保姆级全流程教程,大模型一键把文档转成高清视频,配音 + 字幕 + 画面全自动化!附完整可运行代码!
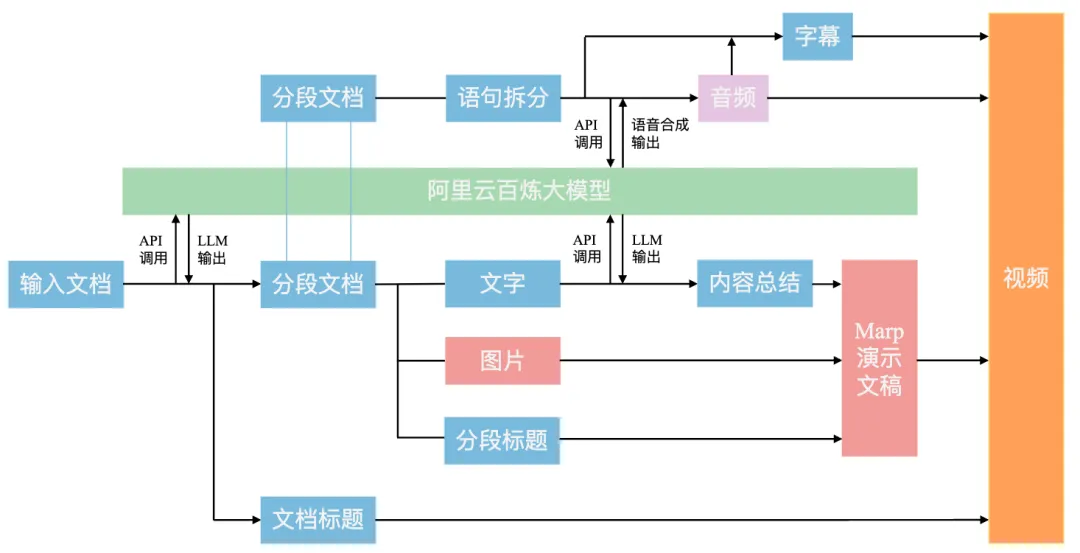
你是不是也遇到过这样的困境?手里有一份干货满满的课程文档、培训课件、职场方案,想把它做成视频,却被狠狠卡住:不会专业的剪辑软件,PR、AE 看了就头大;自己配音普通话不标准,找 AI 配音还要一句句导出对齐;打字幕要耗几个小时,画面和音轨对不上反复返工;哪怕是最简单的图文讲解视频,前前后后也要花大半天,效率低到离谱。 今天这篇文章,就给你带来一套彻底解放双手的终极解决方案 —— 依托通义千问大模型,实现文档到视频的全自动化生成。不用你手动剪一帧,不用你录一句音,甚至不用你打一个字的字幕,只要一份 Markdown 文档,就能自动生成带高清图文、专业配音、精准字幕的完整讲解视频,新手也能跟着步骤一步落地。 先搞懂核心逻辑:4 步实现文档到视频的全自动转换。这套方案的全流程,拆解开来就是四大核心环节,环环相扣,全自动化完成,哪怕你完全不懂视频制作,也能一眼看懂全貌:
文档切片: 首先,我们运用大模型来总结文档标题,将文档划分为不同段落。并为每个段落生成一个概括性的段落标题。
生成演示文稿: 紧接着,我们整合各部分内容,包括标题、正文以及图片等,利用这些素材生成演示文稿图片。
生成讲解语音与字幕: 接下来,我们采用多模态大模型技术,将文字材料转换成音频文件,并依据音频的播放时长自动生成配套的文字字幕。
生成视频: 最后我们将所有演示文稿图片剪辑为视频,并将音频与字幕文件嵌入视频。
接下来,就进入保姆级的实操环节,从环境准备到代码落地,每一步都给你讲得明明白白,哪怕你是刚接触 Python 的新手,也能跟着做出成品。 一、前期准备工作:30 分钟搞定所有环境,避坑指南都在这 这套方案的门槛极低,你不需要有任何的 AI 开发经验,只要你的电脑能装 Python,能连上网,就能跑通。我们先把所有的前置环境和工具一次性装好,避免大家中途踩坑。 1. 必备前提:获取大模型API Key 这套方案的核心能力依赖大模型,所以第一步,你需要先获取一个 API Key,用来调用大模型能力。 2. 核心工具安装:FFmpeg + Marp 这套方案里,我们用到两个非常强大的开源工具,一个是音视频处理神器 FFmpeg,另一个是 Markdown 转演示文稿的工具 Marp,下面给大家不同系统的安装命令,直接复制到终端运行就行。 MacOS 系统安装命令:
# 安装FFmpeg(音视频处理必备) brew install ffmpeg# 安装node环境(Marp依赖) brew install node # 配置国内镜像源,避免安装失败 npm install -g cnpm --registry=https://registry.npmmirror.com # 安装Marp cnpm install -g @marp -team/marp-cli
Windows 系统安装(用 conda 环境更省心):
