 夜雨聆风
夜雨聆风





OpenClaw龙虾记忆插件——MemOS使用分享
给各位朋友分享下我最近正在用的一个记忆插件MemOS,本来是想先把最近跑通的一个远程龙虾Node内网穿透写一下(这里还是有着挺多坑点),但是这两天正好有个项目需要用到记忆模块,于是我想先把我这几天使用的MemOS总结一下,一方面可以和team进行一个交流互相探讨,整理下思路。同时,也作为我个人的一个知识记录,可以和看到此篇文章的朋友,也能互相交流探讨。
在安装MemOS插件前,原本计划是集成OpenViking,上个月在X上看到了一位技术博主,在官方插件出来前,就自己实现了一套,那时候自己也想按照帖子里的内容试一下,后来官方插件出来了1.0版本的slot模式,有着session启动会hang住的问题,issue#591。解决方式只能是降低版本…
于是想着先让子弹飞一会
就在前不久,官方的2.0发布了,基于context engine来做的,就是我上一篇文章里提到的。 与此同时,我又看到了另一个记忆解决方案,也就是我们今天的主角——MemOS。
MemOS的设计哲学和OpenViking的区别还是很大的,在我个人看来,通过了解到的信息结合我的使用习惯和方式,短期内我更喜欢MemOS一些,接下来进入正题,让我们先来看看MemOS的特性
特性
-
自动捕获 — 每轮对话结束后自动写入记忆,不用手动触发 -
智能去重 — 写入时相同的跳过、相似的合并;检索时也会过滤掉高度重叠的结果,两个阶段都有去重 -
时间衰减 — 越新的记忆检索权重越高,不会被久远历史干扰 -
Task Summary — 自动把对话切成一个个任务,每个任务完成后生成结构化摘要,方便后续检索完整经验 -
Skill 进化 — 任务完成后自动提炼成可复用的 Skill,下次遇到类似问题直接用,用得多了还会自动升版 -
Public 记忆 — 多 Agent 场景下记忆默认各自隔离,需要共享的内容可以写入公共空间,Skill 也可以发布给其他 Agent 用 -
自动召回 — 每轮对话开始前自动检索相关记忆注入上下文,用户无感知,不需要手动触发
工作原理
