 夜雨聆风
夜雨聆风





INJ建设者分享:哪些软件产品无法被AI取代?
作者:Nicolas Bustamante,CEO@Fintool,(金融领域的垂类AI Agent)
翻译:INJ建设者,Dante

2026年是软件和服务业的多事之秋。就在最近两个月里,软件和服务类企业的股票市值蒸发了近1万亿美元,标普全球在短短几周内暴跌30%,FactSet(慧甚)从200亿美元市值高点跌至不到80亿美元,汤森路透(Thomson Reuters)的市值也在一年内缩水了近一半,关联着140家上市公司的标普500软件与服务指数则在年初迄今下跌了超过20%。
而在上周,Anthropic为Claude Cowork发布了针对特定领域的垂直化插件。Cowork是一款专为脑力劳动者设计的AI代理,能够自主进行复杂的研究和分析工作,处理文档工作流,这些强大的功能让华尔街感到恐慌。而我在过去十年里都在为一些垂直领域打造SaaS产品。
首先是@Doctrine,它现在是欧洲最大的法律信息平台;然后是@fintool,这是一个由AI驱动的股票研究平台,如今正与彭博社、FactSet等展开竞争。
我在几年前做出的软件,如今正经受着大语言模型(LLM)的持续冲击与威胁,而现在,我正参与研发LLM。可以说,在这场针对软件和服务业的颠覆运动中,我在针锋相对的不同阵营都呆过。
以下是我的结论:LLM正在系统性地摧毁垂直领域软件产品的护城河,但它无法取代全部的垂直化软件。同时,垂直类软件的价值以及它的估值将被重新定义。
在本文中,我将针对以下要点进行解析:
-
让垂直类软件具备防御力的十大护城河,以及LLM对它们各自的影响
-
为什么近期美股的恐慌抛售在结构上是合理的,但在时间点上被夸大了
-
AI时代下真正威胁软件行业的到底是什么(并不像大众以为的那样)
-
什么东西将取代垂直类软件
-
垂直类软件的未来出路
垂直类软件的十大护城河,以及LLM对它们的影响
垂直类软件往往是为某个特定行业量身定制的,比如深耕金融的彭博终端(Bloomberg)、法律界的律商联讯(LexisNexis)、医疗保健领域的Epic、建筑行业的Procore、生命科学领域的Veeva等等。
这些公司都有一个共同的特征:收费高昂,且客户极少流失。FactSet向每个用户收取的年费超过1.5万美元,彭博终端的会员成本为2.5万美元,LexisNexis每月向律师事务所收取数千美元,上述软件服务提供商的客户留存率始终徘徊在95%左右。
以上述软件公司为例,我认为这里存在十种不同的护城河,如今LLM正在瓦解这些护城河中的一部分,而对另一部分则无法造成任何冲击。在细节上理解哪些地方受到冲击、哪些地方安然无恙,正是这场行业博弈的关键。

五种被LLM剧烈冲击的软件产品护城河
1.靠操作门槛和UI构建的护城河→被AI彻底瓦解
我从很多人那里听过这种话无数次:“我们全公司都绑定了FactSet。”“我们律所只认Lexis。”“我们团队离不开彭博终端。”
这些话强调的根本不是软件的数据质量有多好,或者功能有多全面,而是一种“肌肉记忆”。人们在这些特定工具上花费了数年的时间去学习和适应,为此掌握的特定经验无法迁移到新平台上。
比如,彭博终端(Bloomberg Terminal)的老用户往往要花费数年时间,去死记硬背各种快捷键、功能代码和操作路径,像GP、FLDS、GIP、FA、BQ这些指令,单看根本不明所以。它们其实是一门门槛极高的“外语”,一旦你熟练掌握了这套专属语言,再换用到其他平台,又需要重新学习操作指令,就等于一夜之间重新变成了“文盲”。
(彭博终端使用说明书截图)
不同软件打造出的专属操作门槛,是一道最容易被低估的护城河。很多人心甘情愿地掏大价钱,就是因为有路径依赖,不想再去适应其他软件的独特操作方式。也就是说,不同软件那套复杂的操作流程,本身就是产品护城河的组成部分。
