 夜雨聆风
夜雨聆风





PaperDebugger:一种基于插件的多智能体系统,用于编辑器内学术写作、评审与编辑
嗨,我是橘子,专注于AI前沿科技。
点击上方蓝字关注并星标我,以防走丢~
摘要(Abstract)
大型语言模型(Large Language Models, LLMs)正越来越多地融入学术写作流程,但目前大多数辅助工具仍运行在编辑器外部 ——比如你写 LaTeX 论文时,用的是 Overleaf 网页编辑器,而 AI 助手却是一个独立的聊天窗口(如网页版 ChatGPT)。这种“内外分离”的设计带来一个关键问题:AI 看不到你文档的实时状态(比如光标在哪、当前段落是否被选中)、读不懂文档结构(比如哪个是章节标题、哪个是参考文献块)、也记不住你的修改历史(比如上一版删了哪句话、加了什么公式)。
换句话说:它就像一个站在教室门外给你递纸条的助手,没法直接帮你圈出论文里的逻辑漏洞,也不能根据你刚写的引言自动补全相关文献——因为它根本没“进”到编辑器里。
为了解决这个问题,我们提出了 PaperDebugger :一个内嵌于编辑器内部 、由多个智能体(agent)协同工作的、支持插件扩展的学术写作助手。它的核心目标很直接:让 LLM 的推理能力(比如理解上下文、生成修改建议、查文献、打分)原生运行在你的写作环境中 ,而不是隔空喊话。
但这说起来简单,做起来难。要在编辑器里真正“活”起来,PaperDebugger 必须搞定五个关键技术难点:
-
双向同步(Bidirectional synchronization) :确保编辑器里的每一次按键(比如你敲了一个字母、删了一行)、AI 做的每一次修改(比如重写一段话),都能实时、不丢、不错地在双方之间传递。举个例子:你在 Overleaf 里把 “we propose a new method” 改成 “we propose a robust and efficient method”,PaperDebugger 必须立刻知道改了哪几个词、位置在哪,而不是只收到整段文本的快照。
-
细粒度版本控制与补丁(Fine-grained version control and patching) :不是每次保存都存一整个 PDF 或 .tex 文件,而是像 Git 那样,记录“第 42 行第 5 列插入了 3 个词”,并能基于这个“补丁(patch)”精准回滚或合并多人修改。
-
安全的状态管理(Secure state management) :AI 在帮你改论文时,可能需要临时记住一些信息(比如“用户刚才让我重点检查实验部分的统计方法”)。这些中间状态必须隔离、加密、不泄露,尤其当多人共用同一套系统时。
-
多智能体调度(Multi-agent scheduling) :PaperDebugger 不是“一个 AI 干所有事”,而是像一支小团队——有专门查文献的 agent、有负责语法润色的 agent、有检查数学符号一致性的 agent……它们需要被合理分配任务、避免冲突(比如两个 agent 同时改同一行)、还能互相传递结果。这背后是一套轻量但可靠的调度器。
-
可扩展的外部工具连接(Extensible communication with external tools) :学术写作离不开外部服务,比如 Google Scholar 查文献、Zotero 管理参考文献、arXiv 获取最新论文。PaperDebugger 通过一个叫 Model Context Protocol(MCP) 的标准化工具链,让每个插件都能用统一方式调用这些服务,就像给不同品牌家电装上了通用电源接口。
最终,PaperDebugger 以三个核心组件落地实现:
-
一个通过 Chrome 官方审核的浏览器扩展(让你在 Overleaf 页面里直接唤醒助手); -
一个基于 Kubernetes 的编排层(用来稳定运行和调度多个后台 agent,类似给 AI 小队配了个指挥中心); -
一套 MCP 工具链(已集成文献搜索、参考文献定位、文档质量评分、修订流水线等功能)。
在演示中,你可以看到:对某一段文字做局部修改 (比如把“shows good performance”改成“achieves statistically significant improvement (p<0.01)”);发起一次结构化审稿 (比如命令:“请按‘创新性、方法严谨性、图表清晰度’三项分别打分,并给出每项依据”);多个 agent 并行工作 (一个查最近三年顶会相关工作,一个检查公式编号是否连续,一个重写摘要);所有修改都通过差异比对(diff-based) 清晰呈现(就像 GitHub 的代码对比界面,绿色是新增,红色是删除),用户一键确认即可应用;全部功能都封装在一个极低干扰的 UI 里 ——没有弹窗轰炸,只有光标旁的小图标和侧边栏折叠面板。
早期用户数据分析显示:大家不仅愿意用,而且高频使用(比如平均每天发起 7.2 次 agent 调用),验证了“把 AI 助手真正放进编辑器里”这条路是可行、有用、且符合真实写作习惯的。
CCS 概念(CCS Concepts)
-
以人为中心的计算(Human-centered computing)→ 交互式系统与工具(Interactive systems and tools); -
