 夜雨聆风
夜雨聆风





CVPR2026论文合集–【3.18更新版】

关键词:文生图;语义分割;零样本;小样本;SAM;大模型;3D姿态估计;缺陷检测;MLLM;自动驾驶;多模态大模型;旋转目标检测;视觉语言模型(VLM);异常检测;跨视觉模态;多模态目标跟踪;红外图像超分辨率;超分辨率重建;联邦学习;图像编辑;医学图像分割;自动驾驶;视频推理;推理分割
—————————
篇幅较长,可通过关键词快速搜索定位相关论文
—————————
一、论文标题
Layer-wise Instance Binding for Regional and Occlusion Control in Text-to-Image Diffusion Transformers
【文章研读】CVPR2026 | 文生图新突破:LayerBind让AI理解物体遮挡关系
二、论文研究方向
文本生成图像中的区域布局与遮挡关系可控生成。
三、文章概要
本文针对文本生成图像模型中难以精确控制物体区域位置和遮挡顺序的问题,提出一种无需训练的控制框架 LayerBind。作者基于扩散模型生成过程中“空间布局与遮挡关系在早期去噪阶段就已经确定”的观察,将不同实例的生成过程视为多个层级生成分支,并在扩散早期通过 Layer-wise Instance Initialization 为每个实例建立独立的生成路径,使其仅关注对应区域同时共享背景信息,然后根据预设的层顺序将多个实例分支融合为统一的 latent 表示,从而在生成早期确定布局和遮挡关系;随后通过 Layer-wise Semantic Nursing 在后续去噪过程中引入层级注意力路径,与全局注意力并行更新,并利用透明度调度机制控制不同实例层的融合与更新,以增强区域语义细节并保持遮挡顺序稳定,从而实现对扩散 Transformer 图像生成中 区域位置与遮挡关系的精细可控生成。
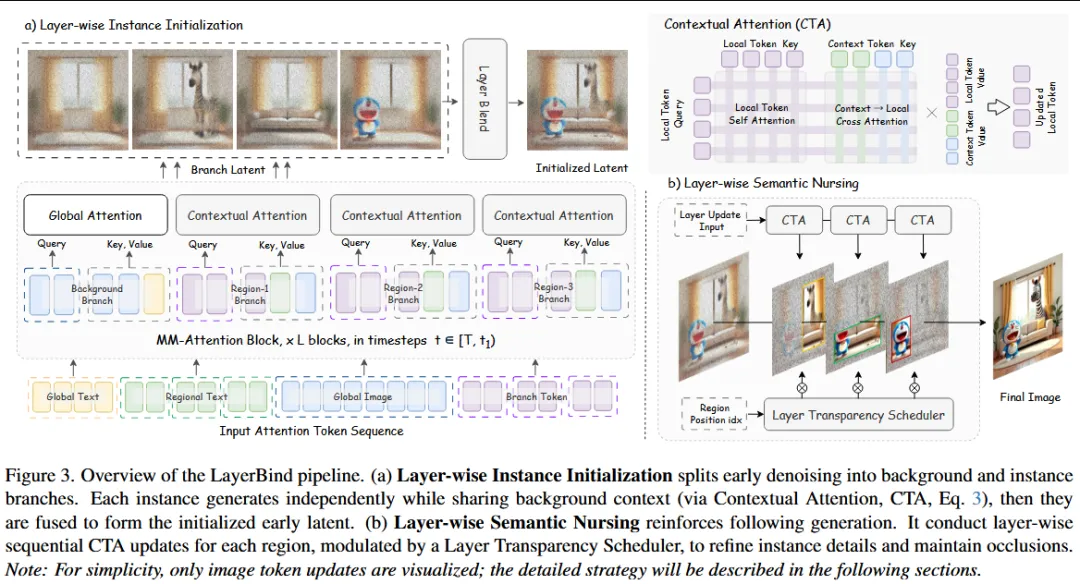
—————————
一、论文标题
Unify the Views: View-Consistent Prototype Learning for Few-Shot Segmentation
【文章研读】CVPR2026 | 图结构+SAM提升Few-shot分割
二、论文研究方向
跨视角一致性的少样本语义分割。
三、文章概要
本文针对少样本语义分割中由于视角变化和外观差异导致的结构错位与特征不一致问题,提出 VINE(View-Informed Network) 框架,通过联合建模结构一致性与前景判别信息来学习更加稳定的类别原型。具体而言,方法在 backbone 特征上构建 Spatial-View Graph,其中空间图用于刻画图像内部的局部几何结构关系,而视角图用于连接不同视角下的特征并传播视角不变语义,从而获得结构一致的表示;同时利用 support 与 query 特征差异构建 前景判别先验,对 SAM 特征进行重加权并重新校准 backbone 激活,以突出前景区域并减少背景干扰;最终将结构增强的 ResNet 特征与前景增强的 SAM 特征通过 masked cross-attention 融合生成类别一致的原型,并将其作为提示输入 SAM 解码器进行分割,实现对复杂视角变化场景下更鲁棒的少样本分割。
