 夜雨聆风
夜雨聆风





需要在本地训练/部署大模型吗?这个开源工具让训练速度翻倍,显存减少70%

你有没有尝试过:想微调一个大模型,结果发现:
-
1000美元的GPU租用费用;
-
等待24小时才能看到第一轮结果;
-
显存不够,训练中途崩溃;
不是你太穷,也不是模型太难,而是你没用对工具。
今天要介绍的 Unsloth,就是为解决这个问题而生。
它让LLM训练变得更快、更省显存的开源工具包,让训练大模型变得像在本地跑个小项目一样简单。目前已经55K+的star。
一、它直面大模型微调的三个痛点
当前微调大模型的痛点太明显:
-
慢:训练时间长,等结果等得心焦;
-
贵:显存不够,只能租用昂贵GPU;
-
难:配置复杂,一不小心就报错;
Unsloth 说:我可以用更少的显存,跑得更快,还能保持精度。
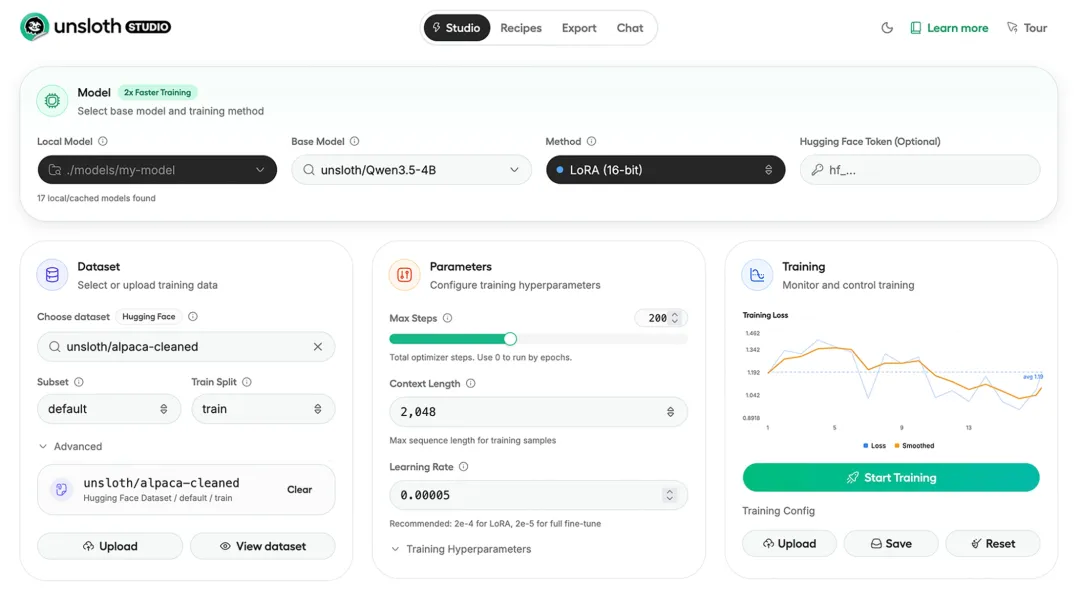
Unsloth部署好后,页面长这样:
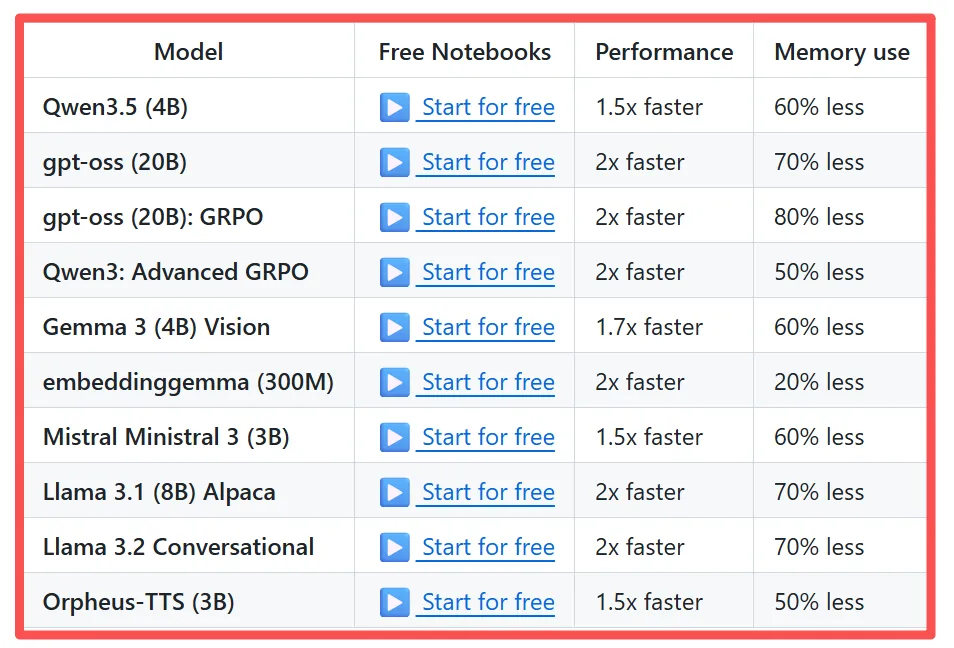
下面是摘自项目Github主页的战绩:
用Qwen3.5-4B模型,训练速度提升1.5倍,显存减少60%;
用gpt-oss-20B,训练速度提升2倍,显存减少70%;
用Llama3.1-8B,训练速度提升2倍,显存减少70%;
二、为什么这么厉害?
Unsloth 的核心是优化了训练过程中的计算和内存使用,主要是下面3个关键点:
1. Triton内核优化
-
用OpenAI的Triton语言重写关键计算内核;
-
让计算更高效,减少GPU等待时间;
2. 动态2.0量化
-
智能判断哪些参数可以量化,哪些不能;
-
保持精度,只用比传统方法少10%的显存;
3. 无近似训练
-
不用近似方法来节省显存;
-
保证训练结果和原模型完全一致;

🌐 项目地址:https://github.com/unslothai/unsloth
📚 官方文档:https://unsloth.ai/docs
请在微信客户端打开