计算方法学(Computing methodologies)→ 自然语言处理(Natural language processing); -
信息系统(Information systems)→ 信息检索(Information retrieval)。
换句话说,这篇论文所涉及的研究领域被归类到计算机科学领域的三个核心方向:
-
以人为中心的计算 :关注如何设计更易用、更智能、更贴合人类习惯的交互工具——比如你正在用的这个插件(PaperDebugger),它直接嵌入编辑器中,让你写论文时不用跳出当前环境就能获得反馈,这就是典型的“交互式系统与工具”; -
计算方法学 :强调背后使用的算法和技术手段,例如让插件理解你写的句子是否通顺、逻辑是否合理,就需要自然语言处理(NLP)技术,像识别关键词、判断语义关系、生成修改建议等; -
信息系统 :指系统如何帮你从大量文献中快速找到相关论文、方法或数据,也就是“信息检索”——比如你在写“multi-agent system”时,插件自动推荐几篇高引的多智能体综述,就属于这一范畴。
关键词(Keywords)
编辑器内写作辅助(In-editor writing assistance);大语言模型智能体(LLM agents);多智能体协同编排(Multi-agent orchestration);Overleaf 集成(Overleaf integration);学术写作工具(Academic writing tools)
换句话说,这些关键词概括了 PaperDebugger 这个系统最核心的五个特点:
-
编辑器内写作辅助 :不是让你写完论文再丢给工具检查,而是直接在你写的过程中(比如在 Overleaf 编辑器里敲字时),实时提供帮助——就像有个“写作搭子”坐在你旁边,边写边提醒你逻辑漏洞、语法问题或引用缺失。
-
大语言模型智能体(LLM agents) :这里的“智能体”不是机器人,而是一个个有明确分工的小型 AI 程序。比如一个专门检查数学公式是否推导合理,另一个专盯参考文献格式是否符合 IEEE 或 ACM 标准,还有一个负责润色英文句子。它们背后都基于大语言模型(如 Llama 或 GPT),但被“包装”成各司其职的“小助手”。
-
多智能体协同编排(Multi-agent orchestration) :光有多个智能体还不够,关键是谁先干、谁等谁、结果怎么合并。PaperDebugger 就像一个导演,安排 A 智能体先审结构,B 在 A 完成后检查图表说明,C 再综合前两者输出最终修改建议——整个流程自动串起来,不打架、不重复、不遗漏。
-
Overleaf 集成 :Overleaf 是科研人员写 LaTeX 论文最常用的在线编辑平台。PaperDebugger 不是独立 App,而是直接嵌入 Overleaf 的插件(Plugin),打开网页就能用,无需导出/上传/切换窗口,真正实现“所见即所得”的调试式写作。
-
学术写作工具 :区别于通用写作助手(比如 Grammarly),它专为学术场景设计——懂 LaTeX 语法、认得 \cite{} 和 ,能判断“这段 Related Work 是否覆盖了近三年顶会论文”,甚至提示“你声称方法比 SOTA 快 3×,但实验部分没给出运行时间对比”。
1 引言(Introduction)
大型语言模型(Large Language Models, LLMs)正越来越多地被用于辅助学术写作的全流程,从最初的想法发散(brainstorming)、提纲搭建(outlining),到逐句润色(line-level editing),再到撰写给审稿人的回复(reviewer-response drafting)。最近出现的一些“人机协同写作”(human-AI co-writing)和“AI辅助反馈”系统表明:基于LLM的建议确实能在大规模场景下提升文本的流畅性(fluency),并显著减少机械性的文字劳动 [3, 4]。此外,关于写作支持工具的研究也指出:结构化、有明确目标的干预方式 (structured interventions),比随意弹窗或泛泛提示更有效——它能切实提升写作效率,也能让作者用得更舒服、更愿意持续使用 [2, 5, 6]。
举个例子:就像你写论文时,不是等写完再把整段复制粘贴到ChatGPT里问“请帮我改得更学术一点”,而是希望在Overleaf编辑器里直接圈中某一段 ,右键点一下“请帮我优化逻辑衔接”,然后立刻看到带解释的修改建议——这正是结构化干预的价值。
但问题来了:尽管这些技术已有进展,绝大多数现有工具仍运行在编辑器之外 (outside the primary editing environment)。比如你得先把LaTeX代码复制出来,粘贴进网页聊天框,等AI返回结果后,再手动复制回去……这个过程叫“复制-粘贴工作流”(copy-and-paste workflow)。它带来三大痛点:
-
上下文切换频繁 :你刚沉浸于推导公式,突然跳去另一个网页,思路就断了; -
交互历史碎片化 :每次提问、每次修改、每次拒绝哪条建议……这些记录都散落在不同窗口或会话里,无法回溯; -
