 夜雨聆风
夜雨聆风





4B参数一统文档智能!百度Qianfan-OCR凭啥碾压多阶段OCR?
4B参数一统文档智能!百度Qianfan-OCR凭啥碾压多阶段OCR?
AI前沿 | 顶会论文解读
论文标题:Qianfan-OCR: A Unified End-to-End Model for Document Intelligence
作者团队:百度千帆团队
发表会议:ArXiv 2026
核心结论:提出4B参数端到端文档智能模型,统一文档解析、布局分析与理解能力;创新Layout-as-Thought机制补全端到端架构布局分析短板;在OmniDocBench等多基准登顶,KIE任务超越Gemini-3.1Pro等旗舰模型
📄 论文摘要
传统OCR系统面临成本、精度与能力的三重权衡:多阶段流水线需复杂组件串联,易产生错误传播;端到端模型缺乏显式布局分析能力;通用大模型在结构化文档任务上精度不足。百度千帆团队提出Qianfan-OCR,一款4B参数的端到端文档智能模型,首次在单一视觉语言架构内统一文档解析、布局分析与语义理解。创新的Layout-as-Thought机制通过<think>令牌触发可选思考阶段,生成结构化布局表示后再输出最终结果,既补全了端到端架构的布局分析能力,又能在复杂文档上提升精度。该模型在OmniDocBench v1.5和OlmOCR Bench等端到端模型中排名第一,在KIE基准上超越Gemini-3.1Pro等旗舰模型,现已通过百度智能云千帆平台开放使用。
🏗️ 总架构设计
Qianfan-OCR采用千帆VL框架的多模态桥接架构,包含三大核心组件:Qianfan-ViT视觉编码器支持任意分辨率输入(最大4K),动态将图像切割为448×448补丁;Qwen3-4B语言模型 backbone具备32K原生上下文窗口,采用Grouped-Query Attention平衡推理能力与部署效率;轻量级跨模态适配器通过两层MLP实现视觉与语言特征空间的对齐。与传统两阶段流水线不同,Qianfan-OCR将所有处理统一在单一模型内,避免了多阶段间的错误传播与视觉上下文丢失,同时支持灵活的任务控制。
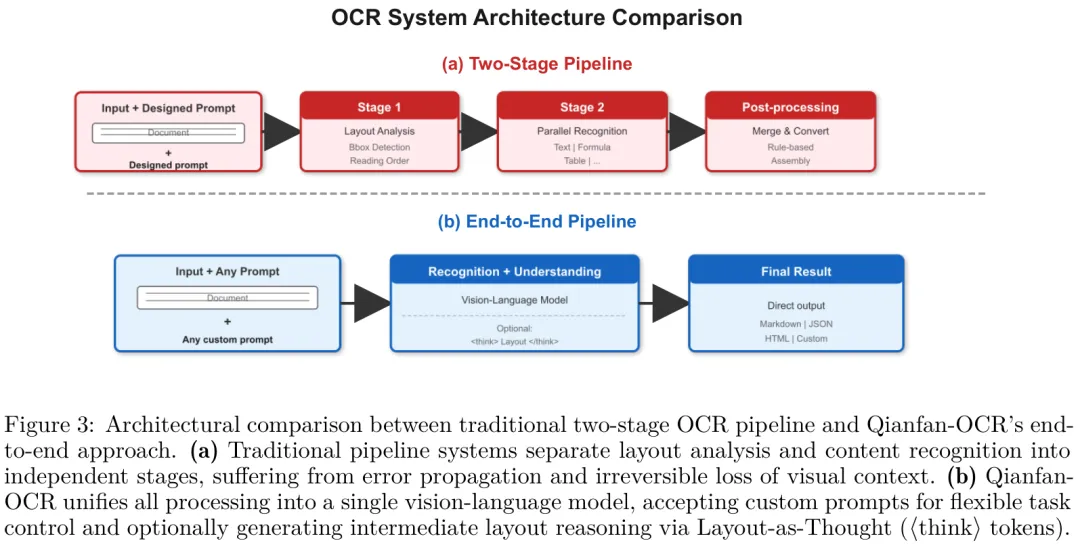
图1:Qianfan-OCR端到端架构与传统两阶段OCR流水线对比
💡 核心创新点
▪ 端到端统一文档智能架构:首次将文档解析、布局分析、文本识别与语义理解统一在单一视觉语言模型内,彻底消除传统多阶段流水线的错误传播问题。模型直接输出Markdown格式结果,支持表格提取、图表理解、文档问答等全流程任务,无需额外组件串联。
▪ Layout-as-Thought布局推理机制:通过<think>令牌触发可选思考阶段,模型先生成包含边界框、元素类型与阅读顺序的结构化布局表示,再生成最终输出。该机制不仅补全了端到端架构缺失的布局分析能力,还能为复杂文档提供结构先验,在多列文本、乱序元素等场景下显著提升识别精度。
▪ OCR与理解能力深度融合:突破传统OCR仅能字符识别的局限,将文档理解能力内置到模型中。在文档问答、图表理解等任务上表现媲美通用大模型,同时保持OCR专业模型的高精度。实验证明,两阶段OCR+LLM流水线在图表理解任务上近乎失效,而Qianfan-OCR能保持88.1%的ChartQA准确率。