传统的垂类软件公司养着大批的设计师和客户经理(CSM),这些人的工作就是手把手教客户怎么用他们的软件。哪怕是对UI进行一丁点的修改,都要当成个大项目来做:
从用户调研、设计冲刺、谨慎上线,再到手把手教学,这些人甚至会为了重新设计一个分类搜索的筛选框而耗上几周,只因客户已经对旧版UI形成了肌肉记忆。界面不仅仅是个图形化的接口,它就是产品本身,而维护这套界面更是一个无底洞。
反观Fintool,我们根本没有所谓的新手引导,没有客户经理去教用户怎么点击菜单寻找按钮。我们的用户只需用大白话说明自己的需求,就能直接得到答案,因为这正是LLM的工作方式。
由于一切操作都通过聊天完成,自然就不存在“需要去学习和适应的操作门槛”,设计师、客户经理团队等也不复存在。一个简单的对话框,就足以解决一切。
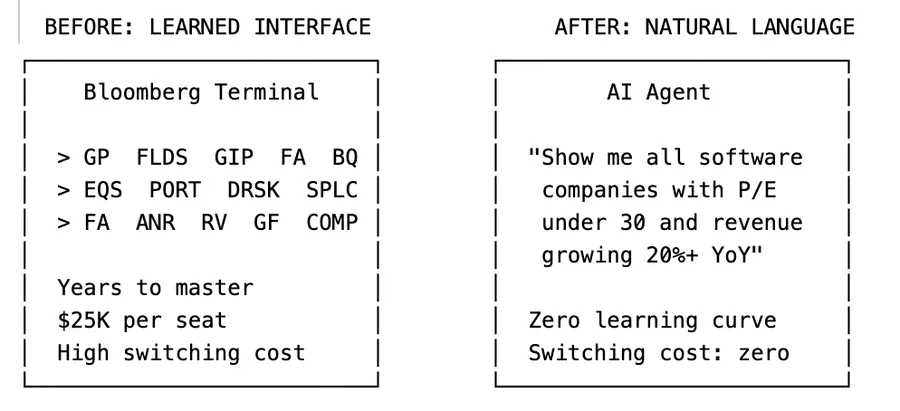
可以说,大语言模型(LLM)将所有复杂的软件界面,通通降维拍扁成了一个简单的对话窗口。
回想一下现在的金融分析师是怎么使用彭博终端的:他们要先点开股票筛选功能,用特定的语法敲入参数,导出结果;接着切换到DCF(现金流折现)模型构建工具,输入各种假设条件,跑一遍敏感性分析;然后再把数据导出到 Excel里,最后做成一份PPT。
这里的每一步操作,靠的都是长期训练出来的软件使用经验。这类专属经验越复杂,越能推高客户的转换成本。
现在,再来看看同一个分析师用LLM代理是怎么干活的:“帮我找出所有市值超10亿美元、市盈率低于30且营收同比增速超过20%的软件公司。给排名前五的公司各建一个DCF模型,并针对折现率和永续增长率做一下敏感性分析。”
仅仅三句话,不需要什么快捷键,不需要背功能代码,也不需要在复杂的菜单里切来切去。用户甚至都不知道、也压根不在乎LLM到底去调了哪家数据商的接口。
当复杂操作变成极其自然的日常对话时,通过长年累月的的肌肉记忆积攒起来的软件使用经验将变得一文不值。曾让“一年收2.5万美元”显得合理的软件转换成本就这么土崩瓦解了。
对许多垂类软件公司来说,那套复杂的界面系统就是他们大部分的价值所在,软件底层的数据要么是买的授权,要么是公开信息,或者是半标准化的商品;真正支撑起高昂定价的,其实是搭建在这些数据之上的工作流。但现在,这套玩法彻底终结了。
2.定制化工作流与业务逻辑→被Agent Skills快速替代
垂类软件本质上是将一个行业的实际运转方式“写成了代码”。一个法律检索平台绝不仅仅是个存放判例的数据库,它把错综复杂的引证网络、Shepard(谢泼德)引证信号、判决摘要的分类体系,甚至是诉讼律师助理起草法律文书的具体习惯,全都转化成了代码逻辑。
沉淀出这套业务逻辑通常要耗费数年之久。它是产品团队与行业专家成千上万次深度交流的结晶。做垂类软件,最难的往往不是技术,而是真正搞懂客户到底是怎么干活的。
以律师为例,你要懂他们是怎么查阅判例的,怎么起草文书的,怎么从接手案子到开庭审理一步步制定诉讼策略的。把这种极其深度的行业认知变成一行行能跑通的代码,正是垂直软件之所以值钱、之所以难以被颠覆的核心壁垒。
然而,LLM把所有这些复杂的逻辑,变成了一个简单的Markdown文本文件,也就是所谓的Skills。这是一个极其容易被忽视的转变,但在我看来,它在长期内也最具毁灭性。
传统的垂直软件把业务逻辑死死地嵌在代码里。成千上万个if/then的条件分支、校验规则、合规审查、审批流程,全都是工程师们年复一年“硬编码”写进去的……而且,还不能是随便找来的工程师。你需要的是那种真正懂行的软件工程师,简直凤毛麟角。
想找一个既能写出企业级商用代码,又明白诉讼流程到底是怎么运转的,或者清楚 DCF模型该怎么搭的人,难如登天。更要命的是,每次修改这些业务逻辑,都得走完一整套开发、测试(QA)和上线的漫长周期。