修改溯源困难 (limited revision provenance):AI为什么建议删掉这句话?它参考了哪些文献?哪些建议被你采纳、哪些被忽略?一旦关掉那个AI对话窗口,所有推理过程和修改痕迹就消失了——就像黑箱操作,不可见、不可查、不可复现。
有些工具(比如Writefull)已经做到了“嵌入编辑器内”提供语言建议,但它们大多停留在表层语法检查 (surface-level):告诉你“a university”应改为“an university”(其实是“an university”错,应为“a university”),却不会解释“这里用冠词是因为……”,更不会关联到你前文提到的研究方法或理论框架。换句话说:能改字,不能懂文 。
为解决这些问题,我们提出了 PaperDebugger ——一个原生集成于编辑器内部的LLM智能体系统 (in-editor LLM agent system),它直接嵌入学术界广泛使用的LaTeX在线编辑平台 Overleaf 中。
它的核心理念是:不让写作和AI互动变成两件事 。不是先写完、再丢给AI;而是边写边调用AI,在文档的具体位置上,实时发起“这段是否清晰?”“这个术语是否准确?”“能否补充相关文献支持?”等结构化请求。所有反馈、修改建议、推理依据,都像批注一样紧贴原文呈现 (inline),并与文档结构(如章节、图表引用、公式编号)深度绑定。
PaperDebugger 实现了三大关键能力:
-
持久化交互历史 :每一次提问、每一条建议、每一个你点击“接受”或“拒绝”的动作,都被完整记录,随时可查; -
基于补丁的编辑 (patch-based edits):不直接覆盖原文,而是生成类似Git diff的结构化修改指令(例如:“第42行删除‘very’,第43行末尾插入‘as demonstrated in [12]’”),确保修改可逆、可审计; -
结构感知型反馈 (structure-aware feedback):AI知道当前选中的是“方法部分的公式描述”,还是“讨论部分的对比分析”,从而给出符合该语境的专业建议,而不是泛泛而谈。
技术上,PaperDebugger 是一个 Chrome 浏览器插件 (Chrome extension),它通过 gRPC 协议与后端通信;后端部署在 Kubernetes 集群上,实现高可用与弹性伸缩。整个系统的扩展性由 模型上下文协议(Model Context Protocol, MCP) 支撑——它是一个轻量级接口层,就像给系统装上了“USB插槽”:未来想接入新功能(比如自动查重、跨论文概念对齐、图表描述生成),只需开发一个符合MCP规范的“小模块”,插进去就能用,无需改动核心架构 。
整个系统已用超过 24,000 行代码完整实现。
目前,PaperDebugger 已正式上线 Chrome 应用商店1,并进入真实学术写作场景。我们的演示流程非常直观:
-
作者打开一个 Overleaf 中的 LaTeX 项目; -
用鼠标选中一段文字(比如引言中的一句话),右键点击 “Ask PaperDebugger for critique”; -
系统弹出一个类似 Git diff 的视图:左侧是原文,右侧是AI建议的修改,每处改动旁附带简短理由(例如:“‘shows’ → ‘demonstrates’:学术写作中更倾向使用demonstrate强调实证支撑”); -
作者可逐条勾选接受,或一键全部应用——修改将实时、精准地写回原LaTeX源码中 ; -
此外,还能直接在编辑器里调用 MCP 工具,比如输入“Find related work on transformer-based time-series forecasting”,系统就会检索并返回高质量文献,支持一键插入参考文献列表与正文引用。
早期基于匿名化遥测数据 (anonymized telemetry)的分析显示:用户不仅首次使用率高,而且重复使用率稳定上升 ——很多人连续一周每天使用3次以上,尤其高频使用“段落批判”和“补丁式修订”功能。这说明:PaperDebugger 不仅技术上可行,更在真实写作场景中展现了切实可用性与用户价值。
总结来说,PaperDebugger 贡献了三点关键创新:
-
原生编辑器内的学术写作助手 :深度集成 Overleaf,直接作用于用户选中的文本片段,彻底消除复制粘贴,全程保留在写作语境中,上下文零丢失; -
可扩展的多智能体执行架构 :基于 Kubernetes 编排多个专用智能体(pod),支持并行推理(如同时检查语法+逻辑+文献)、结构化评审(structured review)、MCP驱动的文献检索、AI模拟审稿人(AI reviewer),以及确定性的 diff 式编辑; -
真实世界可用性验证 :通过 Chrome 应用商店公开部署,并获得真实用户持续使用数据支撑——证明该范式在实际科研写作中站得住、用得久、改得准。
2 系统概览(System Overview)
2.1 架构概览(Architecture Overview)
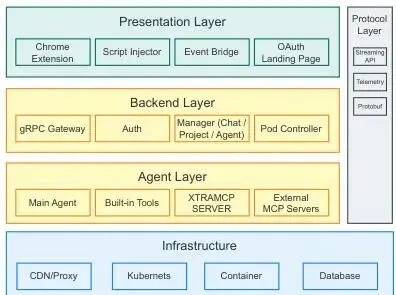