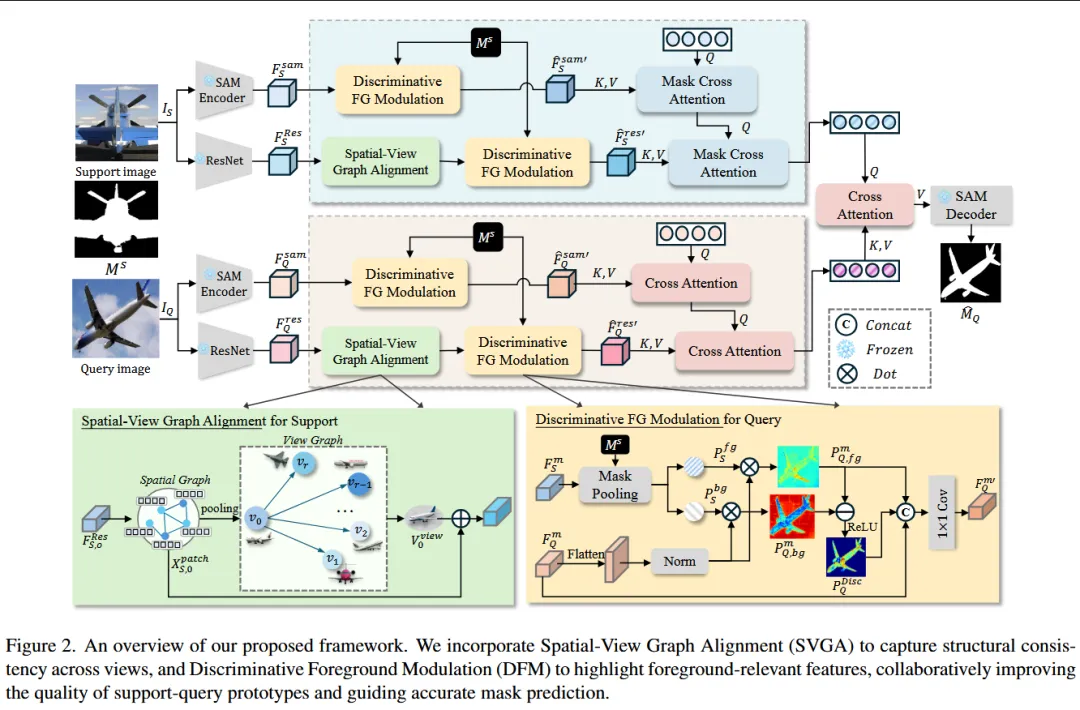
—————————
一、论文标题
Discover, Segment, and Select: A Progressive Mechanism for Zero-shot Camouflaged Object Segmentation
【文章研读】CVPR2026 | MLLM + SAM再升级:DSS框架实现更精准伪装目标检测
二、论文研究方向
基于大模型与SAM的零样本伪装目标分割。
三、文章概要
本文针对伪装目标分割在零样本场景中难以准确定位和识别的问题,提出 Discover–Segment–Select(DSS) 渐进式分割框架,将目标发现、候选分割与语义选择三个阶段进行解耦。首先在 Discover 阶段利用多模态大模型语义信息与视觉特征聚类提出 Feature-coherent Object Discovery 模块,通过局部结构组合与相似性驱动的候选框生成策略发现多个潜在目标区域;随后在 Segment 阶段将这些候选框输入 SAM 生成对应的候选分割掩码;最后在 Select 阶段利用多模态大模型进行语义推理,对多个候选 mask 进行语义一致性评估并选择最合理的分割结果,使大模型从“直接定位目标”转变为“语义判断与选择”,从而在无需训练的情况下实现更加稳定和准确的零样本伪装目标分割。
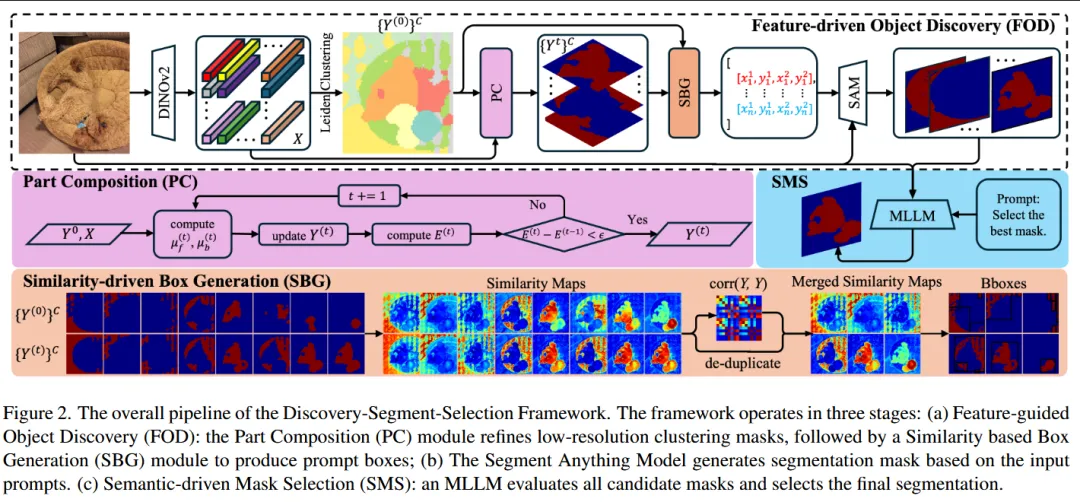
—————————
一、论文标题
EgoPoseFormer v2: Accurate Egocentric Human Motion Estimation for AR/VR
【文章研读】CVPR26 | Meta新作:自中心3D人体姿态估计再进化-EgoPoseFormer v2实现高精度低延迟
二、论文研究方向
第一视角人体姿态与运动估计(Egocentric Human Motion Estimation)。
三、文章概要
本文针对第一视角(egocentric)人体动作估计中存在的身体可见范围有限、遮挡严重以及标注数据稀缺等问题,提出 EgoPoseFormer v2 框架,通过结合时空建模与大规模自动标注训练实现高精度姿态估计。该方法基于 Transformer 构建端到端姿态估计模型,引入 identity-conditioned queries 来保持人体身份一致性,并通过 causal temporal attention 建模时间序列中的运动连续性,同时利用 multi-view spatial refinement 进一步提升空间姿态估计的准确性,使模型能够同时预测关键点与参数化人体模型表示;此外,论文提出一个 自动标注系统(auto-labeling pipeline),采用 teacher–student 半监督训练与不确定性蒸馏机制,在大规模未标注视频上生成伪标签,从而将训练规模扩展到数千万帧数据并提升模型泛化能力,在保持极低推理延迟的同时显著提高姿态估计精度和时间稳定性。
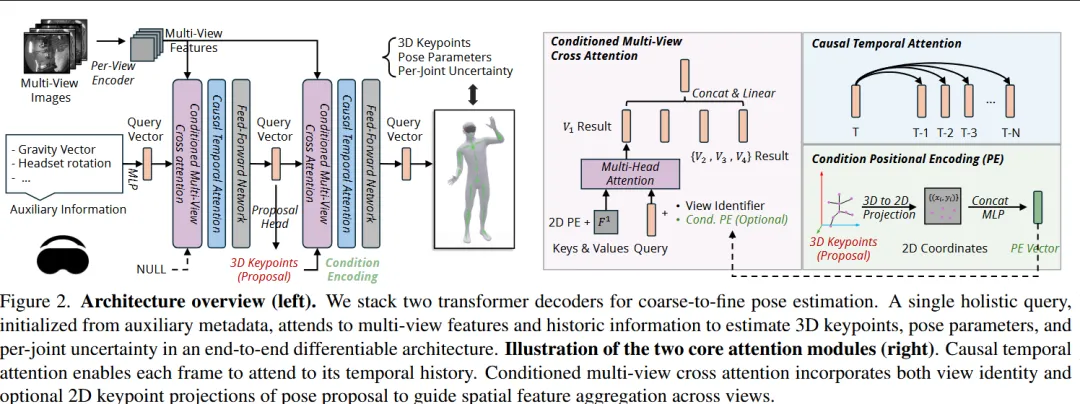
—————————
一、论文标题
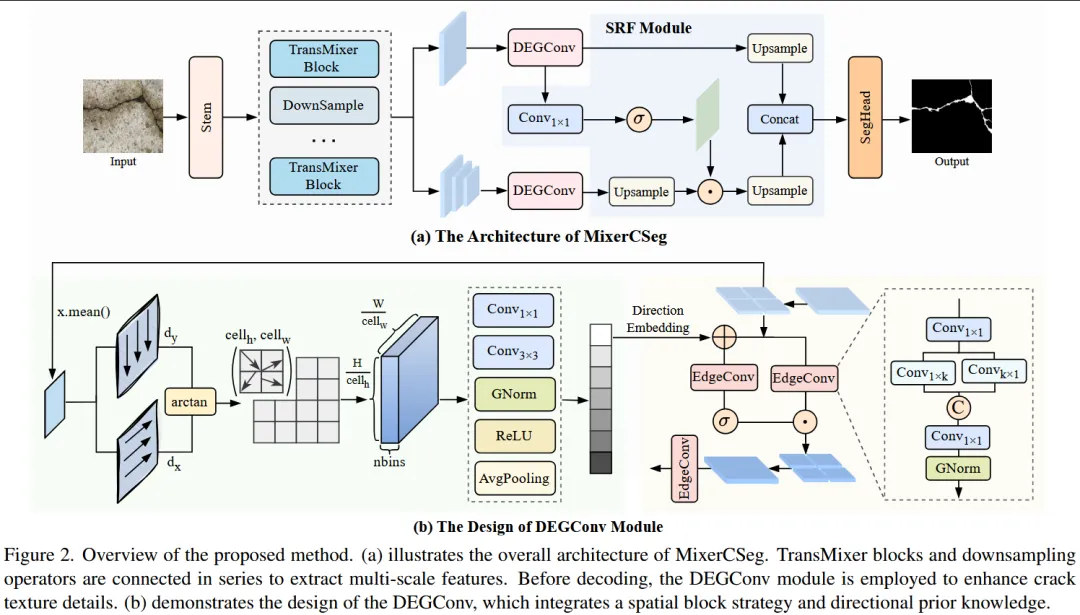
