 夜雨聆风
夜雨聆风





PDF转Markdown新利器:智能体AI解析器深度测评
字数 4163,阅读大约需 16 分钟

对LandingAI全新ADE文档解析API在LLM、RAG及智能体工作流中的性能基准测试
从PDF中提取干净的文本已成为当今众多LLM工作流的核心需求,涵盖标准检索增强生成(RAG)到现代智能体AI系统的各种应用场景。
然而,传统PDF解析器往往丢失文档结构、格式和视觉元素,导致提取内容的可用性大打折扣。输入垃圾,输出垃圾。
Markdown已成为LLM的标准目标格式。真正的挑战在于如何将复杂的真实世界PDF转换为干净的Markdown,同时不丢失任何信息。
在系列文章中,我已针对同一基准文档测试了十余款PDF转Markdown工具。如今,我将对LandingAI全新推出的智能体文档提取(ADE)工具进行测试。
AI智能体能否生成完美的Markdown?
智能体PDF转Markdown转换
LandingAI的ADE采用智能体方法来解析文档。从本质上讲,这意味着LLM充当”大脑”,根据文档内容调用专业工具进行推理和操作。
基本理念是:现实世界的文档往往杂乱、复杂且多样。有些文档只是纯文本,有些则包含图表、表格和手写内容,有些是光照不佳的文档低质量照片。
与一刀切的工作流相比,智能体方法增加了灵活性,因为智能体可以自主决定如何处理每个文档。
LandingAI智能体文档提取的工作原理
ADE解析文档的具体过程并未公开披露。然而,根据文档页面和LandingAI在线课程”Document AI: From OCR to Agentic Doc Extraction”的内容,我们可以进行一些推测 [1]。
与传统OCR方法不同,ADE将文档视为视觉对象。ADE特别关注文档的布局和结构,因为这些元素包含重要信息。例如,考虑人类如何阅读双栏布局,以及传统OCR如何处理它。
PaddleOCR 3:业界领先的开源PDF转Markdown方案
ADE的功能可能与PaddleOCR 3非常相似,特别是PP-StructureV3文档解析管道。这个多模型管道通过五步处理工作流将PDF文档转换为Markdown和JSON格式 [2]。
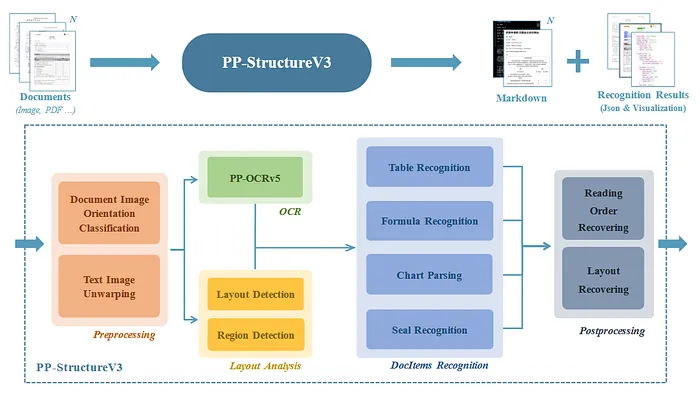
PaddleOCR 3.0的PP-StructureV3管道 [2]。工作流主要包括预处理、OCR、布局分析、文档元素识别和后处理。根据CC BY 4.0许可证授权使用。
以下是PP-StructureV3功能的简要总结 [2]:
-
1. 预处理: 修正图像旋转和畸变 -
2. OCR: 检测并识别所有文本内容 -
3. 布局分析: 用边界框对文档中所有重要区域进行分类和定位 -
4. 文档元素识别: 将布局分析中的特定区域发送给专业模型,用于识别表格、公式、图表和印章 -
5. 后处理: 根据正确的阅读顺序对所有元素进行排序
Docling也执行类似的功能,包括对PDF文档的OCR、布局分析、表格识别和后处理 [3]。
之前已经对PaddleOCR的PP-StructureV3和Docling进行了基准测试。当时的结果不太理想,因此我很想知道ADE的表现如何。
LandingAI ADE (DPT-2)
对于此任务,LandingAI使用其DPT-2模型:
文档预训练Transformer(DPT)是ADE解析API的核心模型。DPT识别文档布局并进行分块,然后为这些块生成描述性说明(标题)[4]。
这听起来像是一个大型Transformer模型,但也可能是一个由多个较小模型组成的管道。
DPT-2具有表格和图表标题生成、布局检测和块本体分类功能,可对每个检测到的区域进行分类。
使用ADE,我 предполага的是,智能体并非对每个文档都使用相同的管道,而是根据需要调用处理步骤。此外,可能还存在一个反馈循环,智能体可以纠正Markdown输出中的任何错误。
创建Markdown转换测试的基准PDF
为了评估PDF转Markdown转换的准确性,我使用了一个已知标准答案的基准文件。其中包含了所有基本的Markdown语法元素。