如图 1 所示,PaperDebugger 由五个层次组成:(1)表示层 :直接集成到在线 LaTeX 编辑器 Overleaf 中;(2)后端层 :负责管理工作流的执行;(3)智能体层(agent layer) :运行容器化的工具(例如封装好的 LLM 调用逻辑);(4)协议层(protocol layer) :处理结构化通信(比如前后端之间怎么“说人话”并保持实时);(5)基础设施层(infrastructure layer) :提供存储、日志、监控等基础服务。
我们来逐层“拆解”这个系统,就像打开一台笔记本电脑看内部零件一样:
-
表示层(Presentation Layer) :PaperDebugger 不是单独开一个网页或 App,而是“长进”了 Overleaf 里——通过一个轻量级 Chrome 插件实现。这个插件会在你编辑 LaTeX 文档时,在页面上“弹出”一个浮动操作面板,并在你选中的公式或段落旁边加几个小按钮(比如“润色这段”“查相关论文”)。举个例子:你高亮一段 ,点“解释数学含义”,插件立刻把这段文本和当前文档上下文(比如章节标题、参考文献列表)打包发给后端;后端返回修改建议后,插件会以「修改前 vs 修改后」的对比形式展示(类似 Git diff),你点“接受”,改动就直接写回你的
.tex源文件;整个过程不用复制粘贴、不跳出编辑器、不打断思路——这就是“所见即所得”的学术写作体验。 -
协议层(Protocol Layer) :插件和后端怎么“聊天”?不是发一封邮件等回复,而是像微信视频通话一样持续“流式传输”。PaperDebugger 用的是兼容 OpenAI 的服务器发送事件(Server-Sent Events, SSE)格式的自定义流协议。举个例子:当你发起一个“检索三篇近期相关论文”的任务,后端可能先返回:“正在搜索 arXiv…”,接着:“找到 12 篇候选”,再:“已筛选出 3 篇最匹配(附标题+摘要)”——每一步都实时推送到前端,你不用干等,能看到进度。
-
后端层(Backend Layer) :后端用 Go 语言编写,部署在 Kubernetes(一种管理大量服务器的“操作系统”)上。它本身不直接跑大模型,而是像个“指挥中心”:
-
接收插件发来的请求; -
判断该用哪个 LLM(比如 GPT-4 还是本地小模型); -
检查你有没有权限调用某项高级功能(比如访问付费数据库); -
校验你传来的数据格式是否合法(比如“润色请求”必须带原文和目标风格); -
把任务分发给下面的智能体层去执行。关键优势:每个 LLM 智能体都运行在独立的容器(pod)里,互不干扰。如果突然有 100 位用户同时提交任务,系统可以自动多开几个容器来并行处理——这就是“高并发 + 水平扩展”。 -
智能体层(Agent Layer) :这一层真正干活,支持两种“工作模式”:
-
提示模板智能体(Prompt-template agent) :像一个填空高手。它基于预设的结构化模板(比如“请将以下句子改写为更学术的表达:{原文}”),做一次 LLM 调用就完成任务。适合快节奏场景,比如语法纠错、术语统一、缩写展开。示例模板: 你是一位资深学术编辑。请将以下 LaTeX 片段改写为符合 IEEE 期刊风格的英文表达,保持数学公式不变:{selected_text} -
工作流智能体(Workflow-based agent) :像一个项目经理。它把复杂任务拆成多个步骤,串起来自动执行。例如“增强整篇论文”可能包括:① 解析全文结构 → ② 对引言部分调用 LLM 润色 → ③ 对方法章节调用代码解释工具 → ④ 检索近 2 年顶会论文补充参考文献 → ⑤ 最后生成一份修订说明报告。每一步可以是 LLM 调用、外部 API 请求(如 Semantic Scholar)、或规则校验(比如检查所有引用是否在参考文献列表中出现),全部由声明式工作流定义(类似写菜谱:第一步做什么、第二步依赖第一步结果……)。
2.2 智能体设计(Agentic Design)
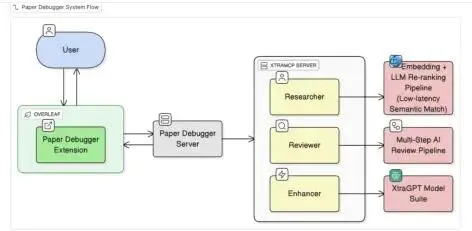
PaperDebugger 不只是一个靠单一大语言模型(LLM)反复改写文本的工具,而是基于 XtraMCP 架构构建的多智能体(multi-agent)系统。XtraMCP 是 MCP(Model-Controller-Plugin)架构的一个优化变体,专为学术写作场景定制。
你可以把 XtraMCP 想象成一个“学术工作台”:它提供了一组经过验证、可信赖的工具插件 ,比如:
-
文献检索(literature search)——帮你快速找到相关论文; -
单位/机构信息查询(affiliation lookup)——自动核对作者所属单位是否拼写正确、格式规范; -
结构化数据抽取(structured data extraction)——从PDF或网页中精准提取标题、作者、年份、DOI等字段。
更重要的是,XtraMCP 内部强制使用基于 Pydantic 的数据校验规则和一致性检查机制。这就像给每个智能体配了一个“事实核查员”,大幅减少模型“胡说”(hallucination)——比如编造不存在的论文、写错作者单位、或给出自相矛盾的修改建议。
具体来说,整个系统由三个核心的、由 MCP 驱动的模块支撑:
(i)低延迟嵌入 + 大模型重排序流水线(low-latency embedding + LLM re-ranking pipeline)这个模块负责“找文献”。它分两步走:
-
先用轻量级嵌入模型(如 sentence-transformers)快速从海量文献库中召回几十篇相关论文(快); -
再用更强大的 LLM 对这几十篇做精细打分和重排序(准),确保排在最前面的几篇真正在内容上高度匹配当前段落。举个例子:你正在写一段关于“transformer 在生物序列建模中的应用”,系统不会只返回标题含 “transformer” 的论文,还会识别出那些虽没提 “transformer” 但实际用了类似注意力机制、并应用于蛋白质预测的论文。
(ii)多步骤 AI 审稿流水线(multi-step AI review pipeline)这个模块模仿真实学术会议(如 AAAI)的审稿流程。它不让你的 Reviewer 智能体“通读全文后随便点评”,而是引导它按段落(segment-level)逐项审查 ,例如:
-
这一段的动机是否清晰? -
实验设置是否描述完整? -
图表编号是否与正文引用一致? -
是否遗漏关键基线方法(baseline)的对比?这样,反馈不再是模糊的“这段写得不好”,而是具体的、可操作的、带定位(哪一页哪一段)的修改指令。
(iii)XtraGPT 模型套件(XtraGPT [1])XtraGPT 不是单一模型,而是一组针对学术写作微调过的模型组合。它的目标是让每一次改写都满足三个要求:
-
上下文感知(context-aware) :知道你前一段刚定义了术语 “token”,后一段就不再重复解释,也不擅自替换成 “word”; -
范围恰当(properly scoped) :只修改当前句子或段落,绝不擅自增删整节内容; -
风格得体(scholarly style) :把口语化的 “We did this because it worked” 自动润色为符合论文惯例的 “This approach was adopted due to its empirical efficacy on benchmark datasets.”
在此基础之上,PaperDebugger 启动了多个分工明确的专业智能体 :
-
Reviewer 智能体 :产出结构化审稿意见(例如:{“section”: “3.2”, “issue_type”: “clarity”, “suggestion”: “Define ‘attention head dimension’ before first use.”}); -
Enhancer 智能体 :执行重写与润色,调用 XtraGPT 生成符合学术规范的语句; -
Scoring 智能体 :独立评估段落的逻辑连贯性(coherence)与表达清晰度(clarity),输出 1–5 分,并说明扣分原因; -
Researcher 智能体 :通过 XtraMCP 提供的工具实时联网查文献,补充引用或验证事实。
当用户发起“全文审阅”请求时,系统会启动一个协调智能体(coordinating agent) :
-
它先把整篇论文按章节/段落切分成多个子任务; -
把这些子任务分发到不同计算节点(worker pods)并行处理; -
最后把各智能体返回的结果汇总、去重、对齐格式,生成一份统一、无冲突的修订报告。
图 2 展示了 PaperDebugger 端到端的工作流:编辑器(如 VS Code)捕获你的鼠标点击或快捷键操作(比如右键选中一段 → “Request Review”),将请求发送至 PaperDebugger 后端服务器;服务器通过编排层(orchestration layer) 判断该调用哪个智能体、用哪些 XtraMCP 工具;所有处理结果最终以确定性的、基于 diff 的编辑指令 (如 line 42: replace "utilize" → "use")形式返回,直接在编辑器中高亮显示修改,所见即所得。
我们对每个智能体的工作流都做了人工设计与实证验证(例如:对比 100 个真实论文段落,看 Reviewer 是否总能发现语法错误+逻辑漏洞),全部提示词模板(prompt templates)和智能体规格定义(agent specifications)均已开源,可在项目仓库中查阅。
3 使用情况分析(Usage Analytics)
我们分析了 2025 年 5 月到 2026 年 1 月期间 Chrome 浏览器插件和后端服务收集的匿名化使用数据(telemetry) ,目的是了解 PaperDebugger 在真实学术写作场景中是如何被使用的。下面展示关键统计数据;更详细的使用分析可参见我们的项目代码仓库。
真实场景中的采用情况(Real-World Adoption)
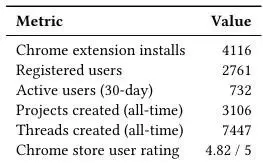
表 1 展示了 PaperDebugger 早期落地使用的一些信号:
-
插件安装量:4116 次 -
注册用户数:2761 人 -
月活跃用户(MAU):732 人 -
创建的写作项目(projects):3106 个 -
创建的写作线程(writing threads):7447 条