让我用我的亲身经历举个具体的例子。
以传统的股票筛选平台为例。要想做出一套靠谱的筛选工作流,你得懂金融分类体系,得能从格式五花八门的多个数据源里解析财报文件,还得根据相关性和时效性对结果进行排序,最后还要配上行业基准、历史对比等完整的上下文信息展示给用户。这通常需要一支由工程师和金融专家组成的团队耗费数年才能打造出来。
那些核心的业务逻辑,最终被打散、塞进了几千行代码、自研的排序算法和纯手工微调的相关性模型里。哪怕只是做个小改动,都得大动干戈,搞几轮开发冲刺、代码审查、测试和发布。
而在Fintool,我们给AI开发了一个“DCF估值技能”。它用来指导LLM代理如何做现金流折现分析:需要抓取哪些数据,怎么根据不同行业计算WACC(加权平均资本成本),哪些假设条件需要交叉验证,怎么跑敏感性分析,什么时候要把期权激励费用(SBC)加回来。
你猜怎么着?这玩意儿根本不是什么复杂的代码,就是一份普通的Markdown文档。写这份文档只花了一周时间。而后续更新,只需要几分钟。一个做过500次DCF估值的基金经理,就算完全不懂编程,连一行代码都不写,也能把毕生的绝学和方法论直接“输入”给系统。

过去需要数年才能完成的开发,现在通过文本撰写的方式一周就能完成。这就是时代的巨变。
而且这不仅仅是速度变快了。用Markdown写的“技能”在很多关键方面甚至更胜一筹:任何人都能看懂,方便审查,还可以为每个用户量身定制(我们的客户甚至会自己写技能文档)。更绝的是,随着底层大模型的升级,它还会自动迭代进化,我们连一行代码都不用碰。
业务逻辑正在发生一场大迁徙——从只有专业工程师才能写的代码,变成了任何懂行的人都能写的Markdown文件。过去垂类软件公司花上几年才跑通的业务逻辑,现在几周就能复刻。这道“工作流护城河”正在以惊人的速度瓦解。
3.公域数据的解析与获取→毫无独特性
垂类软件很大一部分的价值主张,就在于把难以获取的数据变得容易检索。FactSet让美国SEC文件变得可搜索;LexisNexis让法律判例变得可搜索,这些都是实打实的服务。SEC文件名义上是公开的,但你试试去读一份200页纯HTML格式的10-K表格?
此外,各家公司的排版结构千奇百怪,会计术语晦涩难懂。想要抠出你真正需要的核心数据,你得去解析嵌套表格、顺藤摸瓜查阅脚注,还要去核对重述后的财务数据。
在LLM出现之前,想要顺利的解析这些公开数据,必须依赖专用软件和极其庞大的工程架构。像FactSet这样的公司,硬是手搓了成千上万个解析器——针对每一种文件类型、甚至每一家公司奇葩的排版格式,都要专门写一个解析器。他们养着一整支工程师军队,就为了在某家公司发布的文件格式变动时去维护定制化的解析器。能把一份原始的 SEC文件转化为可查询的数据,那套代码在当年绝对是无敌的。
在传统的金融数据公司里,这也是个海量工程。为不同的文件类型搭建NLP(自然语言处理)流水线:用命名实体识别(NER)技术去提取股票代码、高管名字和财务指标;用专门的机器学习模型按行业或资产类别对文档进行分类;为每一个排版奇特的独立数据源开发专属的解析器。
工程师们花了好几年时间来搭建和维护这套脚手架。那的确是令人惊叹的技术,也确实是一条坚固的护城河,因为别人想抄,就得同样砸进去好几年的时间。
但在Fintool,这些玩意儿我们一个都没做。零NER,零定制解析器,零行业专属分类器。为什么?因为最前沿的 AI大模型早就知道怎么看懂10-K报表了。它们知道家得宝(Home Depot)的代码是HD,分得清GAAP(美国通用会计准则)和非GAAP营收的区别,就算你不教它表结构,它也能轻松解析嵌套在文档里的表格。别人花了几年时间搭建的解析设施,现在已经成了大模型自带的能力。
