 夜雨聆风
夜雨聆风





外贸人宝藏插件之Instant Date Scraper
Instant Date Scraper
推荐一个外贸业务员开发客户超好用的谷歌浏览器插件,个人使用下来觉得只有刚开始用确实需要熟悉一下,然后就越用越顺手
我把新手在插件使用过程中的可能遇到的问题和解决方法都放在文章末尾,希望能帮助大家少走弯路,快速上手
安装步骤:
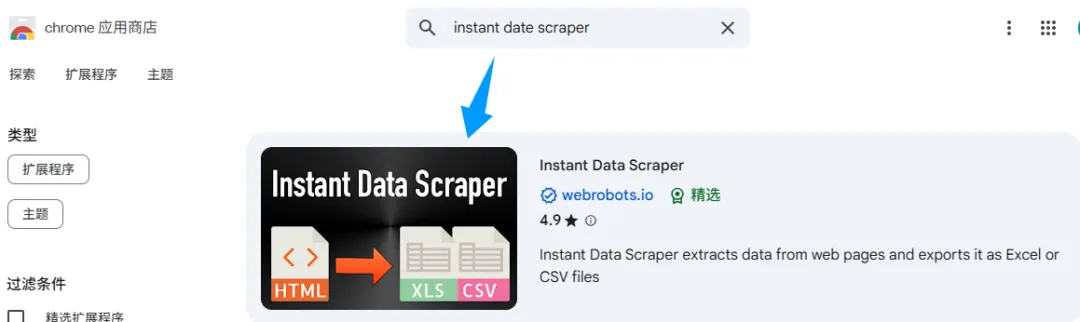
1.打开谷歌浏览器,进入Chrome应用商店
2.搜索“Instant Data Scraper”,会出现下面这个界面,这个就是我们要的插件
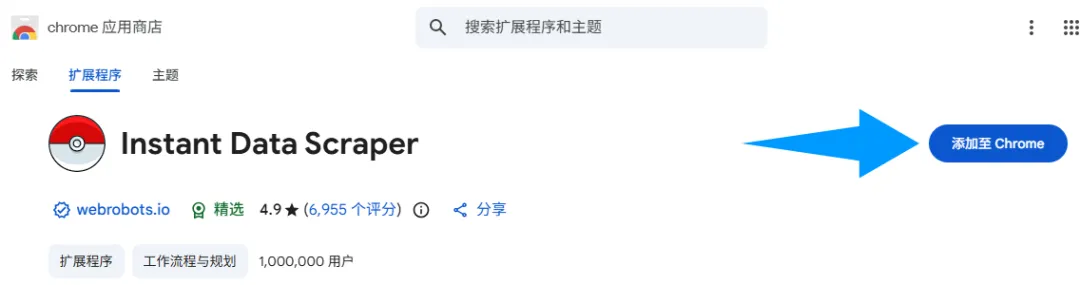
3.点进去跳转至添加界面,点击“添加至Chrome”
4.安装完成后点亮图钉将插件固定在导航栏方便使用