# 先安装nodejs conda config --add channels conda-forge conda install nodejs # 配置淘宝镜像 npm config set registry https://registry.npmmirror.com # 安装Marp npm install -g @marp-team/marp-cli # 安装FFmpeg conda install -c conda-forge ffmpeg
这里提醒一下,Marp 生成图片需要浏览器引擎渲染,所以你的电脑里要装 Chrome、Edge 或者 Chromium 浏览器,这个大家基本都有,不用额外装。
3. Python 环境与依赖库安装 这套方案全流程基于 Python 实现,所以我们先配置好 Python 虚拟环境,避免依赖冲突,新手推荐用 Miniconda 来管理环境,非常方便。 第一步:创建并激活 Python 虚拟环境
# 创建Python3.12的虚拟环境,名字可以自己改 conda create --name py12 python=3 .12 # 激活虚拟环境 conda activate py12
第二步:一键安装所有需要的 Python 依赖库
pip install --upgrade pippip install urllib3==1 .25 .8 pip install pyppeteerpip install dashscopepip install --upgrade dashscopepip install pydubpip install natsortpip install moviepypip install ffmpeg-pythonpip install --upgrade requests
如果安装过程中遇到 urllib3 版本冲突的报错,比如提示 pyppeteer 需要低版本的 urllib3,直接运行下面三行命令就能解决:
pip uninstall urllib3pip install "urllib3<2.0.0,>=1.25.8" pip install pyppeteer==2 .0 .0
到这里,所有的前期准备工作就全部完成了,是不是很简单?接下来,我们先给想快速上手的朋友,准备了 3 分钟极速体验的方法,想先跑通看效果的可以直接看这部分;想搞懂每一步原理、做个性化定制的朋友,可以直接跳后面的分步拆解。
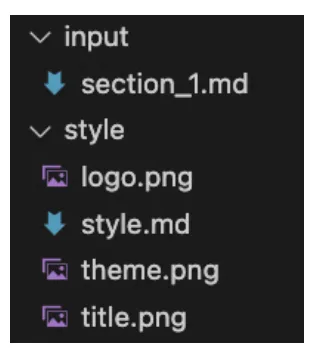
二、极速体验:3 步跑出成品视频,零代码也能玩 如果你想先快速体验效果,不想一步步写代码,直接下载官方提供的完整代码包,解压后,三步就能跑出成品视频: 把你的文档写成 Markdown 格式,命名为section_1.md,放到input文件夹里;
