🐉 龙哥读论文知识星球来了!
还在为复杂的视频剪辑软件头疼?想了解如何用AI一键生成大片?星球每日拆解视频生成、AI创作、大模型应用等前沿论文,让你像读故事一样轻松掌握核心技术!👇扫码加入「龙哥读论文」知识星球,解锁未来创作新姿势~

龙哥推荐理由:
这篇来自Adobe研究院的论文,提出了一种颠覆性的视频创作范式。它不再要求你学习复杂的剪辑软件,而是让你回归最熟悉的写作本身。如果你曾梦想过“我手写我心,我心映我影”,那么Doki可能就是通往那个梦想的钥匙。它不仅是一个工具,更是一种关于人机协作、创意表达的全新思考,非常值得所有对AI创作感兴趣的朋友一读。
原论文信息如下:
论文标题:
A Text-Native Interface for Generative Video Authoring
发表日期:
2026年03月
发表单位:
Adobe Research
原文链接:
https://arxiv.org/pdf/2603.09072v1.pdf
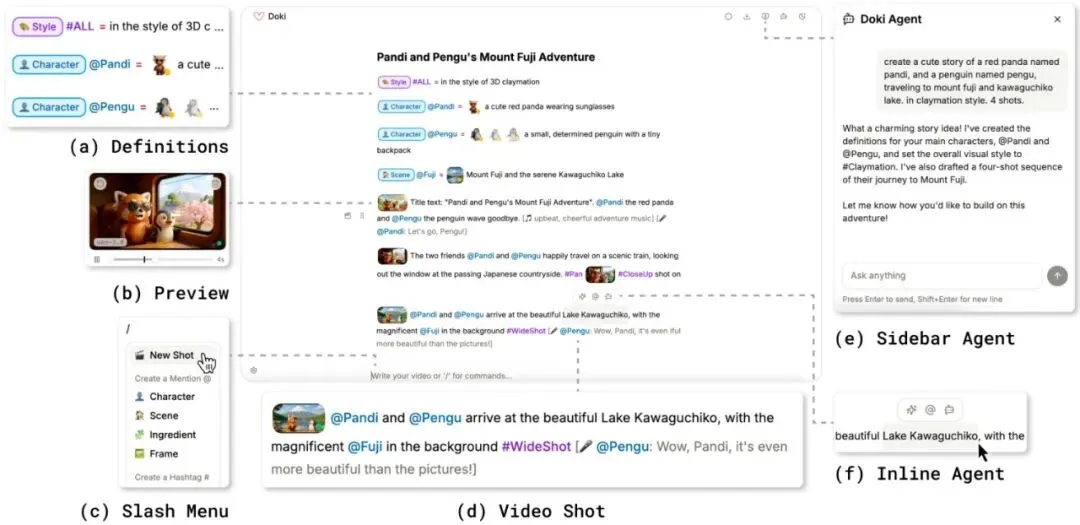
图1: Doki是一个文本原生的视频创作界面,在单个文档中创建生成式视频。 (a) 用户使用@提及和#标签定义可重用的资产和风格,(b) 查看和调整内联预览,(c) 通过斜杠菜单访问命令,(d) 编写编译成视频镜头的段落,并与 (e) 对话式AI代理和 (f) 内联代理协作。
告别时间线!用写文档的方式拍电影?