LLM让这一切变得轻而易举。前沿模型早就从训练数据中学会了如何解析SEC文件。它们懂10-K的结构,知道去哪里找收入确认政策,也知道怎么去调节GAAP和非GAAP数据。你根本不需要去造什么解析器,模型本身就是解析器。喂给它一份10-K,它就能回答你关于这份报告的任何问题。
垂直软件花了数十年时间打造的解析、结构化和检索能力,现在已经成了直接焊死在LLM里的标配功能。数据本身当然还有价值,但是那个“让数据变得可搜索”的产品层——也是垂类软件很大部分价值和定价权所在的地方——正在全面崩盘。
4.垂直领域工程师稀缺→被LLM无情冲击
做垂直软件,你需要既懂垂直行业又懂技术的人才。想找一个既能写出商业级代码,又明白信用衍生品是怎么构建的工程师,简直是大海捞针。这种人才的稀缺性天然筑起了一道行业门槛,在过去极大地限制了任何垂直领域的重量级玩家数量。
LLM彻底掀翻了这条护城河。
以前在任何垂直领域,招人都极其痛苦。你不仅仅需要优秀的工程师,你还需要能听懂“行话”的工程师:在建筑项目进度表里,变更单是怎么层层传导的?留置权豁免书跟付款申请是怎么交互的?在AIA(美国建筑师协会)合同条款下,什么会触发延期索赔?
这种交叉领域的人才几乎不存在。垂直软件公司只能靠耗时数月内部培训,自己“造”人才,让行业专家去教工程师怎么实现特定领域的业务逻辑。一个新招来的工程师往往要好几个月后才能产出价值。对于任何想要入局垂类软件行业的人来说,人才稀缺性就是一道实打实的铜墙铁壁。
在Fintool,我们完全不搞这一套。我们的行业专家(基金经理、分析师)直接把他们的方法论写进Markdown技能文件里。他们不需要去学Python,也不需要懂什么API调用。他们只需“用大白话写清楚”一个好的DCF分析流程应该长什么样”,LLM就会去执行。
所有的工程化工作全由模型代劳了。原本并不稀缺的“行业认知”,现在彻底摆脱了工程师这个瓶颈,可以直接转化为软件产品。
LLM让工程技术变得唾手可得,这意味着原本极其稀缺的“将行业认知转化为垂直软件的能力”,突然之间变得泛滥了。这就是为什么行业准入门槛会如此戏剧性地坍塌。
5.捆绑销售(功能全家桶)→不再有威力
垂直软件公司通常靠捆绑周边功能来扩张版图。彭博终端最早只做市场数据收集和展示,后来慢慢塞进了即时通讯、新闻分析工具、交易和合规模块。每多一个新模块,客户转换到其他软件上的成本就高一分,因为他们现在依赖的是彭博终端独家的生态,不仅仅是某个单一功能。标普全球(S&P Global)砸440亿美元收购IHS Markit,玩的正是这个策略。“功能全家桶”本身成了护城河。
整个软件行业都在套用捆绑销售的剧本。每一个模块都有自己的一套UI、一套新手引导和一套客户工作流。公司花大精力打造出极其复杂的UI,让用户可以在里面配置自选股、设置自动提醒、管理研究文档。每一个新功能都意味着更多的设计、更多的代码和更庞大的UI界面。这种捆绑把客户死死地锁在里面,因为他们已经把所有的工作流都定在了这个生态上。
LLM代理直接打碎了这道“捆绑”护城河,因为AI代理本身就是一个功能全家桶。在Fintool,设置提醒就是一句话(Prompt),建立自选股就是一句话,投资组合筛选也是一句话。根本不需要为这些独特功能开发独立模块,也没有乱七八糟的UI需要频繁维护。客户只要说一句:“如果我持仓的标的公司在财报会上提到关税风险,立刻提醒我”,事情就办妥了。
AI代理可以在一个工作流里,行云流水地调度十个不同的专业工具。它可以从一个渠道拉取市场数据,从另一个渠道抓取新闻,再通过第三个工具做分析,最后把结果汇总呈现。在这个过程中到底调用了五个还是几个不同的服务?用户压根不知道,也完全不在乎。

当系统的“集成层”从软件供应商转移到AI代理手中时,客户购买“全家桶”的意愿也就烟消云散了。既然AI代理能为每一项独立功能精准挑选出性价比最高的服务提供商,凭什么还要去当冤大头,为彭博终端的整套软件支付高昂的溢价?