把你的 logo、背景图、标题图放到style文件夹里,替换掉默认素材;
打开终端,进入代码目录,运行对应的命令:
Mac/Linux 系统运行命令:
Windows 系统运行命令(用 WSL 或 Git Bash):
运行之后,程序会自动完成全流程的处理,你可以在result.log里查看运行日志,最终生成的成品视频,会直接保存在./material/video文件夹里,连长文档都能自动拆分合并,一步到位。 三、保姆级分步拆解:从 0 到 1 搭建文档转视频工程 如果你想搞懂每一步的原理,想要个性化定制自己的视频,那接下来的内容,你一定要认真看,每一个环节的代码作用、实现逻辑,都给你讲透。 首先,我们先搭建好项目的目录结构,先把文件夹建好,避免后续文件乱放:在你的项目根目录下,需要创建这几个文件夹:
input:用来存放你的输入文档(Markdown 格式)
style:用来存放 logo、背景图、样式文件等素材
material:用来存放中间生成的文件,里面再建json、image、audio、markdown、video这几个子文件夹
然后在根目录下创建main.py,这是我们的主程序文件,所有的步骤都会在这里调用执行,后续我们写好的每个功能模块,都会导入到这个主文件里运行。 步骤一:文档智能切片,让大模型帮你拆解文案 我们做视频,首先要把长文档拆成一个个适合做成单页 PPT 的片段,这个环节,完全交给大模型来做,不用你手动拆分。 给整个文档生成一个核心的主题标题;
按语义把文档拆分成段落,给每个段落生成精炼的小标题,同时把图片链接单独归类,最终输出结构化的 JSON 文件;
给每个段落的内容做要点提炼,适配 PPT 的简洁排版需求。
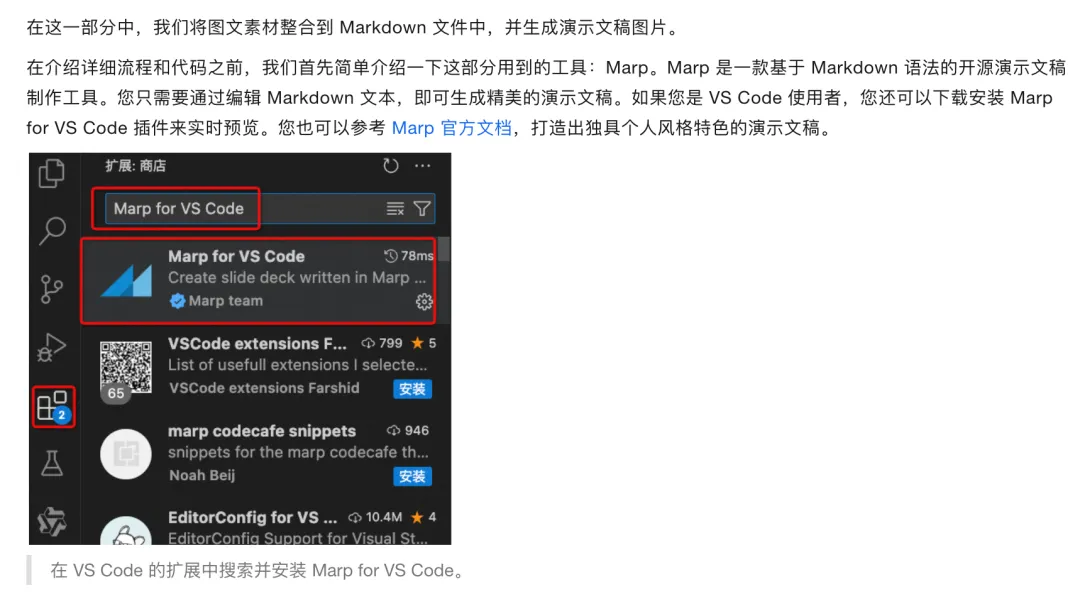
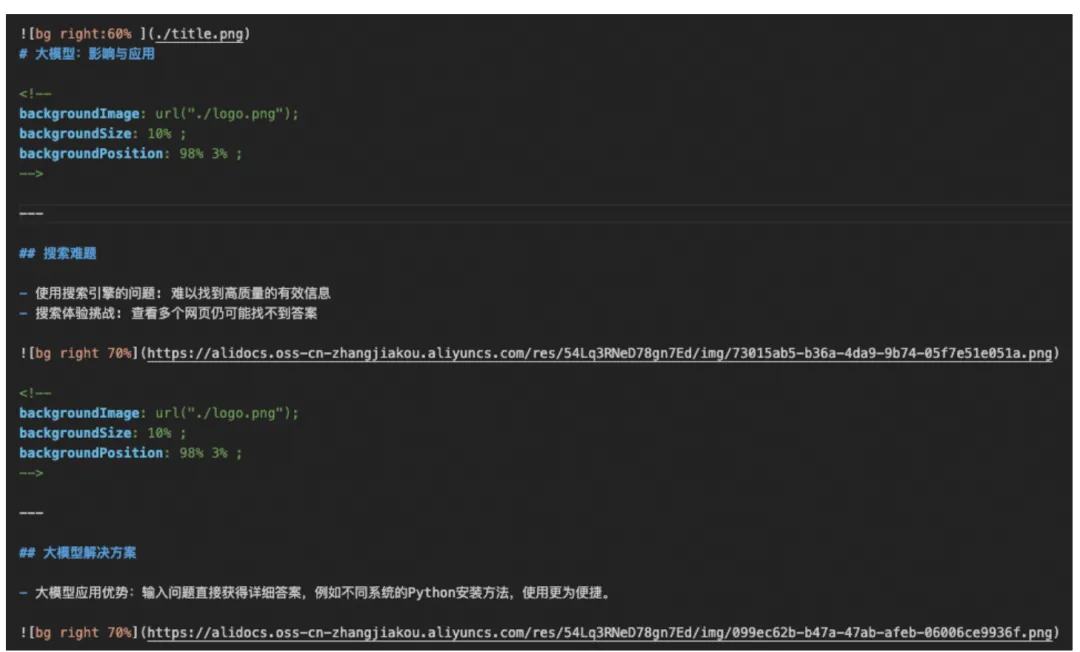
1. 生成文档核心标题 创建theme_generate.py,核心功能是调用通义千问 – Plus 大模型,根据文档内容和你指定的主题,生成精炼的核心标题。我们在 prompt 里明确要求模型只输出标题,不要多余内容,确保生成的标题简洁贴合主题。 写好之后,就可以在main.py里导入并调用这个函数,运行后就能自动生成文档的核心标题,比如示例文档生成的标题就是「大模型:影响与应用」。 2. 文档智能分段与结构化 创建doc_split.py,这是这个环节的核心文件。我们在 prompt 里给大模型明确了分段规则、标题生成要求、JSON 输出格式,要求它必须完整保留原文内容,不能修改,同时把图片链接单独拆分出来。 大模型处理完之后,会直接输出一个结构化的 JSON 数组,每个条目都有title和content字段,后续的所有环节,都基于这个结构化数据来做,完全不用你手动整理文档。运行后,生成的 JSON 文件会自动保存到material/json文件夹里。 3. 