 夜雨聆风
夜雨聆风





【第12期】AI文档工作流:从0到1搭建智能文档处理系统
🎯 AI文档工作流:从0到1搭建智能文档处理系统
大家好,我是会一聊AI。
😱 一个项目经理的痛苦
说个真实的数据:工程项目中,工程师平均每天要处理20-30份文档,包括技术规范、施工方案、验收报告、变更单、合同文件等等。
上周我在一个工地上跟项目经理聊天,他跟我说了句让我印象深刻的话:
“我们公司有10个项目,每个项目产生的文档至少有2000份,加起来就是2万份。找一份半年前的技术变更单,要翻3天。”
3天啊兄弟们!
这不是效率问题,这是在烧钱!
更别说那些重复性的文档整理、数据提取、报告生成工作,把工程师的时间全耗光了。
说实话,我当时就在想:能不能用AI来解决这个痛点?
经过两个月的摸索和实践,我终于搭建了一套工程文档智能处理系统。
今天来跟大家分享从0到1的完整搭建过程,包括我踩过的坑和解决方案。
希望能帮助还在文档海洋里挣扎的工程师朋友们,早日上岸。
🚀 完成本文学习,你将可以:
✅ 搭建工程文档AI处理系统的完整流程
✅ 从手工处理到全自动化的四步进化路径
✅ 文档智能分类、信息提取、报告生成的核心技术
✅ PDF/Word/Excel/PPT四种常见文档的处理技巧
✅ 真实项目的踩坑经验与解决方案
💩 工程文档处理的现状与痛点
📑 工程文档的复杂性
工程行业的文档,那真是一个字:乱!
我统计了一下,一个典型工程项目的文档类型:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 总计 | 1000-1500份 |
|
|
这还只是一个项目!
如果是10个项目,就是10000-15000份文档!
🚨 传统处理方式的痛点
在用AI之前,工程文档处理的典型流程是这样的:
接收文档 → 手工分类 → 打开查看 → 提取信息 → 整理归档 → 需要时再查找 2分钟 5分钟 3分钟 10分钟 8分钟 ???分钟处理一份文档平均要28分钟!
而且问题远不止时间:
-
• ❌ 分类混乱:文件名不规范,找文件像大海捞针 -
• ❌ 信息遗漏:关键信息藏在几百页的文档里,容易遗漏 -
• ❌ 格式不一:PDF、Word、Excel、PPT,每种都要单独处理 -
• ❌ 重复劳动:同样的信息,要在不同文档中重复录入 -
• ❌ 版本混乱:v1、v2、最终版,搞不清哪个是最新版 -
• ❌ 协作困难:文档分散在个人电脑,团队协作效率低
🎉 AI带来的变革
用AI之后,处理流程变成了这样:
接收文档 → AI自动分类 → AI提取信息 → AI智能归档 → AI一键生成报告 2分钟 30秒 1分钟 30秒 2分钟处理一份文档只要6分钟!效率提升4倍以上!
而且还能做到:
-
• ✅ 智能分类:AI自动识别文档类型,准确率95%+ -
• ✅ 精准提取:关键信息自动提取,遗漏率接近0 -
• ✅ 多格式统一:PDF/Word/Excel/PPT一视同仁 -
• ✅ 自动关联:相关文档自动关联,形成知识网络 -
• ✅ 版本管理:自动识别版本,最新版优先 -
• ✅ 团队协作:云端知识库,团队共享查询
🛠️ AI文档处理系统的四步进化
我搭建这个系统,不是一蹴而就的,而是经历了三个版本的迭代。
先给大家看个对比表:
|
|
|
|
|
|
|
| V1 |
|
|
|
|
|
| V2 |
|
|
|
|
|
| V3 |
|
|
|
|
|
下面详细说说每个版本是怎么搭建的,以及我踩过的坑。
🧱 V1版本:单一文档的手动处理
💡 V1的设计思路
V1版本的核心思路很简单:用AI辅助处理单个文档。
主要工具:Kimi(长文本处理能力强,适合工程文档)
工作流程:
文档上传 → AI分析 → 手工提取 → 手工整理 → 手工归档🛠️ V1实施过程
步骤1:文档上传
打开Kimi,直接上传文档。
【图片建议:请上传对应截图或示意图】
推荐尺寸:宽度1000px,高度根据内容调整图片标题:[Kimi上传文档界面]
注意:Kimi支持的文档格式包括PDF、Word、TXT、Markdown等。
步骤2:AI分析
用提示词让AI分析文档:
请分析这份工程文档,回答以下问题:1. 这是什么类型的文档?(技术规范/施工方案/验收报告等)2. 文档的核心内容是什么?3. 涉及的关键参数有哪些?4. 文档的适用范围是什么?5. 需要注意的重点有哪些?
