 夜雨聆风
夜雨聆风





面试官:大模型是怎么调用工具的呢 ?
#1. 前言
首先我们开发所谓 Agent,其实就写一堆工具给大模型调用,所以要学习 Agent 开发就得知道大模型是怎么调用工具的。
大模型本质上是一个文本生成模型,它是无法直接访问外部数据和操作外部系统的,如获取实时信息、读取文件等。但如今,主流的代码智能体(如 Claude Code)皆已实现对文件系统的直接操作,使其能够自主完成文件读写、项目构建等复杂任务。
它们是怎么做到的呢?
为了解决大模型无法访问外部数据这个局限,OpenAI 提出了 Function Calling(工具调用)机制,后来 Anthropic、Google 等也推出了类似的功能,统称为 Tool Use。
其核心思想是:大模型根据用户的输入判断如果要调用工具时,就让大模型在生成回答时,能够输出一个结构化的请求,要求外部系统执行某个函数,然后将函数执行的结果返回给模型,大模型再基于结果生成最终回答。
本质上就是 Tools + LLM,也就是工具加大模型。
同理地所谓 AI Agent 开发可以简单理解为编写各种工具函数让大模型调用。当然 AI Agent 除了需要编写工具,还需要规划机制 + 记忆系统 + 安全控制 + ……。
下面我们详细讲解这个机制的实现原理和流程。
注意:本文是使用 Python 语言,所以想了解 Python 入门以及大模型的基础操作知识,可以回看我的上一篇文章:《AI全栈实战:使用 Python+LangChain+Vue3 构建一个 LLM 聊天应用》,Python 是一门非常容易上手的语言,建议大家在 AI 全栈时代掌握它。可以主要看看 `LLM 和 OpenAI 接口快速入门` 章节部分。
#2. LLM 和 OpenAI 接口快速入门
首先我们快手回顾一下上一篇文章中的基础知识点,LLM 和 OpenAI 接口快速入门如下:
import osfrom openai import OpenAIfrom dotenv import load_dotenv# 初始化客户端client = OpenAI(api_key=os.getenv("DEEPSEEK_API_KEY"), # 身份验证凭证,确保你有权访问 APIbase_url="https://api.deepseek.com" # 将请求重定向到 DeepSeek 的服务器(而非 OpenAI))# 构建聊天请求response = client.chat.completions.create(model="deepseek-chat", # 指定模型版本temperature=0.5,messages=[ # 对话消息数组{"role": "user", "content": "你是谁?"}])# 打印结果print(response.choices[0].message.content.strip())
其中比较重要的知识点是消息类型,主要有:system (系统角色)、user (用户角色)、assistant (助手角色)。除了上述的角色外还有一种高级角色,也就是 function/tool (函数/工具角色)。
#3. 定义工具
根据上文我们知道大模型本身不具备执行代码的能力,但它可以通过结构化输出“请求”调用外部工具,其实就是返回的数据中带有一个 tool_calls 的参数。我们开发者需要做的事情就是提前定义好工具的描述(函数名、参数、功能)给到大模型,让大模型知道有哪些工具可以调用。
工具定义必须符合 OpenAI 的规范(其他厂商基本兼容),每个工具包含以下要素:
– type:目前主要是 “function“。
– function:函数的具体描述:
– name:函数名称(在代码中唯一标识)。
– description:函数功能说明,帮助模型理解何时调用。
– parameters:参数定义,采用 JSON Schema 格式,包括参数类型、是否必需、枚举值等。
# 工具定义tools = [{"type": "function","function": {"name": "read_file","description": "读取文本文件内容。","parameters": {"type": "object","properties": {"path": {"type": "string","description": "要读取的文件路径"},"encoding": {"type": "string","enum": ["utf-8", "gbk"],"description": "文件编码格式"}},"required": ["path"]}}}]
上述代码就定义了一个读取文本内容的工具,然后大模型就会根据用户的输入进行判断是否需要调用读取文本内容的工具。注意上面只是定义,真正读取文本内容的工具需要我们自己实现。
#4. 发起请求,附带工具描述