文案要点提炼 创建qwen_plus_marp.py,核心功能是给每个段落的内容做要点提炼。因为 PPT 里不能放大段的文字,所以我们让大模型把段落内容提炼成简洁的要点,用 Markdown 列表格式输出,图片链接则直接保留,这样生成的 PPT 画面才会简洁美观,适合视频呈现。 步骤二:自动生成演示文稿,一键搞定视频画面 文档拆分好了,接下来就要生成视频里的画面了。这里我们用到 Marp 这个神器,只要写好 Markdown,就能自动生成精美的 PPT 画面,完全不用你手动调排版。 1. 格式处理工具函数 先创建markdown_gather.py,这个文件里我们写了一系列工具函数,用来处理 Markdown 格式,比如合并样式文件、插入 logo、添加背景图、生成标题页、清理多余格式等等,让生成的 PPT 画面更美观,更符合视频的呈现需求,后续我们直接调用这些函数就行,不用重复写代码。 2. 结构化数据转 Markdown 演示文稿 创建json2md.py,这个文件的核心作用,就是把我们上一步生成的 JSON 结构化数据,转换成符合 Marp 语法的 Markdown 文件。 它会把每个段落的标题、提炼后的要点、图片整合在一起,给每个页面设置好背景图,用—分隔不同的页面,同时把图片做成背景大图,让画面更有视觉冲击力。运行后,生成的 Markdown 文件会自动保存到material/markdown文件夹里。 3. 全局样式统一与图片导出 生成 Markdown 文件之后,我们还要给它加上全局样式,比如 Marp 的主题、字体、颜色、logo 的固定位置等等,这些我们都可以提前写在style文件夹里的style.md文件里,通过markdown_gather.py里的函数,自动合并到每个 Markdown 文件的开头,一键统一所有页面的风格。 然后创建marp2image.py,核心功能就是调用 Marp 的命令行工具,把我们写好的 Markdown 演示文稿,批量导出成高清的 PNG 图片,每一页 PPT 对应一张图片,这些图片,就是我们视频里的核心画面素材,生成的图片会自动保存到material/image文件夹里。 到这一步,视频里的所有画面素材,就全部自动生成好了。你完全不用打开 PPT 软件,不用手动调排版、插图片,只要提前准备好 logo 和背景图,大模型和 Marp 就帮你把所有画面都搞定了,效率直接拉满。 步骤三:AI 配音 + 自动字幕,音画同步一步到位 画面有了,接下来就是视频的灵魂 —— 讲解配音和字幕。传统做视频,最费时间的就是配音和对齐字幕,而在这套方案里,这两步全都是自动化完成的,连时间轴都不用你手动调。 1. 真人级 AI 配音生成 创建audio_generate_each_sentence.py,这个文件实现两个核心功能:第一,把文档里的文案,按标点和语义拆分成一个个完整的句子,避免长句子合成音频时出现断句问题;第二,调用阿里云 CosyVoice 语音大模型,把每个句子都合成为媲美真人的 MP3 音频文件,你可以选择自己喜欢的主播音色,比如温柔的女声、沉稳的男声,合成的音频会按段落和句子分类保存,方便后续处理。 