先来看一下整体架构组成
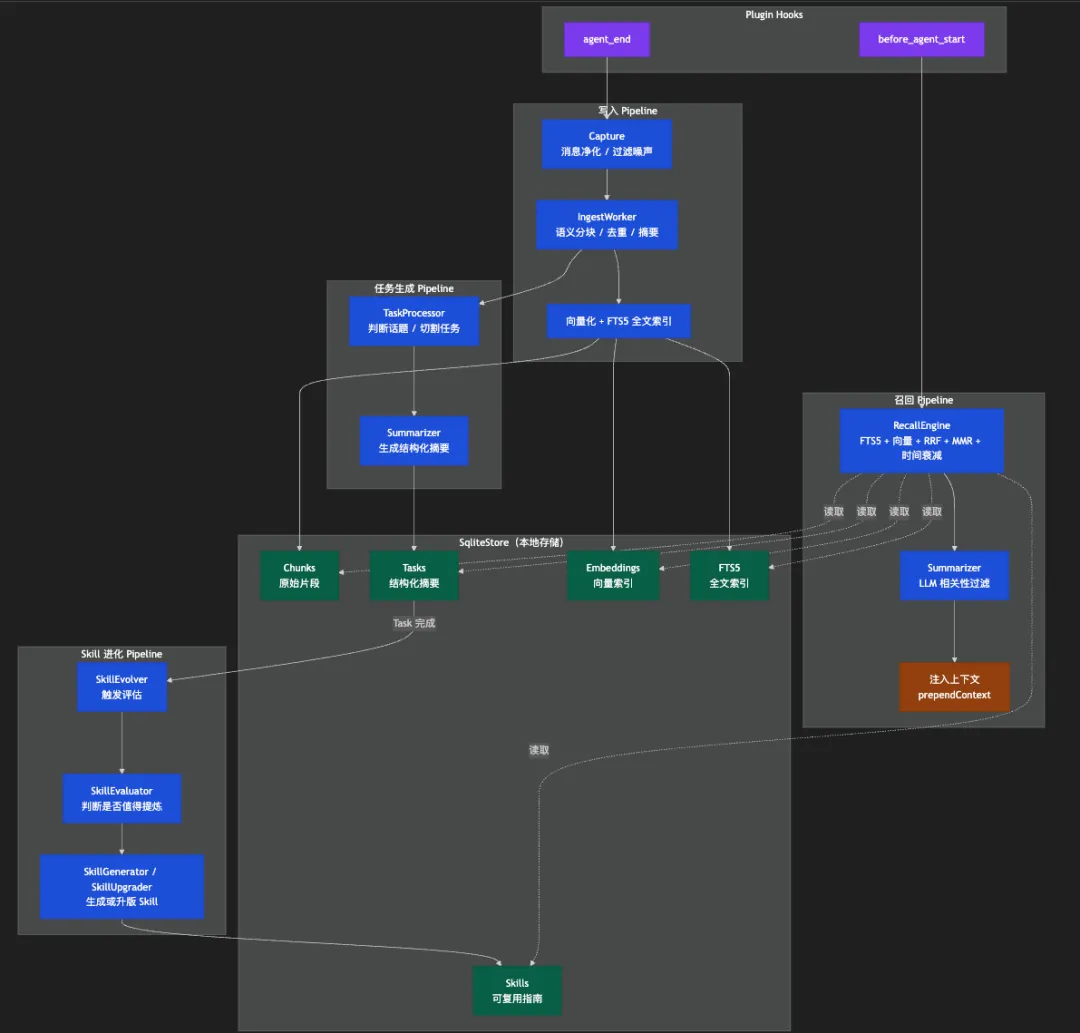
上面是整体的组件关系和数据流向,相信大家看完图,有了一个整体的了解了,接下来挑几个关键的组件细说一下。
Plugin Hooks

MemOS 的两个核心 Hook 是整个系统的入口,借助 OpenClaw 的插件 Hook 机制实现,不需要改任何业务代码。
agent_end 在每轮对话成功结束后触发,负责把这轮新增的消息捕获并写入记忆。user、assistant、tool 三种角色的消息都会被记录,但写入前会做一轮清洗:OpenClaw 注入的元数据、时间戳前缀、以及上一轮召回塞进来的记忆内容本身都会被剥离,只保留用户实际说的话和 Agent 真实的回复,以免存了一些冗余没啥价值的内容记忆污染
before_agent_start 在每轮对话开始前触发,用用户的消息跑一次记忆检索,把结果通过 prependContext 注入到 Agent 的上下文里。Agent 能看到这些内容,但对用户不可见。有意思的一点是,如果检索没有命中(或者 LLM 过滤后觉得结果不够用),系统不会直接跳过,而是在上下文里加一段强提示,要求 Agent 主动调用 memory_search 用更短的关键词再搜一次。
IngestWorker
IngestWorker 是记忆写入的核心,每条消息进来都要经过摘要和去重两个步骤。
摘要先于去重执行。每条消息写入前,先用 LLM 提炼出一句摘要,然后对这个摘要做向量化。后续的去重判断和检索都基于摘要而不是原始内容,这样既节省 token,语义匹配也更准确。
去重有两个步骤:
第一个是内容哈希精确匹配,完全一样的内容直接跳过,不走 LLM。
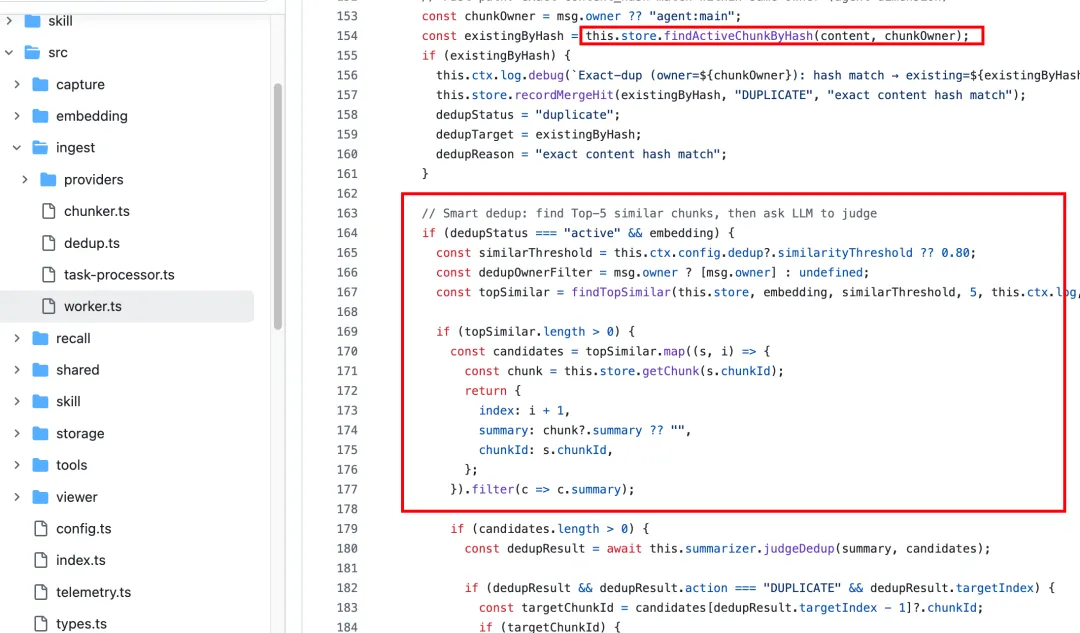
第二个是语义去重,找出向量相似度超过阈值的 Top-5,交给 LLM 判断,有三种结果——新的直接写入,重复的跳过,复杂一点的是 UPDATE:新内容和旧内容相关但有补充,合并成一个新摘要,旧 chunk 退休,新 chunk 带着合并后的摘要和更新的向量写入,同时继承合并历史。