MixerCSeg: An Efficient Mixer Architecture for Crack Segmentation via Decoupled Mamba Attention
【文章研读】CVPR2026 | CNN+Transformer+Mamba协同:裂缝检测新架构
二、论文研究方向
面向基础设施检测的裂缝语义分割(Crack Segmentation)。
三、文章概要
本文针对裂缝分割任务中细长结构复杂、纹理细节丰富且全局上下文依赖强的问题,提出 MixerCSeg 编码架构,通过融合 CNN、Transformer 和 Mamba 三种建模能力实现高效特征表达。该方法在编码器中设计 TransMixer 模块,将 CNN 风格路径用于捕获局部纹理信息,Transformer 风格路径用于建模长距离全局依赖,同时引入基于 Mamba 的序列建模机制来刻画结构连续性,从而在单一编码框架中统一局部、全局与序列上下文信息;此外,作者提出 Direction-guided Edge Gated Convolution (DEGConv) 来强化对裂缝边界和方向结构的感知,并通过 Spatial Block Processing 与 Spatial Refinement Multi-Level Fusion (SRF) 模块对多尺度特征进行高效融合和细节恢复,使模型在保持极低参数量和计算量的同时仍能准确捕获细粒度裂缝结构,实现高效且精确的裂缝分割。
—————————
一、论文标题
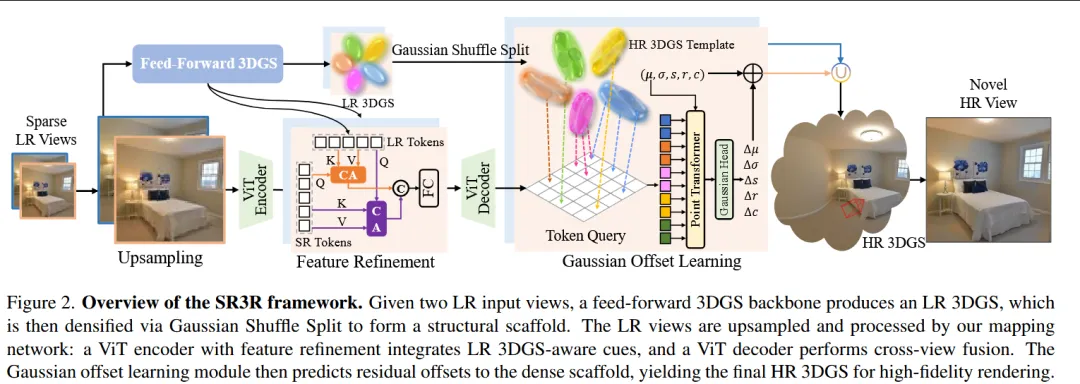
SR3R: Rethinking Super-Resolution 3D Reconstruction With Feed-Forward Models
【文章研读】CVPR2026 | 两张低清图片,也能重建高清3D世界!
二、论文研究方向
三维重建中的超分辨率重建(3D Super-Resolution Reconstruction)。
三、文章概要
本文针对传统三维超分辨率重建方法在跨场景泛化能力和高频细节恢复方面的局限,提出 SR3R 框架,将 3D 超分辨率问题重新表述为从 低分辨率多视图图像直接映射到高分辨率 3D Gaussian Splatting 表示 的前馈学习问题。具体而言,方法通过构建一个端到端的 feed-forward mapping network,直接从稀疏的低分辨率输入视图预测高分辨率 3DGS 表示,使模型能够在大规模多场景数据上学习三维结构与外观中的高频几何与纹理信息,从而摆脱传统迭代优化和场景特定训练带来的效率瓶颈,并显著提升跨场景泛化能力和实时重建性能,实现对复杂三维细节的高质量恢复。
—————————
一、论文标题
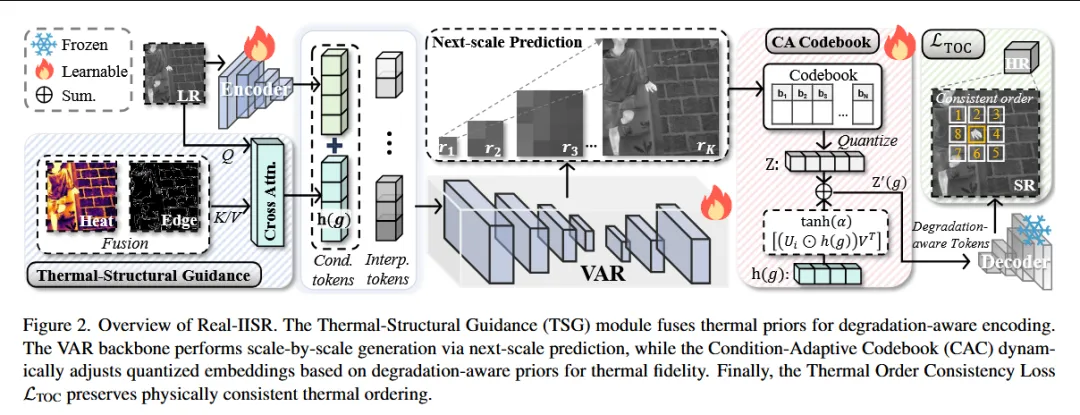
Toward Real-world Infrared Image Super-Resolution: A Unified Autoregressive Framework and Benchmark Dataset
【文章研读】CVPR26 | 真实红外超分辨率新突破:自回归框架 Real-IISR
二、论文研究方向
真实场景红外图像超分辨率(Real-world Infrared Image Super-Resolution)。