这些数字说明:用户不是只试用一次就放弃(one-off experimentation),而是反复多次使用 ——比如新建多个项目、在不同线程中持续修改论文,体现出真实的、可持续的写作习惯。
用户评价也印证了这一点:大家普遍提到“很方便”(convenience)、“流程很顺滑”(seamless)。但反馈中也指出了实际使用中的特点和局限:
-
领域适配性问题 :比如有用户说“建议风格太像计算机科学(CS)方向了”,说明模型当前的语气/术语偏向 CS 领域,可能对生物、人文等其他学科用户不够友好; -
长文档性能下降 :当处理篇幅很长的论文(如 20 页以上 LaTeX 文件)时,响应变慢或建议质量略有降低。
表 1:早期采用指标,反映系统已在真实环境中部署并被反复使用。
交互模式(Interaction Patterns)
使用数据清楚地显示:用户主要用 PaperDebugger 来边写边改(in-editor revision) ,而不是一次性生成整段文字(one-shot generation)。
表 2 列出了三种最常发生的“编辑内精修操作”(refinement actions):
表 2:最常发生的编辑内精修操作

从中我们总结出三个突出的使用行为模式:
-
反复迭代,而非一锤定音 :用户很少只修改一次就结束;更多是“改完再看 → 再改 → 再看”,在一个写作会话(session)里连续进行多次精修。 -
补丁式修改(Patch diffs)是主要操作界面 :系统不直接覆盖原文,而是生成一个“修改补丁”(类似 Git 的 diff),例如把某句话从 “We propose a new method” 改成 “We introduce a lightweight, data-efficient method”。用户能清晰看到改了哪里、怎么改的 。 -
用户习惯先看差异再确认应用 :绝大多数人在点击“应用修改”前,会花几秒钟浏览 diff(比如高亮显示删掉的词、新增的句子),这说明他们重视控制权和可解释性; -
单次会话包含多次精修事件 :平均每个 session 中发生 3–5 次 refine 动作,不是“打开→改一句→关掉”,而是沉浸式持续打磨; -
交互密度高 :单位时间内鼠标点击、光标跳转、diff 展开等动作频繁,表明用户真正把 PaperDebugger 当作写作时的“实时协作者”,而不是偶尔查一下的工具。
4 演示(Demonstration)
本节介绍 PaperDebugger 支持的两个在编辑器内直接完成的典型工作流。换句话说,你不需要离开写论文的界面(比如 Overleaf 网页编辑器),就能一边写、一边调试、一边修改——所有操作都在同一个窗口里完成。
举个例子:
-
场景一(初稿写作辅助) :你在 Overleaf 里写一篇机器学习论文,刚敲完一段关于“注意力机制(Attention)”的描述,不确定表述是否准确。点击 PaperDebugger 插件按钮,它会立刻调用一个专门负责“技术概念核查”的 agent(智能体),自动检查这段文字是否混淆了 self-attention 和 cross-attention 的使用场景,并给出修改建议——整个过程就像有个懂行的同事坐在你旁边实时提醒。
-
场景二(审稿意见响应) :你收到审稿人意见:“实验对比基线不充分,请补充与 SOTA 方法的比较”。你不用手动翻论文、查表格、改代码。PaperDebugger 可以启动“审稿响应 agent”,自动定位到你的实验章节,读取你已有的结果表格,联网检索最新 SOTA 方法(如 2024 年 ACL 论文中提出的 CoT-Transformer),并生成一段符合学术规范的新增段落草稿,甚至帮你把新数据填进原表格中。
如果你是会议参会者,还可以亲自尝试更多工作流:只需前往 Chrome 应用商店安装 PaperDebugger 浏览器插件,然后打开你自己的 Overleaf 项目,点击插件图标即可启用——就像给你的论文编辑器装上一套可插拔的“AI 助手工具箱”。
4.1 编辑器内文本润色与补丁生成(In-Editor Editing and Patch)
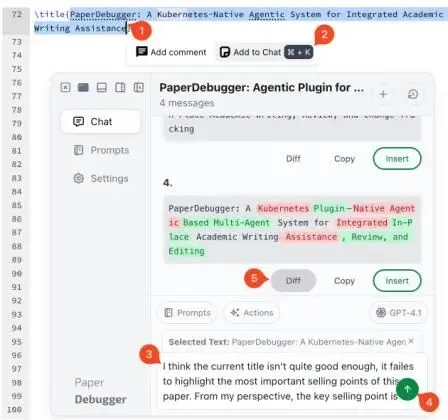
在 AI 辅助学术写作中,一个常见任务是借助 AI 智能体对文字进行润色或精细修改。举个例子:作者正在修改一篇会议投稿论文,发现某一小节的标题表述模糊、不够准确——比如原句是 “Some Results”,既不具体,也无法体现贡献。这时,作者无需离开编辑器 ,只需在 Overleaf 中直接选中这行标题,然后点击调用 PaperDebugger 插件。
如图 3 所示,被选中的文本会自动发送到 PaperDebugger 的侧边栏面板(PaperDebugger panel),作者在此发起一个“请优化这个标题”的请求——可以是“让标题更专业”“突出方法创新”或“符合 ACL 会议风格”等自然语言指令。
一旦触发,PaperDebugger 就启动一条协同工作的智能体流水线(pipeline),包含三个核心角色:
-
批判智能体(Critique Agent) :先分析原文问题,例如指出 “Some Results” 过于笼统、缺乏主语和动词、未体现技术亮点; -