抓取数据:
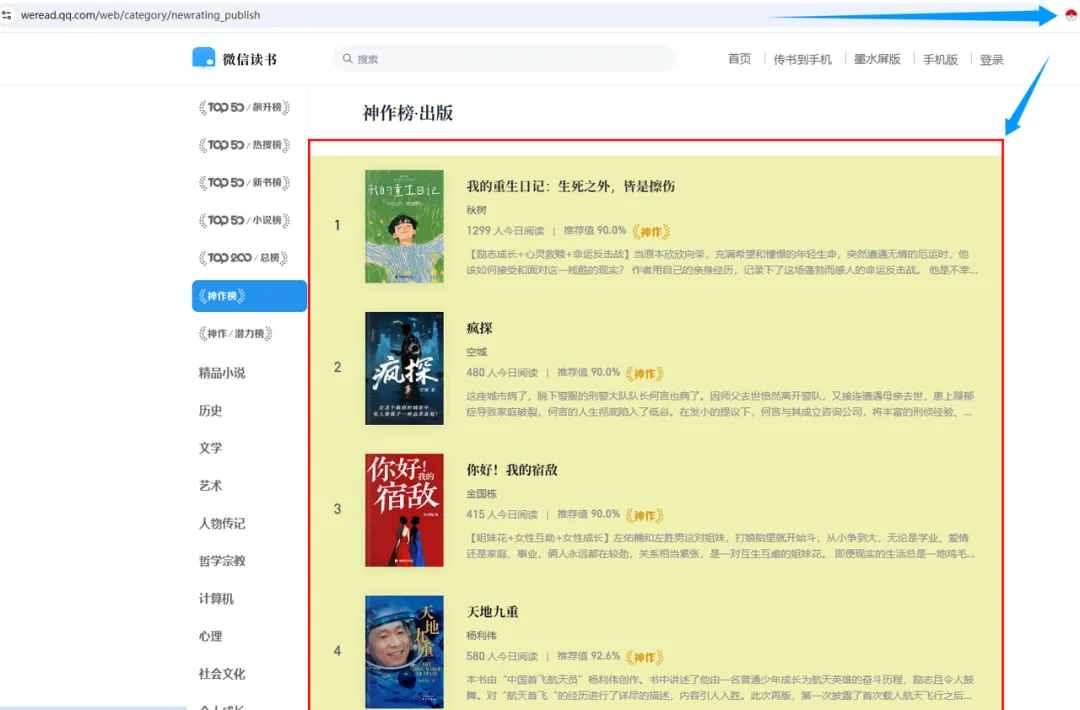
1.打开要抓取数据的网页:以微信读书榜为例
https://weread.qq.com/web/category/newrating_publish
2.点击网页右上角拓展程序固定栏“Instant Data Scraper”图标,界面会发生两个变化
a.跳出抓取数据设置界面(这个界面不会显示在网页表面,需要缩小网页或者alt+tab键切换窗口)
b.同时网页界面上被选中的区域变成红线框+黄底
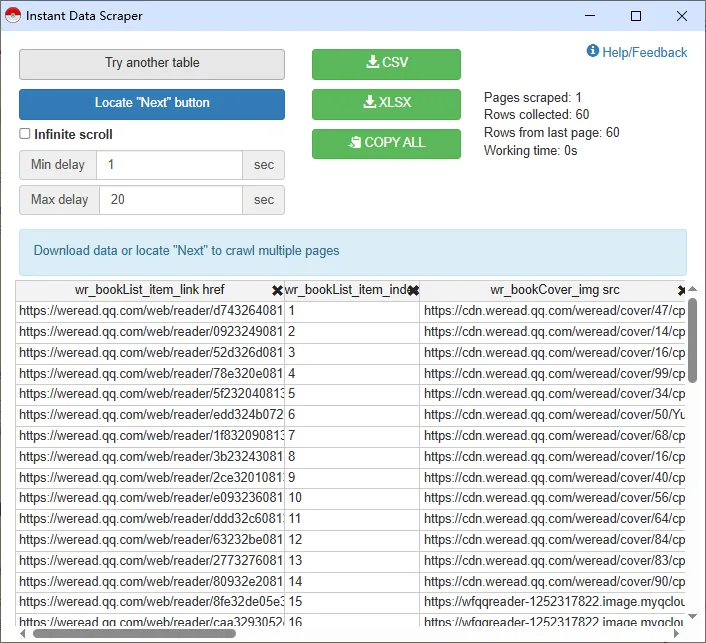
3.可以试着多用一下每个按钮,比如 “try another table”,可以看到被选中的区域变成了如图所示左边侧边栏。因此,如果系统自动选中的区域不是自己想要的,可以通过这个按钮切换抓取区域直到抓取到我们需要的区域