三、文章概要
本文针对真实环境下红外图像超分辨率(IISR)任务中存在的复杂退化问题(如空间模糊、热辐射漂移与结构边界不稳定等),提出 Real-IISR 统一自回归框架,通过 热结构引导的视觉自回归机制 逐尺度重建图像中的热结构细节和背景纹理。该方法首先利用 Thermal-Structural Guidance 模块 将红外热辐射先验编码为结构信息,以缓解热信号与视觉边缘之间的不匹配;随后设计 Condition-Adaptive Codebook 根据退化感知的热先验动态调整离散表示,从而适应真实红外成像中的非均匀退化;同时提出 Thermal Order Consistency Loss 强制温度与像素强度之间保持单调关系,以维持物理一致性并减少热漂移带来的影响。此外,论文构建了 FLIR-IISR 数据集,通过真实焦距变化与运动模糊采集配对 LR-HR 红外图像,为真实红外超分辨率提供新的评测基准,并在实验中验证了该框架在真实退化场景中的显著性能优势。
—————————
一、论文标题
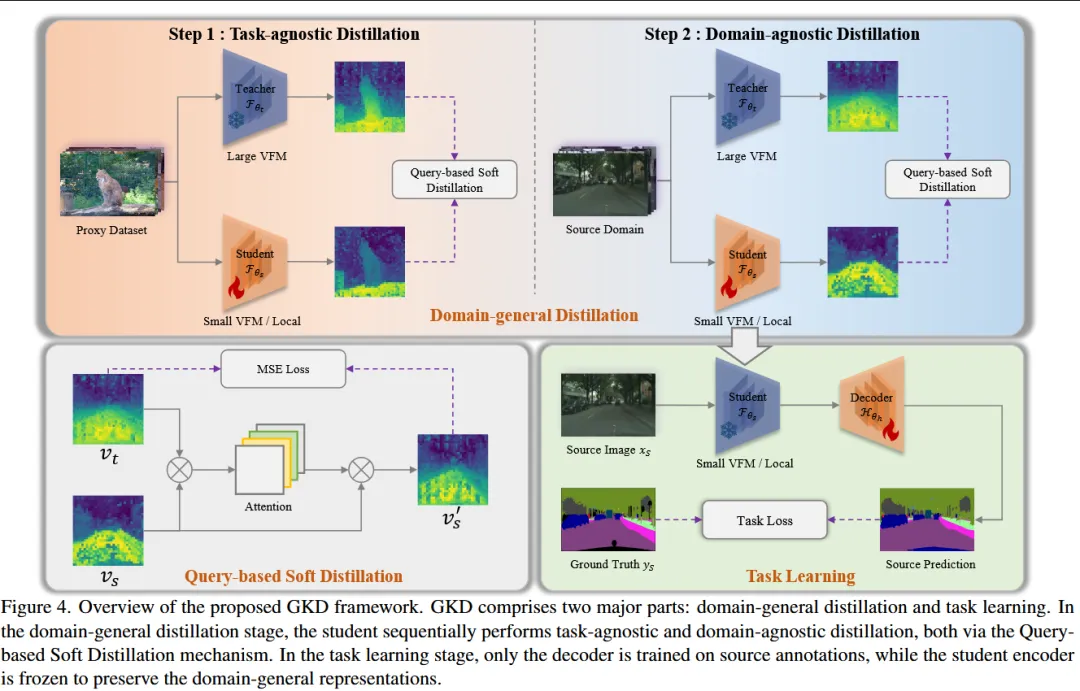
Generalizable Knowledge Distillation from Vision Foundation Models for Semantic Segmentation
【文章研读】CVPR26 | 跨域语义分割新突破:GKD让蒸馏模型继承VFM泛化能力
二、论文研究方向
视觉基础模型蒸馏与跨域泛化的语义分割。
三、文章概要
本文研究在语义分割任务中如何将大型视觉基础模型(Vision Foundation Models, VFM)的知识蒸馏到轻量模型,同时保持其跨域泛化能力。作者发现传统知识蒸馏方法虽然能够压缩模型,但往往会削弱教师模型在未见域上的泛化能力,因此提出 Generalizable Knowledge Distillation (GKD) 框架,通过 多阶段蒸馏策略 将表示学习与任务学习进行解耦:在第一阶段通过选择性特征蒸馏学习 域无关表示,使学生模型获得具有泛化能力的特征;在第二阶段冻结这些表示并进行任务适配,以避免模型过度拟合训练域。此外,论文提出 query-based soft distillation 机制,让学生特征作为查询从教师模型中检索具有迁移能力的空间知识,从而更有效地继承视觉基础模型的结构信息与泛化能力。实验表明该方法在多个跨域分割基准上显著优于传统蒸馏方法,并在 foundation-to-foundation 与 foundation-to-local 两种蒸馏场景下均取得明显性能提升。
—————————
一、论文标题
RAGTrack: Language-aware RGBT Tracking with Retrieval-Augmented Generation
【文章研读】【CVPR2026】视觉+语言+推理:RAGTrack重塑多模态目标跟踪
二、论文研究方向
融合语言信息的 RGB-T 多模态目标跟踪。
三、文章概要
