 夜雨聆风
夜雨聆风





【OpenClaw 源码解析第3期】你的 AI 助手每次都「失忆」?学会这一招,让它记住你所有重要决策,效率直接翻倍!
深扒 OpenClaw 源码,揭秘顶级 AI Agent 背后不为人知的「记忆黑科技」——普通人永远不知道的💰财富密码😱
就像花了一个月调教出来的实习生,第二天早上进门,满脸问号地看着你:「您好,请问我是来做什么的?」

💡 阅读指南:章节之间是层层递进的关系——先搞明白「记什么」,再搞清楚「怎么存」,然后是「怎么找」,最后是「什么时候自动保存」。每一章都在解决上一章留下的新问题。

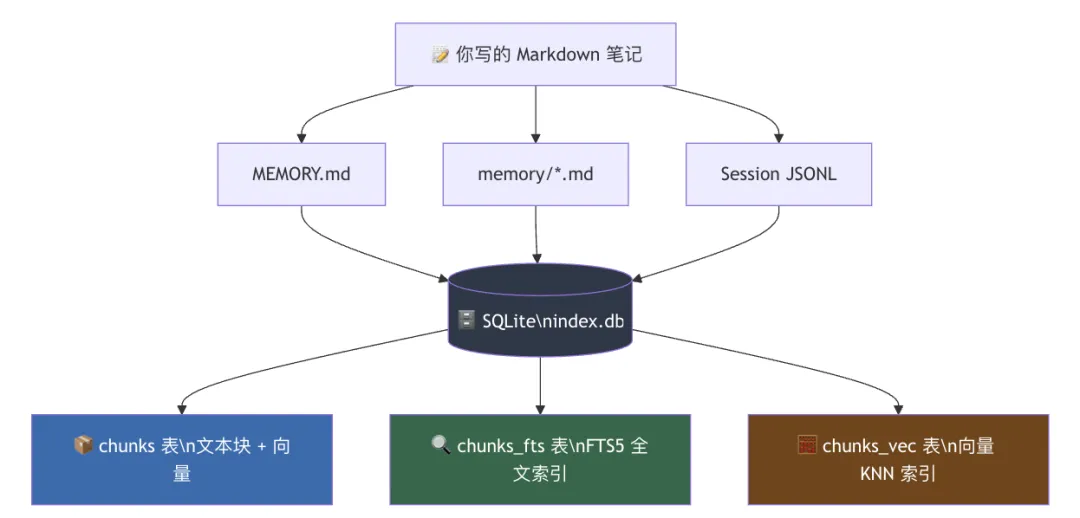
第一章:大脑在哪里?💾
|
|
|
|
|---|---|---|
|
|
MEMORY.md |
~/.openclaw/workspace/<你的ID>/ |
|
|
memory/*.md |
|
|
|
|
~/.openclaw/sessions/ |
|
|
|
~/.openclaw/memory/<你的ID>/index.db |
CREATE TABLE chunks (id TEXT PRIMARY KEY,path TEXT NOT NULL, -- 来自哪个文件source TEXT NOT NULL DEFAULT 'memory', -- 'memory' | 'sessions'start_line INTEGER NOT NULL, -- 块开始行号end_line INTEGER NOT NULL, -- 块结束行号hash TEXT NOT NULL, -- 内容哈希,用来检测变更model TEXT NOT NULL, -- 用哪个 embedding 模型算的text TEXT NOT NULL, -- 原始文本 embedding TEXT NOT NULL, -- ⚠️ JSON 序列化的向量数组!updated_at INTEGER NOT NULL);
CREATE TABLE files (path TEXT PRIMARY KEY,source TEXT NOT NULL DEFAULT 'memory',hash TEXT NOT NULL, -- SHA-256 文件哈希mtime INTEGER NOT NULL, -- 修改时间size INTEGER NOT NULL);
// 一个文本块type MemoryChunk = {startLine: number;endLine: number;text: string;hash: string; // 块内容的 SHA-256};// 搜索返回的一条结果type MemorySearchResult = {path: string;startLine: number;endLine: number;score: number; // 0-1 的相关性分数snippet: string; // 最多 700 字符的摘要source: "memory" | "sessions";citation?: string; // 格式:path#L15 或 path#L15-L30};
😏 一句话总结:你写的 Markdown 笔记是「原材料」,AI 把它们切碎、编码、建索引之后,才能真正「懂得」里面说的是什么。
