 夜雨聆风
夜雨聆风





构建代理式软件的5级架构:从简单工具代理到生产系统
推荐阅读
-
Agentic Software Engineering(致AI开发者)
-
Anthropic Multi-Agent Research System构建方法与经验
-
Anthropic 高效的AI agents上下文工程设计理念和实践经验
-
Anthropic通过MCP实现高效的Agent
-
Anthropic Agentic coding最佳实践
-
Anthropic:高效构建Agents设计理念
-
Claude Agent Skills:从第一性原理深入剖析
-
如何保证Agent的上下文Memory清晰
-
重要推荐:Agent AI: Surveying the Horizons of Multimodal Interaction
-
基于llama.cpp理解LLM推理的工作原理
-
LLM推理过程分析
-
回归基础!KVcache实现原理与优化!如何让LLM推理更快?
-
必知!大模型时代超常用的训练、微调、推理、部署框架
-
AI从业者必知!DeepSeek再度推出高效推理框架 FlashMLA,牛在哪?
-
K2-Think低成本高可用的高效推理系统
构建代理式软件的五级架构:从简单工具代理到生产系统
大多数团队会过度复杂化代理系统。他们一开始就采用多代理编排、自主推理循环和过于复杂的架构,然后花费数周时间调试为什么最简单的任务都会失败。
我遵循的模式简单得令人尴尬:从简单开始,逐步添加能力,并在每一步验证行为。
今天,我将向大家展示代理式软件的五级架构:
-
• 带工具的代理 -
• 带存储和知识的代理 -
• 带记忆和学习的代理 -
• 多代理团队 -
• 生产系统
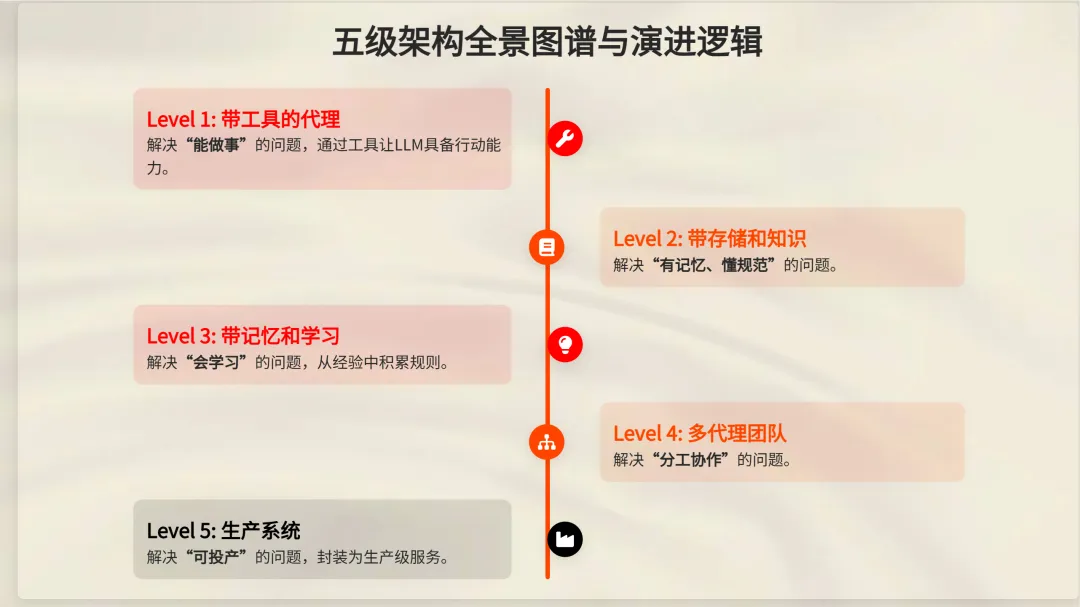
我们将构建一个名为 Gcode 的轻量级编码代理,每次只添加一项能力。像往常一样,我会为每个级别分享代码片段。
查看完整的cookbook:https://agno.link/agent-levels,里面有可直接克隆并运行的代码。
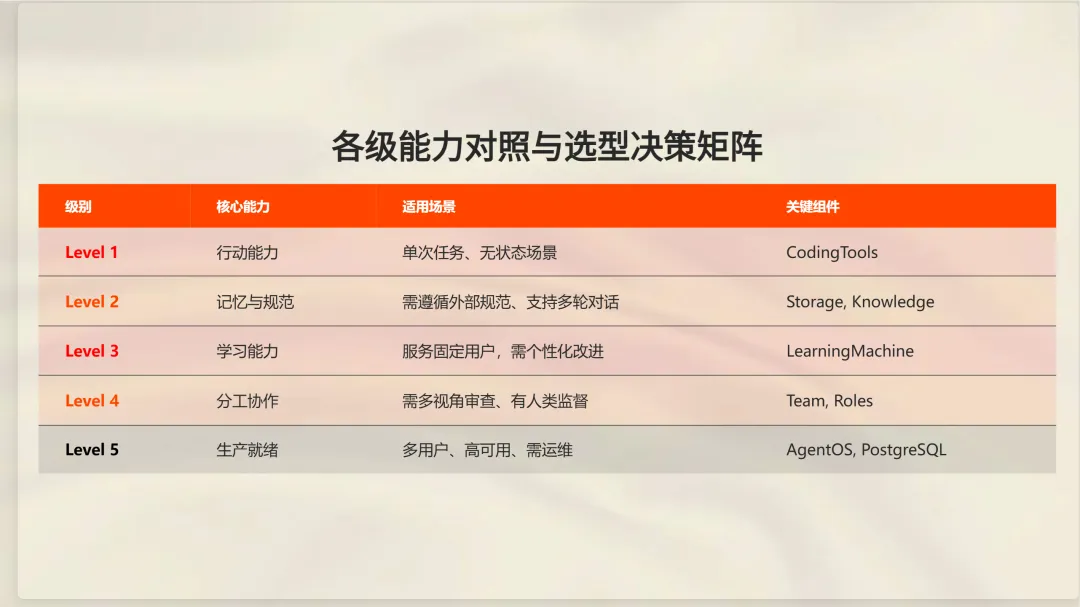
第 1 级:带工具的代理
没有工具的代理只是一个大语言模型(LLM)。它能推理,但什么都做不了。工具才是把 LLM 变成代理的关键。
对于编码代理,最小可用的工具集包括:读取文件、写入文件、运行 shell 命令。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
from agno.agent import Agent
from agno.models.openai import OpenAIResponses
from agno.tools.coding import CodingTools
WORKSPACE = Path(__file__).parent.joinpath("workspace")
WORKSPACE.mkdir(parents=True, exist_ok=True)
agent = Agent(
name="Gcode",
model=OpenAIResponses(id="gpt-5.2"),
instructions=(
"You are a coding agent. Write clean, well-documented code. "
"Always save your work to files and test by running them."
),
tools=[CodingTools(base_dir=WORKSPACE, all=True)],
markdown=True,
)
agent.print_response(
"Write a Fibonacci function, save it to fib.py, and run it to verify",
stream=True,
)
发生了什么:代理接收任务,使用 CodingTools 编写、编辑和运行代码。all=True 标志会启用 CodingTools 工具包中的所有工具(读取、写入、编辑、shell、grep、find、ls)。