如今大趋势已经摆在眼前:AI代理让“解绑”变成了一件极具可行性的事,这在过去是根本无法想象的。
五种无法被LLM冲击的护城河
6.私有数据→固若金汤(甚至更强)
一些垂直软件公司拥有或独家获取了市面上绝无仅有的数据。彭博终端从全球各大交易平台收集实时报价数据,标普全球掌握着信用评级和独家分析模型,邓白氏(Dun&Bradstreet)维护着超过5亿家企业的商业信用档案。这些数据是几十年如一日积累下来的,通常还伴随着排他性。你爬取不到,更伪造不出。
如果你的数据真的无法被复制,那么LLM不仅无法削弱它的价值,反而会让它更值钱。
比如,彭博终端从各家交易平台那里拿到的实时报价,你的爬虫爬不到,AI也生成不了,也无法从第三方获得授权。在LLM时代,这种数据成了所有AI代理都嗷嗷待哺的稀缺养料。彭博终端对独家数据的定价权甚至可能会不降反升。
标普全球的信用评级也是同样的道理。信用评级可不仅仅是数据,它是一套受监管的评估体系,结合数十年历史中的违约数据,靠私有数据库得出的“权威意见”。LLM出不了信用评级,但标普能。
这条检验标准极其简单:这些数据别人能不能搞到、买到授权,或者是用AI合成出来?如果不能,你的护城河就依然坚挺。如果能,那你就有大麻烦了。
我在自己的两家公司里都真切地验证了这一点。当我们刚创办Doctrine时,头两年的核心价值是给公开的判例法搭建一套带有行业属性的基础架构:分类体系、引证网络、相关性排序。但团队在差不多十年前就意识到,光靠公开数据是远远不够的。
大约七年前,Doctrine开始打造独家内容库:独有的法律批注、编辑团队的深度分析、精选的专家评论——这些在别处根本找不到。时至今日,这个内容库极难被复制,成了一道极深的护城河。再加上全面向LLM转型,现在的 Doctrine简直势不可挡!这正是目前市场定价出现偏差的地方。
一些拥有深厚数据护城河、又早早拥抱了AI的中型企业,将会在与传统巨头和新入局者的较量中攫取绝大部分的价值。
能在这场时代巨变中活下来的公司,是那些从“我们能更好地整理公开数据”成功转型为“我们拥有你别处弄不到的数据”的公司。因为游戏规则已经变了:过去搭建那个“智能处理层”需要好几年的工程开发。现在,这只是大模型自带的一个基础能力。甚至连“数据获取”本身也在被商品化。
MCP(模型上下文协议)正在把每一家数据供应商变成一个“插件”。现在已经有几十家公司以MCP服务器的形式提供独家金融数据,任何AI代理都能直接调用。当你的数据仅仅沦为Claude旗下的一个插件时,那种“让数据变好用”的溢价就彻底消失了。
讽刺的是,LLM正在加速两极分化。手里有独家数据的公司赢麻了;没有独家数据的公司输得底裤都不剩。
如果你的数据不是真正独一无二的——如果它能在别处搞到、买到或合成出来——你就不安全。你面临着沦为“底层标配”的巨大风险。AI代理将把控与客户的直接关系。它会成为用户交互的界面、用户信任的品牌,以及用户真正掏钱购买的产品。而你,只是代理的一个“供应商”,不再是客户的“服务商”。
这就是“聚合理论”(Aggregation Theory)在现实中的实时推演:
聚合器(AI代理)截获了用户关系和高额利润,而底层供应商(数据贩子)只能靠打价格战来给平台喂数据。如果彭博、FactSet和另外十几家小供应商提供的是一模一样的市场数据,AI代理就会直接把数据请求路由给最便宜的那家数据供应商。你的定价权灰飞烟灭,你的利润空间被无限挤压。你彻底沦为了别人产品链条里的一种廉价原材料。
7.监管与合规锁定→结构性壁垒