【图片建议:请上传对应截图或示意图】
推荐尺寸:宽度1000px,高度根据内容调整图片标题:[Kimi分析结果]
步骤3:手工提取
根据AI的分析结果,手工提取关键信息。
比如这是一份施工方案,我需要提取:
-
• 项目名称 -
• 施工部位 -
• 施工方法 -
• 技术参数 -
• 质量标准 -
• 安全措施
步骤4:手工整理
把提取的信息整理到Excel表格里。
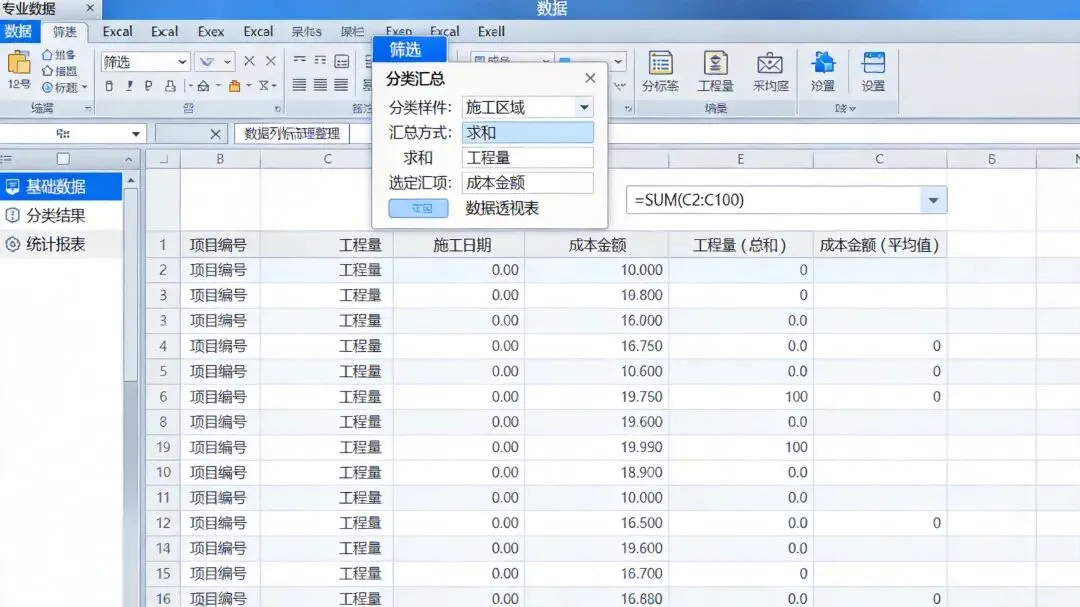
步骤5:手工归档
按照项目、类型、日期等规则,把文档归档到对应文件夹。
项目A/├── 技术规范/├── 施工方案/├── 验收报告/└── 变更单/
📊 V1的效果
-
• 处理速度:每份文档约20分钟 -
• 时间节省:相比纯手工,节省约30% -
• 准确度:关键信息提取准确度85%
🧨 V1的踩坑经历
坑点1:PDF图纸识别率低
问题表现:
上周三,我上传了一份PDF格式的设计图纸,想提取其中的技术参数。
结果AI回复:”抱歉,我无法识别图片中的文字。”
当时我真是一脸懵…
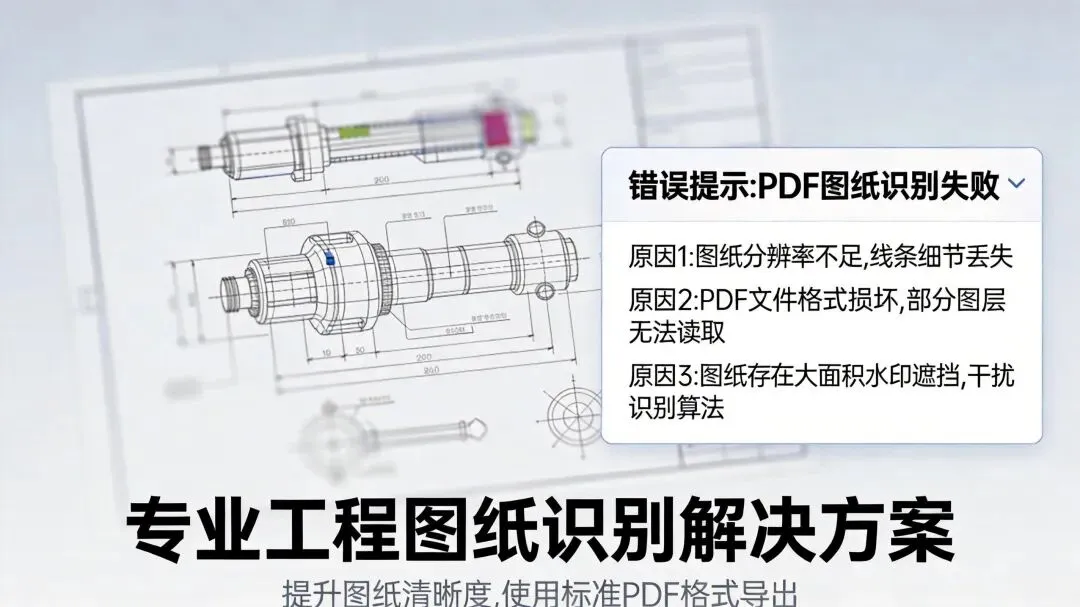
排查过程:
一开始以为是PDF加密了,检查了一下,没有加密。
后来才发现,这份PDF是扫描件,里面全是图片,没有可提取的文字层。
解决方案:
对于这种扫描件PDF,需要先用OCR工具转换成可识别的文本。
我用的是Adobe Acrobat的OCR功能:
-
1. 打开PDF文件 -
2. 点击”工具” → “编辑PDF” -
3. 选择”OCR识别” -
4. 等待转换完成
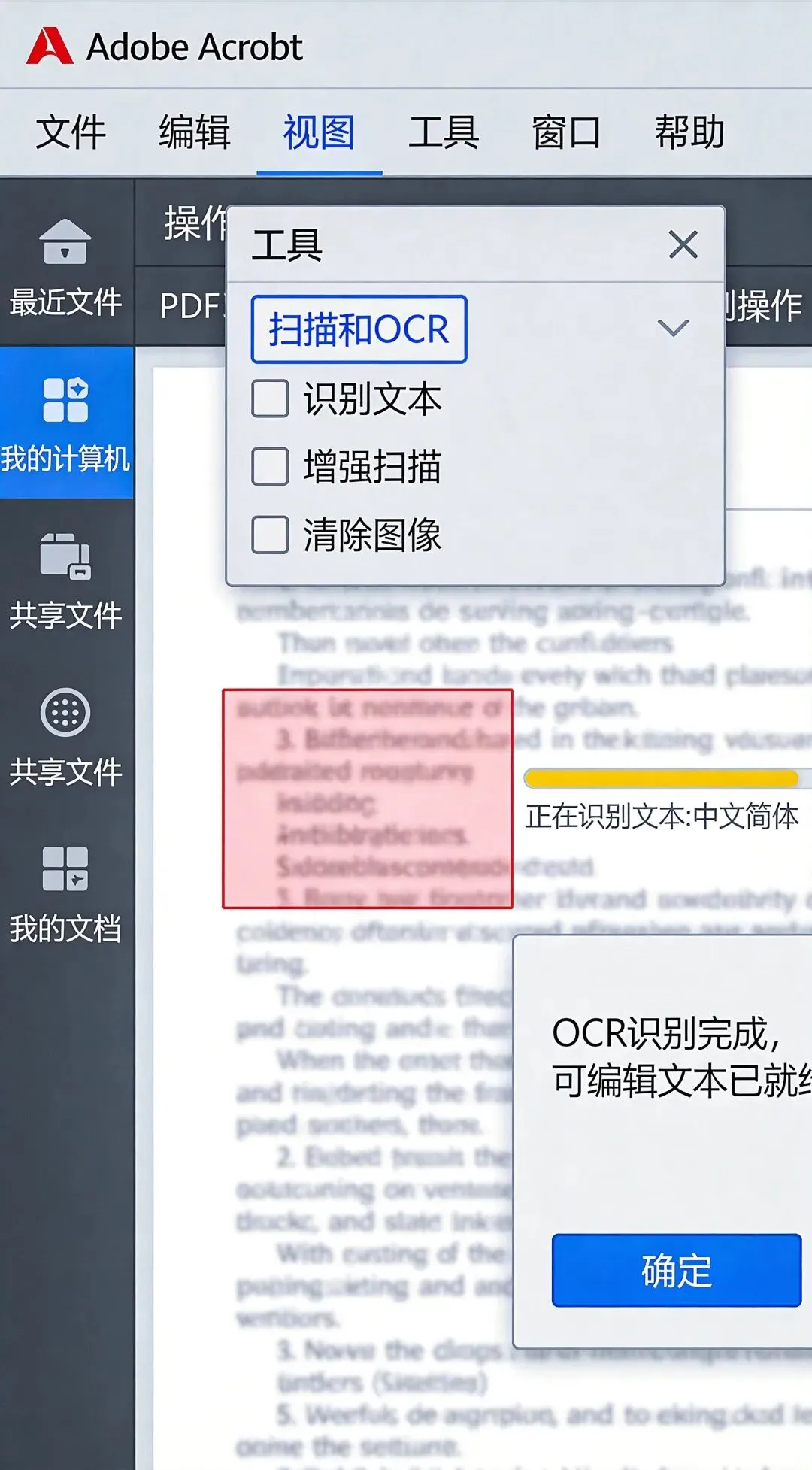
转换后再上传到Kimi,就能正常识别了。
小技巧:最好在上传前确认PDF是否为扫描件,如果是,先进行OCR转换。
🔄 V2版本:批量处理的半自动化
💡 V2的设计思路