相应的代码就在woker.ts里,对写记忆这里感兴趣的虾友可以看下这里面的实现
TaskProcessor
TaskProcessor 负责把零散的对话 chunk 归并成一个个有意义的任务,然后在任务结束时生成结构化摘要。
1、首先是判断任务的边界,也就是说确定属于同一个task:
每批 chunk 写入后,TaskProcessor 按 user-turn 逐轮处理,判断是继续当前任务还是切新任务,有优先级顺序:
首先检查硬规则——session 切换或时间间隔超过 2 小时,直接切割,不往下走。
硬规则没触发,再看当前任务里有没有至少 1 条用户消息,没有就没有参照物,直接归入当前任务。
有参照物了才调 LLM,把当前任务的上下文和新消息一起发过去,判断是 SAME 还是 NEW。
2、任务跳过
不是所有任务都会生成摘要。任务完成后会先过一遍规则过滤,满足以下任意一条就跳过:消息少于 4 条、问答轮次不足 2 轮、没有用户消息、总内容太短、内容是测试或hello,hi 之类、工具结果占比高还有一些其他规则,被跳过的任务标记为 skipped,不参与检索。
这个过滤挺有必要的,不然随便打个招呼也生成一次摘要,既浪费 token 也没意义。
3、摘要生成
通过过滤的任务,把所有 chunk 的原始内容拼成完整对话文本,交给 LLM 生成结构化摘要。摘要里会保留目标、步骤、结果等关键细节。摘要生成后,任务状态变为 completed,同时触发 SkillEvolver 的回调,开始评估是否值得提炼成 Skill。
SkillEvolver
Skill 进化是 MemOS 里最吸引我的部分,但是同时也是我担心的部分,怕它乱写skill。
Task 摘要生成完成后,TaskProcessor 会触发 SkillEvolver 的回调,然后进入下面这套流程:
第一步,规则过滤。 先过一遍硬规则,chunk 数量不够、摘要太短、没有用户消息的任务直接跳过,不走 LLM,省 token。
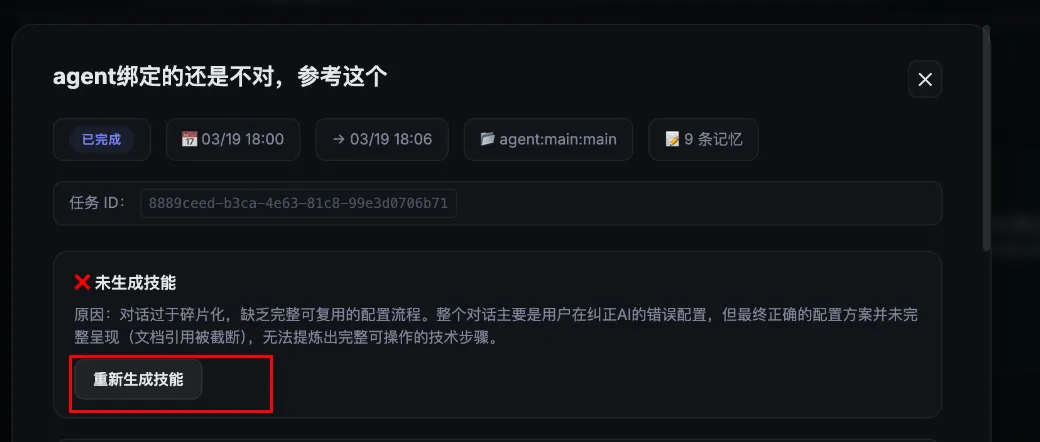