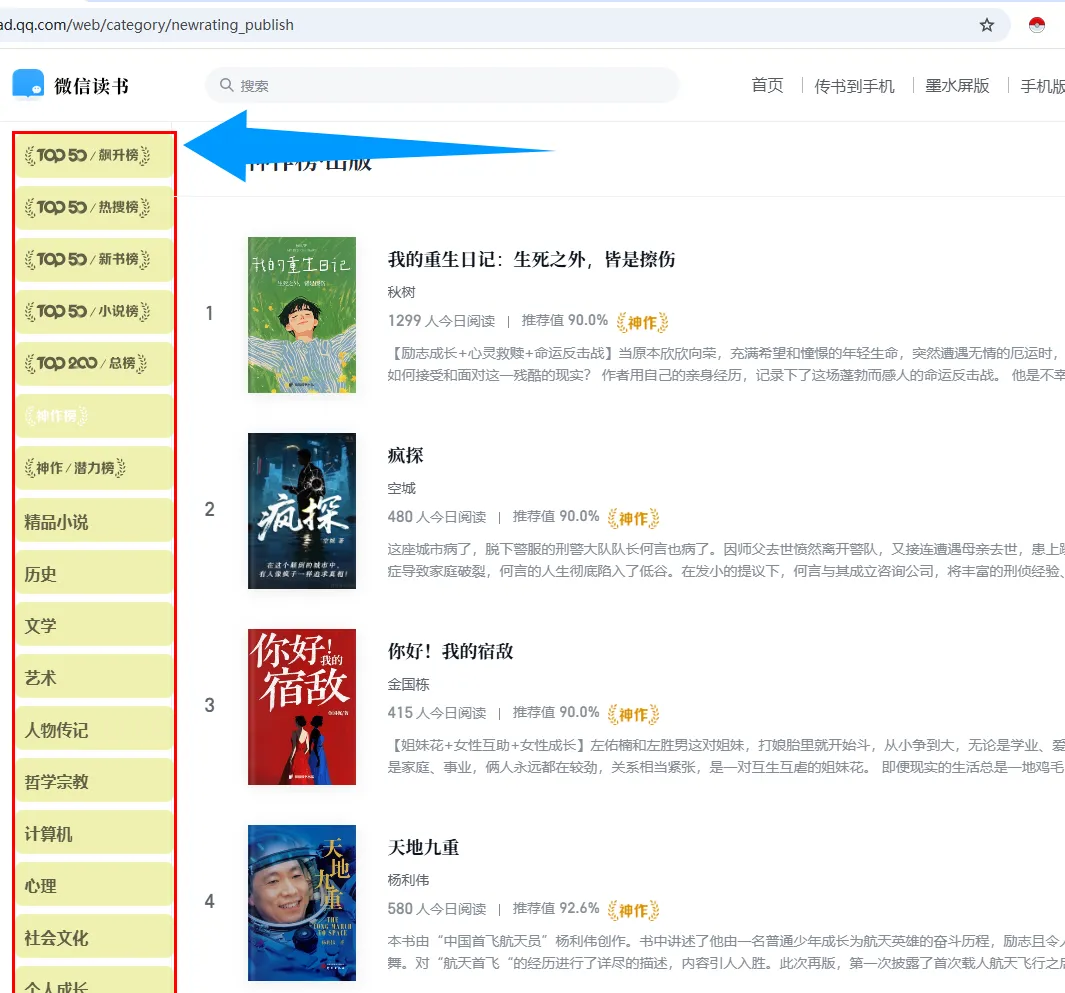
4.切换回我们要抓取的书单界面,点击“Locate Next button” ,在网页界面定位到“下一页”按钮
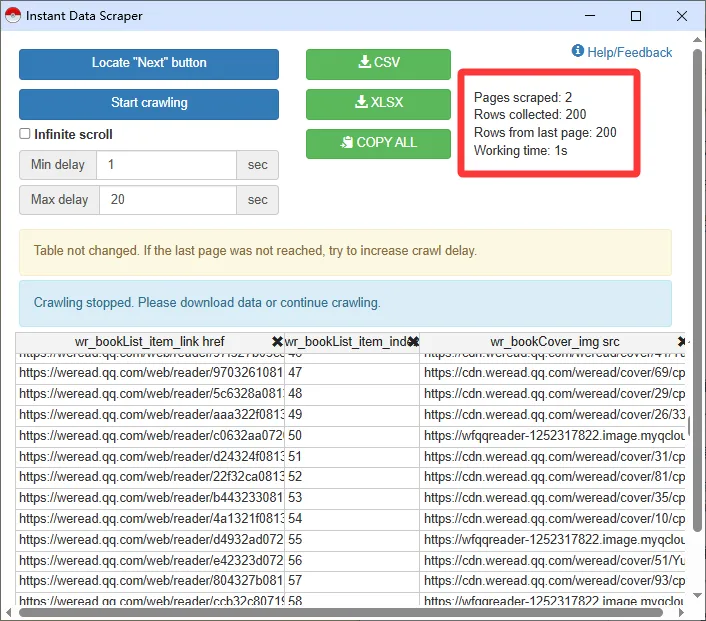
系统默认的抓取数据会根据界面加载情况而变化,有时可以全部一次性抓取,有时第一次只能抓到前面部分,我找的这个案例只有一页共200,滚动加载
下面分两种情况讨论:
a.一次性抓到全部200项:就跳过第5步直接到第6步下载文件
b.显示只抓到60项:把下一页按钮定位到抓取部分内容的第61个
5.点击“Start crawling”,插件就自动抓取到了剩下的部分,200个全部抓取成功
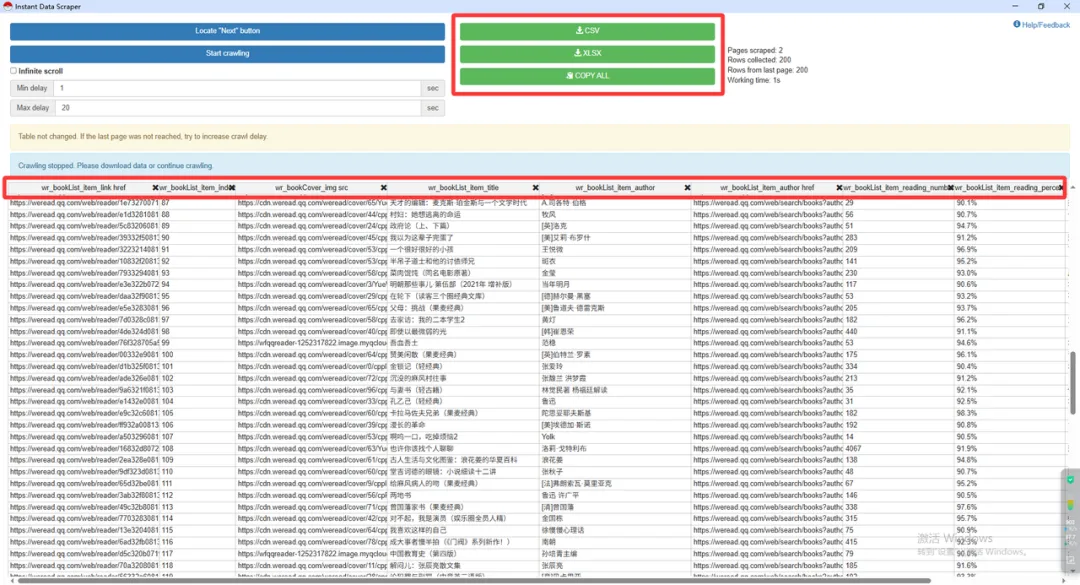
6.保留你需要的信息,完成下载
如图所示底部会详细显示插件抓取到的所有信息,其中很多是无用信息,点击×直接删除不需要的列,保留需要的信息
处理好后,点击绿色部分自己需要的格式进行下载或者全选下面列表复制粘贴
操作技巧总结:
1.太频繁操作或者操作时关闭屏幕谷歌会跳人机验证,尽量模拟人工操作
2.在谷歌搜索页使用的时候把导航栏改为搜索“网页”,减少无关页面导致插件识别不准
3.每点击一次插件图标,都会弹出一个抓取数据设置界面,多次点击记得关闭
4.抓取数据卡住的时候,重新点一下start crawling,试试能不能继续识别
5.下一页按钮有时候不那么好用,需要多试试
如果还遇到其他问题欢迎评论区留言我们一起解决
看到这里了,点个关注不迷路
邀请你和我一起走在成为销冠的路上
不定期分享新人外贸业务员的成长记录和获客心得
