 夜雨聆风
夜雨聆风





Multimodal OCR:文档理解的「全能选手」
研究背景
你有没有遇到过这样的场景:拿到一份 PDF,里面有大段文字、复杂的表格、精心绘制的图表,还夹杂着化学分子式和数学公式。你想提取里面的信息,结果传统 OCR 只认字,图表直接被裁成一张图片丢在一边——这些信息就这样丢了。
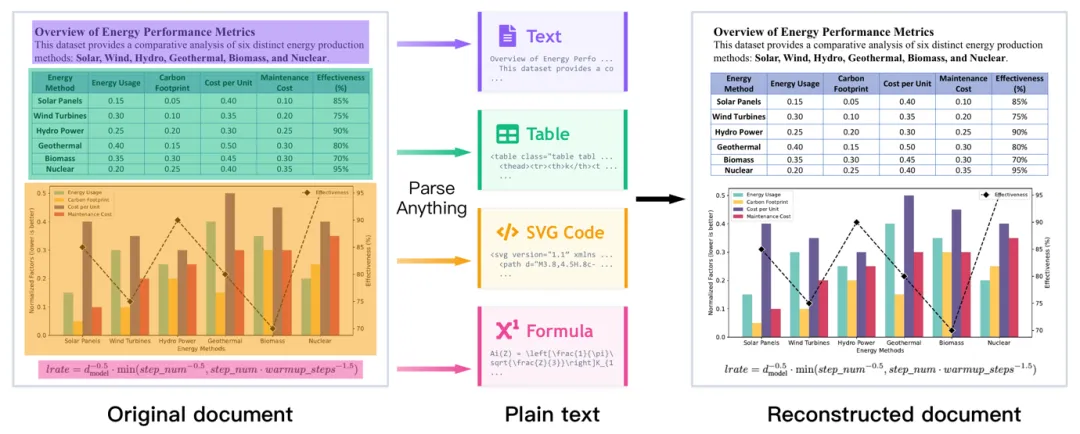
今天介绍的这篇工作,想要做的事情很简单,也很大胆:把文档里的「一切」都解析出来。文字要认,表格要认,图表要变成可编辑的 SVG 代码,公式要变成 LaTeX,流程图也不放过。这就是 Multimodal OCR(MOCR)。
▲ Figure 1:MOCR 整体流程。给定一张文档图片,MOCR 将页面上所有元素统一解析为结构化文本表示,实现原始文档的忠实重建。
上面这张图很直观地展示了 MOCR 的核心理念。左边是一个包含文字、表格和图表的原始文档,中间是模型的解析输出——文字变成纯文本、表格变成 HTML 标记、图表变成 SVG 代码、公式变成 LaTeX——右边则是根据这些结构化输出重建出来的文档。对比左右,几乎完美还原。
1. 传统 OCR 到底丢了什么?
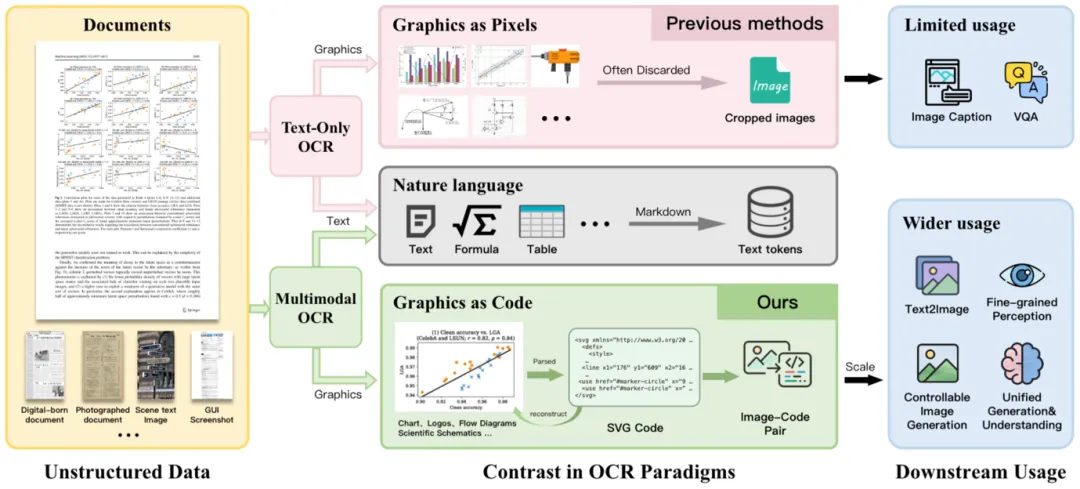
我们日常接触的文档,信息量远不止文字。一张精心制作的柱状图,可能浓缩了一整页报告的核心结论;一个化学结构式,承载着关键的分子信息。但在传统 OCR 流程里,这些非文字区域的命运只有一个——被框出来,裁成一张图片,然后丢掉。
▲ Figure 3:传统 OCR vs MOCR 范式对比。传统 OCR 把图形当像素处理并丢弃;MOCR 将图形解析为结构化代码(如 SVG),实现忠实重建和更广泛的下游应用。
