 夜雨聆风
夜雨聆风





别再复制粘贴!Python帮你把多份Word文档瞬间“合多为一”
关注我,学习更多实用Python知识
🌈Hi,小伙伴们~
🛠️ 这些不断复制粘贴,你有遇到过吗?
📄 年终总结:各部门的报告,要合成一本
📇 招标文件:标书、规格书等不同文档需按序合并
💰 合同归档:每月几百份Word要按日期汇总
🏆 书籍排版:不同章内容要手动合并成完整书稿
🎯今天,以 「一键批量合并多个Word文档」 为例,用Python让你从文档搬运工变身效率达人!
🛠️ 项目需求
📄 批量合并Word文档,按需生成合集
✅ ①自动读取:遍历指定文件夹,支持.docx格式
✅ ②智能排序:按文件名或自定义顺序合并
✅ ③精准控制:每个文档间自动插入分节符或分页符
✅ ④一键生成:将合并后的完整文档保存到指定位置
📊 效果示意图:
📁 各章节文稿/ → 📄 完整书稿.docx├── 01-第一章.docx ├── 第一章内容...├── 02-第二章.docx ├── (分页符)├── 03-第三章.docx ├── 第二章内容...└── ...(直到第N章).docx └── ... (所有内容按序合并)🛠️ 准备工作(代码执行前)
1️⃣ 整理待合并文档📂
将所有需要合并的Word文档放入同一个文件夹,建议按合并顺序命名,例如:01_概述.docx、02_需求分析.docx、03_技术方案.docx,程序将按文件名排序处理
2️⃣ 明确合并规则
你需要决定文档之间的衔接方式:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
3️⃣ 安装Python库
打开终端,输入以下命令:
pip install python-docx✅ 库简介:python-docx 是读写Word(.docx)文件的利器,能完美读写段落、表格、图片、页眉页脚等所有元素
⚙️ 代码实现
💡 核心思路:
📝 完整代码示例:
import osfrom docx import Documentfrom docx.enum.text import WD_BREAKdefmerge_word_docs(source_folder, output_filename, add_page_break=True):""" 批量合并指定文件夹下的所有Word文档 :param source_folder: 存放待合并文档的文件夹路径 :param output_filename: 输出合并后文档的文件名 :param add_page_break: 是否在文档间插入分页符 """# 1. 创建一个主文档 merged_doc = Document()# 2. 获取文件夹下所有docx文件,并按名称排序 docx_files = [f for f in os.listdir(source_folder) if f.endswith('.docx')] docx_files.sort() # 关键!确保按顺序合并ifnot docx_files: print("文件夹中没有找到 .docx 文件")return print(f"🔍 找到 {len(docx_files)} 个文档,开始合并...")# 3. 遍历每个文档for i, filename in enumerate(docx_files): file_path = os.path.join(source_folder, filename) print(f" 正在处理: {filename}")# 打开当前文档 doc = Document(file_path)# 4. 将当前文档的所有元素添加到主文档# 处理段落for para in doc.paragraphs:# 创建一个新段落,并复制原段落的样式和文本 new_para = merged_doc.add_paragraph() new_para.paragraph_format.alignment = para.paragraph_format.alignment new_para.style = para.stylefor run in para.runs: new_run = new_para.add_run(run.text)# 复制文字样式 new_run.bold = run.bold new_run.italic = run.italic new_run.underline = run.underline new_run.font.name = run.font.name new_run.font.size = run.font.size# ... 可以继续复制其他样式# 处理表格for table in doc.tables:# 这里需要更复杂的表格复制逻辑,为简化示例,先跳过# 实际应用中可遍历行列创建新表格pass# 5. 如果不是最后一个文档,且需要插入分页符if add_page_break and i < len(docx_files) - 1: merged_doc.add_page_break()# 6. 保存合并后的文档 output_path = os.path.join(source_folder, output_filename) merged_doc.save(output_path) print(f"\n 合并完成!