缺少什么:每次运行都从零开始。代理无法回忆之前的会话,无法遵循项目规范(除非你把规范粘贴到提示中),也没有超出当前上下文的知识。
第 2 级:带存储和知识的代理
第 1 级是无状态的,一切都必须放在上下文中。第 2 级通过两个新增功能解决这个问题:会话存储 和 领域知识。
存储
存储会将每个代理会话及其中的每次运行保存到数据库。这带来两点好处:
-
• 聊天历史作为上下文:使用存储,代理可以把最近 N 条消息纳入上下文窗口,从而知道当前进展。对于较长的会话,你可以运行压缩算法来总结早期上下文,保持窗口聚焦于当前重要内容。 -
• 发生记录:不需要把一切都发送给第三方追踪提供商。将会话存储在自己的数据库中,是了解代理做了什么、何时做以及为什么做的最简单方式。你拥有数据,可以查询、审计,还可以在上面构建仪表盘。
知识
如今的编码代理只能看到你代码库中的文件,除此之外一无所知。它们无法访问你的架构规范、团队的设计决策、内部会议纪要,或是 Slack 线程中有人解释为什么选择 Postgres 而不是 DynamoDB 的讨论。
这就是知识要解决的问题。它为代理提供了一个可搜索的存储库,包含项目中所有重要但不需要始终放在上下文窗口中的内容:规范、RFP、操作手册、架构决策记录、会议纪要、团队对话。
关键洞见:大量有价值的上下文存在于代码库之外。如果团队上个月在会议中讨论了迁移策略,这个上下文就应该在代理处理迁移任务时可用。如果六个月前有人决定使用库 X 而不是库 Y,代理就应该能在推翻 X 重新开始之前找到那段推理。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28
from agno.db.sqlite import SqliteDb
from agno.knowledge import Knowledge
from agno.knowledge.embedder.openai import OpenAIEmbedder
from agno.vectordb.chroma import ChromaDb, SearchType
db = SqliteDb(db_file=str(WORKSPACE / "agents.db"))
knowledge = Knowledge(
vector_db=ChromaDb(
collection="coding-standards",
path=str(WORKSPACE / "chromadb"),
search_type=SearchType.hybrid,
embedder=OpenAIEmbedder(id="text-embedding-3-small"),
),
)
agent = Agent(
name="Gcode",
model=OpenAIResponses(id="gpt-5.2"),
instructions=(...),
tools=[CodingTools(base_dir=WORKSPACE, all=True)],
knowledge=knowledge,
search_knowledge=True,
db=db,
add_history_to_context=True,
num_history_runs=3,
markdown=True,
)
变化:新增两项功能——基于 ChromaDb 的知识库(支持语义和关键词混合搜索),以及用于会话存储的 SqliteDb。现在代理可以:
-
• 在编码前搜索知识。如果你的风格指南要求“使用 snake_case”,代理会找到并遵循它。 -
• 记住对话:在同一会话中提出后续问题时,它拥有完整上下文。 -
• 知识入库:你将文档(文本、PDF、URL)插入知识库。运行时,代理搜索相关片段并将其添加到上下文中。这就是基础的 Agentic RAG。
1 2 3 4 5 6 7
# Load your coding standards
knowledge.insert(text_content="""
## Project Conventions
- Use type hints on all function signatures
- Write docstrings in Google style
- Prefer list comprehensions over map/filter
""")