MOCR 的核心洞察:文档中最有价值的信息,往往是视觉的而非文字的。但长期以来,这些视觉元素一直被 OCR 管线当作「二等公民」丢弃。MOCR 把它们升级为一等解析目标,统一转化为可复用的结构化输出。
2. 技术方法
MOCR 的实现系统叫 dots.mocr,由华中科技大学和小红书 hi lab 联合开发,是一个仅 3B 参数的紧凑模型,却覆盖了从文档解析到图形重建的完整能力。
2.1 模型架构
整体架构遵循经典的视觉-语言模型范式,但每个组件都针对文档场景做了深度优化:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
2.2 三阶段渐进式预训练
训练策略是纯数据驱动的,通过精心设计的课程逐步降低学习难度:
-
阶段一:建立视觉-语言接口。通用视觉训练,让语言模型学会「看图说话」 -
阶段二:广泛预训练。混合通用视觉数据和文档解析监督信号,打下坚实基础 -
阶段三:MOCR 专项强化。重点强化图形转 SVG 能力,逐步提升输入分辨率
预训练之后还有一轮高质量的指令微调(SFT),团队发布了两个版本:
-
dots.mocr:均衡能力 -
dots.mocr-svg:SVG 解析增强版
2.3 数据引擎
训练数据从四个互补渠道构建:
-
PDF 文档 → 文本解析监督 -
网页渲染 → 复杂布局和天然 SVG 图标/图表 -
原生 SVG 资产 → 图像-代码配对数据 -
通用视觉数据 → 保持模型广泛能力
3. 实验结果
团队从两个维度进行了系统评估:文档解析和结构化图形解析。
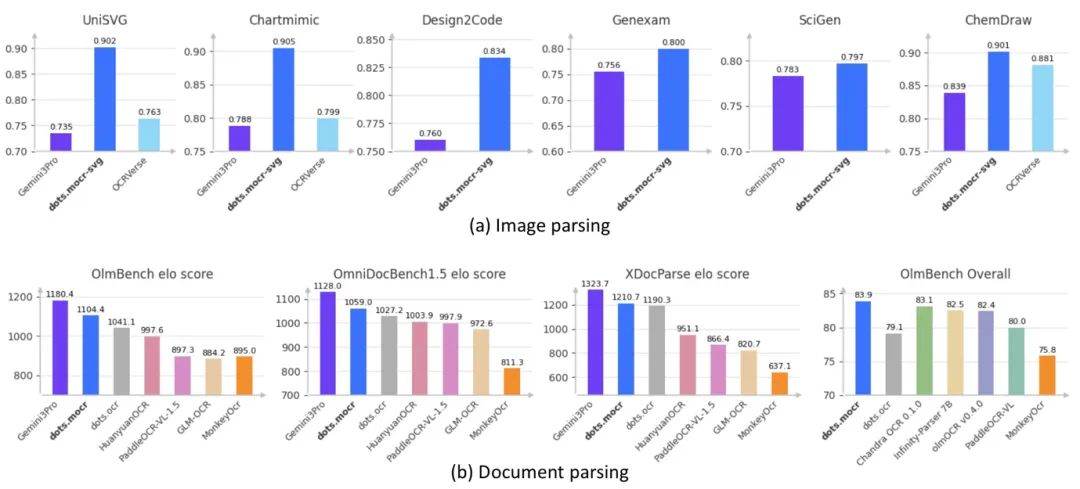