第二章:大脑怎么工作?🔪
function chunkMarkdown(content: string,chunking: { tokens: number; overlap: number }) {const maxChars = tokens * 4; // 400 tokens → ~1600 字符const overlapChars = overlap * 4; // 80 tokens → ~320 字符重叠// 按行累积,超过 maxChars 时切分// 保留 overlapChars 作为下一个块的开头}
就像切披萨,你不会让奶酪刚好从中间断掉——重叠部分就是「多留一点边」的意思。🍕
type EmbeddingProvider = {id: string; // 'openai' | 'gemini' | 'local'model: string; // 具体模型名embedQuery: (text: string) => Promise<number[]>; // 单条查询embedBatch: (texts: string[]) => Promise<number[][]>; // 批量处理};
🧠 记忆原理:你的笔记被变成数字 → 数字存进数据库 → 下次搜索时,你的问题也被变成数字 → 找最接近的数字 → 返回对应的笔记片段
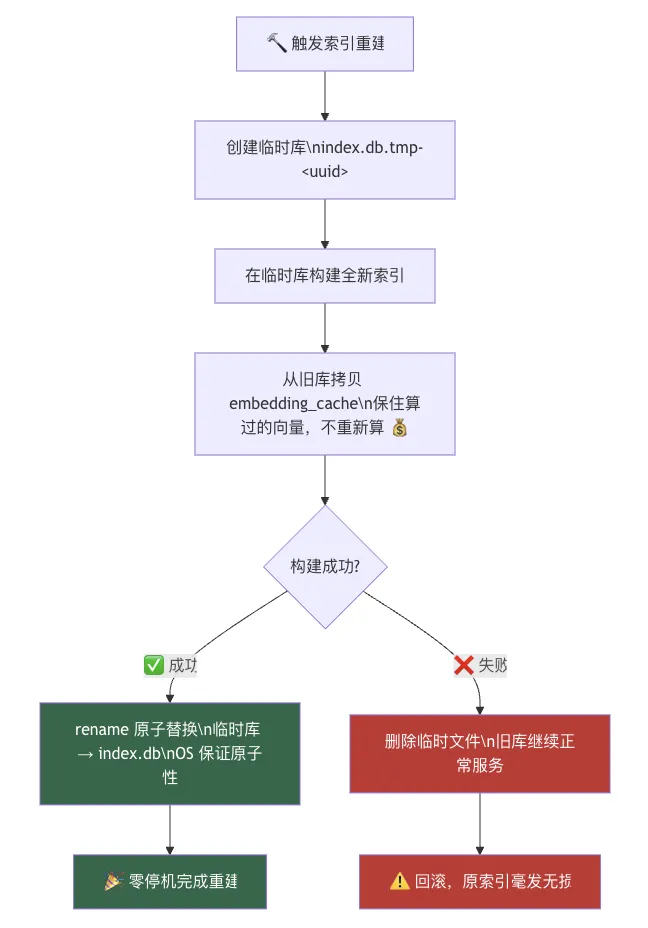
// 构建批次,每批最多 8000 tokensconst BATCH_MAX_TOKENS = 8000;function buildEmbeddingBatches(chunks: MemoryChunk[]): MemoryChunk[][] {// 按 token 估算累积,超过 8000 就新开一批}// 带缓存的批量 embeddingasync function embedChunksInBatches(chunks: MemoryChunk[]) {// 1. 先查 embedding_cache 表,找已缓存的// 2. 只对「未命中」的调用 provider.embedBatch()// 3. 把新结果写回缓存}
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
第三章:怎么想起来的?🔍
function mergeHybridResults(params: {vector: HybridVectorResult[];keyword: HybridKeywordResult[];vectorWeight: number; // 默认 0.7textWeight: number; // 默认 0.3}) {// score = vectorWeight * vectorScore + textWeight * textScore}
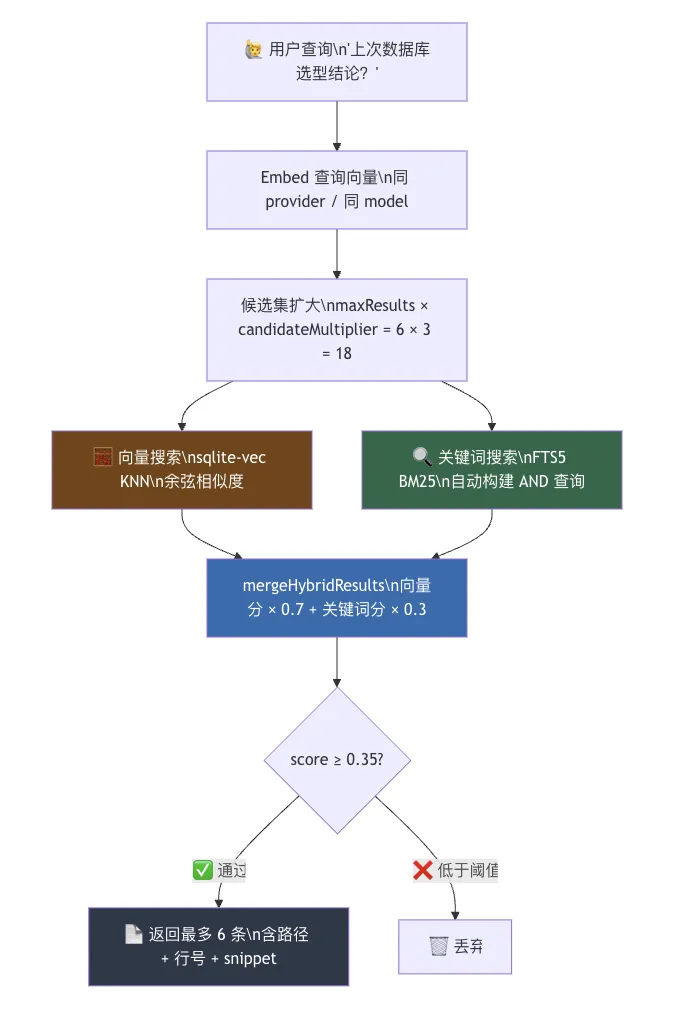
SELECT id, embeddingFROM chunks_vecWHERE embedding MATCH ? -- k-nearest neighbor 查询ORDER BY distanceLIMIT ?