使用通用文档转换器Pandoc,我将Markdown标准答案转换为PDF文档bench_pdf_v2.pdf。
结果是一个两页的基准PDF文件,我知道用于创建它的Markdown。

我将使用此基准文档来查看和比较LandingAI的ADE与其他PDF转Markdown工具的结果。
使用LandingAI ADE Python包
ADE提供REST API以及Python和TypeScript库。我将使用Python库来解析我的基准PDF文件。
首先,我们必须使用pip install landingai-ade安装Python包。
然后,我们只需几行Python代码即可执行ADE管道。我们需要创建一个client并传入API密钥。然后,调用客户的parse函数,传入文档路径和最新的dpt-2模型作为参数:
from landingai_ade import LandingAIADEfrom pathlib import Pathclient = LandingAIADE(apikey= "INSERT-YOUR-API-KEY")doc_path = Path("./bench_pdf_v2.pdf") # 更改为您自己的文件路径parse_response = client.parse( document=doc_path, model="dpt-2-latest")执行此代码大约需要六秒,每页消耗三个积分。
parse函数返回一个包含以下字段的ParseResponse对象 [4]:
-
• chunks:Chunk对象列表,每个解析区域一个 -
• markdown:文档的完整Markdown表示 -
• metadata:处理信息(积分使用量、持续时间、文件名、任务ID、页数、版本) -
• splits:按页面或部分组织的Chunk对象列表 -
• grounding:将块ID映射到详细定位信息的字典
这意味着我们不仅收到最终的Markdown结果,还收到视觉定位信息。
具体来说,每个检测到的元素称为一个”块”。对于每个块,我们收到包含以下内容的结构化数据:页面、块类型(例如文本、表格、图形、标题)、边界框坐标、置信度和Markdown。
可视化ADE的布局检测
基于这些信息,我们可以准确了解AI在PDF中识别了什么。
我使用了一些辅助函数 [1]来可视化parse_response中的数据。这产生了以下边界框可视化效果。
第一页:

第一PDF页面的边界框可视化(布局检测)。图片由作者提供
第二页:
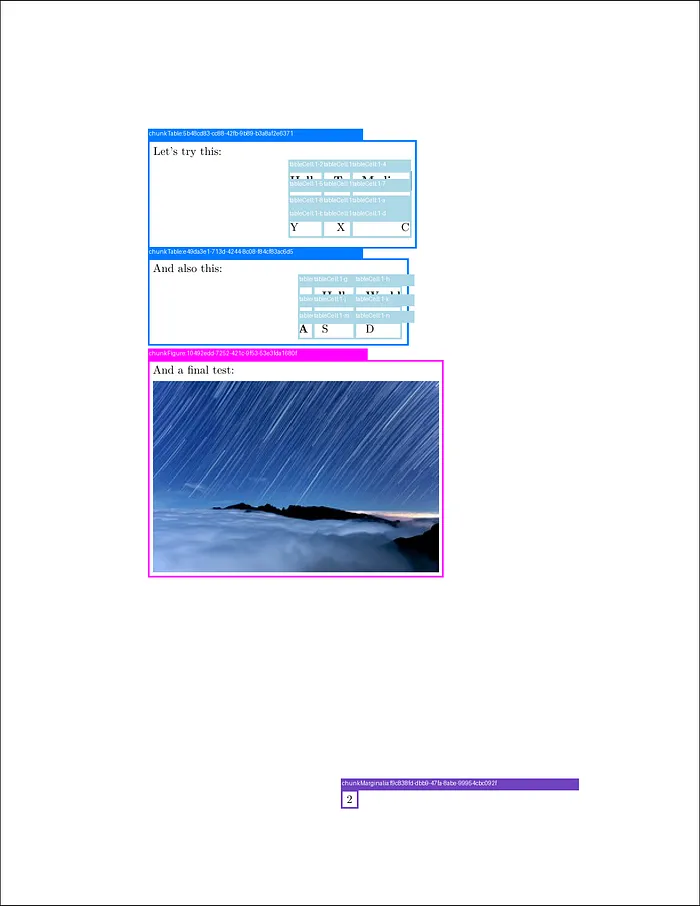
第二PDF页面的边界框可视化(布局检测)。图片由作者提供
每个边界框就是一个块。例如,访问第一个块的方法如下:
print(parse_response.chunks[0])>> Chunk(id='2df6c4ad-6735-42ac-92a1-5828edae451a', grounding=ChunkGrounding(box=ParseGroundingBox(bottom=0.2504836618900299, left=0.2118898183107376, right=0.4682390093803406, top=0.15064971148967743), page=0), markdown="<a id='2df6c4ad-6735-42ac-92a1-5828edae451a'></a>\n\n# Lorem Ipsum\n\nLorem ipsum dolor sit amet.\nConsetetur sadipscing elitr.\nSed diam nonumy eirmod tempor.", type='text')边界框信息非常有用。例如,当LLM在RAG系统中引用文档的某个部分时,您可以直观地向用户显示该数据的确切来源。此功能有助于开发者调试并增强用户信任。
评估Markdown输出