▲ Figure 2:整体性能对比。(a) 图形解析任务指标;(b) 文档解析任务指标(olmOCR-Bench、OmniDocBench 1.5、XDocParse)。
3.1 文档解析:开源最强,直逼 Gemini 3 Pro
团队采用了基于 Elo 评分的自动化评估框架 OCR Arena——让 Gemini 3 Flash 做「裁判」,对模型输出进行两两对比打分。
|
|
|
|
|
平均 Elo |
|---|---|---|---|---|
|
|
|
|
|
|
| dots.mocr | 1104 | 1059 | 1211 | 1125 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
在 olmOCR-Bench 上的逐类别评测:
|
|
|
|
|
|
|
总分 |
|---|---|---|---|---|---|---|
| dots.mocr | 85.9 | 90.7 | 48.2 | 81.6 | 99.7 | 83.9 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
3.2 图形解析:反超 Gemini 3 Pro
如果说文档解析是 MOCR 的「基本功」,那图形到 SVG 的重建就是它真正亮眼的地方:
|
|
|
|
|
|
|
|---|---|---|---|---|---|
| dots.mocr-svg | 0.902 | 0.905 | 0.834 | 0.797 | 0.901 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
一个 3B 参数的小模型,在自己擅长的方向上比顶级闭源模型还强!
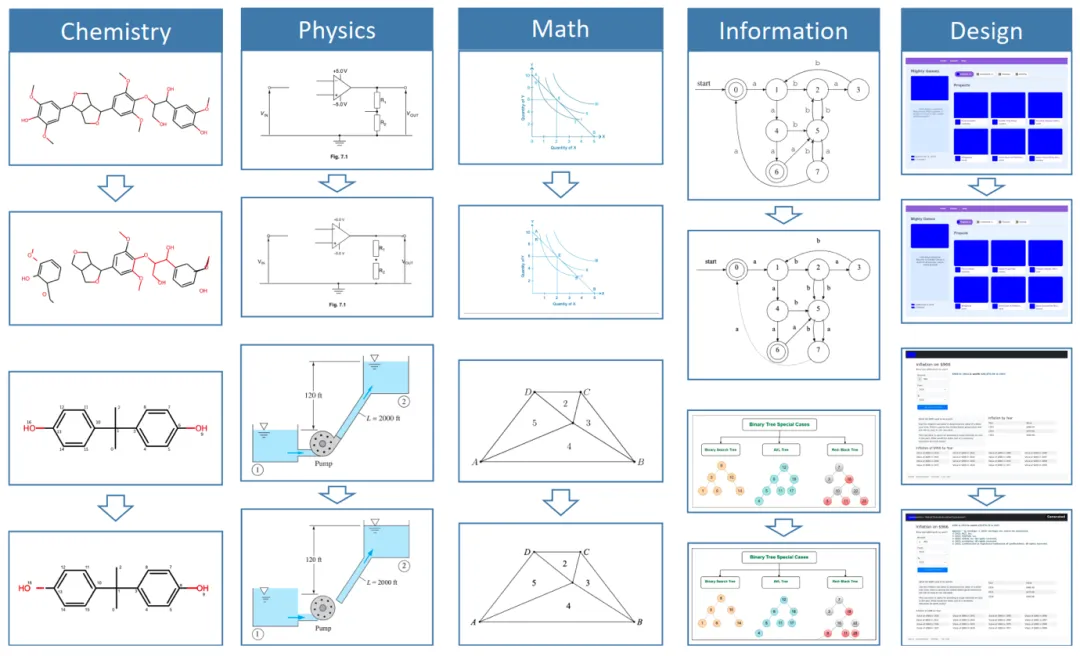