想象一下,你要创作一个短视频。现在的主流流程大概是:打开剪映或者Premiere,面对复杂的时间线轨道,导入素材,一点点拼接、调整、加特效……光是想想就头大。😫
或者,你用Runway、Pika之类的AI视频生成工具。结果往往是:写一个长长的提示词,生成一个几秒的片段,觉得不对再改,然后把这些零碎的片段导出来,再扔进另一个剪辑软件里去排列组合、配音乐……依然繁琐。
有没有一种可能,创作视频能像写作文一样简单?你只需要打开一个空白的文档,像构思故事一样写下:“一个可爱的柯基犬来到了机场,它带着行李,然后登上了飞机……” 随着你的文字流淌,旁边的预览窗口里,一个符合你描述的、画面连贯的动画短片就自动生成了。
这不是科幻。Adobe Research的研究员们真的做出了这样一个工具,名叫Doki。他们管这叫“文本原生(Text-Native)”的视频创作界面。它的目标极其清晰:干掉复杂的时间线,让写文档成为创作视频的唯一方式。
论文作者们调研了当前的AI视频创作流程,发现大家普遍面临三大痛点:
1. 工具碎片化:写剧本用一个软件(如Word),生成角色图用另一个(如Midjourney),生成视频片段再用第三个(如Veo),最后合成剪辑用第四个(如Premiere)。创作者像个不停切换工具的杂技演员,思路不断被打断。
2. 提示词凌驾于故事之上:为了生成30个镜头,你可能要写30段冗长、重复的提示词,反复微调。精力全耗在“如何让AI听懂”上,而不是“如何讲好故事”。
3. 一致性难题:让AI记住同一个角色在不同镜头里的样子,堪比让金鱼记住三秒前的事。今天生成的柯基是可爱的,下一秒可能就变成了狰狞的“地狱犬”。
所以,Doki应运而生。它的核心理念是:文本应该成为创作的中心媒介。文本既是人类最自然的表达方式,也是AI的“母语”。在同一个文档里,你定义角色、撰写故事、生成预览、调整细节、添加音频……所有操作,一气呵成。
这听起来有点像“所见即所得”的升级版——“所写即所得”。
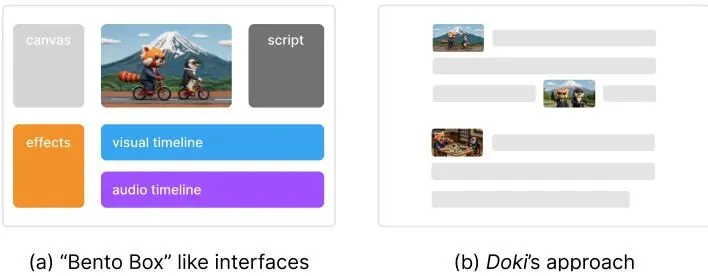
图2:界面范式的比较。(a) “便当盒”式界面将创作分散在多个独立的表征中。(b) Doki的方法使用文本原生的规范表征,文档本身就是主要界面。
Doki核心揭秘:文本如何变成视频?
Doki的秘密,藏在一个极其优雅的三层映射结构里:
文档 (Document) → 整部视频 (Video)
你打开的这个空白文档,就是你的视频项目本身。文档的全局结构决定了视频的叙事流。
段落 (Paragraph) → 序列 (Sequence)
在电影里,一个场景(Scene)可能由多个镜头组成,这叫一个序列。在Doki里,你每开始一个新段落,就相当于开启了一个新的叙事单元或场景。段落内的所有内容在时间上是连续的。
句子/镜头标记 (Sentence/Shot) → 单个镜头 (Shot)
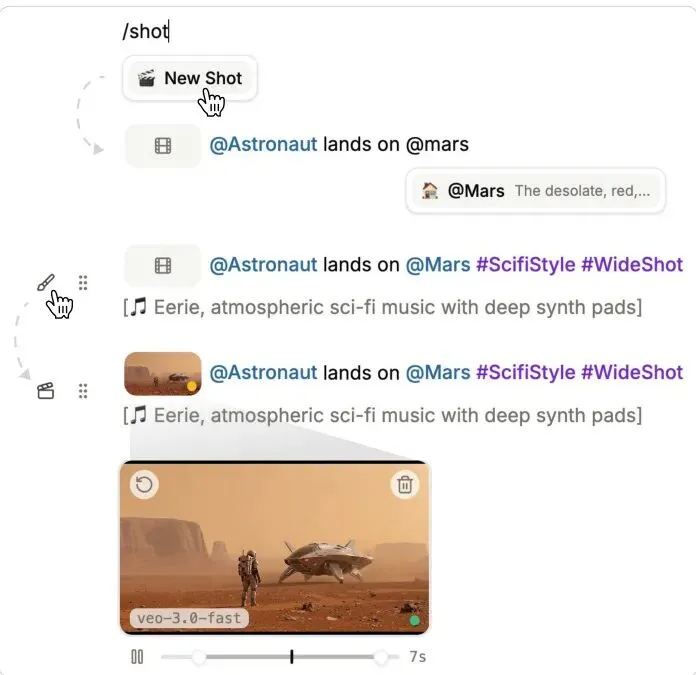
这是最核心的操作。你不需要去时间线上拖拽。在文档里,当你敲入一个斜杠“/”,选择“New Shot”,文档中就会插入一个特殊的镜头标记。紧接着这个标记写的所有描述性文字,就自动成为了这个镜头的“提示词”。