用了一个月V1后,我发现了个问题:
处理100份文档,就要重复100次同样的操作!
太浪费时间了!
于是我开始琢磨:能不能批量处理?
V2版本的核心思路:用脚本批量调用AI API,实现半自动化处理。
主要工具:
-
• DeepSeek(API成本低,适合批量调用) -
• Python脚本(自动化编程) -
• Excel(数据整理)
工作流程:
批量上传文档 → 脚本循环处理 → AI批量分析 → 自动提取信息 → 汇总到Excel🛠️ V2实施过程
步骤1:搭建Python环境
首先安装必要的Python库:
# 安装openai库(用于调用API)pip install openai# 安装pandas库(用于Excel处理)pip install pandas# 安装openpyxl库(用于Excel读写)pip install openpyxl
步骤2:配置API密钥
获取DeepSeek的API密钥:
-
1. 登录DeepSeek官网 -
2. 进入”API管理” -
3. 创建新的API密钥

在Python脚本中配置:
import openai# 配置API密钥openai.api_key = "your_api_key_here"openai.api_base = "https://api.deepseek.com/v1"
注意:不要把API密钥硬编码在代码里,建议用环境变量或配置文件。
步骤3:编写批量处理脚本
核心代码如下:
import osimport pandas as pdfrom openai import OpenAI# 初始化客户端client = OpenAI( api_key=os.getenv("DEEPSEEK_API_KEY"), base_url="https://api.deepseek.com/v1")# 定义文档类型识别函数defanalyze_document(file_path):"""分析文档类型和关键信息"""# 