本文针对 RGB-T(可见光+红外)目标跟踪中仅依赖首帧视觉信息建模目标而难以适应外观变化的问题,引入语言信息以增强目标表达能力,并提出 RAGTrack 框架,通过检索增强生成(Retrieval-Augmented Generation)实现跨模态推理式跟踪。该方法首先利用多模态大语言模型自动为 RGB-T 跟踪数据生成文本描述,从而构建视觉-语言联合标注;随后设计 Multi-modal Transformer Encoder 对视觉和语言信息进行统一建模,并通过 Adaptive Token Fusion 根据跨模态相关性选择目标相关特征并进行通道交互,以减少搜索区域冗余和模态差异带来的干扰;最后引入 Context-aware Reasoning Module 构建动态知识库,并利用 RAG 机制在时间维度进行语言推理和信息检索,从而实现更加稳健的目标建模和持续跟踪,在复杂场景和外观变化情况下显著提升 RGB-T 跟踪性能。
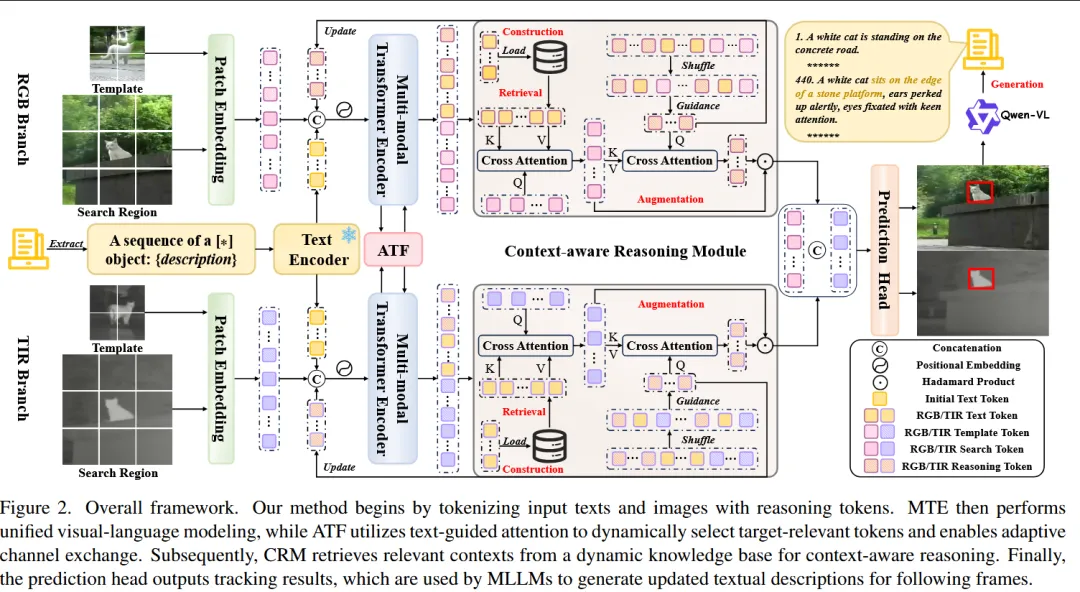
—————————
一、论文标题
Modeling Cross-vision Synergy for Unified Large Vision Model
【文章研读】【CVPR26】NUS&NTU:图像、视频、3D一体化理解:PolyV开启跨视觉协同时代
二、论文研究方向
统一大视觉模型(Large Vision Model)中跨视觉模态协同学习。
三、文章概要
本文针对当前统一视觉模型在处理图像、视频和3D数据时仅实现功能层面统一而缺乏深层模态协同的问题,提出 PolyV 统一大视觉模型,通过建模跨视觉模态之间的协同关系来提升多模态视觉推理能力。该方法在架构层面采用 稀疏 Mixture-of-Experts(MoE)结构 并引入 动态模态路由器(dynamic modality router),使不同专家能够学习各自模态特定的先验知识,同时允许不同视觉模态之间进行双向信息交互与特征互补;在训练层面提出 synergy-aware 训练范式,先进行模态特定预训练,再通过由粗到细的协同微调阶段实现跨模态知识蒸馏以及对象级和关系级对齐,从而逐步建立跨模态视觉语义联系,使模型能够在统一框架下同时处理图像、视频与3D任务并实现更强的跨视觉推理能力。
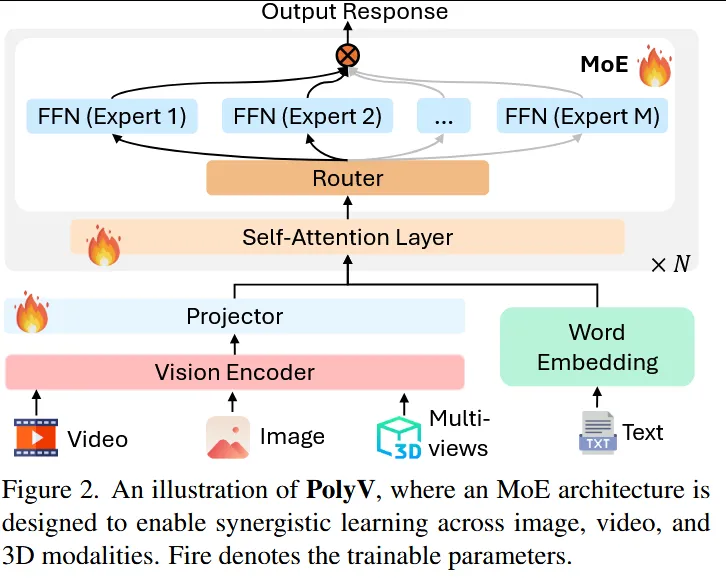
—————————
一、论文标题
Mind the Way You Select Negative Texts: Pursuing the Distance Consistency in OOD Detection with VLMs
【文章研读】【CVPR26】从文本到视觉:InterNeg重塑零样本OOD检测
二、论文研究方向
基于视觉语言模型(VLM)的开放集异常检测(OOD Detection)。
三、文章概要
本文研究视觉语言模型在开放集识别中的 OOD 检测问题,指出现有方法通常利用图像或文本内部的距离关系进行判别,但这种 模态内距离度量 与 CLIP 类模型训练时依赖的 跨模态对齐目标存在不一致,从而限制了检测性能。为解决这一问题,作者提出 InterNeg 框架,通过强化跨模态距离一致性来改进 OOD 检测,其中在文本侧设计 跨模态负文本选择准则,优先选择能够与图像形成更有效对比的负文本描述;在视觉侧则根据模型预测动态筛选高置信度的 OOD 图像,并将这些图像映射到文本空间生成额外的负文本嵌入,以增强跨模态对比学习信号,从而使图像与文本之间的距离关系更加一致并提高未知类别检测能力,在多个 OOD benchmark 上取得显著性能提升。