何时使用第 2 级:当代理需要遵循它未训练过的标准,或用户期望多轮对话时。这是大多数内部工具的甜蜜点。
第 3 级:带记忆和学习的代理

从第 2 级到第 3 级的跨越是最重要的。在第 2 级,代理遵循你给它的规则;在第 3 级,它会从经验中学习规则。
第 1000 次交互应该比第 1 次更好。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33
from agno.learn import LearnedKnowledgeConfig, LearningMachine, LearningMode
from agno.tools.reasoning import ReasoningTools
learned_knowledge = Knowledge(
vector_db=ChromaDb(
collection="coding-learnings",
path="tmp/chromadb",
search_type=SearchType.hybrid,
embedder=OpenAIEmbedder(id="text-embedding-3-small"),
),
)
agent = Agent(
name="Gcode",
model=OpenAIResponses(id="gpt-5.2"),
instructions=(...),
tools=[
CodingTools(base_dir=WORKSPACE, all=True),
ReasoningTools(),
],
knowledge=docs_knowledge,
search_knowledge=True,
learning=LearningMachine(
knowledge=learned_knowledge,
learned_knowledge=LearnedKnowledgeConfig(
mode=LearningMode.AGENTIC,
),
),
enable_agentic_memory=True,
db=db,
markdown=True,
)
变化:
-
• 学习机器:代理获得 save_learning和search_learnings工具。它自己决定什么值得记住:有效的编码模式、需要避免的错误、用户偏好。这些内容存储在独立的知识库中,并在未来会话中呈现。 -
• 代理式记忆:代理随着时间构建用户画像:你偏好的编码风格、使用的框架、喜欢解释的方式。
两会话测试:
1 2 3 4 5 6 7 8 9 10 11 12
# Session 1: User teaches a preference
agent.print_response(
"I prefer functional programming style — no classes, "
"use pure functions and immutable data. Write a data pipeline.",
session_id="session_1",
)
# Session 2: New task — agent should apply the preference
agent.print_response(
"Write a log parser that extracts error counts by category.",
session_id="session_2",
)
在第 2 个会话中,代理搜索其学习记录,找到函数式编程偏好,然后编写函数式代码。
何时使用第 3 级:当代理服务于同一批用户且需要随时间改进时。个人编码助手、带有共享学习的团队工具,以及任何“按我们的方式做”的场景。
第 4 级:多代理团队

有时候单个代理不够用。第 4 级将职责拆分给专业化的代理,由团队领导者协调。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
from agno.team.team import Team
coder = Agent(
name="Coder",
role="Write code based on requirements",
tools=[CodingTools(base_dir=WORKSPACE, all=True)],
...