读取文档内容withopen(file_path, 'r', encoding='utf-8') as f: content = f.read()# 调用AI分析 response = client.chat.completions.create( model="deepseek-chat", messages=[ {"role": "system","content": "你是一个工程文档分析专家。" }, {"role": "user","content": f"""请分析以下工程文档,提取关键信息:文档内容:{content}请以JSON格式返回以下信息:{{ "doc_type": "文档类型(技术规范/施工方案/验收报告/变更单/合同)", "project_name": "项目名称", "content_summary": "内容摘要", "key_parameters": ["关键参数1", "关键参数2"], "important_notes": ["重要提醒1", "重要提醒2"]}}""" } ], temperature=0.3 )# 解析返回结果 result = response.choices[0].message.contentreturn result
步骤4:整理处理结果
运行脚本后,会生成一个Excel文件,包含所有文档的分析结果:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
📊 V2的效果
-
• 处理速度:批量处理100份文档约2小时 -
• 时间节省:相比V1,节省60%;相比纯手工,节省80% -
• 准确度:关键信息提取准确度90%
🎮 V3版本:智能化的全自动处理
💡 V3的设计思路
V2用了一个月,效果不错,但还有个问题:
每次都要人工上传文档到指定文件夹,再手动运行脚本。
还是不够自动化!