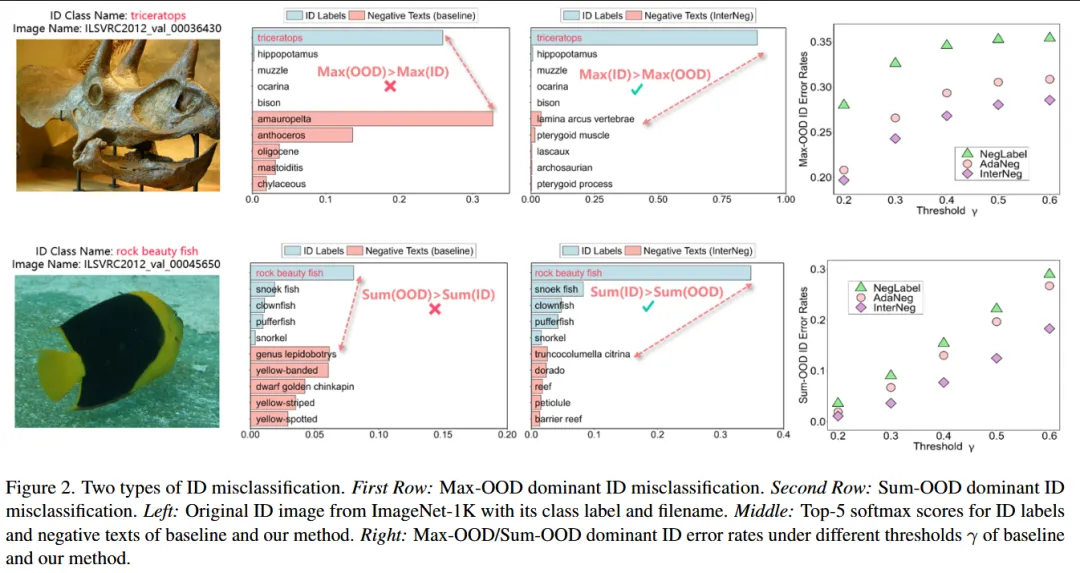
—————————
一、论文标题
Fourier Angle Alignment for Oriented Object Detection in Remote Sensing
【文章研读】【CVPR2026】打破角度瓶颈!频域对齐刷新遥感检测SOTA
二、论文研究方向
遥感图像旋转目标检测(Oriented Object Detection)。
三、文章概要
本文针对遥感图像中旋转目标检测存在的两个关键问题——特征融合阶段的方向信息不一致以及检测头中分类与回归任务之间的冲突——提出 Fourier Angle Alignment (FAA) 方法,通过频域建模实现方向信息的统一表示。具体而言,作者利用 傅里叶旋转等变性在频域中分析特征的主方向并将其对齐到统一方向,然后提出两个即插即用模块:在检测器 neck 中设计 FAAFusion 模块,使高层特征的方向信息与低层特征保持一致后再进行融合;在检测头中提出 FAA Head,通过将 RoI 特征预先对齐到规范角度后再进行分类与回归,从而减少方向不一致带来的误差并缓解检测任务冲突问题,使模型能够更加准确地识别不同方向的目标,在多个遥感检测数据集上显著提升检测精度。
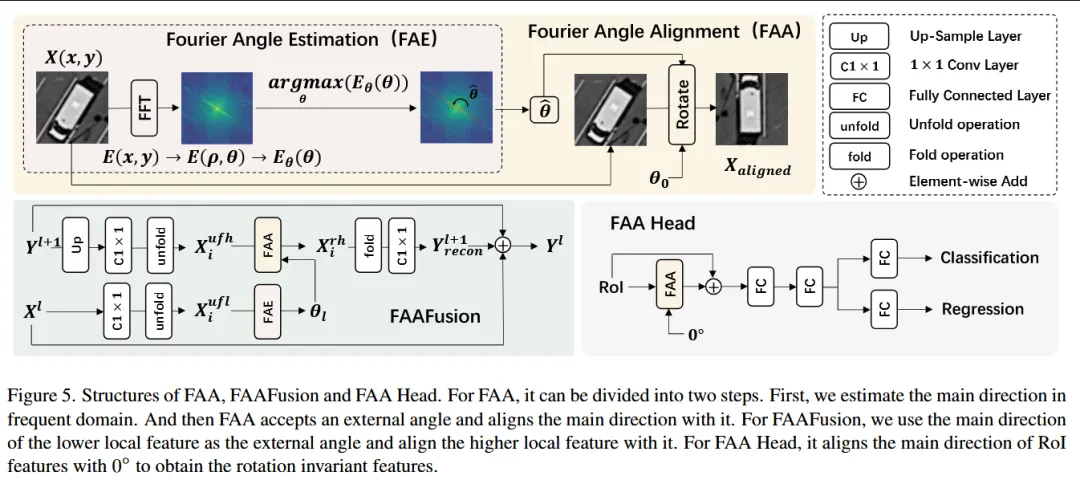
—————————
一、论文标题
Efficient Encoder-Free Fourier-based 3D Large Multimodal Model
【文章研读】【CVPR2026】首个无编码器3D大模型诞生!Fase3D用FFT替代Self-Attention
二、论文研究方向
面向点云场景理解的 3D多模态大模型(3D Large Multimodal Model) 架构设计。
三、文章概要
本文针对现有3D多模态大模型通常依赖复杂视觉编码器提取点云特征而导致计算成本高、扩展性差的问题,提出 Fase3D,一种无需视觉编码器的 Fourier-based 3D Large Multimodal Model。该方法通过设计新的点云 tokenization 机制直接处理无序点云数据:首先利用 空间填充曲线(space-filling curve)序列化 将点云结构转化为序列表示,再结合 快速傅里叶变换(FFT) 在频域中近似自注意力,从而高效建模全局上下文关系并降低计算复杂度;同时通过 superpoint 表示 对大规模场景进行结构化压缩,并采用 图结构 token merging 自适应减少 token 数量以降低 GPU 开销;在语言模型侧,作者进一步提出 Fourier-augmented LoRA 适配器,将频域信息注入 LLM,使其能够捕获几何结构与语义信息之间的全局交互。该框架通过在空间域与频域之间协同建模,实现对大规模3D点云场景的高效理解,在保持与传统 encoder-based 3D LMM 相当性能的同时显著减少计算量
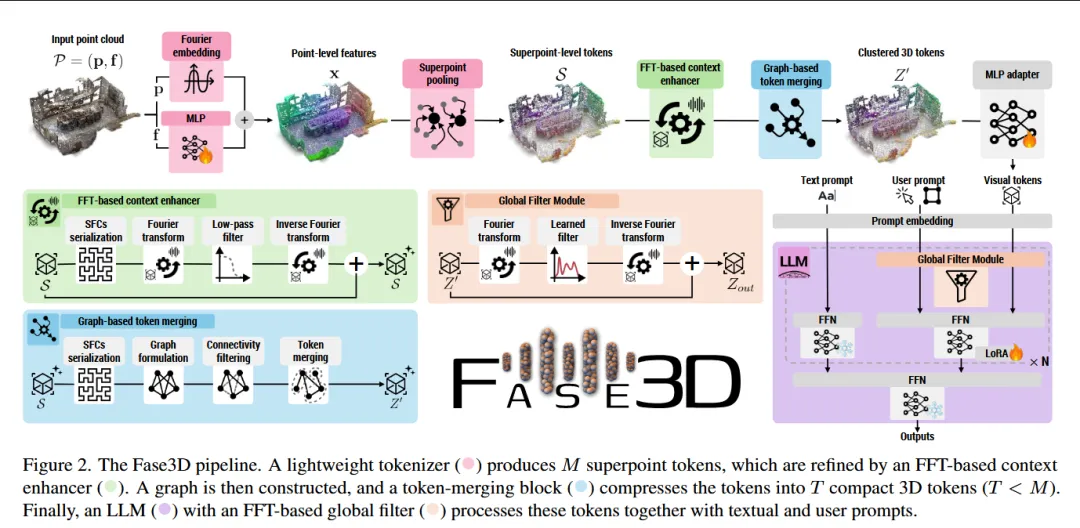
—————————
一、论文标题
SeeThrough3D: Occlusion Aware 3D Control in Text-to-Image Generation
