 夜雨聆风
夜雨聆风





我的 obsidian 插件支持中文标点标准化,拒绝长文的标点崩坏
最近,我给自己的 Obsidian 插件加了一个功能。
它看起来不算什么“大动作”,甚至在很多开发者眼里可能只是几行正则表达式的事儿,但我却觉得它非常值得认真复盘一下。
这个功能很简单:把中文正文里的英文半角标点,自动规范成中文标点。
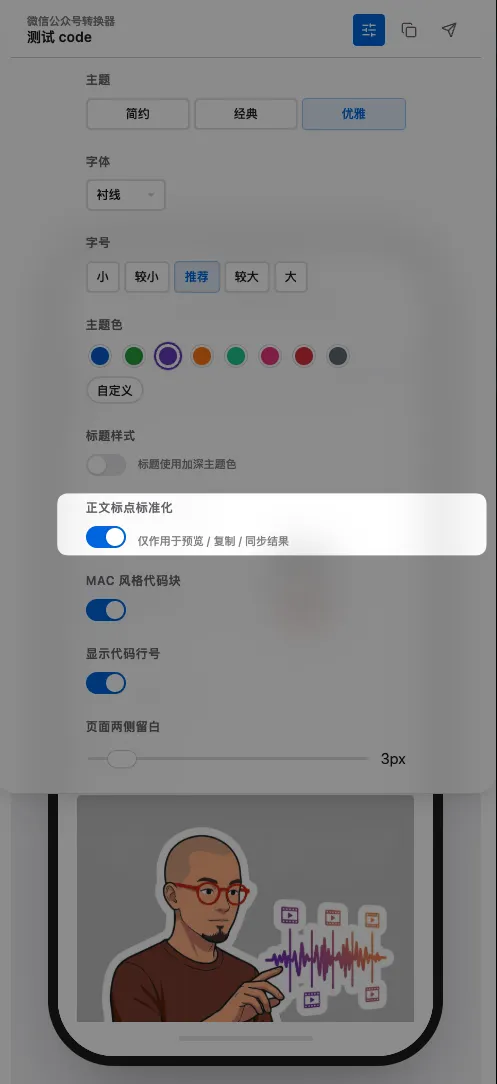
比如把英文逗号 , 变成中文逗号 ,,把英文句号 . 变成空心的小圆圈 。。
我想聊聊,在这个 AI 无所不能的时代,为什么我反而选择了一套“死板”的代码规则。
视觉里的那颗“沙子”
做这个功能的起因有两个。
一个是 GitHub 上有位朋友提了个 Issue,建议增加对中文标点的处理。虽然这对他来说可能只是个“痒点”,但却恰好挠到了我的心坎上。
另一个原因更直接:视觉上的痛苦。
我最近在尝试用国产大模型(比如 GLM)来辅助处理文章,结果发现它在标点处理上有一种顽固的“洋习惯”。最让我受不了的,是它整篇文章结尾的句号,全是实心的英文点 .。
想象一下,满屏温婉的中文,末尾却坠着一颗颗黑乎乎的芝麻点。这种感觉,就像在一幅细腻的水墨画里,突然被人随手甩了几滴刺眼的蓝墨水。这是一种对文字质感的无声破坏。

对我来说,标点符号在中文里不仅仅是停顿,它更是一种装饰,一种情绪的衔接。
为什么我拒绝了“全流程 AI 化”?
既然问题是由 AI 引起的,那能不能再用 AI 解决回去?比如写一段更强的 Prompt,让模型在输出时自己改好?
我尝试过,但最后我决定:第一层标准化,必须死磕代码规则,绝对不给 AI 自由发挥的空间。
我和 AI(Codex)在这一点上达成了某种“共识”:模型在处理规则时的不确定性,是它的天性。
我听朋友提起过,即使是 Claude 或 GPT 这样顶级的模型,在处理超过两千字的长文时,标点逻辑也会开始“精神错乱”:引号配着配着就丢了,或者中英文标点开始大乱斗。
更重要的是,AI 对 Markdown 结构有一种天然的“侵入性”和潜在破坏力。
标点在 Markdown 里不仅是文字,更是“骨架”。比如代码块的三个反引号 ```,如果你把它误转成了中文的全角符号,整个代码块就瞬间崩坏,预览界面会乱成一锅粥。
所以我的方案是:先用冷冰冰的、确定的代码规则做一层“硬隔离”,把那些绝对不能错的地方(比如代码块、URL、公式)保护起来,剩下的正文部分再交给规则去做标准化。
小白架构师的“掌控与惶恐”
说实话,我一直自认是个“小白”。
这套功能背后的代码逻辑,其实是我指挥 Codex 帮我写出来的。我只是负责表达我的想法、我的边界,然后看着它一行行吐出代码。
这种感觉非常奇妙,甚至让我产生了一种隐隐的“惶恐”。
一方面,我获得了一种前所未有的掌控感。我可以把那些困扰我已久的“洋句号”彻底抹平;另一方面,我也在惊叹于 AI 能力的强大,它让一个不懂底层工程的小白,也能构建出如此稳定、优雅的规则系统。
这种“能力下沉”,让想法变现的门槛几乎消失了。我只要负责坚持那份对“确定性”的直觉,AI 就能帮我完成剩下的重活。

我划下的那道“冷酷红线”
在设计规则时,我给自己定了一个原则:宁可漏改,绝不误改。
比如,我知道很多人希望把并列词语间的逗号自动改成顿号 、。这听起来很智能,但在实际编码时,我冷酷地拒绝了这个诱惑。
因为“逗号变顿号”涉及到语义判断。一旦规则写得太激进,就很容易在不该改的地方乱动。
我希望这个功能是一个边界清楚、行为稳定、默认靠谱的工程能力,而不是一个整天玩“概率游戏”的魔法棒。
被用户推着走的真实体感
说实话,有时候看到 GitHub 上的建议,我也会觉得是一种负担。
但这次不一样。那个 Issue 让我意识到,这种对标点细节的执着,其实是很多创作者的共鸣。无论你是手打 Markdown,还是用弱模型生成的草稿,这套标准化工具都能给你提供一份发布前的“格式质检”。
这种被用户推着走的感觉,在这一刻,从负担变成了动力。
好的工具,往往不需要多么绚丽的“黑科技”。
它只需要在你最需要的地方,提供一份可预测的安稳感。中文标点标准化就是这样一件事,它不炫,但它让文字回到了它该有的质感。
能做的事我都做了。现在,我终于可以看着那些圆润的空心句号,从容地点击发布了。