这里要夸一下 CosyVoice,合成的语音自然度非常高,停顿、语气都很贴合真人讲解,完全没有机械感,用来做课程讲解、培训视频,再合适不过了。 2. 自动生成精准字幕 音频生成好之后,我们就要生成对应的字幕了。创建srt_generate_for_each_sentence.py,这个文件的核心功能,就是读取每个音频文件的时长,再对应上句子的文字内容,自动计算好字幕的开始和结束时间,生成标准的 SRT 字幕文件,连句子之间的间隔都给你留好了,完全不会出现音画不同步的问题。 生成的 SRT 字幕文件,会直接保存到material/video文件夹里,后续可以直接嵌入到视频中。这一步下来,你连字幕软件都不用打开,几百字的文案,几秒钟就生成好了精准的字幕,比手动打字幕快上百倍。 步骤四:视频合成与封装,直接导出成品视频 画面、音频、字幕都准备好了,最后一步,就是把这些素材合成为一个完整的视频,并且把音频和字幕都嵌入进去,直接导出可以发布的 MP4 文件。 1. 计算画面时长,确保音画匹配 首先,我们要先计算好每一页 PPT 画面在视频里的停留时长。创建calculate_durations_for_each_image.py,这个函数会自动统计每个段落对应的所有音频的总时长,再给标题页加上合适的停留时间,生成一个时长列表,确保每一页画面的播放时长,和对应的讲解音频完全匹配,不会出现画面播完了音频还没讲完,或者音频结束了画面还停着的问题。 2. 画面剪辑成无声视频 创建movie_editor.py,用 moviepy 库把所有的 PPT 图片,按照我们计算好的时长,依次剪辑成视频片段,拼接成一个完整的无声视频,同时统一视频的分辨率为 1280*720、帧率 30fps,确保画面清晰,播放流畅。运行后,生成的无声视频会保存到material/video文件夹里。 3. 音频嵌入与合并 接下来,我们要把音频合并起来,嵌入到视频里。创建audio2video.py,这个函数会把所有句子的音频片段,按顺序拼接起来,句子之间加上合适的间隔,避免听起来太紧凑,然后把合并好的完整音频,和我们上一步生成的无声视频合并,导出带配音的视频文件。 4. 字幕嵌入,生成最终成品 最后一步,就是把字幕嵌入到视频里。创建srt2video.py,这里我们调用 FFmpeg 的命令,把 SRT 字幕文件烧录到视频里,直接生成带画面、带配音、带字幕的最终成品视频,生成的文件就在material/video文件夹里,打开就能看,直接就能发布到各个平台。 到这里,单篇文档转视频的全流程,就全部实现了。你只要在main.py里,把所有环节的函数按顺序导入和调用,然后运行python main.py命令,程序就会自动跑完所有流程,你只需要等着拿成品视频就行。 