【文章研读】CVPR26:遮挡感知三维生成
二、论文研究方向
三维布局条件控制的文本生成图像(3D layout-conditioned text-to-image generation)。
三、文章概要
本文针对文本生成图像中难以精确建模物体之间遮挡关系的问题,提出 SeeThrough3D 框架,通过显式建模三维场景结构实现遮挡一致的图像生成。该方法首先提出 Occlusion-Aware 3D Scene Representation (OSCR),将场景中的物体表示为位于虚拟空间中的半透明3D包围盒,并通过透明度显式编码被遮挡区域,使生成模型能够理解物体之间的空间遮挡关系,同时利用颜色编码的盒面表示物体方向并支持相机视角控制;随后将该3D场景表示渲染为视觉token并作为条件输入到预训练的文本到图像生成模型中,通过 masked self-attention 将每个物体框与对应文本描述进行绑定,避免多物体生成中的属性混淆,并通过构建包含复杂遮挡关系的合成数据集进行训练,使模型能够在给定3D布局和文本描述的情况下生成具有真实透视关系、正确遮挡顺序和一致相机视角的图像。

—————————
一、论文标题
CATNet: Collaborative Alignment and Transformation Network for Cooperative Perception
【文章研读】CVPR2026 | 自动驾驶协同感知新突破:CATNet解决通信延迟与噪声难题
二、论文研究方向
该论文属于 自动驾驶中的协同感知(Cooperative Perception)与多智能体感知融合 研究方向,具体任务是 多车协同的3D目标检测 / 场景理解。
三、文章概要
该论文提出了一种面向自动驾驶协同感知(Cooperative Perception)的鲁棒融合框架 CATNet(Collaborative Alignment and Transformation Network),旨在解决多车协同感知中常见的 通信延迟导致的时序错位和 多源噪声导致的特征退化两大关键问题。作者设计了一个包含三个核心模块的自适应补偿网络:首先通过 STSync(Spatio-Temporal Recurrent Synchronization)模块利用递归时序建模和运动预测对不同车辆异步传输的特征进行时空对齐;随后通过 WTDen(Dual-Branch Wavelet Enhanced Denoiser)在小波域中进行双分支去噪,从全局和局部两个层面恢复被噪声破坏的特征结构;最后利用 AdpSel(Adaptive Feature Selector)根据语义显著性选择关键区域特征并抑制无效信息,从而实现更加稳健的特征融合。大量实验在 OPV2V、V2XSet 和 DAIR-V2X等协同感知数据集上验证了方法的有效性,在存在通信延迟和噪声干扰的复杂场景中,相比现有方法显著提升检测性能并保持更强鲁棒性,例如在 V2XSet 数据集上 AP@0.5 提升约 4.1%,表明 CATNet 能够有效提升多车协同感知系统在真实环境中的稳定性和准确性。
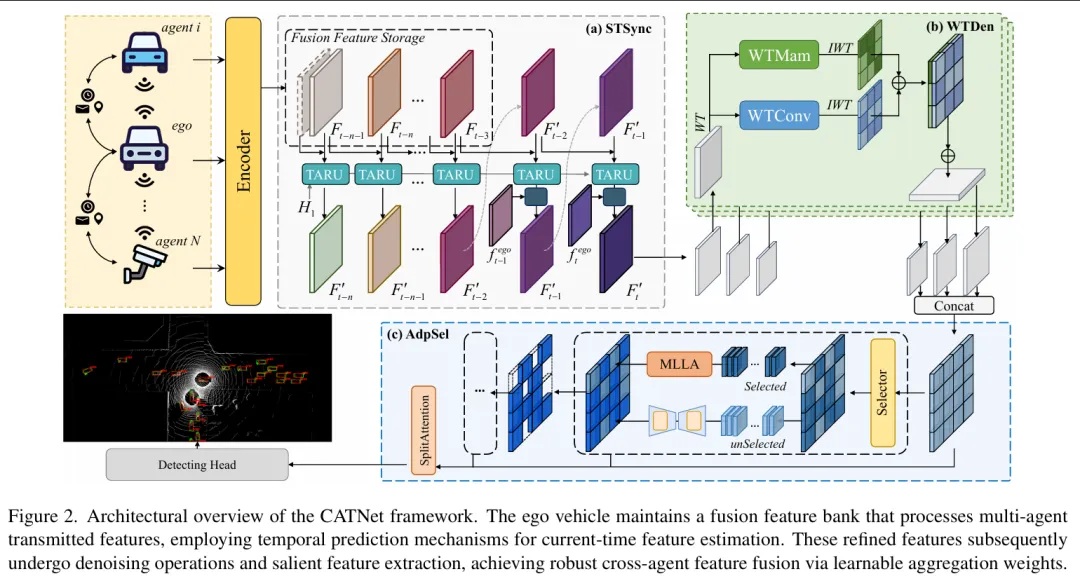
—————————
一、论文标题