在医疗保健领域,Epic能够称霸绝不仅仅是因为产品好用。它靠的是HIPAA(健康保险隐私及责任法案)合规、FDA认证,以及医院必须硬着头皮熬过的那长达18个月的部署周期。更换电子病历(EHR)系统是一个耗时数年、耗资数百万美元的大工程,稍有不慎甚至会危及患者的生命安全。在金融服务领域,合规要求同样制造了极强的锁定效应。审计追踪、监管报送、数据留存政策,这些全都死死地焊在了软件里。
HIPAA可不管你是不是LLM。FDA认证也不会因为GPT-5的发布就变得容易半分。萨班斯法案(SOX)的合规要求更不会因为Anthropic发了个新插件就有所改变。
Epic在医疗EHR领域的统治地位,本质上就是一道监管护城河。那18个月的部署周期、各种合规认证、与医院计费系统的深度集成,没有任何一项会受到LLM的冲击。
事实上,在合规锁定最严格的垂直领域,监管要求反而可能会拖慢LLM的普及速度。医院根本不可能用一个AI代理去替换掉Epic,因为这个AI代理没有HIPAA认证,没有合规的审计追踪记录,也没有经过FDA的临床决策支持验证。
8.网络效应→极具粘性(难以撼动)
有些垂直软件用的人越多,它就越值钱。彭博终端的即时通讯功能(IB chat)实际上就是华尔街默认的沟通底座。如果你的交易对手都在用彭博终端,那你就必须得用彭博终端。不是为了看它的数据,而是为了混它的圈子。
LLM根本打破不了网络效应。甚至可以说,它们可能会让这种沟通网络变得更有价值。在这个网络中流动的各类信息,本身就会成为极具价值的大模型训练数据、上下文背景和市场信号,这些对LLM而言极具价值的数据反而加强了彭博终端的护城河。
这套逻辑同样适用于任何在行业内充当“沟通底层”的垂直软件。比如Veeva在药企之间建立的网络效应,或者 Procore在建筑施工各方之间形成的网络效应。这些护城河之所以极具粘性,是因为它的价值来源于“还有谁在这个平台上”,而不是“这个软件有多好用”。
9.交易链路嵌入→经久不衰(难以剥离)
有些垂类软件直接卡在了资金流转的咽喉要道上。比如餐厅的支付处理系统,银行的贷款发放系统,或者是保险公司的理赔处理系统。当你深度嵌入到交易环节中时,客户换掉你就意味着要切断营收命脉。没有哪个脑子正常的人会主动干这种事。
如果你的软件是用来处理支付、发放贷款或者结算交易的,LLM根本无法绕开你(去中介化)。它最多只是盖在你上面的一层更好用的交互界面,但底层的交易铁轨依然是不可或缺的。
Stripe并没有受到LLM的威胁,FIS和Fiserv也没有。交易处理层是基础设施,不是交互界面。
10.“记录系统”地位→LLM需要长期才能造成威胁
当你的软件成为企业关键业务数据“唯一的事实真相来源”时,换软件就不只是麻烦那么简单了,那是事关生死的豪赌。迁移过程中数据损坏了怎么办?历史记录丢了怎么办?审计追踪断链了怎么办?
Epic是患者数据的记录系统。Salesforce是客户关系的记录系统。SAP也一样。这些公司都在吃一种“不对称”的红利:留下来的成本(高昂的订阅费)远远低于离开的代价(潜在的数据丢失和运营瘫痪)。
就目前而言,LLM还没有直接威胁到“记录系统”的霸主地位。但是,AI代理们正在暗中打造属于自己的记录系统。
情况是这样的:AI代理不仅仅是在查询现有系统的数据。它们还在阅读你的SharePoint文档、你的Outlook邮件、你的Slack聊天记录。它们在收集用户的行为数据,撰写跨越多个会话的详细记忆文件。当它们执行关键操作时,也会把这些上下文统统存下来。随着时间的推移,AI代理积累的关于用户工作全貌的信息,将比任何一个单一的“记录系统”都要丰富、完整得多。
代理的“记忆”,正在成为新的事实真相来源。 这倒不是谁刻意规划的,而是因为AI代理是唯一一个能把所有信息尽收眼底的层面。Salesforce只能看到你的CRM数据,Outlook只能看到你的邮件,SharePoint只能看到你的文档。但 AI代理能看到这三者,并且全都会记住。