图2:Layout-as-Thought在数学试卷上的应用示例
🔬 关键方法与实验结果
模型采用四阶段渐进式训练策略:Stage1跨模态对齐(50B tokens)、Stage2基础OCR训练(2T tokens)、Stage3领域增强(800B tokens)、Stage4指令调优。针对OCR任务构建六大数据合成流水线,覆盖文档解析、KIE、复杂表格、图表理解等场景,总数据量超过2.85T tokens。实验在四类基准上全面验证,包含OCR特定基准、通用OCR基准、文档理解基准与KIE基准。
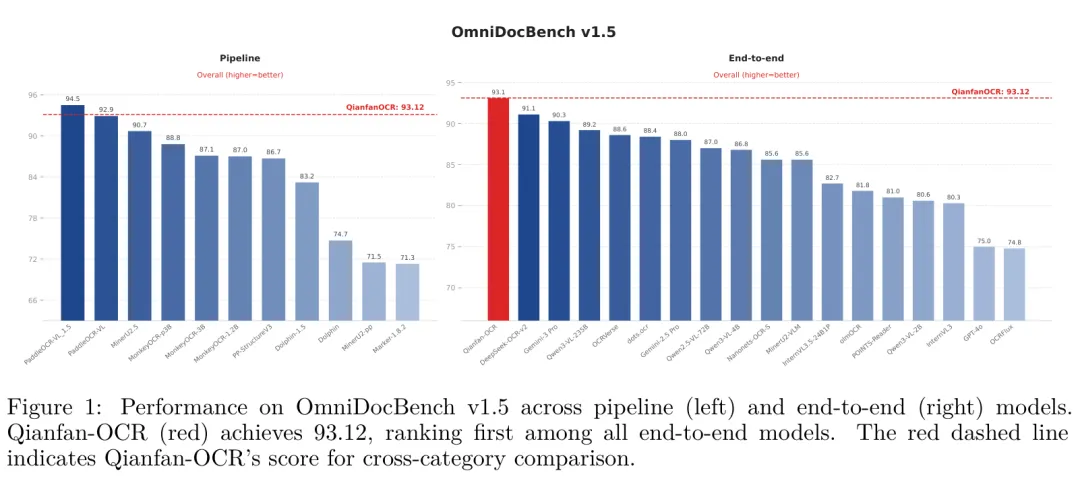
图3:OmniDocBench v1.5端到端模型性能对比
实验结果显示,Qianfan-OCR在端到端模型中表现突出:在OmniDocBench v1.5上以93.12分排名第一,超过DeepSeek-OCR-v2(91.09)与Gemini-3 Pro(90.33);OlmOCR Bench获得79.8分,仅次于顶级流水线系统PaddleOCR-VL(80.0)。在KIE任务上表现尤为亮眼,在五公开基准上平均得分87.9,超过Gemini-3.1Pro(79.2)与Qwen3-VL-235B-A22B(84.2)。推理效率方面,W8A8量化后单A100 GPU可达1.024页/秒,接近PaddleOCR-VL的1.224页/秒。
| 模型 | OmniDocBench总分 | OlmOCR Bench总分 | KIE平均得分 | ChartQA准确率 |
|---|---|---|---|---|
| PaddleOCR-VL | 94.50 | 80.0 | 无原生能力 | 无原生能力 |
| Gemini-3 Pro | 90.33 | 无数据 | 77.0 | 无数据 |
| Qianfan-OCR | 93.12 | 79.8 | 87.9 | 88.1% |
🚀 应用价值与展望
Qianfan-OCR为文档智能领域提供了全新的技术范式,其端到端统一架构显著降低了部署复杂度与维护成本,同时保持了专业级OCR精度与强大的文档理解能力。在企业场景中可广泛应用于票据识别、合同审核、文档数字化等任务,特别是KIE任务上的优势使其在金融、政务等领域具备极高实用价值。未来,团队将探索Layout-as-Thought机制在更多任务上的应用,优化模型在资源受限环境下的部署效率,并拓展视频OCR、3D文本识别等更具挑战性的场景。
📚 论文原文:https://arxiv.org/pdf/2603.13398
💻 相关资源:https://github.com/baidubce/Qianfan-VL
🎯 核心亮点:4B参数端到端统一模型,Layout-as-Thought布局推理机制,多基准超越旗舰模型,兼顾精度与效率
⭐ 觉得文章有用?欢迎分享给更多朋友!
💡 关注公众号,获取更多顶会论文深度分析
🔥 每日精选AI论文,解读最新技术进展