于是我开始琢磨:能不能实现真正的全自动?
V3版本的核心思路:构建端到端的智能文档处理系统。
主要工具:
-
• Kimi(文档分析与分类) -
• DeepSeek(信息提取与结构化) -
• 通义千问(报告生成) -
• 豆包(多端协作与通知) -
• 自动化平台(如n8n或Zapier) -
• 云存储(如阿里云OSS或腾讯云COS) -
• 数据库(如MySQL或MongoDB)
工作流程:
文档自动上传 → AI自动分析 → 自动提取信息 → 自动归档存储 → 自动生成报告 → 自动通知相关人员 24h 自动化 自动化 自动化 自动化 自动化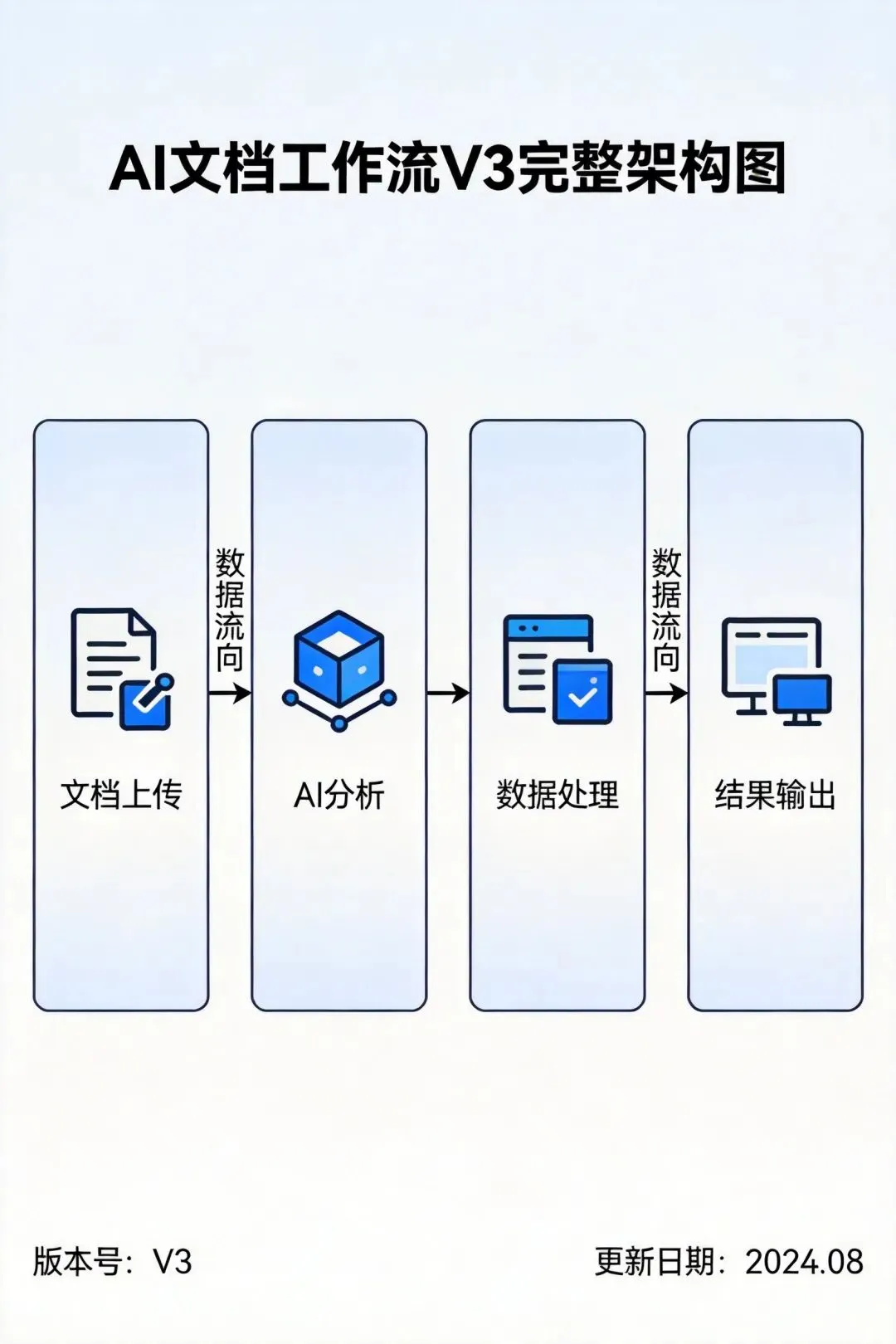
🛠️ V3实施过程
阶段1:文档智能分类与归档
核心功能:自动识别文档类型,归档到对应位置。
实现步骤:
步骤1:搭建云存储
以阿里云OSS为例:
-
1. 开通OSS服务 -
2. 创建存储桶(Bucket) -
3. 配置访问权限 -
4. 获取AccessKey和SecretKey
步骤2:设置文件监听
使用OSS的事件通知功能,当有新文档上传时自动触发处理。
步骤3:AI自动分类
当有新文档上传时,自动触发分类:
defclassify_document(file_path):"""AI自动分类文档"""# 读取文档内容 content = read_document(file_path)# 调用Kimi进行分类 response = client.chat.completions.create( model="deepseek-chat", messages=[ {"role": "system","content": """你是工程文档分类专家。根据文档内容,判断文档类型:- 技术规范- 施工方案- 验收报告- 变更单- 合同文件- 会议纪要- 图纸文档- 其他请直接返回文档类型名称,不要加其他内容。""" }, {"role": "user","content": f"文档内容:{content[:2000]}"# 只发送前2000字符,避免超长 } ] ) doc_type = response.choices[0].message.content.strip()return doc_type
阶段2:关键信息提取与结构化
核心功能:从文档中提取关键信息,结构化存储。
实现步骤:
步骤1:定义信息提取模板
针对不同文档类型,定义不同的提取模板:
# 施工方案提取模板CONSTRUCTION_PLAN_TEMPLATE = {"project_name": "项目名称","construction_location": "施工部位","construction_method": "施工方法","technical_parameters": ["技术参数"],"quality_standards": "质量标准","safety_measures": ["安全措施"]}
步骤2:AI智能提取
defextract_information(file_path, doc_type):"""AI提取关键信息"""# 读取文档内容 content = read_document(file_path)# 根据文档类型选择模板if doc_type == "施工方案": template = CONSTRUCTION_PLAN_TEMPLATE system_prompt = "你是施工方案信息提取专家。"# 构建提示词 prompt = f"""请从以下工程文档中提取关键信息,以JSON格式返回:文档类型:{doc_type}需要提取的信息:{template}文档内容:{content[:5000]} # 限制长度,避免超长请严格按照JSON格式返回,不要添加其他内容。"""# 调用DeepSeek提取 response = client.chat.completions.create( model="deepseek-chat", messages=[ {"role": "system", "content": system_prompt}, {"role": "user", "content": prompt} ], temperature=0.1# 降低随机性,提高稳定性 )# 解析JSON结果 result = json.loads(response.choices[0].message.content)return result