这当然不是一夜之间就能完成的颠覆。但从大趋势来看,AI代理正在从底层一点一滴地构建属于它们自己的“记录系统”。随着代理上下文记忆的不断膨胀,传统记录系统的护城河只会越来越脆弱。
最终结果:行业准入门槛的全面大崩塌
算算总账吧。有五道护城河被摧毁或削弱,还有五道依然坚挺。但要命的是,垮掉的那五道,恰恰是过去用来把竞争对手挡在门外的壁垒;而守住的那五道,却只有极少数老玩家才拥有。
在LLM出现之前,你想打造一个能跟彭博终端或LexisNexis叫板的竞品,需要几百号既懂垂直领域又懂技术的工程师、好几年的开发周期、砸重金买下海量数据授权、一支销售团队,还得搞定各种监管认证。结果就是:大多数垂直行业里,真正能上牌桌的玩家也就两三家。
有了LLM之后,只要两三个人拉起一支小团队,手里攥着最顶尖大模型的API,懂点行业门道,再搭好数据管道,几个月时间就能攒出一个干掉传统垂直软件80%功能的产品。
这里最核心的洞察在于:竞争加剧绝不是线性的,而是呈指数级大爆炸的。 牌桌上的玩家不会从3家变成4家,而是直接从3家暴增到300家!这就是把定价权彻底砸穿的元凶。以前,每个垂直领域都有那么两三家巨头躺着赚高溢价,因为行业壁垒根本不可逾越。但现在,如果突然冒出50家AI原生初创公司,只收你五分之一的钱,就能提供 80%的功能,这笔账的算法就彻底变了。
其中的微妙之处:这是一场长跑,而非一夜暴毙。这正是我认为美股市场前一阵的暴跌虽然看对了方向,却搞错了时间表。
企业级营收不会瞬间蒸发
FactSet的客户签的都是好几年的大单。彭博终端的合同通常起步就是两年。这些白纸黑字的合同,绝不会因为 Anthropic昨天刚发了个新插件就原地作废。
企业的采购周期是按季度甚至按年算的,绝不是按天算。一家管理着500亿美元资金的对冲基金,绝不可能因为 Claude现在能查SEC报告了,明天就把标普全球的CapIQ系统给拔了。他们会花上12到18个月去评估替代方案,会搞小范围的试点,会去来回扯皮谈合同条款,并且一定会等到现有的合同到期。
所谓“营收悬崖”确实存在,但它是一个缓坡,而不是万丈深渊。未来12到24个月的营收,大部分早就已经锁在保险柜里了。
但市场早就看透了另一个潜规则:股票崩盘根本不需要等到营收真掉下来,只需要估值倍数(PS/PE)被压缩就够了。 一家金融数据公司,当年手里捏着定价权、客户留存率高达95%时,市场愿意给它15倍的市销率(PS)。
可一旦市场察觉到这两块基石正在松动,它的估值可能直接被杀到6倍。哪怕它的营收一分没少,股价也会照样暴跌 60%。这就是当下某些公司正在上演的血淋淋的现实。
市场真正定价的,不是眼前的营收崩盘,而是“高溢价时代”的终结——因为当年撑起这种高估值的护城河,已经被溶解了。
真正的威胁
真正的威胁根本不是LLM本身。而是传统垂直软件巨头们完全没料到的、一种上下夹击的“钳形攻势”。
从下方看,成百上千家AI原生初创公司正在疯狂涌入每一个垂直领域。以前,想做个像样的金融数据产品得养200个工程师、砸5000万美元买数据授权,市场自然会向那3到4家巨头集中。可现在,当你只需要10个工程师加上最前沿大模型的API就能起盘时,整个市场就会发生剧烈的碎片化。竞争对手从3家直接飙升到了300家。
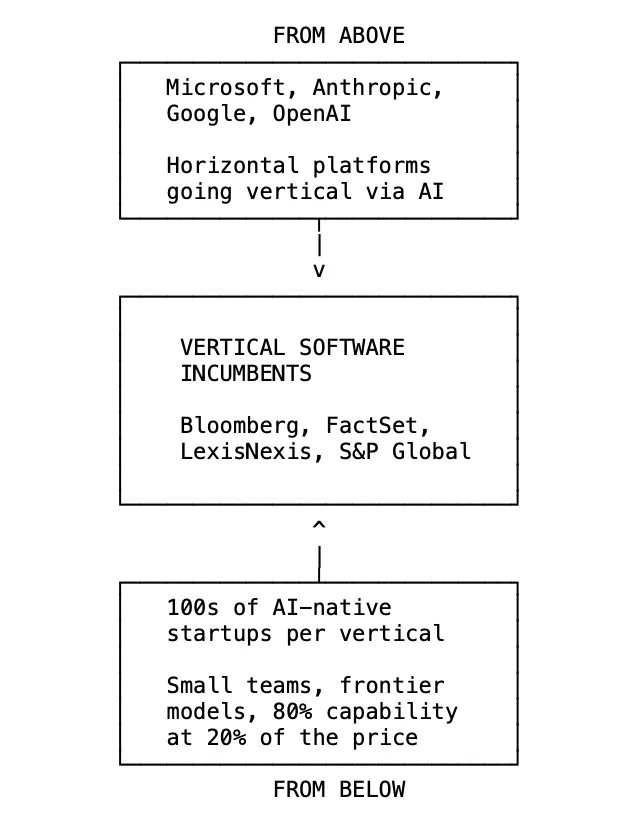
从上方看,通用型(横向)平台破天荒地开始向垂直领域深扎。现在,Excel里的Microsoft Copilot已经能通过AI来跑DCF模型、解析财务报表了。Word里的Copilot则干起了审查合同、检索判例法的活儿。这些通用工具不再靠堆叠工程代码,而是直接靠AI实现了“垂直化”。