图4:在Doki中创建一个镜头。通过斜杠命令内联插入一个新镜头,其后的描述即为其提示词。系统首先生成预览图像,然后可将其转换为视频片段。用户可以点击展开以进行播放和获得更多控制。
这个镜头标记最初会显示为一个小的占位符。当你点击生成,它会先变成一个静态的图片预览(这步快且便宜),让你确认画面是否符合预期。满意后,你再点击生成视频,它才会变成一段真正的动态视频片段,并内嵌在文档中显示第一帧。你可以随时点击播放。
更妙的是,同一个段落内的多个镜头是连续的。比如你在一个段落里写了两个镜头:“柯基到达机场”和“柯基登上飞机”。Doki在生成第二个镜头时,会自动把第一个镜头生成的画面作为上下文参考,从而确保场景、角色风格的连贯性,你不需要在第二个镜头的描述里重复说“在同一个机场”。
图5:在单个段落内编写连续的镜头。后面的镜头继承前面镜头的上下文,从而实现序列内的连续性。我们无需在Doki文档中重复描述上下文,就能实现镜头间的高度一致性。
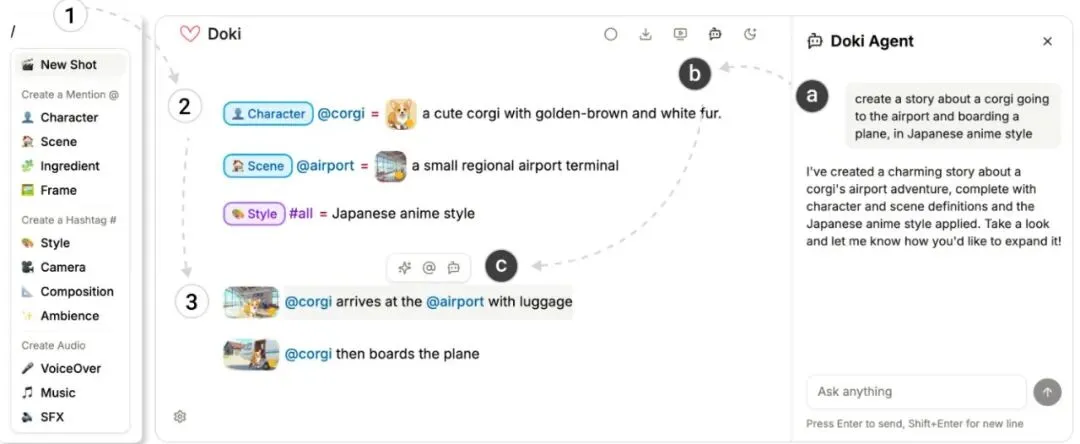
图3:Doki中的两个基本工作流程示例。Alice: (1) 使用斜杠命令定义资产和镜头 → (2) 编写故事并生成预览 → (3) 创建视频镜头;Bob: (a) 向侧边栏代理索要草稿 → (b) 审阅AI生成的草稿 → (c) 使用内联AI代理进行精修。
参数化魔法:一招解决AI视频“变脸”难题
前面提到AI记不住角色,Doki的解决方案堪称一绝:参数化定义。这就像是给你的故事元素创建了一个“变量”。
在文档开头(或任何地方),你可以用斜杠菜单创建各种定义,主要分两大类:
@提及 (Mentions) – 故事里的“名词”
比如:@corgi = 一只拥有金棕色和白色毛发的可爱柯基犬
#标签 (Hashtags) – 故事里的“形容词/副词”
比如:#AnimeStyle = 日式动漫风格,色彩明亮,线条清晰
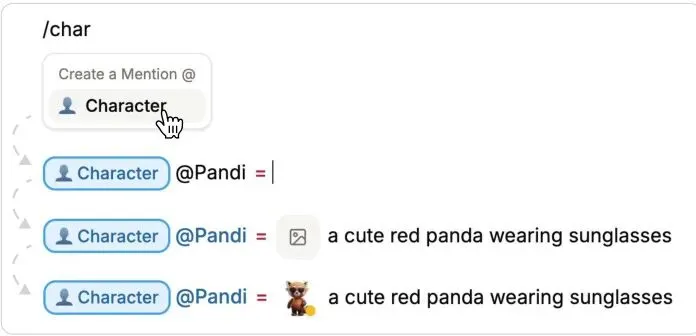
图6:在Doki中创建定义。用户输入“/”打开命令菜单,选择类型,并提供名称和描述。他们还可以选择添加视觉定义以获得更好的一致性。
定义好后,你就可以在文档后文的镜头描述里,轻松地“调用”这些变量了。比如你的镜头描述可以写成:
“@corgi 兴奋地跑进 @airport, #CloseUp 它的表情。整体风格是 #AnimeStyle。”
Doki的引擎在生成这个镜头时,会自动把 @corgi、@airport 等“变量名”替换成你之前写好的详细描述,组合成一个完整、精确的提示词送给AI模型。这解决了“重复描述”的麻烦。
但光有文本描述,AI的理解还是有偏差。怎么办?“视觉定义”来了!在创建 @corgi 的时候,你可以当场为它生成一张(或多张)参考图。这张图会和它的文本描述绑定在一起。
此后,任何调用 @corgi 的镜头,在生成时,Doki不仅会传入文本描述,还会把这张参考图作为“形象模板”塞给视频生成模型(如Veo)。这样,柯基的样子就被牢牢“锁死”了!🎯
这才是真正的降维打击。它把维持一致性的责任,从用户的大脑和重复劳动中,转移到了系统的结构化设计里。你想修改整个视频的风格?只需回头把 #AnimeStyle 的定义从“日漫风”改成“粘土定格动画风”,所有引用了这个标签的镜头会自动标记为“已过期”,你一键即可批量重新生成。效率提升了不止一个数量级。
