu, H., Li, C., Wu, Q., & Lee, Y. J. (2024). Visual instruction tuning. NeurIPS.
[29] Bai, J., et al. (2024). Qwen2.5-VL: A versatile vision-language model for understanding and generation. arXiv preprint.
[30] Yao, S., et al. (2024). OmniDocBench: A benchmark for unified document understanding. arXiv preprint.
[66] Yuan, Z., et al. (2024). Group relative policy optimization for efficient RLHF. ICLR.
(注:以上为论文中引用的部分代表性文献,完整列表请参阅原论文。)
*本文仅代表个人理解及观点,不构成任何论文审核或者项目落地推荐意见,具体以相关组织评审结果为准。欢迎就论文内容交流探讨,理性发言哦~ 想了解更多原文细节的小伙伴,可以点击左下角的“阅读原文”,查看更多原论文细节哦!

还在为看不懂复杂的图表和网页结构而烦恼吗?🤔 想和更多AI视觉大牛交流OCR的黑科技吗?欢迎加入龙哥读论文粉丝群,
扫描下方二维码或者添加龙哥助手微信号加群:kangjinlonghelper。
一定要备注:研究方向+地点+学校/公司+昵称(如 图像处理+上海+清华+龙哥),根据格式备注,可更快被通过且邀请进群。一起探讨如何让AI“看懂”世界!


 夜雨聆风
夜雨聆风