四、进阶玩法:长文档一键生成完整视频 很多人会问,我有几十页的长文档,比如一整章的课程内容,能不能一次性生成完整的视频?当然可以,官方也给我们准备好了长文档的处理方案,操作起来非常简单。 方法很简单,你只要把长文档,按章节拆分成多个短文档,按section_1.md、section_2.md、section_3.md…… 这样的命名格式,统一放到input文件夹里。 然后,创建merge_all_videos.py,这个文件里的函数,会自动把每个短文档生成的成品视频,按序号顺序拼接起来,合并成一个完整的长视频。 更方便的是,官方还提供了一键运行的run.sh脚本,这个脚本会自动按顺序处理input文件夹里的所有文档,逐个生成视频,最后自动合并成一个完整的成品视频,全程不用你手动操作,哪怕是几万字的课程文档,也能一键生成完整的讲解视频,太适合做系列课程、长培训内容的朋友了。
# 更改权限 chmod +x run.sh# 运行脚本 ./run.sh
看到这里,相信你已经对这套文档转视频的全流程方案,有了完整的了解。
第一, 极致降本提效 。原来做一个文档讲解视频,要花大半天甚至一整天,现在只要几分钟,全流程自动化完成,人力和时间成本直接降到几乎为零。
第二, 零门槛易上手 。不用你会剪辑、不用你会配音、不用你懂复杂的 AI 开发,只要跟着教程装好环境,准备好文档,就能一键生成成品,新手也能快速落地。
第三, 高度可定制化 。从画面的 logo、背景、排版,到配音的主播音色、语速,再到字幕的样式,你都可以自由修改,做出完全符合自己品牌风格的视频,不会千篇一律。
第四, 成本极低 。阿里云百炼给新用户提供了 100 万 Token 的免费额度,哪怕是额度用完了,通义千问 – Plus 的成本也才 0.004 元 / 千 Token 输入、0.012 元 / 千 Token 输出,做一个视频,成本可能连几毛钱都不到,比找配音、找剪辑划算太多了。
这套方案,几乎能覆盖所有需要把文档转成视频的场景:
知识付费博主、自媒体人:把你的文案、课程稿,快速转成视频,批量产出内容,抢占平台流量;
企业内训讲师、HR:把培训方案、制度文档、产品手册,转成讲解视频,不用反复线下培训,新员工随时能看;
教师、教育工作者:把课件、知识点文档,做成教学视频,线上授课、网课录制都能用;
职场人:把工作方案、复盘报告,做成演示视频,汇报的时候更直观,更能打动领导和客户。
在这个 AI 时代,真正能拉开差距的,不是你有多强的专业技能,而是你会不会用 AI 工具,把重复繁琐的工作自动化,把自己的时间解放出来,去做更有价值的事情。 希望这篇保姆级的教程,能帮你彻底解决文档转视频的痛点。如果你觉得这篇文章对你有帮助,别忘了点赞、在看、收藏,转发给身边有需要的朋友。也欢迎大家在评论区留言,说说你用这套方案的使用体验,或者遇到了什么问题,我都会一一回复。 源码下载:https://gitee.com/soyoger/doc2video
 夜雨聆风
夜雨聆风