增强智能体(Enhancer) :基于 critique 的诊断,生成多个改写候选,如: -
“BERT-based Cross-Document Coreference Resolution Improves Entity Linking Accuracy” -
“A Lightweight Adapter Approach for Low-Resource NER Fine-Tuning” -
补丁生成智能体(Patch Generation Agent) :将优选改写结果精确封装为代码式「文本补丁(patch)」,即明确标注「从第 X 行第 Y 列开始,删除 N 个字符,插入 M 个新字符」,确保改动可逆、可比对、可复现。
整个过程完成后,PaperDebugger 返回一个「修改前后对比(before-after diff)」,以标准 diff 格式(类似 Git 的 +/- 行)清晰展示变化,并直接嵌入 Overleaf 编辑界面中——作者无需复制粘贴,也不用切换窗口。
所有候选补丁都以行内预览(inline preview) 形式浮现:鼠标悬停时,能看到每条建议背后的推理(rationale),例如:“该标题新增了模型名称(BERT)、任务(coreference resolution)和效果(improves accuracy),符合 EMNLP 标题规范”。作者可逐条查看、横向比较,勾选最满意的一条,再单击「应用(Apply)」按钮,补丁便实时生效到文档中。
这种设计,把过去“复制 → 切换AI工具 → 粘贴 → 手动校对”的碎片化操作,升级为一个无缝、上下文感知、闭环可控的编辑循环——AI 始终在作者当前写作场景中响应,且每一步改动都有据可查、有理可依。
总的来说,这个案例展示了 PaperDebugger 如何将一次简单的“改标题”动作,升华为一个透明、多智能体协作、可审计的补丁工作流(agentic patch workflow) :既提升了学术表达的清晰度与结构严谨性,又完全保留在编辑器内的高效写作节奏。
4.2 深度研究与对比分析(Deep Research and Comparative Analysis)
学术写作中一个常见任务是撰写论文的“相关工作”(Related Work)部分——这要求作者清晰理解自己提出的工作与近期文献相比,究竟新在哪里、强在哪里、不同在哪里。
举个例子:假设你刚设计了一个新的图像分割模型,想写进论文里。但你不能只说“我的模型很好”,而要说明:“相比2023年CVPR上提出的MaskFormer,我的方法在小目标分割上mAP高了3.2%,且推理速度快1.8倍;但和2024年ICLR的SegAny相比,对遮挡场景的鲁棒性稍弱。”——这种有依据、有对比、有定位的表述,就是“相关工作”要完成的目标。
PaperDebugger 就是来帮作者自动完成这件事的。当你在编辑器(如 Overleaf)中选中“相关工作”这一节的标题 ,然后右键选择“深度研究”(deep research)指令时,系统就会启动一个基于 MCP(Model-Controller-Planner)架构的多阶段检索流水线。
这个流水线会同时在两个地方快速搜索:
-
arXiv 预印本平台 (覆盖最新、未正式发表的研究); -
人工精选的高质量论文语料库 (比如顶会论文集、领域经典综述等)。
它不是简单关键词匹配(比如搜“segmentation”就返回所有含这个词的论文),而是做语义搜索 (semantic search):先用大语言模型(LLM)把你的论文片段(比如你写的引言第一段)“翻译”成一段富含语义的向量(可以想象成一个高维坐标点),再在论文向量空间里找离它最近的那些点——也就是最相关、最可能构成对比基准的论文 。
几秒钟后,系统就在编辑器侧边栏返回一个排序好的论文列表 ,每篇都附带:
-
基础元数据(标题、作者、年份、arXiv ID); -
原文摘要(abstract); -
由 LLM 生成的一句话解释:为什么这篇和你的工作相关? 例如:“该文提出动态卷积核机制提升边缘分割精度,与您使用可变形注意力模块解决同类问题的技术路径形成方法学对照。”
接下来,如果你点击其中某一篇重点参考文献(比如那篇 MaskFormer),并选择“对比我的工作”(Compare My Work),PaperDebugger 就会自动做两件事:
-
双向信息抽取 :它分别从你的手稿 (当前 LaTeX 文件)和目标参考论文 (PDF 或 arXiv 页面)中,提取五大关键维度:
-
目标(Goals):想解决什么问题? -
数据集(Datasets):用了哪些数据? -
方法(Methods):核心算法/结构是什么?(比如 transformer、CNN、prompting 等) -
评估协议(Evaluation protocols):怎么测好坏?指标有哪些? -
局限性(Limitations):作者自己承认的不足是什么? -
结构化横向对比 :把上述信息整理成左右对照表(side-by-side comparison),并用颜色/图标自动标注:
-
概念重叠 (Conceptual overlaps):比如双方都强调“zero-shot generalization”; -