这里贴一个生成失败的截图,插件没有自动生成skill或者由于调用模型失败,也可以自己触发,但是也同样需要检测
第二步,找有没有已有的相关 Skill。 通过 FTS + 向量双路检索,然后交给 LLM 做严格判断——只有任务和某个 Skill 明确属于同一个领域,才算命中。这里用了向量 0.7 + FTS 0.3 的加权排序,再让 LLM 最终拍板,避免强行匹配不相关的 Skill。
第三步,走两条路。
找到相关 Skill:让 LLM 评估这次任务有没有带来实质性改进——更快的路径、更准确的步骤、新的错误处理,任意一条满足就升版。SkillUpgrader 会生成新版 SKILL.md,同时写入 changelog。
没找到:让 LLM 判断这个任务值不值得提炼成新 Skill。纯问答、闲聊、一次性的个人任务这些会被过滤掉,真正有复用价值的才会生成。
用得多了还会自动升版。(这个我还没有试过)。
时间衰减算法
之前的文章里提到,一个好的记忆设计,绝不是一堆松散结构的内容,平铺在哪里,没有分类、没有层级、没有权重优先级,去年的内容和今天的内容,同样被召回时,哪个应该被应用显而易见。
这里的时间算法很简单
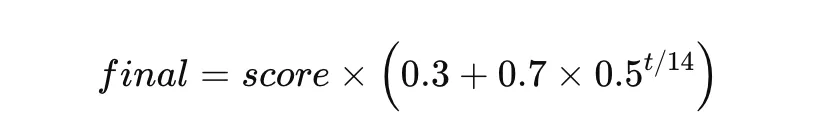
半衰期默认 14 天,也就是说 14 天前的记忆衰减到原来的一半,28 天前衰减到四分之一,以此类推。
0.3,作用是保底——就算一条记忆很老,最终得分也不会低于 base_score × 0.3。这样高度相关但时间久远的记忆还是有机会被召回,不会被新的无关内容完全压掉。0.7的值是为了控制时间的影响程度。
这一步在召回 pipeline 里排在 RRF 融合和 MMR 重排之后,最终结果再归一化到 [0, 1] 输出。
写在最后
龙虾的MemOS插件刚出不久,所以用的时间并不长,这篇文章写的也是很匆忙,自带的tool的能力也没有来得及写,很多细节也没有来得及去深挖,但每个组件我觉得都值得我们去研究,主要不是组件的使用,而是其中的思想。
如果你也在用 OpenClaw 并且觉得记忆管理有点头疼,可以试一试,有什么问题或者不同看法欢迎一起交流。