)
reviewer = Agent(
name="Reviewer",
role="Review code for quality, bugs, and best practices",
tools=[CodingTools(base_dir=WORKSPACE, enable_write_file=False,
enable_edit_file=False, enable_run_shell=False)],
...
)
tester = Agent(
name="Tester",
role="Write and run tests for the code",
tools=[CodingTools(base_dir=WORKSPACE, all=True)],
...
)
coding_team = Team(
name="Coding Team",
members=[coder, reviewer, tester],
instructions=(...),
show_members_responses=True,
markdown=True,
)
Coder 负责编写,Reviewer 负责阅读(注意:禁用 write/edit/shell),Tester 负责验证。团队领导者负责协调和综合。
诚实提醒:多代理团队强大但不可预测。团队领导者是一个 LLM,负责委托决策。有时委托得好,有时不好。对于可靠性至关重要的生产系统,优先选择显式工作流而非动态团队。团队在有人类监督的场景中表现最佳,人类可以审查输出。
何时使用第 4 级:当你需要多种视角(代码审查就是完美例子)、任务自然分解为专业角色,或构建可让人类监督的交互工具时。
第 5 级:代理式系统(生产 API)
第 5 级是把第 1-4 级变成生产服务的运行时。你从开发数据库升级到生产数据库,添加追踪,并把一切暴露为 API。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29
from agno.db.postgres import PostgresDb
from agno.vectordb.pgvector import PgVector, SearchType
from agno.os import AgentOS
db_url = "postgresql+psycopg://ai:ai@localhost:5532/ai"
db = PostgresDb(db_url=db_url)
knowledge = Knowledge(
vector_db=PgVector(
db_url=db_url,
table_name="coding_knowledge",
search_type=SearchType.hybrid,
embedder=OpenAIEmbedder(id="text-embedding-3-small"),
),
)
# ... create your Level 3 agent with production db ...
agent_os = AgentOS(
id="Gcode OS",
agents=[coding_agent],
teams=[coding_team],
config=config_path,
tracing=True,
)
app = agent_os.get_app()
if __name__ == "__main__":
agent_os.serve(app="run:app", reload=True)
变化:
-
• PostgreSQL + PgVector 取代 SQLite + ChromaDb。实现真正的连接池、真实备份和并发访问。 -
• AgentOS 将你的代理包装成 FastAPI 应用,内置 Web UI、会话管理和追踪。 -
• 追踪( tracing=True)让你能观察每个工具调用、每次知识搜索、每次委托决策。
何时使用第 5 级:当代理离开你的笔记本电脑时。多用户、高可用要求、需要调试生产问题。
最重要建议
从第 1 级开始。构建能解决问题的最简单代理。运行它。看看哪里失败。然后只添加它缺少的那一项能力。
大多数团队直接跳到第 4 级,因为多代理架构在演示中看起来很炫目。然后他们花费数月调试协调失败——而这些失败用一个指令清晰的单代理就能避免。
把这些级别看作能力层级,记住每升一级都会增加复杂度,而复杂度是有代价的。只有在更简单的方法明确失败时,才支付这个代价。
这里是包含所有五个级别可运行代码的食谱。克隆它,运行它,如果有问题告诉我。我是人类,也会犯错。

引用来源
-
• https://x.com/ashpreetbedi/status/2024885969250394191 -
• https://github.com/agno-agi/agno/tree/main/cookbook/levels_of_agentic_software
推荐阅读
-
Agentic Software Engineering(致AI开发者)
-
AI Coding 时代,基础知识与应用实践真的不重要了吗?