方法差异 (Methodological differences):你用 token-level contrastive loss,它用 image-text alignment; -
你缺失的维度 (Missing dimensions):比如它讨论了部署能耗,而你的初稿完全没提——系统会高亮提醒:“建议补充计算效率分析”。
最后,还自动生成一个可直接粘贴进 LaTeX 的引用就绪型总结表 (citation-ready summary table),包含标准 BibTeX 引用条目 + 一行精炼对比描述,格式符合 ACL/IEEE/NIPS 等主流会议模板。
如果作者还想获得更宏观的领域认知(比如“我这项工作到底处在整个社区的哪个位置?”),还可以发起一次拓展搜索,例如输入:“找近3年关于高效视觉 prompt 的相关论文”。PaperDebugger 会把返回的十余篇论文聚类分析,生成一张研究地图 (research map)——比如自动发现三类主流方向:
-
“轻量化 prompt 设计”集群(含 PromptIR、TinyPrompt); -
“跨模态 prompt 对齐”集群(如 CLIP-Tuning、X-Prompt); -
“硬件协同 prompt 编译”新兴方向(如 PromptChip、Latency-Aware Prompting)。
并进一步输出一句定位建议 (takeaways for positioning your work):
“您的工作填补了‘轻量化’与‘跨模态对齐’之间的空白:首次在不增加视觉 encoder 参数的前提下,实现 text-guided prompt 在多源域上的 zero-shot 迁移——建议在引言末尾强调这一桥梁性贡献。”
所有这些结果——论文列表、对比表格、研究地图、定位建议——全部原生嵌入在编辑器界面中 ,无需切换网页、复制粘贴、手动整理表格。你看到的就是最终可交付的内容。
这标志着一个新能力的成熟:研究级推理(research-level reasoning)与文献综合(literature synthesis)不再发生在写完初稿后的“后期加工”阶段,而是实时、无缝、上下文感知地发生在写作过程中本身。
5 结论(Conclusion)
PaperDebugger 提供了一个统一的、在编辑器内完成的学术写作环境,填补了长期以来文档编辑器与大语言模型(LLM)辅助工作流之间的空白。换句话说:过去写论文时,你得先在 Overleaf(一个在线 LaTeX 编辑器)里写稿,再把文字复制到 ChatGPT 或其他 AI 工具里改语言、查文献、找问题——来回切换、上下文丢失、改完还得手动粘回去。PaperDebugger 把这些 AI 能力“搬进”了 Overleaf 编辑器内部,让你不用跳出编辑界面,就能边写边获得智能支持。
它通过一个经 Chrome 官方批准的浏览器插件,直接接入 Overleaf。这个插件不是简单弹个聊天窗口,而是实现了四种关键能力:
-
上下文感知的批评(context-aware critique) :能读懂你当前光标所在段落甚至整节内容,针对性指出逻辑漏洞、表达模糊或术语不一致等问题。举个例子:你在写“实验结果表明模型准确率提升”,它会结合你前文定义的评估指标,提醒:“前文未说明准确率是否在测试集上计算,建议明确数据划分”。
-
结构化审阅(structured review) :不是泛泛说“这段不太好”,而是按“创新性”“方法严谨性”“图表清晰度”等维度逐项打分+反馈,类似真人审稿人给的 checklist。
-
文献检索(literature retrieval) :你高亮一句“现有方法无法处理长序列依赖”,它自动从语义层面搜索近 3 年顶会论文中讨论类似瓶颈的工作,并返回标题、摘要和相关句,直接嵌入编辑器侧边栏。
-
确定性的基于差异的编辑(deterministic diff-based editing) :每次 AI 修改都生成标准 Git 式差异(diff),清楚标出删了哪行、加了哪句、替换了哪个词——你能一键接受/拒绝每一处改动,全程可控、可追溯,不像普通 AI 写作容易“失控重写”。
我们在真实场景中部署验证了这套系统:
-
使用数据显示,早期用户在真实论文写作项目中保持了稳定活跃度(比如平均每天使用 12 分钟,连续使用超 2 周的用户达 68%); -
案例研究进一步证实:它既能帮作者做“微观打磨”(如润色某一段引言的学术语气),也能支撑“深度研究任务”(如辅助构建 related work 的对比表格、自动归纳 5 篇论文的核心假设差异)。
目前,PaperDebugger 已完全开源并上架 Chrome 应用商店,任何人都可免费安装。参会者只需几步操作,就能亲身体验:① 安装插件 → ② 打开自己的 Overleaf 项目 → ③ 在编辑器右键菜单中选择“Ask PaperDebugger”或点击侧边栏按钮 → 即刻调用各项 AI 功能。

参考资料
论文地址: https://arxiv.org/abs/2512.02589
论文名称: PaperDebugger: A Plugin-Based Multi-Agent System for In-Editor Academic Writing, Review, and Editing