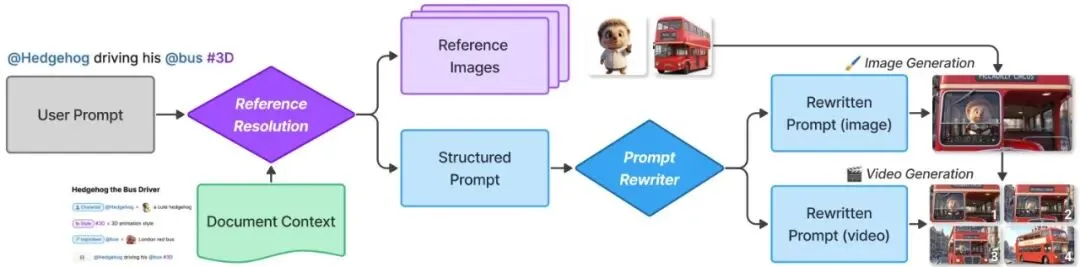
图10:Doki的镜头生成流程。首先,用户的原始提示词和文档上下文被传递给参考解析模块,以创建结构化提示词并从定义中收集相关的视觉参考图像。然后,提示词重写器将此结构化提示词进行改写和润色,用于图像和视频生成。Doki首先生成一个静态预览图像,然后使用该图像作为第一帧来生成最终的视频片段。
人机共舞:你是导演,AI是全能剧组
Doki的交互设计极其简洁,但背后的AI协作能力却很强大。它提供了两种与AI共事的模式:
模式一:亲力亲为的“编剧导演”(图3-Alice)
你享受从零开始构建的掌控感。自己敲斜杠命令定义角色、场景、风格,然后在文档里一行行写下故事,插入镜头标记,逐个生成和调整。AI在这里更像一个高效、听话的“摄影师”和“特效团队”,严格执行你的文本“分镜稿”。
你有一个模糊的想法,比如“一个柯基在机场登机的日漫风格短片”。你可以直接把这个想法丢给Doki的侧边栏AI代理(Conversational AI Agent)。
这个代理(基于大语言模型)会理解你的需求,并直接在文档里生成一个完整的草稿:包括定义好的@corgi、@airport、#AnimeStyle,以及几个镜头的段落描述。你拿到的是一个立即可执行的“初版剧本”。
接下来,你可以进行精修。这里又有一个利器:内联AI代理(Inline Agent)。你可以选中一段描述文字,对它说:“把这里改得更戏剧化一点”,或者“给这个镜头加上背景音乐描述”。AI会理解上下文,直接修改你选中的文本。
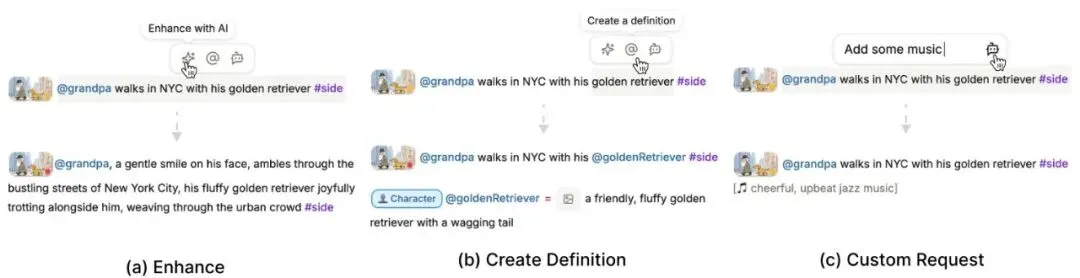
图9:三种类型的内联代理操作。(a) “增强”增加所选文本的描述性。(b) “创建定义”将所选内容转换为可重用的定义。(c) “自定义请求”根据用户指令进行上下文编辑。
最关键的是,所有的AI协作都发生在文本层面,并且结果完全透明、可编辑。你不会得到一个看不懂的“黑盒”视频。你得到的是一份被AI优化过的、更详细的“拍摄脚本”。你可以随时否决、修改AI的提议。你始终是掌握最终决定权的导演。
文本,成为了人机之间完美的“共同基础(Common Ground)”。
一周实测:新手变导演,专家加速器
为了验证Doki的效果,研究者们进行了一项为期一周的日记研究,邀请了10位背景各异的参与者,从毫无视频制作经验的新手到专业电影制作人。
一周后,成果斐然:10个人共创作了46个视频。Doki的系统可用性量表(SUS)平均得分高达81.2分,属于“优秀”级别。
图11:日记研究中参与者创作视频的示例帧。这些视频展示了Doki支持的视频类型的广度。每一行对应一个视频,从左到右显示四个代表性关键帧。
对新手:赋能 从未做过视频的人发现,他们脑子里天马行空的想法,第一次可以如此轻松地变成可视化的故事。他们不再被技术门槛吓退,而是能专注于叙事本身。“我竟然能做出这个!”是常见的兴奋反馈。
对专家:加速 专业创作者并没有把Doki当作最终的生产工具来替代Premiere,而是视为一个超级高效的故事板和预可视化(Pre-visualization)工具。他们可以用它快速验证创意、生成动态分镜,与团队沟通想法,其速度远超手绘或传统软件拼接。一位参与者说:“它就像我的创意加速器。”