定义了工具之后在调用模型 API 时,通过 tools 参数传入上述工具定义,并设置 `tool_choice=”auto”` 让大模型自主决定是否调用。
response = client.chat.completions.create(model="deepseek-chat",temperature=0.5,messages=messages,tools=tools, # 通过 `tools` 参数传入上述工具定义tool_choice="auto" # "auto":大模型自主决定是否调用工具(默认)、"none":禁止调用工具)
一般执行的结果数据结构如下:
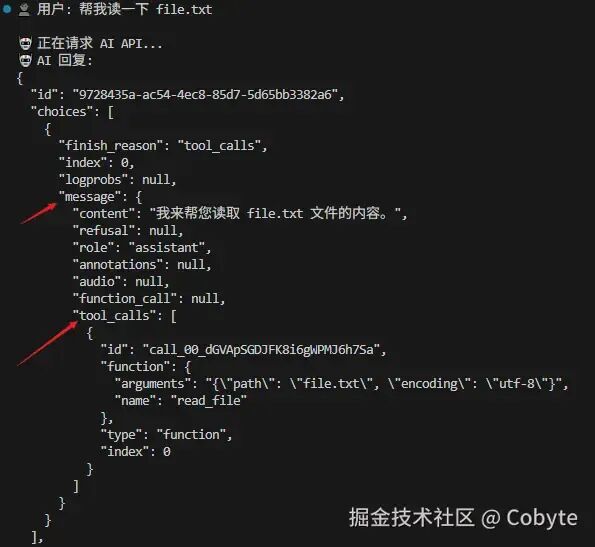
我们看到在 message 下有一个 tool_calls 的参数中返回了数据,这代表大模型需要调用外部工具。
#5. 解析模型响应,提取工具调用请求
通过前面我们知道大模型返回的 message 中若包含 tool_calls 字段,则表示需要调用工具。tool_calls 是一个列表,每个元素包含:
– id:工具调用唯一标识。
– function.name:要调用的函数名。
– function.arguments:JSON 格式的参数。
接下来,我们就需要根据 tool_calls 字段去判断需要执行哪些工具:
msg = response.choices[0].messageif msg.tool_calls:for tool_call in msg.tool_calls:if tool_call.function.name == "read_file":args = json.loads(tool_call.function.arguments)result = file_tool.execute(**args) # 执行本地函数
这个 read_file 只是一个判断标记,代表需要执行读取文件,这个标记是在定义工具的时候我们自己设置的。file_tool 则是一个本地函数,需要我们编写的。
读取文件的函数如下:
from pathlib import Pathclass ReadFileTool:"""读取文件内容"""def execute(self, path: str, encoding: str = "utf-8") -> str:try:file_path = Path(path).expanduser()if not file_path.exists():return f"❌ 文件不存在: {path}"return file_path.read_text(encoding="utf-8")except Exception as e:return f"❌ 读取失败: {str(e)}"# 初始化工具实例file_tool = ReadFileTool()
#6. 执行本地函数,并返回结果
我们根据函数名调用对应的本地函数,获得结果后,构造一条 tool 角色的消息,包含 tool_call_id 和 content(上述执行本地读取文件函数的结果 result),追加到对话历史中,重新发给大模型。
messages.append({"role": "tool","tool_call_id": tool_call.id,"content": result})
#7. 二次请求:让模型基于工具结果生成最终回答
将更新后的消息历史再次发送给大模型,不再需要传入我们的定义的工具(tools),大模型会结合工具执行结果,生成连贯的自然语言回答。
second_response = client.chat.completions.create(model="deepseek-chat",messages=messages)final_answer = second_response.choices[0].message.content
#8. 完整代码示例:文件读取助手
以下便是上述例子代码完整示例,展示了从工具定义、调用、执行到生成最终回答的全过程。
import osimport jsonfrom pathlib import Pathfrom dotenv import load_dotenvfrom openai import OpenAI# 加载环境变量(如 DEEPSEEK_API_KEY)load_dotenv()# ---------- 工具定义 ----------tools = [{"type": "function","function": {"name": "read_file","description": "读取文本文件内容。","parameters": {"type": "object","properties": {"path": {"type": "string", "description": "要读取的文件路径"},"encoding": {"type": "string", "enum": ["utf-8", "gbk"], "description": "文件编码格式"}},"required": ["path"]}}}]# ---------- 