FedAFD: Multimodal Federated Learning via Adversarial Fusion and Distillation
【文章研读】CVPR2026 | 多模态联邦学习新突破:FedAFD统一对齐与蒸馏框架
二、论文研究方向
本文属于 多模态联邦学习(Multimodal Federated Learning, MFL)研究领域,重点解决 隐私保护条件下的跨模态协同学习问题。
三、文章概要
本文提出了一种新的多模态联邦学习框架 FedAFD,旨在解决真实场景中客户端数据 模态差异、任务差异以及模型异构等问题。该方法通过 双层对抗对齐(BAA)缩小客户端与服务器之间的跨模态特征分布差异,通过 粒度感知特征融合(GFF)在本地训练中自适应融合全局语义与本地个性化信息,并利用 相似度引导的集成蒸馏(SED)在服务器端实现异构模型的有效知识聚合,从而同时提升全局模型和本地模型性能。大量实验表明,FedAFD在IID和Non-IID环境下均显著优于多种联邦学习基线方法,并在保持客户端个性化能力的同时增强了服务器模型的跨模态表示能力,为实际场景中的隐私保护多模态协同学习提供了一种有效解决方案。
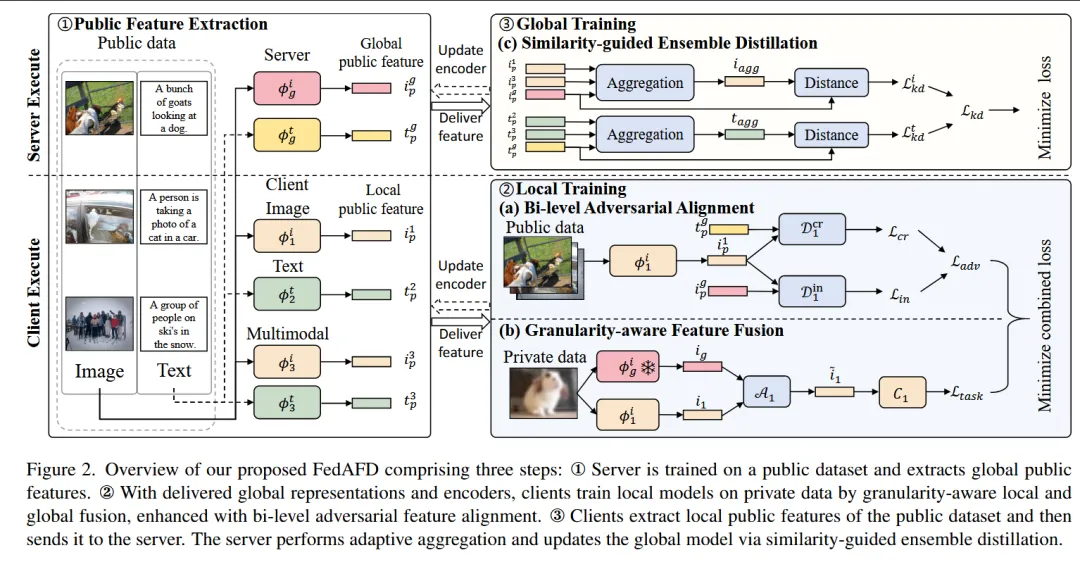
—————————
一、论文标题
二、论文研究方向
本文属于 多模态图学习(Multimodal Graph Learning)与大语言模型推理(LLM Reasoning)交叉领域,重点研究 如何利用大语言模型在多模态图(MMG)上进行结构化推理。
三、文章概要
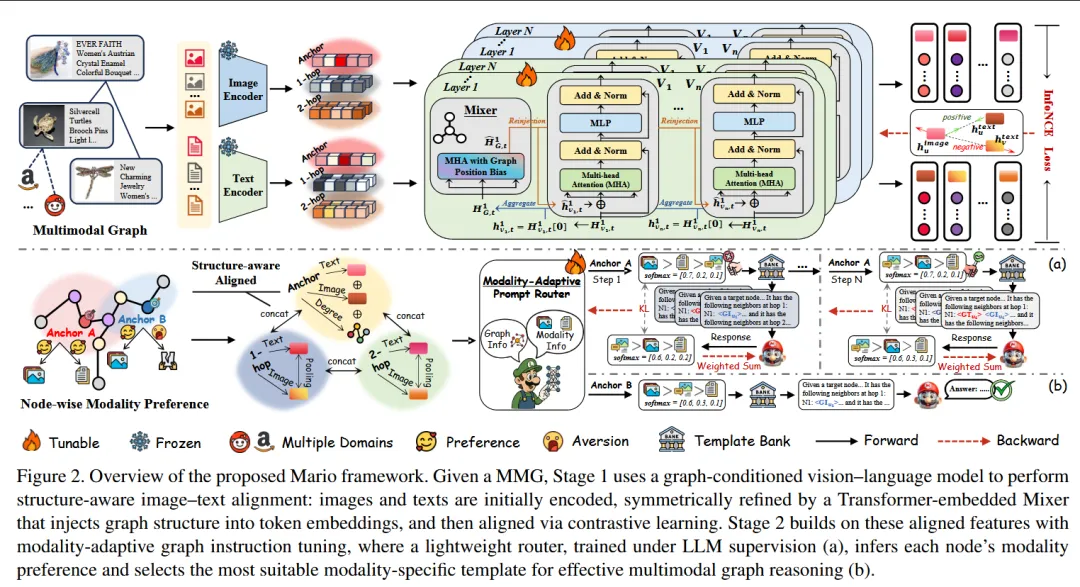
—————————
一、论文标题
二、论文研究方向
该论文属于 视觉生成与图像编辑(Image Editing)领域,重点研究 测试时扩展(Test-Time Scaling)在图像编辑任务中的效率问题。
三、文章概要
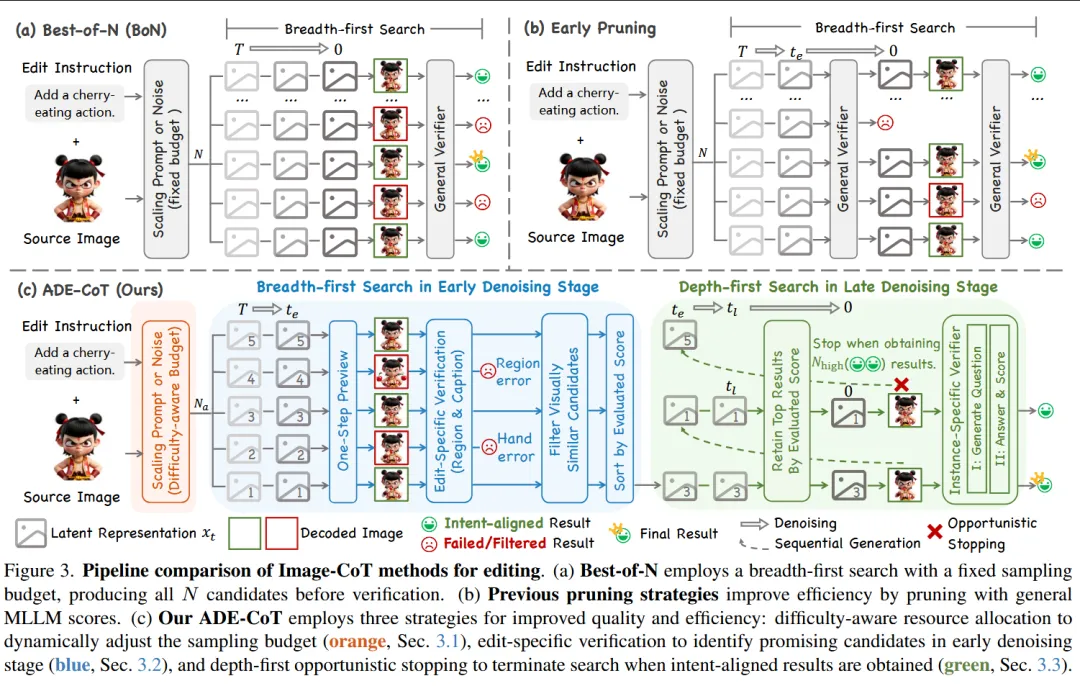
————————–
一、论文标题
二、论文研究方向
这篇论文属于医学图像分割与领域自适应(Domain Adaptation)交叉方向,更具体地说,是源数据不可用的无监督领域自适应(Source-Free Unsupervised Domain Adaptation, SFUDA)
三、文章概要
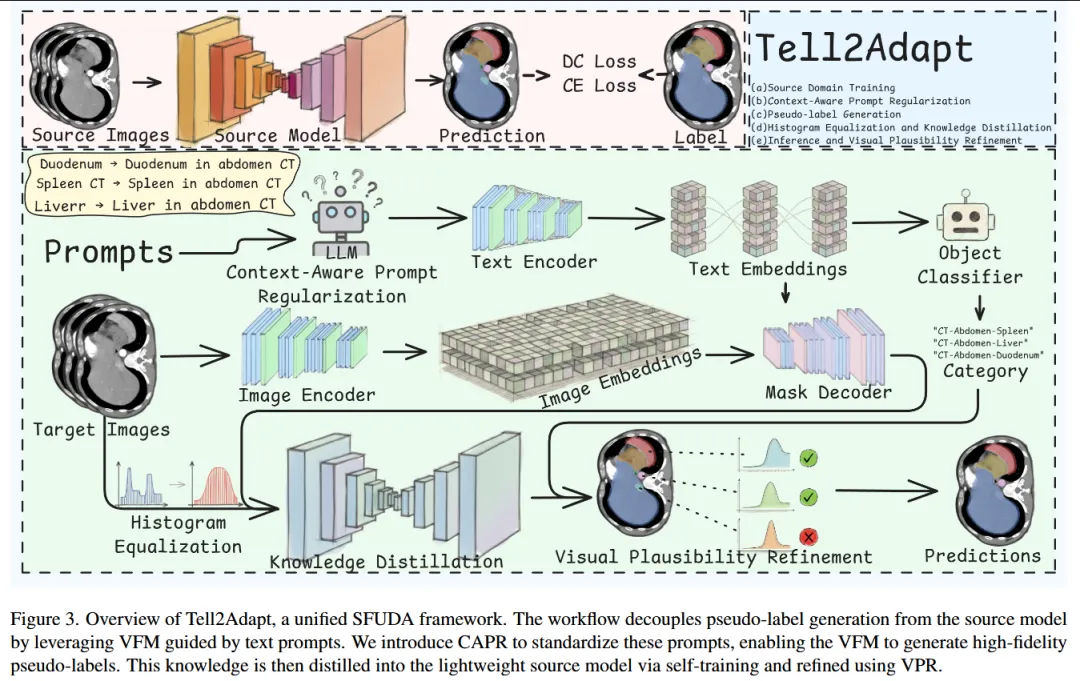
————————–
一、论文标题
二、论文研究方向
三、文章概要
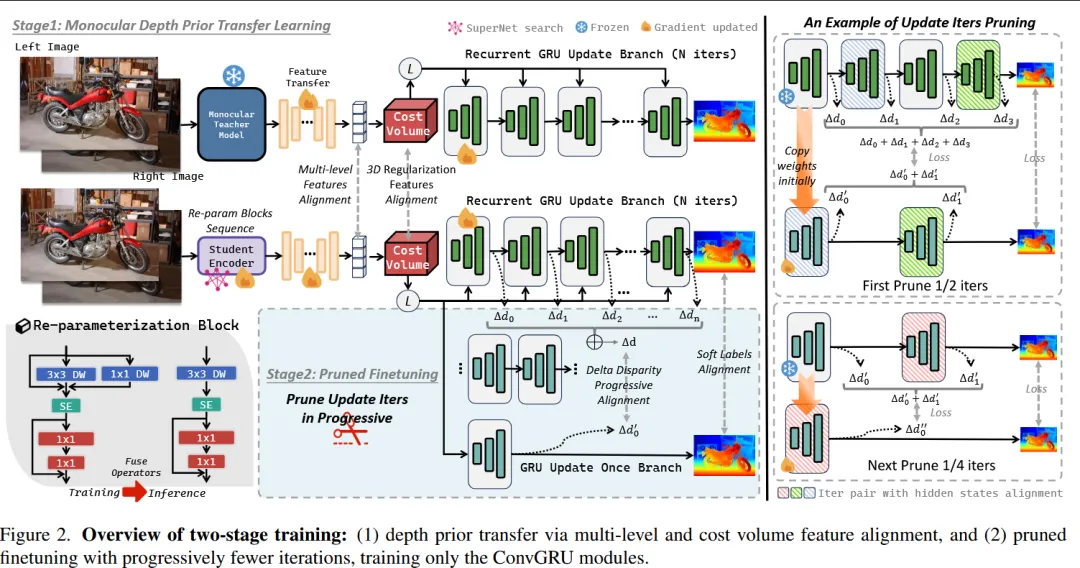
————————–
一、论文标题
二、论文研究方向
三、文章概要
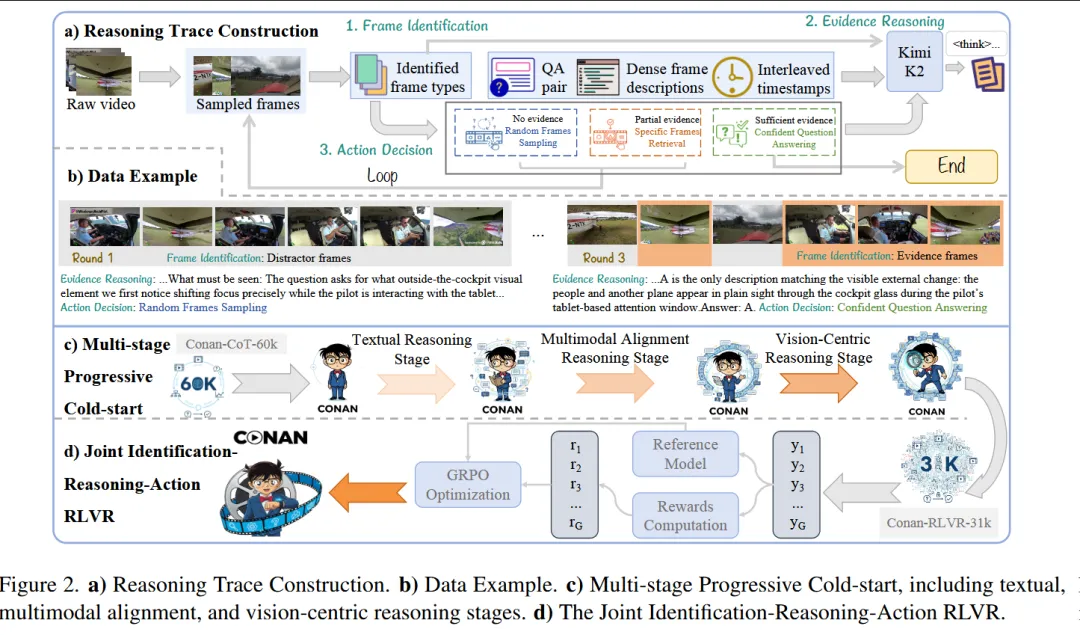
一、论文标题
二、论文研究方向
这篇论文属于视觉大模型(VLLM)后训练 / 强化学习优化方向,具体聚焦于视觉感知任务中的推理分割(reasoning segmentation)
三、文章概要
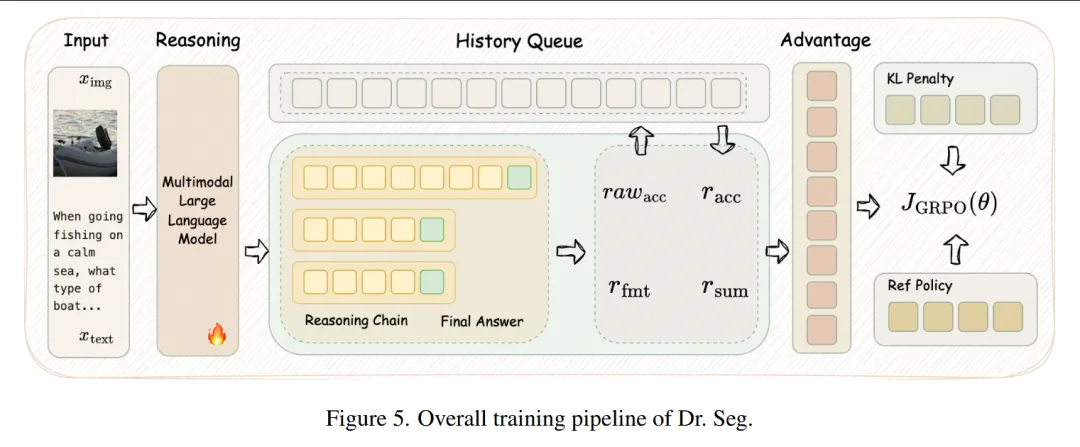
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~本文仅做学术分享,如有侵权、笔误等,请联系修改、删文。