让我们将完整的Markdown输出保存为文件并查看结果。
# 将Markdown保存到磁盘with open("output-ade.md", "w", encoding="utf-8") as myfile: myfile.write(parse_response.markdown)这为我们的PDF文档生成以下Markdown输出:
<a id='569078a5-d828-4fbc-bde2-b3d4c223b054'></a># Lorem IpsumLorem ipsum dolor sit amet.Consetetur sadipscing elitr.Sed diam nonumy eirmod tempor.<a id='5688ef04-69b5-4a98-b5d4-745fb6d056fb'></a>Lorem IpsumLorem ipsum.*Lorem ipsum.***_Lorem ipsum._**Lorem ipsum.<a id='b3932830-cd5c-4648-904b-bfdce53c1231'></a># Lorem IpsumLorem. Lorem ipsum. Lorem ipsum dolor. Lorem ipsum.1. Lorem2. Lorem ipsum3. Lorem ipsum dolor* Lorem* Lorem ipsum* Lorem ipsum dolor<a id='99cbbade-d994-4dc1-9ea2-2ecf9c37d5a0'></a>Before something<a id='ca05a4c7-d841-4e77-9dae-13a30bd6c74f'></a>After somethingTest: click.Another test: mail@example.comLet's try this:```pythondef add_integer(a: int, b: int) -> int: return a + b```And also this:```bashcurl -o thatpage.html http://www.example.com/```<a id='80c6444c-1d7e-4f12-b8ee-4bb0906e6945'></a>1<!-- PAGE BREAK --><a id='5b48cd83-cc88-42fb-9b89-b3a8af2e6371'></a>Let's try this:<table id="1-1"><tr><td id="1-2">Hello</td><td id="1-3">To</td><td id="1-4">Medium</td></tr><tr><td id="1-5">Q</td><td id="1-6">W</td><td id="1-7">E</td></tr><tr><td id="1-8">A</td><td id="1-9">S</td><td id="1-a">D</td></tr><tr><td id="1-b">Y</td><td id="1-c">X</td><td id="1-d">C</td></tr></table><a id='e49da3e1-713d-4244-8c08-f84cf83ac6d5'></a>And also this:<table id="1-e"><tr><td id="1-f"></td><td id="1-g">Hello</td><td id="1-h">World</td></tr><tr><td id="1-i">Q</td><td id="1-j">W</td><td id="1-k">E</td></tr><tr><td id="1-l">A</td><td id="1-m">S</td><td id="1-n">D</td></tr></table><a id='10492edd-7252-421c-9f53-53e3fda1680f'></a>And a final test:<::A