Anthropic也在从另一个方向做着同样的事。因为Fintool就是Anthropic投资的公司,所以我能在前线把这一切看得清清楚楚。Claude正在全面“All in”垂直领域。
他们的打法简单得让人后背发凉:一套通用的AI代理框架SDK、支持即插即用的数据接口MCP,再加上特定行业的Skills(几份Markdown文件)。仅此而已。这就是你从通用跨界到垂直领域所需的全部技术栈。不需要什么行业资深工程师,更不需要熬上几年的开发周期。
软件正在变得“无头化”(Headless,指没有前端界面)。交互界面将逐渐消失,所有的业务流都直接从AI代理那里过来。真正重要的早已不再是软件本身,而是谁能把控客户关系和应用场景——说白了,就是谁能把控那个AI代理。
让垂直软件得以做深的技术(LLM+Skills+MCP),恰恰也是让通用平台最终能够打入它们过去连摸都摸不到的领地的武器。这或许是垂直软件面临的最致命的生存危机:
像微软这样的B2B通用软件巨头,现在已经不仅仅是在垂直领域“试试水”了,他们正在极其激进地疯狂扩张。因为这门槛比以往任何时候都要低,更因为在“AI优先”的新世界里,他们必须把控住应用场景和工作流,才能不被时代淘汰。
软件和服务类企业的未来风险评估框架
并非所有的垂直软件都面临同等的风险。以下是我对“谁能活下来、谁会死”的思考框架。
高危区:数据检索层
如果你的核心价值就是通过一个专用界面让数据变得可搜索、易获取,而底层数据偏偏又是公开的,或者花点小钱就能买到授权的,那你麻烦就大了。这包括那些靠授权数据做出来的金融交易终端、专利检索工具,以及任何本质上只是在说“我们为您这个行业做了一个更好用的搜索引擎”的垂直产品。
这些公司过去能享受15到20倍的市销率,靠的全是界面的锁定效应和封闭的竞争环境。现在,这两根支柱都塌了。想想过去一年里那些市值腰斩40%到60%的金融数据供应商吧。市场对他们的重新定价,无比正确。
中危区:混合业务组合
很多垂直软件公司手里的业务线,既有能防守的,也有完全暴露在LLM冲击之下的。一家公司可能一边握着真正独家的评级业务,另一边却做着纯粹靠“倒卖”公开信息包装而成的数据分析业务;或者一边是指数授权业务(深度嵌入交易环节,极具防御力),另一边却是个研究平台(纯检索层,极易被颠覆)。
这类公司20%到30%的股价下跌,反映的正是市场在估值上的摇摆不定:到底哪一块业务才是大头?最核心的问题在于:到底有多少比例的营收,是来自于LLM根本碰不到的护城河?
低危区:监管堡垒
如果你的护城河是监管认证、合规基础设施,并且深度绑定了容不得半点闪失的核心业务工作流,那么在中期内,LLM对你的竞争地位几乎毫无影响。比如符合HIPAA规定并有FDA验证的医疗EHR(电子病历)系统,带有监管锁定属性的生命科学平台,以及金融行业的合规与报送基础设施。
这些公司甚至还能从别处的AI颠覆潮中坐收渔翁之利:当客户开始抛弃那些只用来检索信息的供应商时,他们反而会把预算集中到这些在受监管工作流中值得信赖的“老伙计”身上。
终极考验
评估任何一家垂类软件公司,只需问三个直击灵魂的问题:
数据是独家的吗? 如果是,护城河固若金汤;如果不是,数据获取层的价值正在崩溃。
存在监管锁定吗? 如果是,LLM根本改变不了客户的转换成本;如果不是,那你的转换成本多半是靠界面撑起来的,正在迅速瓦解。
软件嵌入到交易链路中了吗? 如果是,LLM最多只能趴在你上面做个前端,代替不了你;如果不是,你随时可以被替换。
零个“是”:高危。
一个“是”:中危。
两个或三个“是”:你大概率能高枕无忧。