-
别用低维忙碌毁掉人生:Dan Koe的3-2-1法则,让你不用内卷也能跻身前1%
-
LLM推理过程采样策略(全面分析)
-
LLM推理过程分析
-
Karpathy 200行纯Python实现GPT2直观理解大语言模型核心原理
-
再次反思:AI到底替代什么?我们不能替代的能力是什么?
-
避免AI瞎写代码Claude Code核心编程准则
-
Reasoning LLMs解析
-
腾讯ShunyuYao新作CL-BENCH用于评估语言模型上下文学习能力的真实世界基准
-
Kimi K2.5 开源多模态智能体基模
-
各种AI产品爆火浪潮下的一点思考
-
DeepSeek-OCR 2探索统一全模态编码的可能性
-
DeepseekV4预热:mHC 大幅提高预训练模型稳定性
-
Gemini 3 Prompt:通用使用的最佳实践
-
20260125关于AICoding引发技术栈划分取消的思考
-
为什么使用Jinja2构建LLM工具调用Prompt
-
DeepseekV4预热Engram代码解析:静态Memory与动态计算分离
-
DeepseekV4预热:Engram实现静态Memory与动态计算分离
-
Qwen3 Embedding系列模型
-
Anthropic Multi-Agent Research System构建方法与经验
-
Anthropic 高效的AI agents上下文工程设计理念和实践经验
-
Anthropic通过MCP实现高效的Agent
-
Anthropic Agentic coding最佳实践
-
Anthropic think tool设计理念与实践经验
-
Anthropic 评估LLM实现软件工程能力实践经验
-
Anthropic:高效构建Agents设计理念
-
Anthropic RAG 上下文检索设计理念
-
2025,于AI浪潮中锚定自我
-
关于选择:理解贝叶斯主义,拥抱变化做好当下
-
致敬2025:一些前沿的超越标准大语言模型的探索
-
致敬2025:从DeepSeek V3到Mistral 3 Large现代LLM架构设计解析
-
Google极长上下文解决方案:Titans + MIRAS
-
MCP: Function Calling原理
-
一人公司AI技术栈:极简思维,拉满独立开发效率
-
FalkorDB开源Graph数据库
-
MemOS以LLMmemory为中心实现高效的存储和检索
-
一项连通心理学、神经科学与机器学习的研究Key-value memory in the brain
-
Ilya关于Scaling到Research转变的探讨
-
Claude Agent Skills:从第一性原理深入剖析
-
SQL原生LLM记忆引擎Memori
-
CUDA Toolkit安装多版本管理
-
多模态新方向:Cambrain-S空间超感知多模态
-
HunyuanOCR 1B商用级开源VLM模型技术报告解读
-
百度飞桨0.9B文档解析模型PaddleOCR-VL
-
ClaudeCode导入其他AI模型的方法
-
LLM多轮对话数据集构建高级攻略
-
Karpathy提出多LLM协作委员会项目解析
-
Document AI: 智能文档处理的下一次进化
-
Meta 提出SAM 3D Body: 单图像全身3D人体Mesh重建可提示模型
-
极简生活指南49条
-
多模态高效架构:Deeply Stacking Visual Tokens
-
高效生活:五大时间管理工具用法对比分析
-
如何保证Agent的上下文Memory清晰
-
突破textual content限制:RAG-Anything
-
Mate超级实验室推出低成本RL: Scaling Agent Learning
-
Alibaba提出 Logics-Parsing 端到端文档解析模型
-
SimpleVLA-RL为解决VLA模型数据稀缺与泛化能力弱的高效RL框架
-
Microsoft提出Agent Lightning突破性的解耦思维打破了RL与Agent训练的适配壁垒
-
OpenAI指出语言模型幻觉的核心原因:训练和评估机制的统计必然
-
K2-Think低成本高可用的高效推理系统
-
腾讯小模型:R-4B专为通用auto-thinking设计的MLLM
-
Qwen3-VL:从 “看见” 到 “理解”,从 “认知” 到 “行动”
-
如何创造财富?《黑客与画家》
-
LLM-JEPA:跨领域创新打破 NLP 与视觉表征学习的壁垒
-
常用10+多模态检索Benchmark
-
Less is More:递归小模型
-
Context Engineering系统研究:Context Engineering 2.0
-
新方向:DeepSeek-OCR
-
字节新作多模态小模型:SAIL-VL2