long-exposure photograph shows star trails across a deep blue night sky. Below the sky, a dark mountain range is visible, partially obscured by a thick layer of white clouds that fill the valleys and stretch across the landscape, with a faint glow visible on the horizon.: image::><a id='f9c838fd-dbb9-47fa-8abe-99954cbc092f'></a>2总体而言,结果看起来相当不错。
值得注意的是,每个块都以一个不可见的HTML锚点开始。表格使用HTML代码而非纯Markdown实现。
文档中的图像已被描述它的替代文本所替代。定制语法<:: alt text : image::>既不是标准Markdown也不是HTML代码。
处理更复杂的PDF示例
ADE在复杂文档上的表现也相当不错。网络演示包含了四个示例PDF,包含真实世界的表格、图表、手写内容、复选框等。
例如,以下是ADE可以处理的提供的_AccidentStatement.pdf_文件。
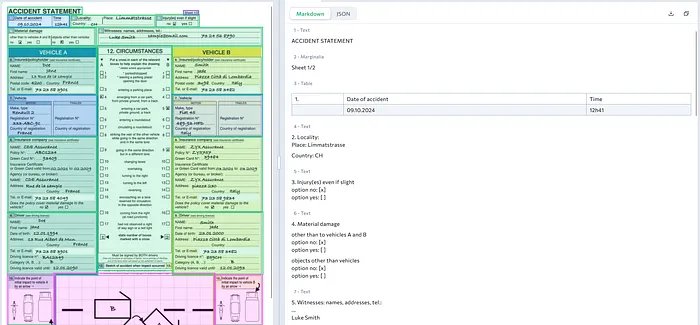
LandingAI的Playground中提供的”AccidentStatement”PDF示例的截图
除了解析为Markdown或JSON之外,您还可以拆分文档、提取键值字段以及与文档进行对话。
ADE与其他PDF转Markdown工具的比较
下表总结了我最近对几款PDF转Markdown转换器工具的测试结果 [5]。
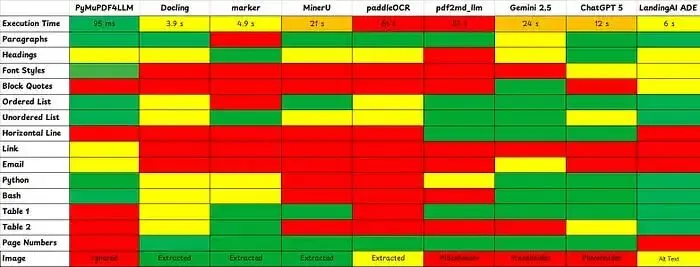
与我测试的其他工具相比,LandingAI的ADE是从PDF文件生成干净Markdown以进行后续下游任务的最佳选择之一。
最大的缺点是使用此服务的成本,因为大多数其他工具都可以免费在本地使用。我每页使用三个积分。目前,您可以按现付现用模式购买100个积分,价格为1美元。
结论
LandingAI的智能体文档提取是一款将智能体AI与PDF转Markdown转换工具相结合的新产品。然而,我不确定智能体行为对此任务的必要性。由于是专有解决方案,很难做出判断。
与我尝试过的所有其他工具相比,我认为ADE相当不错。我还喜欢额外的元数据,包括每个块的边界框区域信息。这些信息可用于以后可视化这些块的确切来源。
一个缺点是此工具无法在本地运行。与Docling等本地开源选项相比,ADE要求您将私人文档上传到服务提供商。您还需要按使用量支付积分。
您可以通过注册并获得1000个免费API积分,或使用其基于网络的Playground演示来试用ADE工具。
参考资源
[1] DeepLearning.AI, Document AI: From OCR to Agentic Doc Extraction (2026)
[2] C. Cui等人, PaddleOCR 3.0 Technical Report (2025), arXiv
[3] N. Livathinos等人, Docling: An Efficient Open-Source Toolkit for AI-driven Document Conversion (2025), AAAI 25: Workshop on Open-Source AI for Mainstream Use
[4]LandingAI,PythonLibraryDocumentation: https://docs.landing.ai/ade/ade-python, 访问于2026年2月22日
[5] L. Eversberg, PDF to Markdown Conversion Benchmark — Part 3 (2025), AI Advances