工具实现 ----------class ReadFileTool:def execute(self, path: str, encoding: str = "utf-8") -> str:try:file_path = Path(path).expanduser()if not file_path.exists():return f"❌ 文件不存在: {path}"return file_path.read_text(encoding=encoding)except Exception as e:return f"❌ 读取失败: {str(e)}"file_tool = ReadFileTool()# ---------- 初始化客户端 ----------client = OpenAI(api_key=os.getenv("DEEPSEEK_API_KEY"),base_url="https://api.deepseek.com")# ---------- 构建对话 ----------messages = [{"role": "system", "content": "你是一个文件读取助手,必要时可以调用工具帮助用户读取文件内容。"}]user_input = "帮我读一下 file.txt"messages.append({"role": "user", "content": user_input})print(f"👤 用户: {user_input}\n")# 第一步:请求模型判断是否调用工具response = client.chat.completions.create(model="deepseek-chat",messages=messages,tools=tools,tool_choice="auto")msg = response.choices[0].messagemessages.append(msg.model_dump())# 第二步:处理工具调用if msg.tool_calls:for tool_call in msg.tool_calls:if tool_call.function.name == "read_file":args = json.loads(tool_call.function.arguments)result = file_tool.execute(**args)print(f"🔧 调用工具: {tool_call.function.name}, 参数: {args}")print(f"✅ 工具执行结果:\n{result}\n")messages.append({"role": "tool","tool_call_id": tool_call.id,"content": result})# 第三步:二次请求,生成最终回答second_response = client.chat.completions.create(model="deepseek-chat",messages=messages)final_msg = second_response.choices[0].messageprint(f"💬 助手: {final_msg.content}")else:print(f"💬 助手: {msg.content}")
最后执行的内容如下:
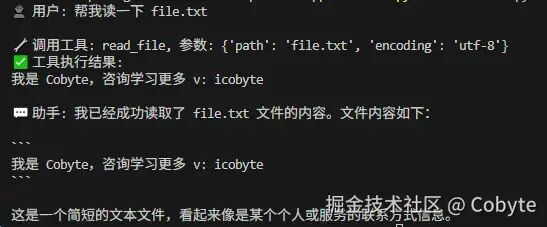
至此我们可以总结一下大模型调用工具的原理是什么了。大模型调用工具的工作流程如下:
– 定义工具(用 JSON Schema 描述函数名称、功能、参数)。
– 将工具描述附加到模型请求中。
– 模型根据用户输入判断是否需要调用工具,以及调用哪个工具和参数。
– 解析模型的响应(tool_calls)。
– 执行本地函数,获得结果。
– 将结果作为新的消息(tool role)发送给模型。
– 模型结合工具结果生成最终回答。
#9. 总结
大模型本身不具备执行代码的能力,但它可以通过结构化输出“请求”调用外部工具。开发者提前定义好工具的描述(函数名、参数、功能)给到大模型,这样大模型在生成回复时,就会判断如果需要工具辅助,就会返回一个特殊的 `tool_calls` 字段,指明要调用的函数和参数。随后开发者也根据大模型返回的 `tool_calls` 字段判断需要执行哪些本地函数,并将执行结果以 `tool` 角色的消息重新发给大模型,大模型再整合生成最终答案。
这种机制极大地扩展了大模型的能力边界,使其能够与外部系统交互,完成实时查询、文件操作、数据库访问等任务,真正成为智能应用的“大脑”。
我是 Cobyte,欢迎添加 v: icobyte,学习 AI 全栈。