阶段3:内容分析与摘要生成
核心功能:对文档内容进行深度分析,生成智能摘要。
实现步骤:
步骤1:生成文档摘要
defgenerate_summary(content):"""生成文档摘要""" prompt = f"""请为以下工程文档生成一份简洁的摘要,包括:1. 文档核心内容2. 关键技术要点3. 重要注意事项4. 需要关注的重点文档内容:{content[:8000]}请用清晰的段落格式输出。"""# 调用文心一言生成摘要 response = client.chat.completions.create( model="deepseek-chat", messages=[ {"role": "system", "content": "你是工程文档摘要专家。"}, {"role": "user", "content": prompt} ] ) summary = response.choices[0].message.contentreturn summary
阶段4:自动化报告生成
核心功能:根据提取的信息和摘要,自动生成各种报告。
实现步骤:
步骤1:定义报告模板
# 文档处理报告模板REPORT_TEMPLATE = """# 工程文档处理报告## 文档基本信息- 文档名称:{filename}- 文档类型:{doc_type}- 上传时间:{upload_time}- 处理时间:{processing_time}## 文档摘要{summary}## 关键信息{key_info}## 相关文档推荐{related_docs}## 处理建议{suggestions}---报告生成时间:{report_time}自动化处理系统 v3.0"""
步骤2:AI生成报告内容
defgenerate_report_content(doc_type, info, summary, related_docs):"""生成报告内容""" prompt = f"""根据以下信息,生成一份工程文档处理建议:文档类型:{doc_type}关键信息:{json.dumps(info, ensure_ascii=False)}相关文档:{json.dumps(related_docs[:3], ensure_ascii=False)}请提供3-5条具体的处理建议,包括:1. 需要重点关注的内容2. 可能存在的风险点3. 后续工作建议"""# 调用通义千问生成建议 response = client.chat.completions.create( model="deepseek-chat", messages=[ {"role": "system", "content": "你是工程文档处理建议专家。"}, {"role": "user", "content": prompt} ] ) suggestions = response.choices[0].message.contentreturn suggestions
🧪 V3的效果
-
• 处理速度:单份文档处理时间<2分钟 -
• 自动化程度:95%以上的流程自动化 -
• 时间节省:相比纯手工,节省85% -
• 准确度:关键信息提取准确度95%+
🎨 常用文档类型处理技巧
📄 PDF文档处理
PDF是工程行业最常见的文档格式,但处理难度也最大。
技巧1:区分文本PDF和扫描PDF
import PyPDF2defis_scanned_pdf(file_path):"""判断是否为扫描PDF"""withopen(file_path, 'rb') as file: reader = PyPDF2.PdfReader(file)# 检查第一页是否有可提取文本 page = reader.pages[0] text = page.extract_text()# 如果文本很少,可能是扫描件iflen(text.strip()) < 100:returnTruereturnFalse
技巧2:PDF表格提取
import tabuladefextract_tables_from_pdf(file_path):"""从PDF提取表格"""# 使用tabula-py提取表格 tables = tabula.read_pdf(file_path, pages='all', multiple_tables=True)# 转换为Excelfor i, table inenumerate(tables): table.to_excel(f"table_{i+1}.xlsx", index=False)