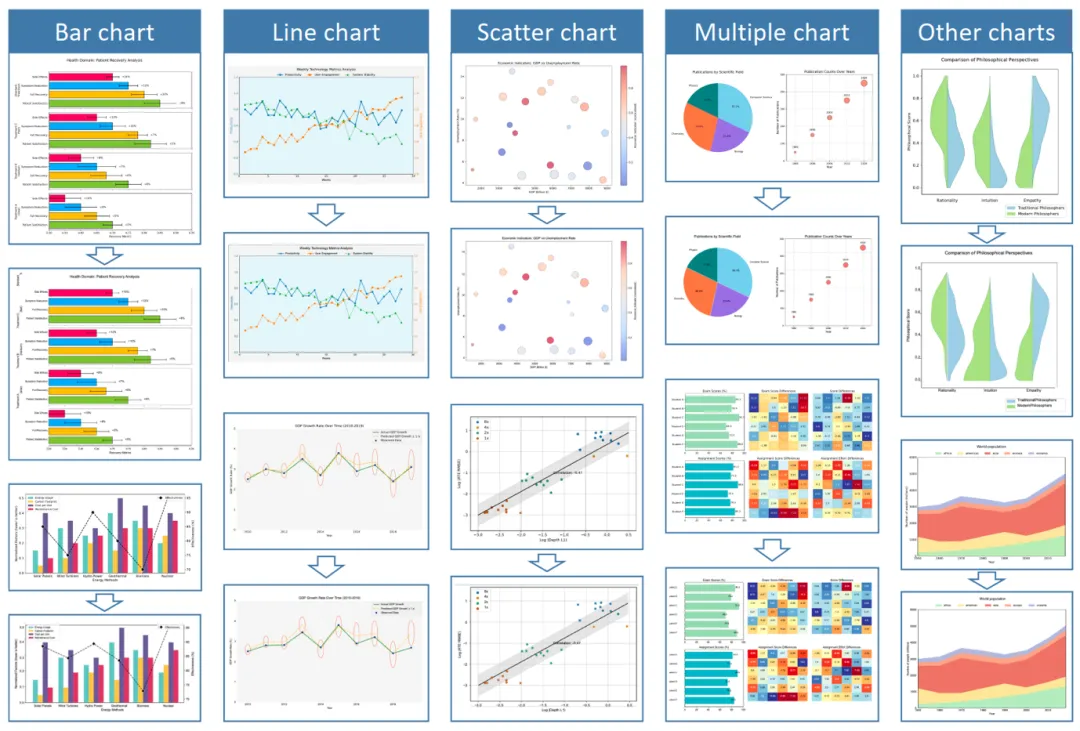
▲ Figure 7:dots.mocr-svg 对各类统计图表的 SVG 重建效果。柱状图、折线图、散点图、复合图表等均可忠实还原为可编辑的向量图形。
▲ Figure 8:dots.mocr-svg 对跨学科复杂插图的 SVG 重建。覆盖化学分子结构、物理示意图、数学图形、信息设计等多个领域。
4. 总结与展望
MOCR 不只是在刷榜——它提出了一个更深层的问题:我们从文档里提取的信息,一直以来都远远不够。
在大模型时代,文档解析是预训练和检索增强生成(RAG)的核心数据引擎。但现有管线都是「文本中心」的,图表里蕴含的丰富结构化信息被大面积浪费。MOCR 把这些「丢弃的金矿」捡了回来——每一张解析为 SVG 的图表,都可以成为(图像, 代码, 文本)三元组的训练数据。
而且,MOCR 的范式并不局限于 SVG。未来可以扩展到 TikZ(科学图形)、D3.js(交互式可视化)、CAD(工程图)、SMILES(化学结构)等各种程序化表示。
一句话总结
dots.mocr 是一个 3B 参数的「全能选手」——文档解析排开源第一(仅次于 Gemini 3 Pro),图形重建反超 Gemini 3 Pro,同时在通用视觉问答上保持了不俗的竞争力。更重要的是,它定义了一个新的范式:文档解析不应该只关注文字,而应该理解页面上的一切视觉语言。
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
引用链接
[1]https://arxiv.org/abs/2603.13032
[2]https://github.com/rednote-hilab/dots.mocr