文件已保存为: {output_path}")# 程序入口if __name__ == "__main__":# 设置你的文件夹路径 folder = "待合并文档"# 将此路径替换为你的文件夹 merge_word_docs(folder, "合并后的完整文档.docx", add_page_break=True)⚡运行效果


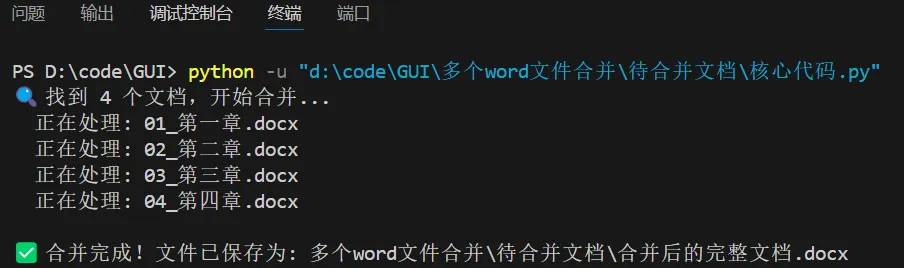
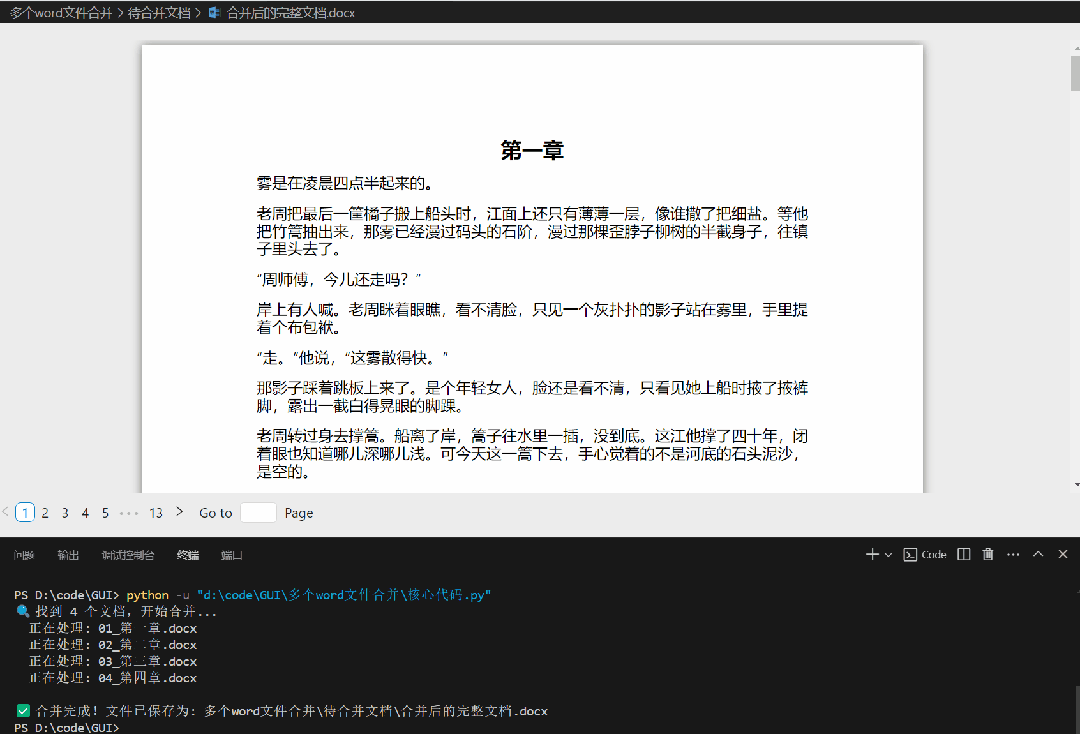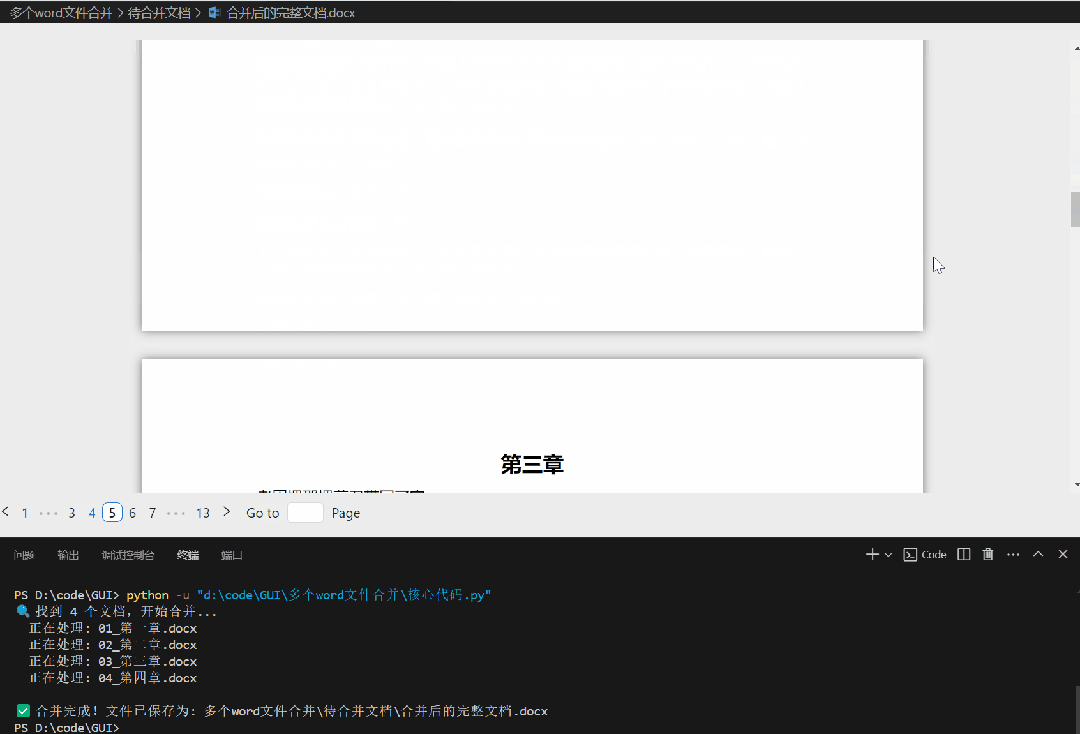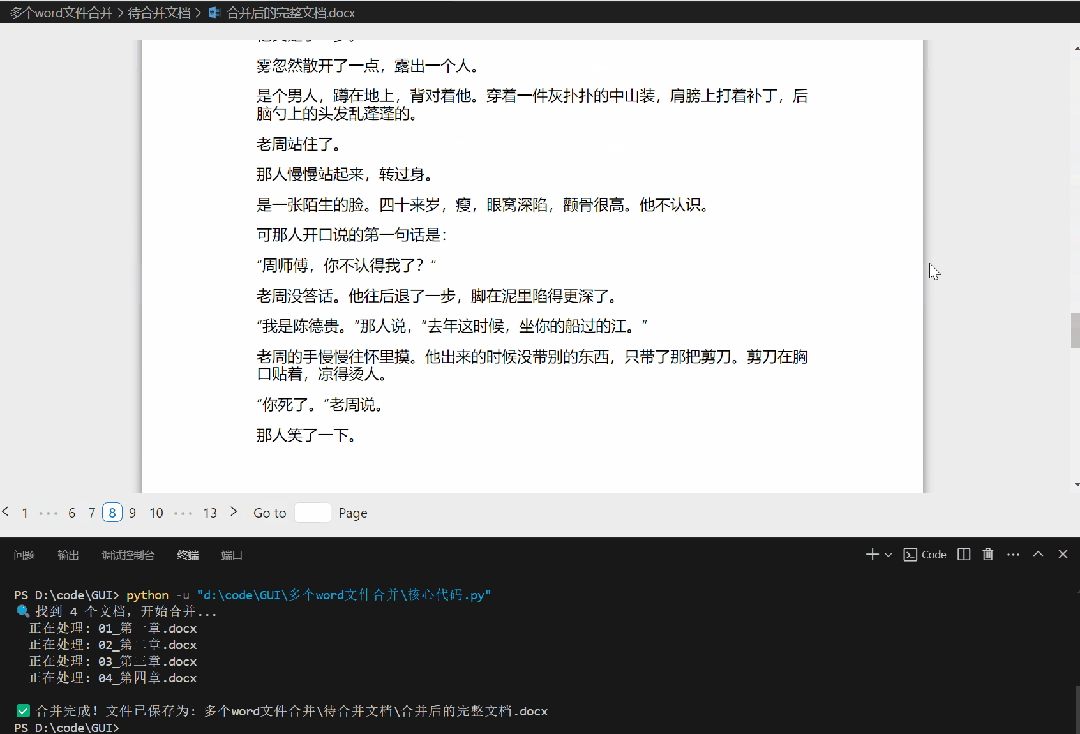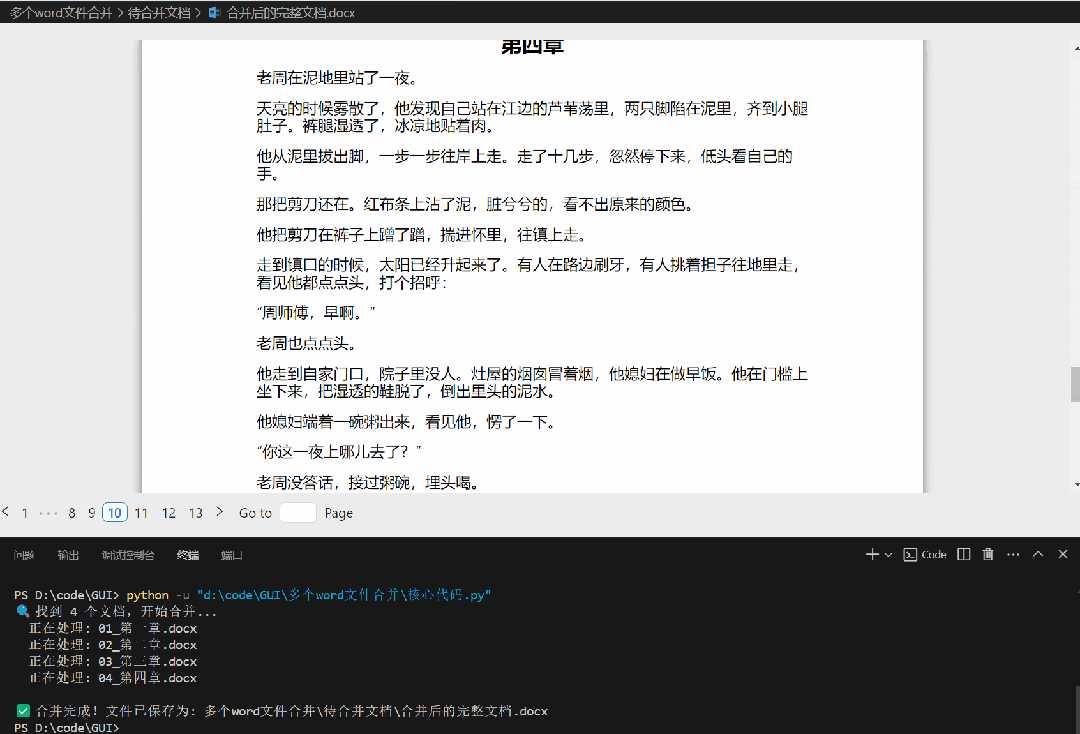
合并后成1个文档如下:
⚠️ 代码小贴士:
图片处理:如需保留图片,需遍历doc.part.rels复制图片文件
样式保留:直接复制run对象是保留格式的最保险方式
性能优化:合并超100个文档时,建议分批处理避免内存溢出
⚡ 效率提升看得见
🧩 传统方式:手工复制粘贴 + 调整格式 ≈ 2小时/100份
🧩 使用脚本:一键自动合并 ≈ 30秒/100份
✅ 准确率100%,省下时间做更有价值的事!
📌 结语
💡 关注我,每周分享Python干货×技巧
📌 如果这篇文章对你有帮助,欢迎:
👍 点赞 | ⭐ 收藏 | 🔄 分享给朋友
💬 如需源码:关注+评论区回复“多个word自动合并“
即可获取完整脚本 + 示例模板!

👇点击阅读往期文章