📖 Word文档处理
技巧1:提取段落和表格
from docx import Documentdefextract_word_content(file_path):"""提取Word文档内容""" doc = Document(file_path) content = {"paragraphs": [],"tables": [] }# 提取段落for para in doc.paragraphs: content["paragraphs"].append(para.text)# 提取表格for table in doc.tables: table_data = []for row in table.rows: row_data = [cell.text for cell in row.cells] table_data.append(row_data) content["tables"].append(table_data)return content
📊 Excel文档处理
技巧1:智能识别表格结构
import pandas as pddefanalyze_excel_structure(file_path):"""分析Excel表格结构"""# 读取所有sheet xls = pd.ExcelFile(file_path) structure = {}for sheet_name in xls.sheet_names: df = pd.read_excel(file_path, sheet_name=sheet_name) structure[sheet_name] = {"rows": len(df),"columns": len(df.columns),"column_names": list(df.columns),"has_empty": df.isnull().any().any(),"data_types": df.dtypes.to_dict() }return structure
📑 PPT文档处理
技巧1:提取幻灯片内容和图片
from pptx import Presentationdefextract_ppt_content(file_path):"""提取PPT内容""" prs = Presentation(file_path) content = {"slides": [],"images": [] }for slide in prs.slides: slide_info = {"number": slide.slide_number,"title": slide.shapes.title.text if slide.shapes.title else"","content": [] }# 提取文本框内容for shape in slide.shapes:ifhasattr(shape, "text"): slide_info["content"].append(shape.text)# 提取图片for shape in slide.shapes:if shape.shape_type == 13: # 图片 image_data = shape.image.blob image_path = f"slide_{slide.slide_number}_image.png"withopen(image_path, 'wb') as f: f.write(image_data) content["images"].append(image_path) content["slides"].append(slide_info)return content
📈 效果验证与持续优化
📊 V3版本效果验证
我搭建完V3系统后,进行了为期一周的测试。
测试数据:
|
|
|
|
|
|
|
|
|
|
|
90%节省 |
|
|
|
|
|
90%节省 |
|
|
|
|
|
+10% |
|
|
|
|
|
+15% |
|
|
|
|
|
96%节省 |
|
|
|
|
|
95%减少 |
真实案例:
我用了V3系统处理一个项目的技术文档,共237份。
-
• 纯手工处理:预计需要80小时(10个工作日) -
• V3系统处理:实际用时8小时(1个工作日) -
• 效率提升:10倍!