共同优点: 所有人都称赞“从想法到草稿”的流程极大加快,文档视图让他们对叙事结构一目了然,参数化定义是保持故事连贯性的“脊柱”。
模型的可预测性:AI生成的结果仍有随机性,有时不如预期。
精确控制:难以实现非常精细的、帧级别的控制(比如特定的手势、口型)。
时间表达性:用文本描述复杂的时间动态(如“镜头缓缓推进,然后快速切到…”)依然比较抽象。
未来已来?文本原生创作的机遇与挑战
Doki不仅仅是一个工具原型,它更代表了一种创作范式的可能性。当视频生成变得像打字一样简单,会发生什么?
全民创作时代:任何人,只要会写字,就有可能成为视频创作者。教育、营销、个人表达的门槛将被无限拉低。
可迭代、可版本控制的故事:视频项目变成了一个文本文件,可以像代码一样进行版本管理(Git)、协作编辑、差异对比。修改历史和创作过程一目了然。
新型人机协作模式:Doki展示了AI作为“增强智力”而非“替代人力”的理想角色。人类负责高层次的创意和决策,AI负责高效执行和提供建议。
“精确度”与“创意自由度”的永恒矛盾:越是追求精准控制,文本描述可能就越像编程,失去自然语言的灵动。如何平衡是关键。
模型能力的边界:Doki的强大,一半源于其精妙设计,另一半依赖于底层视频生成模型(如Veo, Imagen)的能力。这些模型在物理模拟、复杂动作、长时序一致性上仍有很长的路要走。
从原型到产品:目前的Doki是一个研究原型。要变成真正可用的产品,需要解决性能优化、成本控制(视频生成很烧钱)、更丰富的素材库、与专业工作流的对接等一系列工程问题。
龙迷三问
Doki到底是个啥?和Runway、Pika有什么区别?Doki不是一个独立的视频生成模型,而是一个顶层的“创作界面”或“整合平台”。Runway、Pika、Veo这些是它的“发动机”,负责根据提示词生成单段视频。Doki做的事情是:1) 让你用写文档的方式,轻松管理和串联无数个提示词(镜头);2) 通过参数化系统解决角色、风格一致性问题;3) 把所有创作环节(脚本、生成、预览、简单编辑)整合在一个文本编辑器里。你可以理解为,Doki是建立在多个AI视频模型之上的“视频版Word”。
文本“参数化”具体是怎么工作的?你可以把它想象成编程里的“变量”和“函数”。在文档开头,你定义了一个变量,比如 @hero = 一位穿着红色披风的超人。之后在写镜头描述时,你不用每次都写“一位穿着红色披风的超人”,只需写“@hero 在天空中飞翔”。Doki的系统在真正调用AI模型生成前,会自动进行“变量替换”,把 @hero 替换成其完整的描述,并结合视觉参考图,形成最终的、详细的生成指令。这保证了每次提到 @hero 时,AI收到的信息都是一致的。
文中提到的“Bento Box”风格界面是什么意思?“Bento Box”(便当盒)是论文中对当前很多AI创作工具界面的一种形象比喻。就像一个便当盒里有好几个格子分开装菜和饭,这些工具也常常把不同的功能放在不同的面板或窗口里:一个窗口写提示词,一个窗口看生成结果,一个窗口是时间线,一个窗口是资产库……创作者需要不停在几个窗口之间切换视线、同步信息,注意力是“分裂”的。Doki反其道而行之,追求“单一表征”,把所有东西都整合在“文档”这一个大窗口里,减少认知负担。