😮 很多人以为向量搜索一定要上 Pinecone、Weaviate 那种独立服务,其实 SQLite 装个扩展就够了。
function buildFtsQuery(raw: string): string | null {// "hello world" → '"hello" AND "world"'const tokens = raw.match(/[A-Za-z0-9_]+/g);return tokens.map(t => `"${t}"`).join(" AND ");}
function bm25RankToScore(rank: number): number {return 1 / (1 + rank); // 越靠前,rank 越小,分越高}
「如果你最终要返回 6 条结果,我先找出 6 × 3 = 18 条候选,再从里面合并排序、择优返回。」
|
|
|
|
|---|---|---|
vectorWeight |
|
|
textWeight |
|
|
maxResults |
|
|
minScore |
|
|
candidateMultiplier |
|
|
第四章:什么时候自动记住的?🧠
function shouldRunMemoryFlush(params: {entry?: {totalTokens: number;compactionCount: number;memoryFlushCompactionCount: number; // 记录「这轮已经 flush 过了」};contextWindowTokens: number;reserveTokensFloor: number;softThresholdTokens: number; // 默认 4000}) {// 触发条件:// totalTokens > (contextWindowTokens - reserveTokensFloor - softThresholdTokens)// 且当前 compactionCount 未执行过 flush(防止重复触发)}