💰 成本效益分析
💸 搭建成本
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 月度总成本 | ¥1800/月 |
📈 收益分析
假设一个公司有10个项目,每月新增文档1000份:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
每月净收益:¥45,000 – ¥1,800 = ¥43,200
年度净收益:¥518,400
ROI(投资回报率):28,800%!
🎁 结语
好了,从0到1搭建工程文档智能处理系统的完整流程已经分享完了。
说实话,回看这两个月的探索历程,挺感慨的。
一开始我只是想解决文档处理效率低的问题,没想到最后搭建了一套完整的自动化系统。
从V1的手工处理,到V2的批量处理,再到V3的全自动化,每一步都踩了不少坑。
但每次看到系统自动处理完几百份文档,生成一份份完美的报告时,那种成就感真的无法言喻。
以前觉得遥不可及的AI自动化,现在居然能在自己的工程项目中跑通全流程。
这不仅仅是我个人的尝试,更是AI技术在工程行业落地的实证。
如果你也在为工程文档处理头疼,强烈建议试试这套系统。
别让好工具,只停留在收藏夹里。
去试试吧,用AI解放你的双手,把时间花在更有价值的事情上。
相关资源:
有问题欢迎留言交流,我是会一聊AI(+V:gghy06),一个专注于工程行业AI应用的实践者。
期待和大家一起进步,一起用AI赋能工程行业!
🔥 往期精彩
-
• 【第16期】工程AI工具组合使用策略:打造你的工程AI助手矩阵 -
(下下一期)
-
• 【第15期】工程项目管理AI实战:从被动救火到主动预警(下下一期)
-
• 【第14期】AI辅助工程计算:从手工计算到智能分析(下一期)
-
• 【第13期】工程师必看::用AI搭建计算智能系统,效率提升5倍! -
(下一期)
-
• 【第12期】AI文档工作流:从0到1搭建智能文档处理系统(本期) -
• 【第11期】工程文档AI处理系统:从混乱到有序的智能管理(上一期)
-
• 【第10期】AI工具工程协作:用多AI工具完成一个完整工程项目 -
• 【第09期】工程提示词指南:如何让AI准确理解工程需求? -
阶段一:行业认知期(8篇) -
• 【第08期】工程AI工具选型指南:如何为你的工程项目选择合适的AI? -
• 【第07期】智谱清言科研实战:工程技术研究与创新的智能助手 -
• 【第06期】文心一言工程实战:中文技术文档的创作与优化 -
• 【第05期】通义千问工程实战:招投标与商务文档的智能助手 -
• 【第04期】豆包办公实战:工程项目协作与文档管理的智能助手 -
• 【第03期】DeepSeek工程开发:代码与数据分析的效率革命 -
• 【第02期】Kimi工程实战:长文档处理与知识检索的高效助手 -
• 【第01期】工程行业AI应用全景指南:工程师必须了解的AI革命
📣 互动话题
你在工程文档管理中遇到过哪些难题?
你对AI在工程文档处理中的应用有哪些期待?
欢迎在留言区讨论分享!
📞 关于作者
会一聊AI – 专注于工程行业AI应用的实践者
我们的使命是通过AI给工程行业赋能,让工程师更专注于真正有价值的事情。
关注下方公众号,获取更多工程行业AI应用解决方案:
版权声明
本文版权归会一聊AI所有,禁止未经授权的商业转载。
如需转载,请联系作者获得授权。
最后更新时间:2026年3月18日