如果你还有哪些想要了解的,欢迎在评论区留言或者讨论~
龙哥点评
论文创新性分数:★★★★☆
将视频创作完全映射到文本编辑的“文档即视频”范式,在思路上具有显著的创新性。参数化定义系统优雅地解决了生成式视频的一致性难题,是其核心亮点。
实验合理度:★★★★☆
采用为期一周的日记研究(Diary Study)进行“在野”评估,相比单纯的实验室任务更能反映真实使用情况。参与者的多样性(新手到专家)和产出的视频数量(46个)提供了有说服力的质性见解。
学术研究价值:★★★★★
价值极高。本文不仅提出了一个工具原型,更重要的是系统地阐述了“文本原生”交互范式的设计原则(如统一表征、参数化、人机共同基础),为未来AI驱动的创作工具设计提供了清晰的理论框架和方向指引,对HCI(人机交互)和创意支持社区影响深远。
稳定性:★★★☆☆
作为一个研究原型,其稳定性高度依赖于底层视频生成模型(如Veo)的稳定性。AI生成的随机性、不可预测性仍然是主要瓶颈,会导致输出质量波动。
适应性以及泛化能力:★★★★☆
得益于其文本基础和参数化设计,理论上可以适配任何支持文生图/文生视频的模型。其结构化表示方法具有较强的泛化能力,可扩展到其他模态的生成任务(如3D场景生成)。
硬件需求及成本:★★☆☆☆
主要成本来自于调用商用AI生成API(如Google的Imagen和Veo)。根据论文数据,生成一个视频片段(Veo)成本约为$3.2,频繁创作成本不菲。对最终用户端的硬件要求不高,主要是网络和界面交互。
复现难度:★★☆☆☆
难度较高。论文提供了详细的设计理念和系统架构,但并未开源完整代码。复现需要自行实现复杂的文档解析、参数替换、上下文管理引擎,并接入多个收费的AI服务API,工程门槛不低。
产品化成熟度:★★★☆☆
目前是成熟的研究原型,展示了核心可行性。要成为大众产品,需解决生成成本、输出确定性、更精细的编辑控制、音频视频同步优化以及与专业工作流(如导出工程文件到Final Cut Pro)的对接问题。
可能的问题:本文的评估偏重质性,缺少与传统方法在量化指标(如任务完成时间、错误率)上的严格对比。对于“文本原生”范式是否在所有视频创作场景下都优于“便当盒”范式,结论可能有些绝对化。长视频的宏观节奏控制,仅靠段落划分可能仍显不足。
Liu, X. B., Dontcheva, M., & Li, D. (2025). A Text-Native Interface for Generative Video Authoring. In Proceedings of the ACM Conference (To appear).
*本文仅代表个人理解及观点,不构成任何论文审核或者项目落地推荐意见,具体以相关组织评审结果为准。欢迎就论文内容交流探讨,理性发言哦~ 想了解更多原文细节的小伙伴,可以点击左下角的“阅读原文”,查看更多原论文细节哦!

想亲手试试“用文档拍电影”的感觉吗?想和更多视频生成、大模型、AI创作的同好交流?
扫描下方二维码或者添加龙哥助手微信号加群:kangjinlonghelper。
一定要备注:研究方向+地点+学校/公司+昵称(如 视频生成+北京+Adobe+龙迷),根据格式备注,可更快被通过且邀请进群。


 夜雨聆风
夜雨聆风