“Pre-compaction memory flush turn. The session is near auto-compaction; capture durable memories to disk. You may reply, but usually [NO_REPLY] is correct.”
“Pre-compaction memory flush. Store durable memories now (use memory/YYYY-MM-DD.md; create memory/ if needed). If nothing to store, reply with [NO_REPLY].”
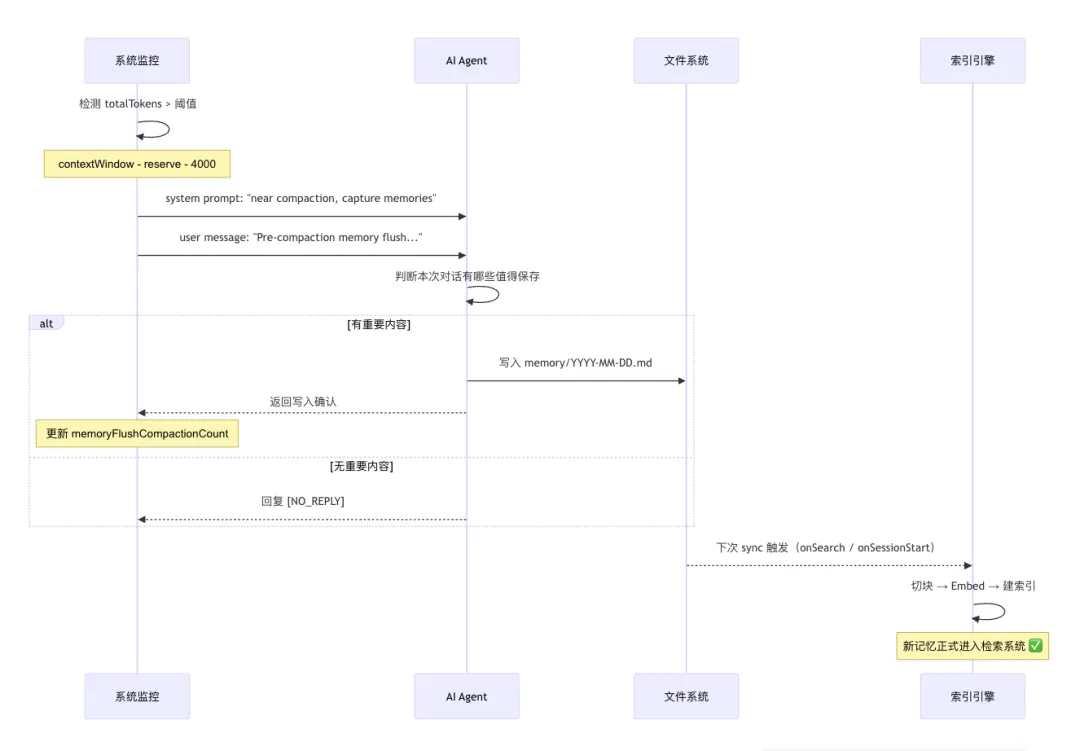
🎯 妙处:不需要你手动整理!AI 自己知道在「快撑不住」之前把重要内容持久化。这才是真正的「记忆」——不是你帮它记,是它自己知道该记什么。
终章:我能用上吗?🚀
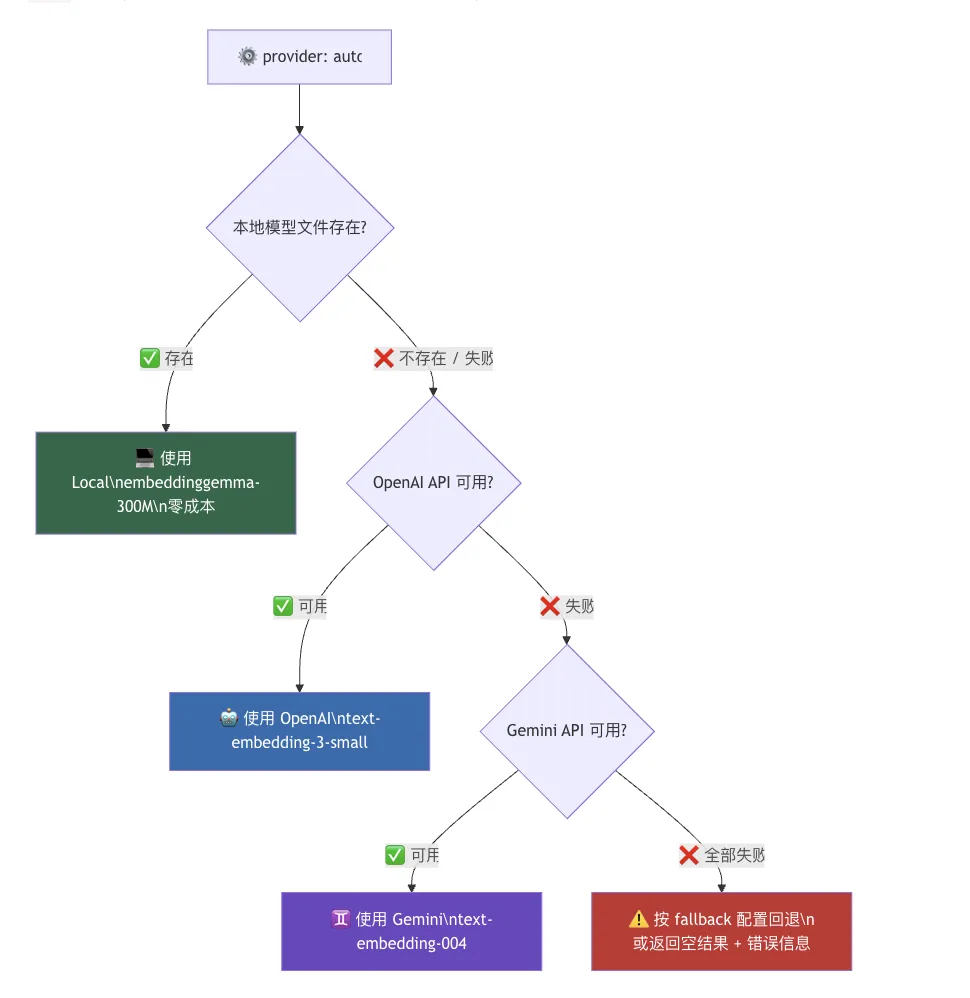
memory:backend: "builtin"内置方案,不需要额外服务 citations: "auto" # 自动显示引用来源 agents: defaults: memorySearch: provider: "auto" # 自动选可用的 Embedding 服务 sync: onSessionStart: true # 每次开始自动同步 onSearch: true # 搜索时自动同步 watch: true # 文件有变化立刻同步(debounce 1500ms) compaction: memoryFlush: enabled: true softThresholdTokens: 4000 # 提前多少 token 开始 flush
💡 最后一句话:
记忆,是让 AI 从「工具」变成「合伙人」的那道门槛。
而门是开着的——你只需要知道它在哪里。🚪